






 本文分析了Hadoop集群NameNode频繁切换的问题,详细介绍了ZKFC进程与Zookeeper之间的交互机制,以及Zookeeper事务日志刷盘耗时异常导致的连接失败,最终定位到磁盘IO压力为根本原因,并提出了相应的解决方案。
本文分析了Hadoop集群NameNode频繁切换的问题,详细介绍了ZKFC进程与Zookeeper之间的交互机制,以及Zookeeper事务日志刷盘耗时异常导致的连接失败,最终定位到磁盘IO压力为根本原因,并提出了相应的解决方案。
一、背景介绍
hadoop1集群NameNode(NN)开启了高可用,方式为基于QJM,但最近出现频繁切换,导致一些连接方式为ip:port的服务出现异常。
二、问题定位
- NN高可用原理简介
-
- NN的高可用通过单独的进程实现:ZKFailoverController。
- 该进程运行在每一个NN上,对NN进行状态监测,当监测到NN状态异常时,借助ZooKeeper实现NN的主备切换。
- Active/Standby NN 所在机器上的ZKFC进程都会尝试创建/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 这个临时节点
- 创建成功的NN成为Active状态。
ZKFC进程可以看做zk 的一个客户端,其与server之间会话的有效性决定了临时节点的存在与否,也就决定了NN 的Active/Standby状态。
查看ZKFC的日志
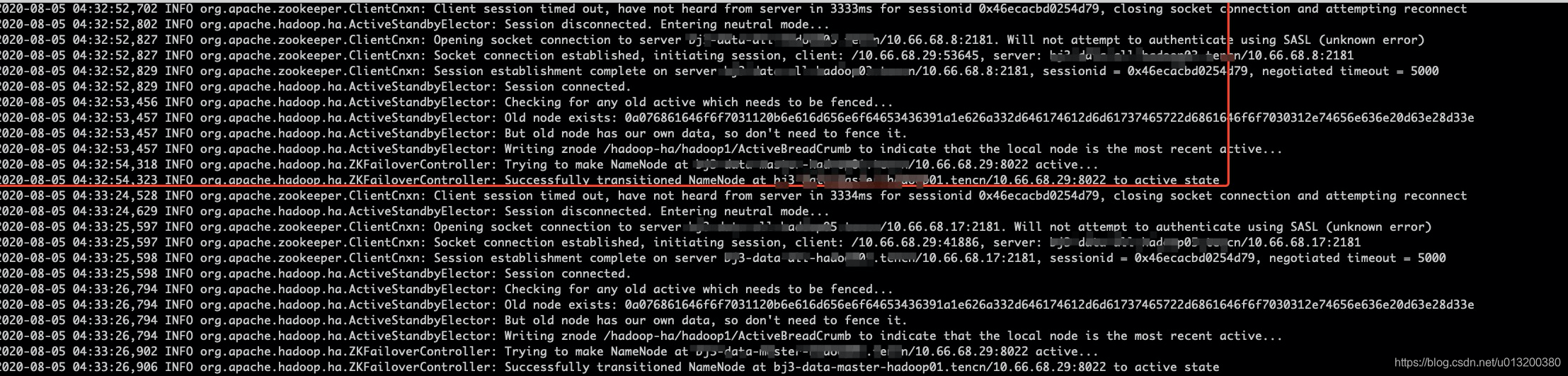
- 08-05 04:32:52:从该时刻起,ZKFC进程,可以看做zk客户端,出现与zk server 会话超时异常。默认情况下,zk client端会周期性向zk server发送心跳请求,发送间隔为sessionTimeout/3。sessionTimeout值后面会细说。
当客户端长时间未收到server端的心跳响应时,client端会认为当前连接的server出现异常,进而主动断开连接,从配置的连接列表中,重新选择一个server,再次连接。在会话过期内,如果可以重新连接,会话恢复,服务正常。
- 08-05 04:34:13: 重新连接无法成功,重试三次,依然无法连接,进程退出,信息如下图。
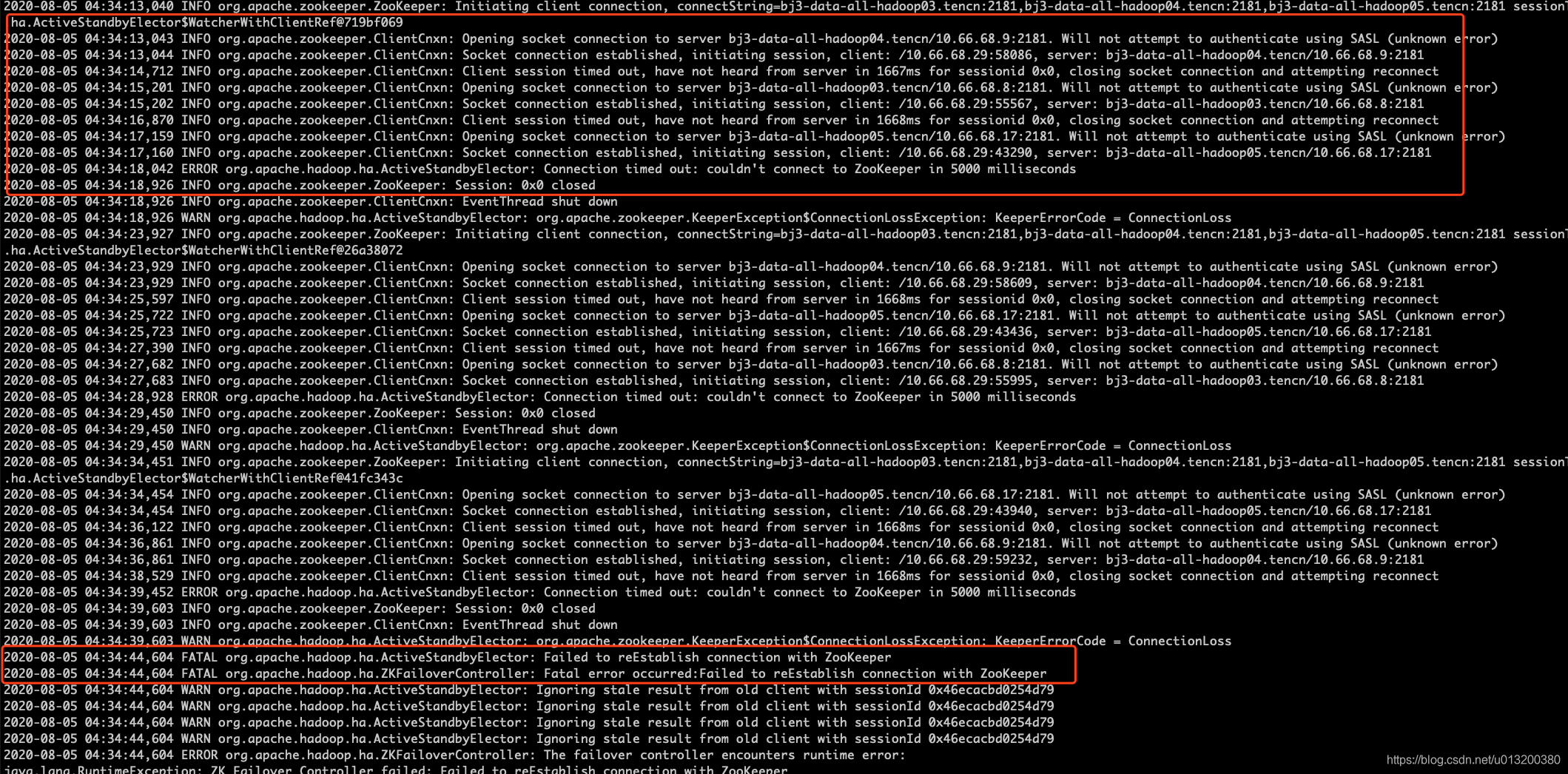
- 08-05 04:34:44 ZKFC进程退出。
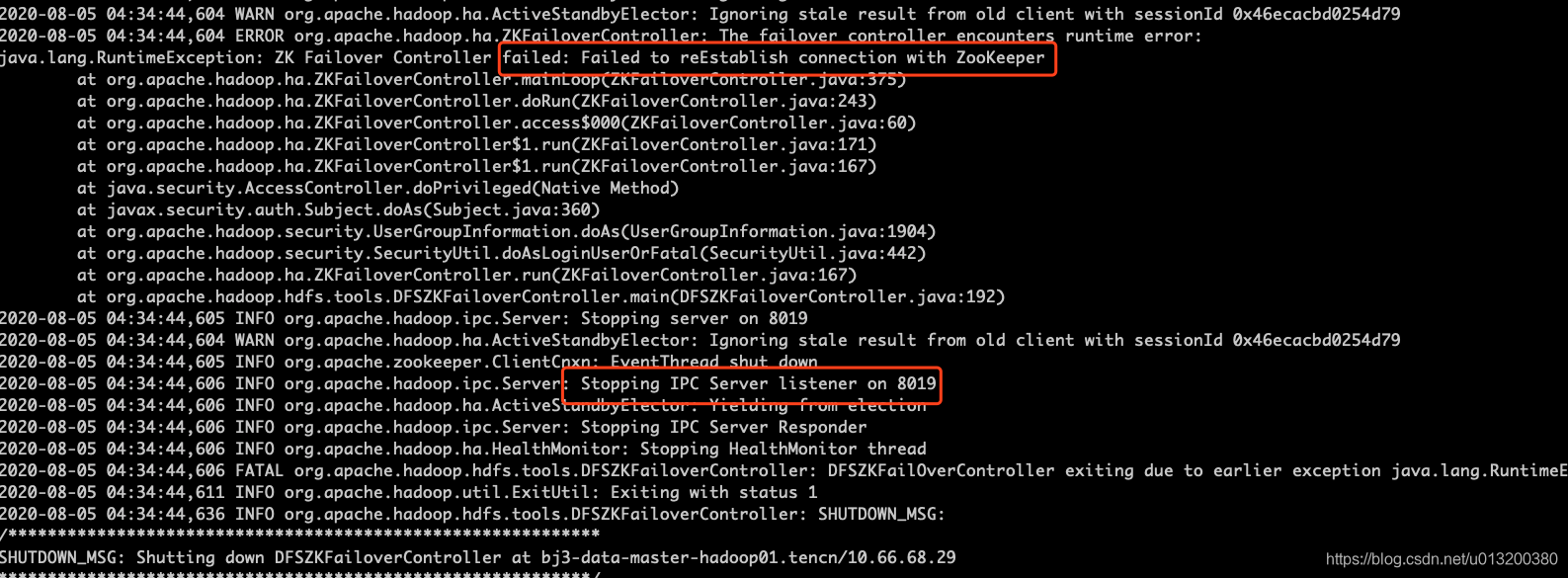
ZKFC本身是一个很轻量的进程,并且日志也显示,会话异常的原因是未收到zk server的心跳响应。因此可以确定这次切换不是ZKFC检测到NN本身状态出现问题,而是其依赖的zookeeper异常导致。这里顺便提一下,NN本身出现问题通常有以下两种情况:
- NN对ZKFC的状态监测无响应 SERVICE_NOT_RESPONDING,超过ha.health-monitor.rpc-timeout.ms(45s),ZKFC认为该NN异常
- NN磁盘空间不足,状态变为SERVICE_UNHEALTHY
查看zookeeper日志
我们去看问题时刻zk的运行日志,发现04:32:02开始,zk server端事务日志刷盘耗时严重。zk的每次更新,包括连接的建立,都会写到事务日志,然后刷盘,最后应用到内存

下图的日志信息显示,当zk server端要给客户端反馈的时候,发现连接已经关闭

仔细查看zk日志,在04:34出现若一次刷盘时间长达20+s:

至此,可以确认,zk事务日志的刷盘耗时异常,严重影响了对客户端的响应,导致ZKFC最终连接失败,标志其为Active的zk 临时节点随着会话的失效,自动删除,最终导致NN的切换。
解决方法
- 首先确认zk实例所在机器上运行着哪些进程
- zookeeper /data1
- JournalNode /data1
- Nodemanager /data1~/data4
- 分析各个磁盘IO压力
-
- /data1压力明显高于其他磁盘,利用率经常达到100%
- 其他磁盘平时IO利用率很低,在5%左右,但偶尔会达到80%,推测是当有YARN container调度到zk实例所在机器时,会对IO造成压力
- 04:30左右各个磁盘IO利用率均飙高
确定解决方案:
- 将JN editlog存储目录更改为单独的磁盘,如/data2: JN需要每次将editlog刷盘,其对磁盘的压力不小于zk,同时其刷盘的性能,也决定了NN对写入操作响应的时效性,只有多数JN写入成功,才认为写入成功,否则认为写入失败,退出Active状态,引发NN切换
- 停掉zk、JN实例所在机器上的YARN Nodemanager角色进程,避免container调度到这些机器,释放对磁盘的压力:通过观看日志,发现凌晨经常有spark任务发布,如果调度到这些机器,机器的4块盘io压力飙升非常明显
方案实施:
- 修改JN editlog目录:停止JN进程,cp 原目录到 /data2的相同目录,保持相同属性;修改配置,并下发配置;启动JN进程;一次操作,操作之间保持一定时间间隔
- 将zk实例机器从YARN Nodemanager集群中剔除:查看yarn.resourcemanager.nodes.exclude-path配置项,确认剔除机器文件,将三台机器写入到该文件中
- 任务运行完毕后,04 05 上的container自动停止,但03上依然存在,确认是推荐组一个应用,与开发沟通,重新发布任务后解决。
- 上述操作完毕后,03 04 05 三台机器各个磁盘IO压力监控如下图:
后续待改进:


















 4771
4771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









