







1、算法描述

2、Python代码实现
import numpy as np
from numpy.linalg import *
import matplotlib.pyplot as plt
import math
import random
def calculate_2Dgauss(mu,sigma,x):
dim=np.shape(sigma)[0]#计算维度
sigma_det=np.linalg.det(sigma)#计算|∑|
sigma_Inv= np.linalg.inv(sigma)#计算∑的逆
if sigma_det == 0:
sigma_det=np.linalg.det(sigma_Inv+np.eye(dim)*0.01)
sigma_Inv=np.linalg.inv(sigma_Inv+np.eye(dim)*0.01)
d1=(x-mu).T
d2=(x-mu)
return np.exp(-0.5 *np.dot(np.dot(d1,sigma_Inv),d2))/(pow(2 * math.pi, dim / 2) * pow(abs(sigma_det), 1 / 2))
def mix_gauss(dataset,k,times):
# 初始化
n = dataset.shape[0]#样本个数
dim = dataset.shape[1]#样本维度
p_mat = np.ones((n, k)) # 存储每个点在各个高斯上的概率的矩阵
time=0
##初始化 均值向量、混合比例、协方差矩阵
# mus = dataset[[5,21,26]]#西瓜书上的均值
mus = dataset[random.sample(range(1, len(dataset)), k)]
alphas = 0.3 * np.ones(k)
sigma = [0] * k
for i in range(k):
# 初始的协方差矩阵源自于原始数据的协方差矩阵,且每个簇的初始协方差矩阵相同
sigma[i] = np.cov(dataset.T)
# sigma[i] = np.array([[0.1,0],[0,0.1]])#西瓜书上的sigma设为[[0.1,0],[0,0.1]]
sigmas = np.array(sigma)
while time < times:
# E步
for i in range(n): # 遍历每一个数据
res = [alphas[j] * calculate_2Dgauss(mus[j], sigmas[j], dataset[i]) for j in range(k)]# 列表表达式
sumers = np.sum(res)
for w in range(k):
p_mat[i][w] = res[w] / sumers
# M步
for i in range(k):
sumline = np.sum(p_mat[:, i])
alphas[i] = sumline / n # 更新比例系数alpha
mus[i] = np.sum([p_mat[j][i] * dataset[j] for j in range(n)], axis=0) / sumline # 更新均值mus的值
xdiffs = dataset - mus[i]
sigmas[i] = (1 / sumline) * np.sum(
[p_mat[nn][i] * xdiffs[nn].reshape(dim, 1) * xdiffs[nn] for nn in range(n)],
axis=0)
time += 1
# 得到聚类结果
flag = np.argmax(p_mat, axis=1)
return flag
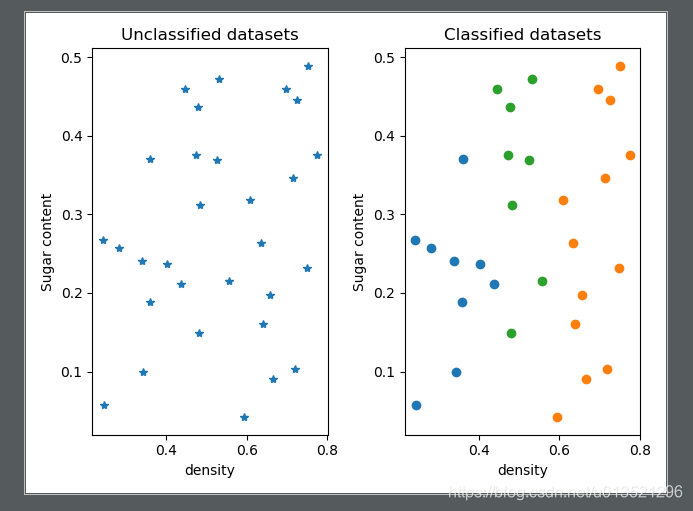
def draw_result(dataset,flag):
# 画出未分类前的数据
plt.subplot(121)
plt.plot(dataset[:, 0], dataset[:, 1], '*')
plt.title('Unclassified datasets')
plt.xlabel('density')
plt.ylabel('Sugar content')
# 画出聚类后的数据
plt.subplot(122)
C = []
for i in range(len(set(flag))):
C.append(dataset[(flag == i)])
for c in C:
plt.plot(c[:, 0], c[:, 1], 'o')
plt.title('Classified datasets')
plt.xlabel('density')
plt.ylabel('Sugar content')
plt.show()
#测试代码,使用西瓜书上4.0数据集,迭代50次
dataset=np.loadtxt('data.txt')
flag=mix_gauss(dataset,3,50)
draw_result(dataset,flag)
3、结果如下
4、参考资料
代码:https://blog.youkuaiyun.com/zhangwei15hh/article/details/78494026
有关协方差:https://blog.youkuaiyun.com/Mr_HHH/article/details/78490576
《机器学习》 周志华

















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









