




 本文深入解析了Spark Streaming中WAL(Write-Ahead Logging)的工作原理,包括其在数据流处理中的作用、配置方法及故障恢复流程。WAL作为预写日志系统,在Spark Streaming中起到关键的容错和数据一致性保障作用。
本文深入解析了Spark Streaming中WAL(Write-Ahead Logging)的工作原理,包括其在数据流处理中的作用、配置方法及故障恢复流程。WAL作为预写日志系统,在Spark Streaming中起到关键的容错和数据一致性保障作用。
1 什么是WAL?
wal(write ahead logging)预写日志系统。就是提前备份元数据信息和数据。
总体上来看:
WAL系统是一个存储系统,它可以存储和接受数据。
有时间属性和索引属性。
看源码介绍:

在sparkstreaming中冷备应用图示介绍
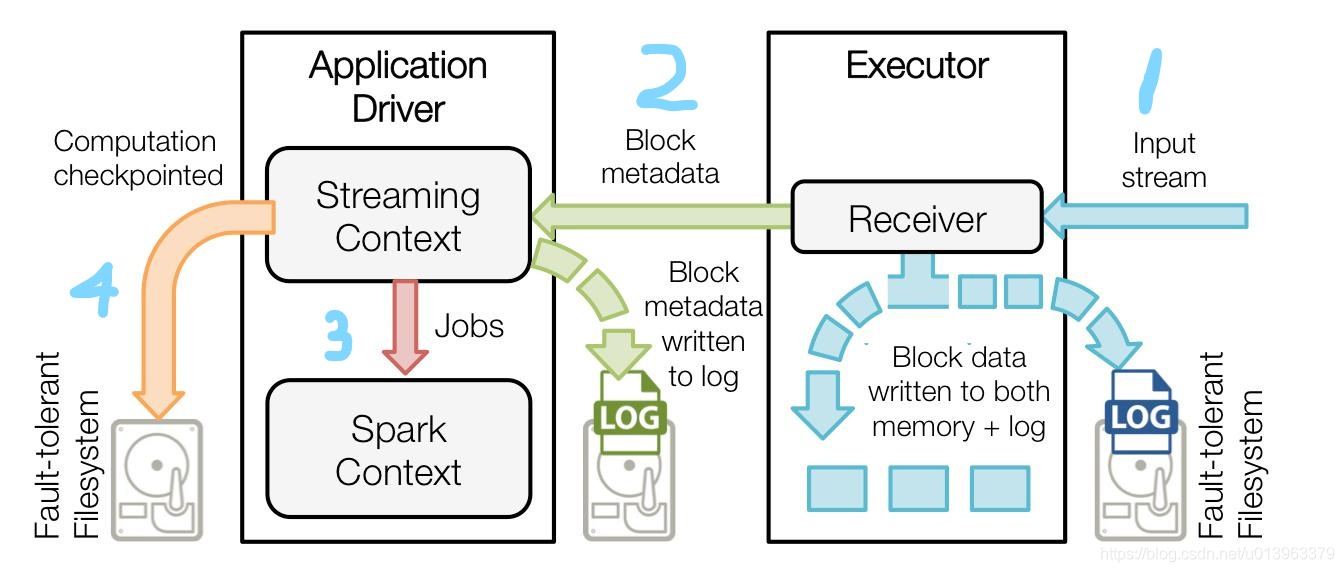
- 表示接受数据,接受器把数据流打包成块,存储在Excutor内存中,如果开启了WAL,将会把数据写入到处在容错文件系统的日志文件中
- 表示提醒Driver将接受到的数据块的元信息发送给Driver中的StreamingContext,这些元数据信息包括Executor内存中的数据块的引用ID和日志文件中数据块的偏移信息。
- 表示处理数据,每一个批批处理间隔,StreammingContext使用块信息生成RDDJobs,SparkContext执行这些Job用于处理Excutor内存中的数据。
- 表示做这些计算的checkpoint,以便于恢复。流式处理会周期性的通过检查点设置保存到文件中。
当Driver 因失败而重启后,恢复流程如下
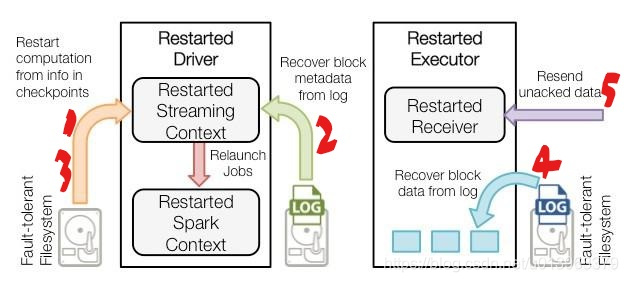
- 表示恢复计算,checkpoint的信息用于重启Driver,重新构造上下文和重启所有的Receiver。
- 表示恢复块元数据信息,所有的信息对于恢复计算都很重要。
- 表示重新生成未完成的Job。会使用到2中恢复的元数据信息。
- 表示读取保存在日志文件中的块,当Job重新执行的时候,块数据信息将从日志中直接读取。
- 表示重发没有确认的数据。缓冲的数据如果没有写到WAL中,将会被重新发送。
启动WAL需要做如下配置:
- 给StreamingContext设置Checkpoint目录,该目录必须是Hadoop支持的文件系统,用来保存WAL和做Streaming的checkpoint。显然,WAL也需要Checkpoint。
- 将spark。streaming.receiver.writeAheadLog.enable 设置为true。
以上是从原理角度解释WAL在sparkstreming中的应用。
从源码角度剖析:https://blog.youkuaiyun.com/andyshar/article/details/52143850

















 1781
1781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









