






 本文是循环神经网络(RNN)的入门教程,介绍了RNN的基础概念和应用,包括语言模型、机器翻译等。RNN利用序列信息,通过隐藏状态捕获历史信息,具有记忆功能。尽管简单的RNN在长距离依赖上存在挑战,但通过扩展如LSTM,RNN在NLP任务中表现出色。
本文是循环神经网络(RNN)的入门教程,介绍了RNN的基础概念和应用,包括语言模型、机器翻译等。RNN利用序列信息,通过隐藏状态捕获历史信息,具有记忆功能。尽管简单的RNN在长距离依赖上存在挑战,但通过扩展如LSTM,RNN在NLP任务中表现出色。
循环神经网络教程-第一部分 RNN介绍
循环神经网络(RNN)是非常流行的模型,它在许多NLP任务上都表现出了巨大的潜力。虽然它很流行,但是详细介绍RNN以及如何实现RNN的文章却很少。这篇教程旨在解决上述问题,教程分为4部分:
1. 介绍RNN(这篇教程)
2. 用Tensorflow实现RNN
3. 理解BPTT后向传播算法以及梯度消失/爆炸问题
4. 实现GRU/LSTM
作为教程的一部分,我们将会实现一个基于RNN的语言模型。语言模型的应用有两个方面:首先,它允许我们根据句子在现实世界出现的可能性对任意的句子进行打分,这给了我们一种衡量句子语法和语义正确性的方法(也就是说看一句话是不是正常人说的,句子越正常,分数就越高)。这种模型通常是机器翻译系统的一部分。第二,我们可以用语言模型生成文本(我认为这是更加酷炫的应用)。在莎士比亚的著作上训练语言模型可以生成莎士比亚风格的文章。Andrej Karpathy的这篇有趣的博客演示了可以用基于RNN的字符级的语言模型做些什么。
如果你对基本的神经网络不熟悉的话,你可能想从头开始实施一个神经网络 ,这篇博客会介绍基本神经网络的概念以及具体实施。
WHAT IS RNN?
RNN的想法是利用序列信息。在传统的神经网络中,我们假设输入(和输出)
是相互独立的,但是对于很多任务来说,这种方法很不好。如果你想要在一个句子中预测下一个词,那么你最好知道这个词的前一个词是什么。RNN称为“复现”,因为它对句子中的每一个元素都执行相同的任务,其输出依赖于前面的计算。另一种思考RNN的方式是认为它有“记忆”的功能,可以捕捉先前已经计算过的信息。从理论上来讲,RNN可以利用任意长度序列中的信息,但是在实际上在它们仅限于回顾几步(在后面做详细介绍)。典型的RNN是这个样子:

上图展示了展开到完整网络的RNN。展开只是意味着我们为完整的序列写出了网络。例如,如果我们关心的是有5个词的句子,网络将会展开成一个5层的网络,每一个词对应着一个网络。RNN中的计算公式如下:
- xt是t时刻的输入。例如,x1可能是句子中一个单词的one−hot向量。
- st是t时刻的隐藏状态。它是网络的"记忆单元"。st 是根据上一时刻的隐层状态和当前的输入计算的: st=f(Uxt+Wst−1) 。函数 f 通常是非线性,例如 tanh或者ReLU。s−1通常初始化为0,然后用它来计算第一个隐藏状态。
- ot 是t时刻的输出。例如,如果我们想预测句子中的下一个单词,那么它将会是一个概率向量,向量中的每一个值代表着词表中对应单词的概率。 ot=softmax(Vst) 。
需要注意以下几点:
- 我们可以认为 st 是网络的记忆单元, st 捕捉前面所有时刻发生的信息。输出 ot 仅根据时刻t的记忆进行计算。正如上面简要提到的那样,在实践中稍微有点复杂,因为 st 通常情况下不能捕捉很久之前时刻的信息。
- 和传统的深度神经网络在每一层都使用不同的参数不同的是,RNN在的所有的步骤中都使用同样的参数( U,V,W )。这反应了我们在每一步都用不同的输入执行同样的任务这一事实。这极大地减少了我们需要学习的参数的数量。
- 上图在每一步都有输出,但是根据任务来说这不是必须的。例如,当预测一个句子的情感的时候,我们只关心最终的输出,而不是每一个单词的情感。同样地,我们也不需要在每一步都有输入。RNN最大的特征就是它的隐藏状态,其捕捉了句子的某些信息。
WHAT CAN RNNS DO?
RNN在许多NLP任务上都取得了巨大的成功。在这一点上我要说明的是大多数用RNN的类型都是LSTM,LSTM可以比原始的RNN更好地捕捉长期依赖。但是不要担心,LSTM本质上和RNN一样,只不过是在隐藏层的计算方式不一样,我们会在后面的教程里讲解。下面是RNN在NLP上面的一些应用(不包含全部)
构建语言模型&生成文本
给定一个词语序列我们想要预测给定前一个词时每一个词的概率。语言模型可以让我们评价一个句子的可能性,这对于机器翻译来说是很重要的(因为概率越高的句子越正确).预测下一个词的副作用就是我们可以得到一个生成模型,这使得我们通过输出概率中采样生成新的文本。基于我们的训练数据,我们可以生成各种各样的东西。在语言建模中,我们的输入是一个词语序列(例如被编码为one-hot向量),我们的输出是预测的词语序列。当训练网络是,我们设置 ot=xt+1 , 因为我们想让 t 时刻的输出就是下一个单词。
关于语言模型与生成文本的相关论文:
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
MACHINE TRANSLATION
机器翻译
机器翻译和语言模模型的相似之处在于输入都是一个源语言(e.g.德语)的词语序列,我们想要的输出是目标语言(e.g.英语)的词语序列。关键的不同在于机器翻译的输出要在完成整个输入之后才开始生成,因为翻译句子的第一个单词可能需要整个输入序列的信息。
关于机器翻译的论文:
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
语言识别
给定来自声波的声学信号的输入序列,我们可以预测语音段的序列及其概率。
语言识别的论文
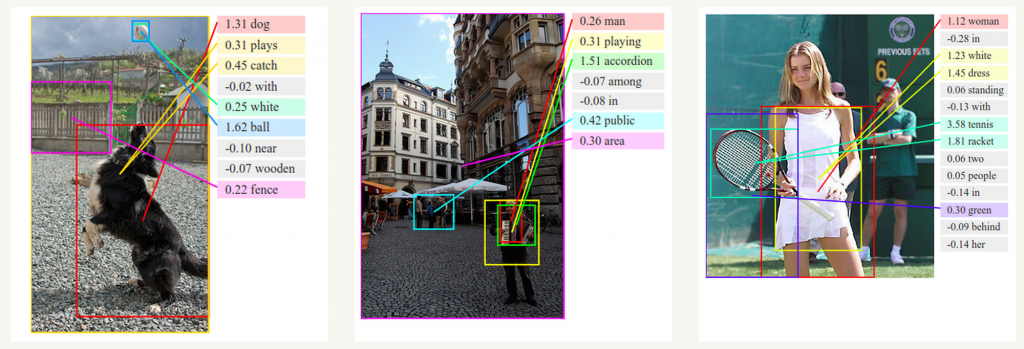
生成图像描述
和卷积神经网络一起,RNN被用来作模型的一部分以生成对未标注的图像的描述。这项工作是相当惊人的。组合模型甚至可以将生产的词语图像中找到的特征对齐。
训练RNN
训练RNN类似于训练传统的神经网络,我们也利用后向传播算法,但是有一点不同。因为网络中每一步的参数都相同,每一个输出的梯度不仅依赖于当前的时刻,也依赖于前面是时刻。例如,为了计算在 t=4时刻的梯度,我们需要反向传播前3个时刻并将梯度求和,这就是所谓的BPTT,不要担心,后面的博客对此会有详细的介绍。现在我们只需要知道一般的用BPTT训练的RNN会有长期依赖的困难(e.g. 相距很远的时刻之间的依赖性)。现在存在一些机制解决这些问题,某些RNN类型(比如说LSTM)就是专门用来解决这个问题的。
RNN 扩展
多年来,研究人员开发了更复杂的RNN类型来处理vanilla RNN模型的一些缺点。我们将在后面的文章中更详细地介绍这些内容,本部分作为简要概述,以便您熟悉模型的分类。
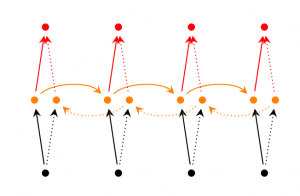
双向RNN是基于这样的想法,在t时刻的输入也许不仅仅依赖于序列中的前一个元素,可能也依赖于后面的元素。例如:为了预测序列中的一个缺失词,你也许想要查看左边和右边的上下文。双向RNN非常简单,它们只是堆叠在彼此顶部的两个RNN,然后基于两个RNN的隐藏状态计算输出。
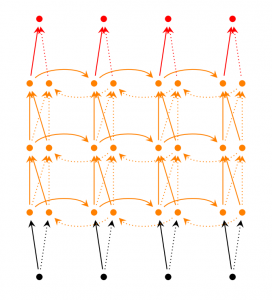
深度(双向)RNN和双向RNN类似,只是现在在每一个时刻都有了多层。实践当中这给了我们更高的学习能力(但同时我们也需要很多训练数据)。
LSTM 网络如今非常流行,上面我们已经简要介绍过LSTM,它和RNN没有本质的区别,但是它们两个用了不同的函数计算隐层的状态。LSTM中的记忆被称作细胞,你也可以吧它们当做黑匣子,它们用上一个时刻的状态
总结
我希望你对RNN是什么以及他们能做什么有一个基本的了解。在下一篇文章中,我们将使用Python和Theano实现我们的语言模型RNN的第一个版本。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









