




 本文探讨了场景分类中视觉不一致和标签混淆问题,提出多分辨率CNN网络和知识迁移技术,包括来自混淆矩阵和其它网络的知识,以提高模型泛化能力和解决类间差异小的难题。
本文探讨了场景分类中视觉不一致和标签混淆问题,提出多分辨率CNN网络和知识迁移技术,包括来自混淆矩阵和其它网络的知识,以提高模型泛化能力和解决类间差异小的难题。
转自:https://blog.youkuaiyun.com/tobale/article/details/80841622
场景分类文献阅读目前共有两篇:
(一)论文阅读: Scene recognition with CNNs: objects, scales and dataset bias
(二)论文阅读:Knowledge Guided Disambiguation for Large-Scale Scene Classification with Multi-Resolution CNNs
论文链接:Knowledge Guided Disambiguation for Large-Scale Scene Classification with Multi-Resolution CNNs
这篇文章的作者里面王利民,乔宇都是是场景分类领域的大牛。
1. Introduction
1.1 Issues
那这篇文章主要可以总结为这三大部分,首先,作者提出问题,对于场景分类任务,为什么数据集也有了,网络结构也有了,但是仍然达不到物体分类那么高的准确率呢?这是因为场景分类任务存在一个很大的问题,就是同一个类别的场景图片可能差异特别大,在文中作者称为视觉不一致(Visual inconsistence), 而不同类别间的场景图片可能差异特别小,作者称之为标签混淆(Label ambiguity)。
首先我们来看一下场景分类的面临的一个问题。就是同一个类别内场景差异大,不同类别间场景差异小。
1.1.1 Visual inconsistence

为什么数据集类内差异大会导致测试的结果不好。原因有两点:
1) 数据集毕竟只能覆盖一部分实际情况。数据集标注的同一类场景(同一个label)在现实场景中可以有许多不同的表现,但实际上,在数据集中只体现了许多场景的一部分。就拿这个厨房的例子来说,这一行的每一个图片都是厨房,但是他们的差异是很大的,厨房装修风格不同,家具摆放位置不同,场景中是否有人的存在,这些都是类内差异大的体现,除了这些图片之外,还有很多厨房的场景,就连不同国家的厨房也是差异很大的,那这个数据集总归是不能汇集所有的厨房场景的。如果测试集中出现的场景和训练集中出现过的场景还是有很大差异的,那对于训练出来的模型来说还是很难分类的。因此训练出来的模型对于测试集可能仍然效果不好。
2) 训练集的类内差异大,会导致训练困难,很难收敛,如果训练不好,训练出来的模型自然也就可能会效果不好。
但是如果训练成功了,那这么模型就可以有很强的泛化能力,即使测试集有大的类内差异,也可能会有比较好的分类结果。
1.1.2 Label ambiguity

对于类间差异小,和类内差异大刚好相反。随着数据集的不断扩增,场景类别数也在不管增加,那么不可避免的,一些类别之间可能存在图片的混叠。比如说棒球场地和体育馆棒球场这两个类别,在数据集中,这是两个不同的类别,但是他们其实是非常相似的。也就是说他们这两个类之间的差异很小。
因此我们需要更合适的网络结构和整体算法实施方案,来增强模型的泛化能力,适用于更多情况。
1.2 Contribuitions
那作者就提出解决办法,这篇文章有两个主要贡献:
1) 作者提出了一个多分辨率的cnn网络结构,来解决类内差异大的问题。多分辨率的网络结构的话,可以从多个层面捕捉场景图像中的内容和物体之间的空间位置关系和语义关系。那这个多分辨率的网络结构,主要由两个部分组成,一个是coarse resolution cnn,另一个是fine resolution cnn,就是一个是粗糙的,一个是精细的。Coarse resolution cnn提取的是场景图片得全局结构和大尺度的物体;fine resolution cnn提取出来的是局部细节信息和小尺度的物体。那他们俩呢正好是互补的。就可以提取场景图片中更全面的信息,详细的我们会在后面说道。
Multi-resolution CNN architecture = Coarse resolution CNNs + Fine resolution CNNs
2) 作者利用知识迁移的方法,优化类间差异小这个问题。作者提出了两种知识迁移的方法。
Two knowledge guided disambiguation techniques
① 来自混淆矩阵的知识迁移(Knowledge from the confusion matrix),另一个是来自其他网络的知识迁移。来自混淆矩阵的知识迁移是说在数据集的验证集上,计算一个混淆矩阵,这个混淆矩阵代表的是各个类之间的相似程度,从而把一些类间差异小的类合并为一个大的类。
② 来自其他模型的知识迁移(Knowledge of extra networks),他是用其他模型对同一张场景图片预测一个soft label,和主网络的预测结果一起用于优化参数。
2. Multi-resolution CNN architecture
2.1 Coarse resolution CNNs

那我们来详细的看一下多分辨率网络结构。那这篇文章提出来的所有网络结构的基本框架都是BN Inception网络结构。就是batch normalization和inception层的结合。使用Inception是因为inception模块有多个不同尺寸的卷积核,因此可以做不同尺度的特征提取。刚好适合我们的场景分类任务。
如上图所示的是原始的bn-inception网络结构,也是本文多尺度网络里的coarse resolution 部分。输入图片尺寸是224*224,首先通过两个卷积层池化层,这个时候feature map的大小是28*28。这么小的尺寸可以在后面的10个inception层处理得更快。那这10个inception层输出的feature map是7*7的,一共有1024个通道,最后用一个全局平均池化层把所有通道整合起来。那最后就是用一个1*1*1024的特征向量来表征这一张场景图片。
那这个coarse resolution的结构主要是提取图片的全局特征和大尺度的物体特征。那他就会丢失掉很多局部细节,而这些局部细节可能对于区分场景类别是很重要的。那我们就还需要一个网络结构来提取局部细节或者小尺度物体的特征,这样就引出了fine resolution cnn。
2.2 Fine resolution CNNs

Fine resolution和coarse resolution是比较相似的,一共有两个主要区别。一个主要区别是输入的图片尺寸更大,他的输入图片尺寸是336*336。另一个主要区别是网络更深,那他在inception的输出增加了两个卷积层,最后仍然是使用全局平均池化处理7*7的feature map。
2.3 Two resolution architectures
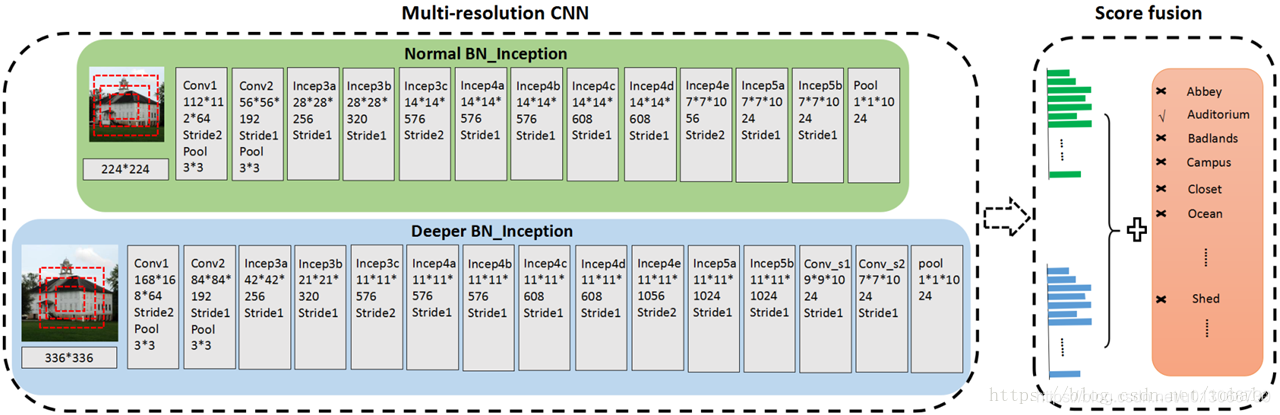
那这两个网络结构,一个coarse resolution,一个fine resolution,结合起来呢,就是一个两种分辨率的网络结构。他们分别描述了场景图片中不同尺度的物体和全局或者局部特征。因此他们两个输出的结果是互补的。最后两分辨率网络结构的输出是这两个网络结构取算术平均。
两分辨率的这个思想可以拓展到多分辨率。在实验中,他们也对四种分辨率做了实验。
那我们上一篇文章说的是多尺度网络,这个是多分辨率网络。乍一看他们俩是差不多的,但是还是有一些区别的。
多分辨率和多尺度的区别:一般地多尺度网络结构是这样的,输入的图片经过尺度变换,然后裁剪到适合网络结构的大小,送进去训练,对于不同尺度的图片,她的输入尺寸和网络结构都是不变的。而多分辨率网络结构输入的图片尺寸就是不一样的,那随着输入图片尺寸的增加,网络结构也会变化,层数会加深,提取的特征更加细节。那这种多分辨率的网络结构更加适合场景分类图片提取多层信息。
3. Two knowledge guided disambiguation techniques
3.1 Knowledge from confusion matrix
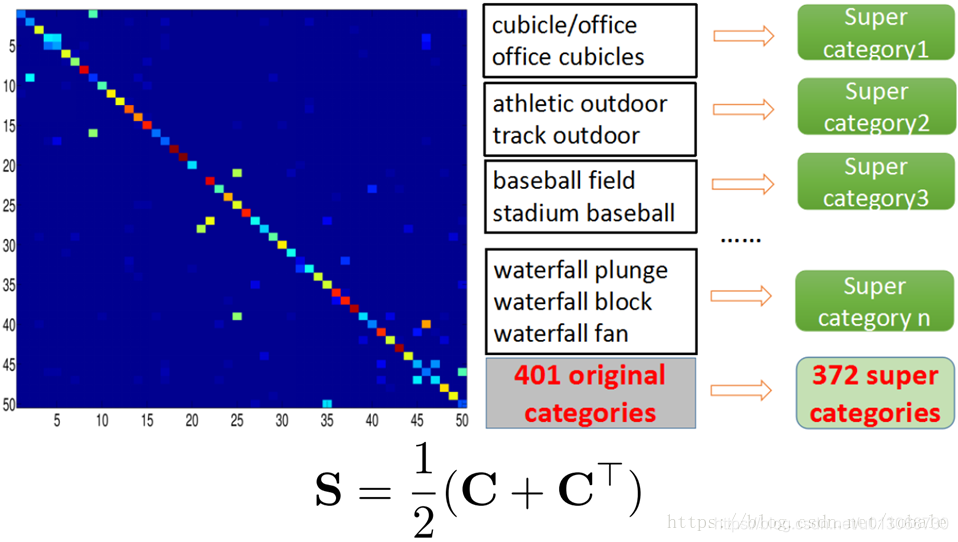
那么随着数据集的增大,许多不同场景类别中的图片可能会有重叠。这就会导致标签模糊,也就是我们说的类间差异小。那么作者就提出了两个简单有效的利用知识迁移的方法来解决类间差异小的问题。第一种方法呢,是使用混淆矩阵的知识迁移。
这个方法的思路是重组数据集,把相似的类别融合为一个大类。那融合不同类别的这个过程的关键点,是如何去衡量不同类别间的相似性。因为这是一个比较主观,而且工作量很大的事情,所以不能人工标注。
那来自混淆矩阵的知识迁移呢,是说我们首先用原始的数据集401类,训练一个模型出来。然后用这个模型,在验证集上做预测,把预测结果和数据集原始标签进行对比,计算混淆矩阵。那这个混淆矩阵中的每一个数值表示的是横纵坐标对应的两个类别之间的相似性。然后用下面这个公式计算相似度。那文章里面是取了几个不同的阈值τ,对相似度做判断。阈值τ不同,合并出来的类别数量也就不一样。如果两个类别的相似度大于这个阈值τ,就把他们俩合并为一类。那实验中发现τ取0.5的时候,效果最好,τ等于0.5的时候,是把整个数据集401类融合了为372类,再拿这372类重新训练。那在测试阶段,只对这372类做分类。
3.2 Knowledge from extra networks
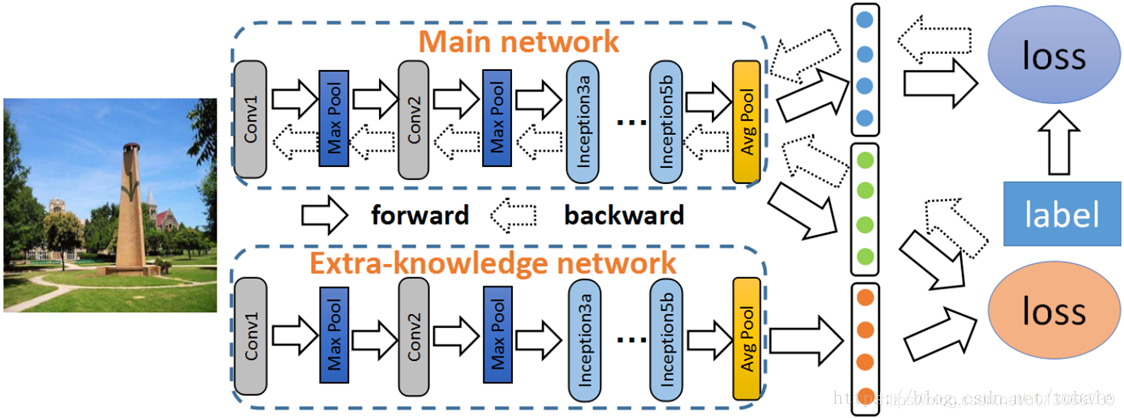
那么来自其他模型的知识迁移是说可以利用已经训练好的模型来辅助我的主网络训练,主网络就是我刚才说的多分辨率网络结构。那么这篇文章里作者使用了两种辅助网络,一个是imagenet上训练的模型,另一个是places上训练的模型。

那我们可以直接使用辅助网络的输出,作为场景图片的soft label。我们来看这组图片,这就是我们刚才说的体育馆棒球场和棒球场地这两类。左边这一列,hard label是原始数据集的标签。中间这一列是使用混淆矩阵的结果,把他们两类合并为一类,称为super category1。那第三列呢,是辅助网络的输出soft label。对于类间差异小的图像,它们可能存在相似的soft labels,但是不会完全相同。因此soft label可以用来区分相似的图像中的细小差别。
在训练过程中,主网络和辅助网络都会输出预测结果,那么我们通过最小化下面这个损失函数作为来目标函数。
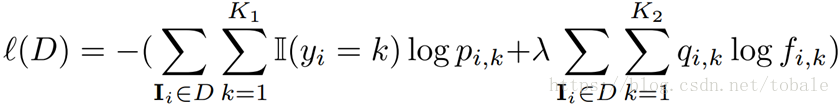
损失函数中左边这个就是正常的交叉熵损失,后边这个稍微有点区别,就是因为他使用的是soft-label,所以我们主要介绍下右边的损失。
首先看源码256_scene_kd_inception2_train_val.prototxt文件中的文件:
layer { name: "kd-loss" type: "SoftmaxWithCrossEntropyLoss" bottom: "s-fc-scale" bottom: "fc-scale" top: "kd-loss" propagate_down: true propagate_down: false loss_weight: 0.25 }从中我们可以将s-fc-scale看成预测结果(实际就是主网络的预测结果),就是右边公式的f,将fc-scale看成是标签(实际上就是额外知识网络的预测结果),就是右边公式的q。
接下来使用caffe-kd\src\caffe\layers\softmax_cross_entropy_loss_layer.cpp这个文件中的前向传播,其中outer_num_指的是batchsize,inner_num_指的特征图大小,这里是1,然后predict_prob_.shape(softmax_axis_)就是通道数,也就是类别数。
template <typename Dtype> void SoftmaxWithCrossEntropyLossLayer<Dtype>::Forward_cpu( const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { // The forward pass computes the softmax prob values. softmax_layer_->Forward(softmax_predict_bottom_vec_, softmax_predict_top_vec_); softmax_layer_->Forward(softmax_target_bottom_vec_, softmax_target_top_vec_); const Dtype* predict_prob_data = predict_prob_.cpu_data(); const Dtype* target_prob_data = target_prob_.cpu_data(); int dim = predict_prob_.count() / outer_num_; Dtype loss = 0; for (int i = 0; i < outer_num_; ++i) { for (int j = 0; j < inner_num_; ++j) { for (int k = 0; k < predict_prob_.shape(softmax_axis_); ++k) { loss -= target_prob_data[i * dim + k * inner_num_ + j] * log(std::max(predict_prob_data[i * dim + k * inner_num_ + j], Dtype(FLT_MIN))); } } } # 这里我感觉上是没有用的,因为后面什么地方都没用到过这个循环,但我不知道作者为什么要写。 for (int i = 0; i < outer_num_; ++i) { for (int j = 0; j < inner_num_; ++j) { for (int k = 0; k < predict_prob_.shape(softmax_axis_); ++k) { loss += target_prob_data[i * dim + k * inner_num_ + j] * log(std::max(target_prob_data[i * dim + k * inner_num_ + j], Dtype(FLT_MIN))); } } } if (normalize_) { top[0]->mutable_cpu_data()[0] = loss / (outer_num_ * inner_num_); } else { top[0]->mutable_cpu_data()[0] = loss / outer_num_; } if (top.size() == 2) { top[1]->ShareData(predict_prob_); } }然后再看一眼反向传播,需要自行求导,中间坐着注释了一段for循环的代码,其实这段是错误的求导,我自己就求导错了。修改过后的predict_prob_data-target_prob_data才是正确的求导。问题链接为:https://github.com/yjxiong/caffe/issues/171
template <typename Dtype> void SoftmaxWithCrossEntropyLossLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) { if (propagate_down[1]) { LOG(FATAL) << this->type() << " Layer cannot backpropagate to target score inputs."; } if (propagate_down[0]) { Dtype* bottom_diff = bottom[0]->mutable_cpu_diff(); const Dtype* predict_prob_data = predict_prob_.cpu_data(); const Dtype* target_prob_data = target_prob_.cpu_data(); // int dim = predict_prob_.count() / outer_num_; caffe_sub(predict_prob_.count(), predict_prob_data, target_prob_data, bottom_diff); // for (int i = 0; i < outer_num_; ++i) { // for (int j = 0; j < inner_num_; ++j) { // Dtype sum = 0; // for (int k = 0; k < bottom[0]->shape(softmax_axis_); ++k) { // sum += target_prob_data[i * dim + k * inner_num_ + j]; // } // for (int k = 0; k < bottom[0]->shape(softmax_axis_); ++k) { // bottom_diff[i * dim + k * inner_num_ + j] = // sum * predict_prob_data[i * dim + k * inner_num_ + j] // - target_prob_data[i * dim + k * inner_num_ + j]; // } // } // } // Scale gradient const Dtype loss_weight = top[0]->cpu_diff()[0]; if (normalize_) { caffe_scal(predict_prob_.count(), loss_weight / (outer_num_ * inner_num_), bottom_diff); } else { caffe_scal(predict_prob_.count(), loss_weight / outer_num_, bottom_diff); } } }求导公式具体如下:
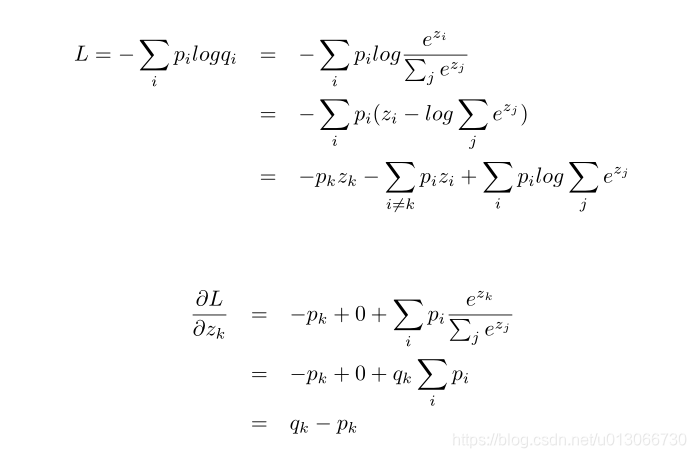
左边这一项是主网络的输出,D是训练数据集,y是ground truth标签,p是预测结果。右边这一项是辅助网络的输出,f是预测的soft label,q是对应的soft label的预测概率。中间的来木他用于权衡左右两项所占的权重。K分别是hard label和soft label的维度,就是分类的类别总数。
那么通过利用其他网络的知识迁移,可以有效提升模型的泛化能力,减小过拟合的影响。
4. Experiments
4.1 Evaluation on multi-resolution CNNs
最后呢,作者用实验结果说明效果。一共放出三组实验结果。第一组是在imagenet和places这两个数据及上的准确率,第二组是他参加places和lsun挑战赛的结果,2015年的places挑战赛他们获得了第二名,2016年的lsun挑战赛他们获得了第一名。第三组实验结果是他直接用他们的模型在其他几个场景分类数据集上做测试,都达到了最高的准确率。
4.1.1 Two-resolution CNNs
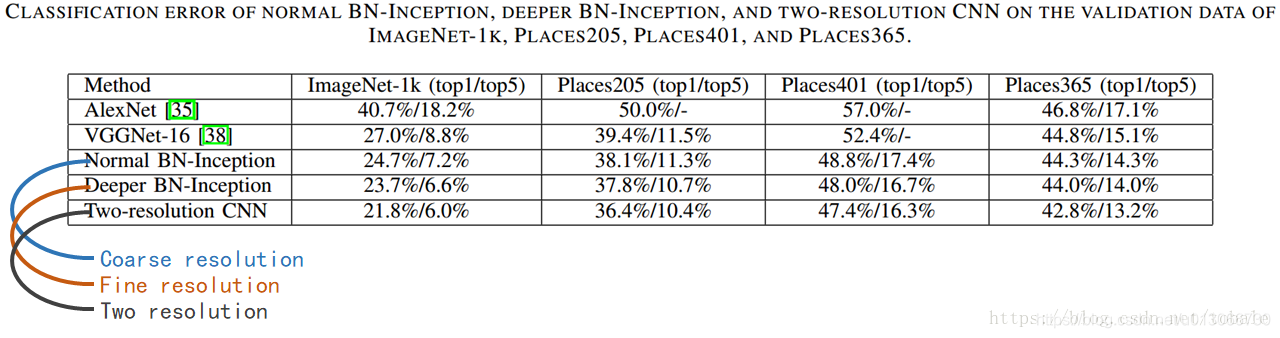
这个是两分辨率的实验结果。作者分别对coarse resolution , fine resolution 和两分辨率也就是coarse、fine结合的这三个模型做了评估。那他计算的是top1错误率和top5错误率。top1错误率就是我们平时说的分类错误,不是对就是错;top5错误率的话是说,取前五个最可能的结果,这五个结果全部都预测错了,才算错,只要有一个正确,就算对。
测试集的话分别是imagenet和places205,401,365。这后面的数字是说places数据集中的类别数。
那我们可以看到在这几个数据集上,fine resolution的错误率是比coarse resolution低的。这是因为fine resolution提取出来更丰富的视觉信息和局部细节。把两个分辨率模型结合起来,全局特征和局部细节互补,效果又比fine resolution更好一些。
4.1.2 Multi-resolution CNNs

多分辨率模型的话,作者是在四个分辨率上做的实验,分别是128,256,384和512这四个分辨率,另外,再把这四个分辨率的模型融合起来。我们可以看到随着输入图片的分辨率增大,不管是imagenet测试集还是places365测试集,错误率是不断降低的。那四分辨率融合后的模型错误率是最低的,相比刚才的两尺度模型的错误率更低。
4.2 Evaluation on knowledge guided disambiguation

然后是知识迁移的实验结果。这一部分使用的是coarse resolution作为主网络结构。
我们首先看来自混淆矩阵的知识迁移,是表格中的A3,和直接使用coarse resolution模型相比,错误率只降低了0.1%。
另外是来自其他模型的知识迁移,来自物体识别模型的知识迁移是A1,这个用的是在imagenet上预先训练好的模型。来自场景分类模型的知识迁移是A2,这个是在places上预先训练好的模型。我们可以看到A2的错误率,也就是用场景分类的知识迁移的模型,比用物体分类的知识迁移的错误率低了很多。

这张图是用fine resolution作为主网络结构。和上面的结论大致是一样的,只是相比于使用coarse resolution作为基本网络框架,错误率会更低很多。
4.3 Generalization analysis
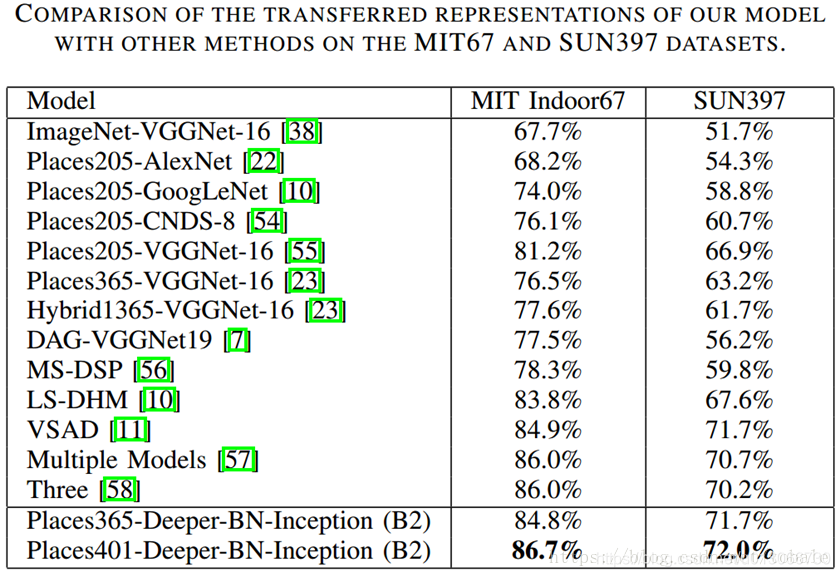
最后,作者说明了他提出来的网络结构的泛化能力很强。他直接在indoor67 和 sun397这两个数据集上做测试,发现和其他方法相比,准确率是最高的。
5. Failure case analysis

一般文章到这就结束了,后面就是conclusion了。但是这篇文章后面还有一小段,写的是他在实验过程中发现的一些失败例子的分析。比如说这个玩具店,他和模型的预测结果,像超市、宠物商店,从外面看起来都很相似。
另外还有会议室和教室,由于他们相似的布局,也很容易分错。所以说场景分类图片包含了复杂的视觉内容,有时候很难用单一标签来描述这一类图片,那么多标签的场景分类数据集和算法一定是未来场景分类发展的重点之一。从这些失败的例子,我们可以发现场景分类仍然是一个富有挑战性的问题。

















 1806
1806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









