







论文重点
采取的有效方式
(1)confidence小于0.5的都参与到loss的计算;
(2)classification如果不存在男人和女人这种情况的话,可以对每个输出使用sigmoid函数,假设有80类,那么输出就是80个数,对80个数的每个值都参与loss的计算,正确的与1比较(希望为1),不正确的与0比较(希望为0);
(3)输出多个尺度的,13*13,26*26,52*52的特征图,然后对每个特征图都使用anchor的操作;
(4)卷积层数变深了。
这几种方式无效
Anchor box x; y offset predictions. We tried using the normal anchor box prediction mechanism where you predict the x; y offset as a multiple of the box width or height using a linear activation. We found this formulation decreased model stability and didn’t work very well.
Linear x; y predictions instead of logistic. We tried using a linear activation to directly predict the x; y offset instead of the logistic activation. This led to a couple point drop in mAP.
Focal loss. We tried using focal loss. It dropped our mAP about 2 points. YOLOv3 may already be robust to the problem focal loss is trying to solve because it has separate objectness predictions and conditional class predictions. Thus for most examples there is no loss from the class predictions? Or something? We aren’t totally sure.
正负样本和损失函数
loss计算
公式不多说了,就说下理解(以下采用均方误差、交叉熵误差只是简单起见,还有些版本选择其他的误差计算,本文重点在正负样本的选择):
如果某网格的某个边框负责预测该物体(正样本):
- 对tx ty求均方误差
- 对tw th求均方误差
- 对80类分类结果求二类交叉熵误差
- 对置信度C计算二类交叉熵误差(C期望值=1)
其余不负责预测该物体的边框,且边框和真实值IOU<阈值(背景、负样本)
- 只对置信度C计算二分类交叉熵误差(C期望值=0)
其余既不负责预测物体,且IOU较大的边框不参与loss计算
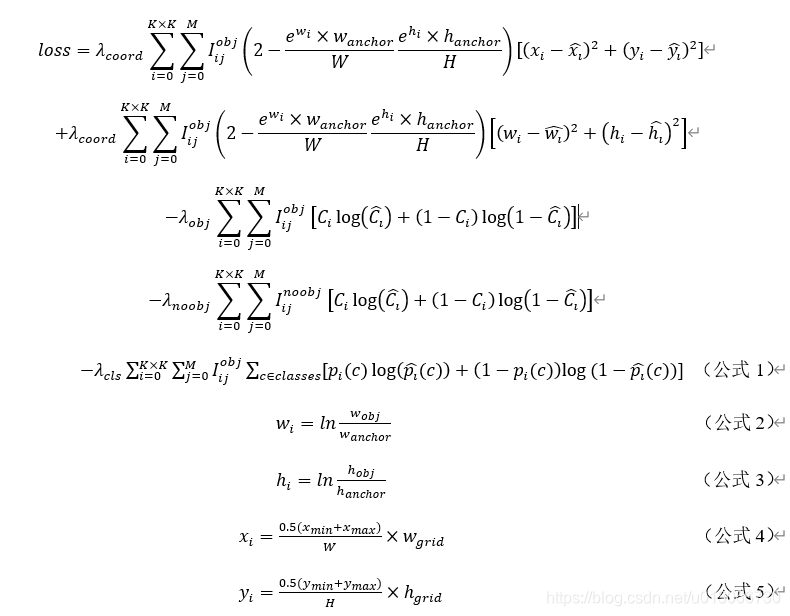
正负样本
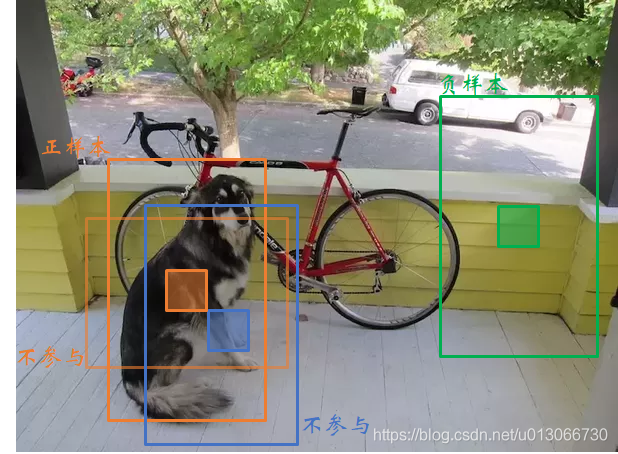
loss计算中,“负责预测目标”(即正样本)和背景(即负样本),以及不参与计算loss的部分是怎么选择的:
正样本的选择:
首先计算目标中心点落在哪个grid上,然后计算这个grid的9个先验框(anchor)和目标真实位置的IOU值(直接计算,不考虑二者的中心位置),取IOU值最大的先验框和目标匹配。于是,找到的 该grid中的 该anchor 负责预测这个目标,其余的网格、anchor都不负责。
负样本的选择:
计算各个先验框和所有的目标ground truth之间的IOU,如果某先验框和图像中所有物体最大的IOU都小于阈值(一般0.5),那么就认为该先验框不含目标,记作负样本,其置信度应当为0
不参与计算部分
这部分虽然不负责预测对象,但IOU较大,可以认为包含了目标的一部分,不可简单当作负样本,所以这部分不参与误差计算。
综上,如下图所示:
参考
https://blog.youkuaiyun.com/qq_42800654/article/details/106428547


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









