 Flink HDFS 数据读取机制
Flink HDFS 数据读取机制





 本文解析了Apache Flink如何从HDFS读取数据的详细流程,包括DataSource组件如何根据并行度生成inputSplits,以及这些splits如何在任务执行时被分配给DataSourceTask,重点关注了数据本地性和split大小的计算。
本文解析了Apache Flink如何从HDFS读取数据的详细流程,包括DataSource组件如何根据并行度生成inputSplits,以及这些splits如何在任务执行时被分配给DataSourceTask,重点关注了数据本地性和split大小的计算。
Flink版本:1.4.2
目的:本文主要是了解Flink中DataSource是如何从HDFS中读取数据的。
梳理一下大致流程:
在JobManager处,通过提交得来的JobGraph生成ExecutionGraph时,会将JobGraph中的每个JobVertex都转换成ExecutionJobVertex(注意ExecutionJobVertex和ExecutionVertex的区别,ExecutionJobVertex是和JobVertex一一对应的)。
代码流程:
JobManager.scala–>
ExecutionGraphBuilder.buildGraph()–>
ExecutionGraph.attachJobGraph()–>
对每个JobVertex都初始化一个ExecutionJobVertex,如果初始化的是DataSource节点,则会根据Source类型和并行度多少来生成inputSplits[],并将inputSplits[]交于给slitAssigner–>
DataSourceTask真正执行的时候,会调用getInputSplit[]方法,该方法发送消息给JobManager–>
JobManager接受消息,找到对应的ExecutionJobVertex中的slitAssigner,由slitAssigner分配一个split给DataSourceTask。
详细跟踪:
在ExecutionJobVertex的初始化过程中,会调用以下代码:
try {
@SuppressWarnings("unchecked")
//存储了数据源的相关信息
InputSplitSource<InputSplit> splitSource = (InputSplitSource<InputSplit>) jobVertex.getInputSplitSource();
if (splitSource != null) {
Thread currentThread = Thread.currentThread();
ClassLoader oldContextClassLoader = currentThread.getContextClassLoader();
currentThread.setContextClassLoader(graph.getUserClassLoader());
try {
//切分成了多少数据块,inputSplits是一个InputSplit[]
inputSplits = splitSource.createInputSplits(numTaskVertices);
if (inputSplits != null) {
//将来用于给真正运行的DataSourceTask分配数据块的
splitAssigner = splitSource.getInputSplitAssigner(inputSplits);
}
} finally {
currentThread.setContextClassLoader(oldContextClassLoader);
}
}
else {
inputSplits = null;
}
}
catch (Throwable t) {
throw new JobException("Creating the input splits caused an error: " + t.getMessage(), t);
}
}
注意代码中获取的splitSource,它存储了文件的一些基本信息,注意这个splitSource并不是每个算子都能获取到,只有(存疑?)Source节点会得到splitSource,其他算子获取到的一般是null。splitSource是存储在jobVertex中的,其实现了InputSplitSource接口。当我们通过代码:
env.readTextFile(hdfs://master:9000/file)
来读取文件的时候,实际的形式是TextInputFormat,其他形式(如csvInputFormat)应该也是类似的,继承图如下所示:
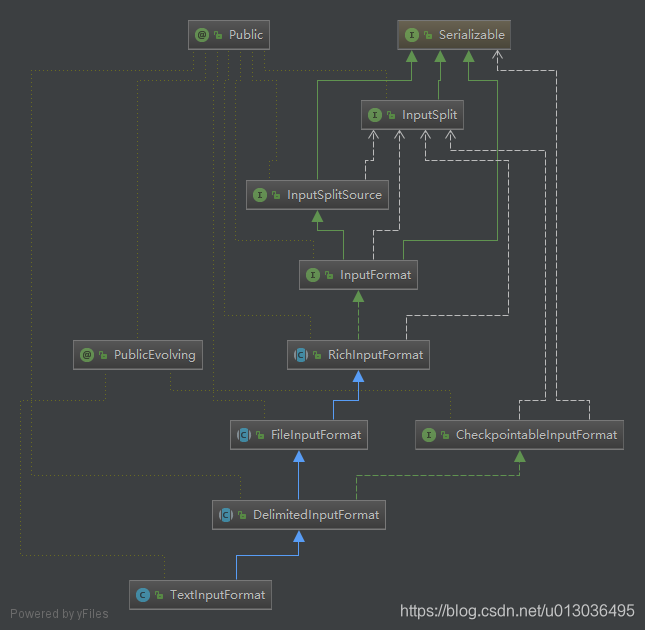
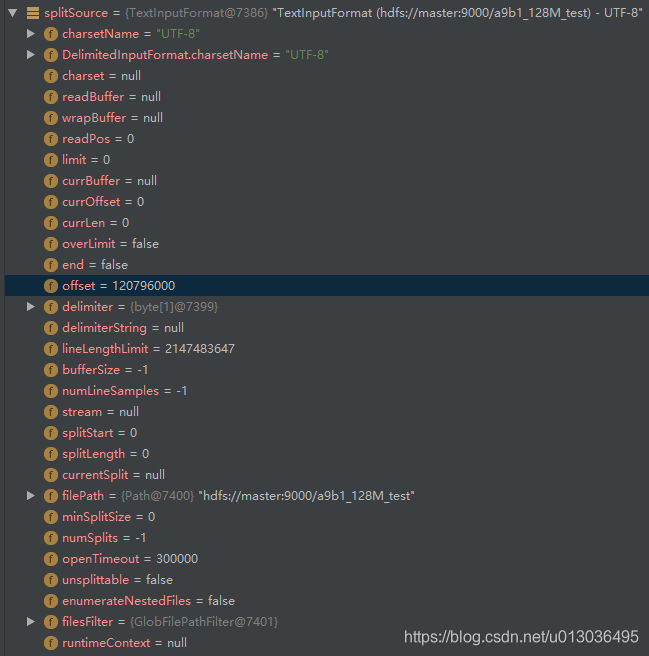
调试得到的splitSource信息如下图所示,有文件的大小、路径等信息:
splitSource是通过get方法得到的,那么它是在哪初始化的呢?其实是在ExecutionGraphBuilder类中,也就是调用ExecutionGraph.attachJobGraph()之前,每个JobVertex会通过vertex.initializeOnMaster(classLoader)进行初始化。如果是Source节点则会调用InputFormatVertex.initializeOnMaster()对其进行初始化。
这下就弄明白了为什么只有Source节点会得到splitSource信息了,归根结底是因为在调用Source节点真正的类型是InputFormatVertex,通过InputFormatVertex.initializeOnMaster(classLoader)方法对splitSource进行了初始化。
接下来重点分析inputSplits = splitSource.createInputSplits(numTaskVertices);
inputSplits是ExecutionJobVertex中的一个属性,其类型是InputSplit[]。其中存储了最终SourceTask将获取的各个数据的split。splitSource.createInputSplits(numTaskVertices)中的numTaskVertices就是Source的并行度了,接下来看一下createInputSplits的源码(只贴了部分):
//之前得到了文件系统,文件是否可以切分的信息
//总文件大小除以Source的并行度,用于后续决定最后的每个split的大小
final long maxSplitSize = totalLength / minNumSplits + (totalLength % minNumSplits == 0 ? 0 : 1);
// now that we have the files, generate the splits
int splitNum = 0;
for (final FileStatus file : files) {
final long len = file.getLen();//得到文件的总大小
final long blockSize = file.getBlockSize();//得到每个HDFS分块的大小
final long minSplitSize;//这个默认是0
if (this.minSplitSize <= blockSize) {
minSplitSize = this.minSplitSize;
}
else {
if (LOG.isWarnEnabled()) {
LOG.warn("Minimal split size of " + this.minSplitSize + " is larger than the block size of " +
blockSize + ". Decreasing minimal split size to block size.");
}
minSplitSize = blockSize;
}
//计算Flink中分块的大小,可以看出这里是不能超过HDFS分块大小的
final long splitSize = Math.max(minSplitSize, Math.min(maxSplitSize, blockSize));
final long halfSplit = splitSize >>> 1;
//每个分块的最大大小是splitSize*1.1
final long maxBytesForLastSplit = (long) (splitSize * MAX_SPLIT_SIZE_DISCREPANCY);
//之后的逻辑就是根据Flink中的分块大小来构造inputSplits了
if (len > 0) {
//这里可以得到HDFS中各个分块的信息
// get the block locations and make sure they are in order with respect to their offset
final BlockLocation[] blocks = fs.getFileBlockLocations(file, 0, len);
Arrays.sort(blocks);
long bytesUnassigned = len;
long position = 0;
int blockIndex = 0;
while (bytesUnassigned > maxBytesForLastSplit) {
// get the block containing the majority of the data
blockIndex = getBlockIndexForPosition(blocks, position, halfSplit, blockIndex);
// create a new split
FileInputSplit fis = new FileInputSplit(splitNum++, file.getPath(), position, splitSize,
blocks[blockIndex].getHosts());
inputSplits.add(fis);
// adjust the positions
position += splitSize;
bytesUnassigned -= splitSize;
}
// assign the last split
if (bytesUnassigned > 0) {
blockIndex = getBlockIndexForPosition(blocks, position, halfSplit, blockIndex);
final FileInputSplit fis = new FileInputSplit(splitNum++, file.getPath(), position,
bytesUnassigned, blocks[blockIndex].getHosts());
inputSplits.add(fis);
}
} else {
// special case with a file of zero bytes size
final BlockLocation[] blocks = fs.getFileBlockLocations(file, 0, 0);
String[] hosts;
if (blocks.length > 0) {
hosts = blocks[0].getHosts();
} else {
hosts = new String[0];
}
final FileInputSplit fis = new FileInputSplit(splitNum++, file.getPath(), 0, 0, hosts);
inputSplits.add(fis);
}
}
源码中会得到文件系统(这里会得到HDFS),和文件的总大小。然后考虑了输入文件时文件夹,输入文件不可切分等情况,然后根据HDFS的分块(block)大小,文件总大小和Source的并行度来计算每个split的大小,每个split会存储对应的HDFS的block信息,例如block在哪个host上。注意:每个split的大小是不能超过HDFS中分块(block)的大小的。得到每个split的大小后就可以根据HDFS的各个分块信息来构造inputSplits了。
举例说明:文件A大小为256M,存储在HDFS上,HDFS的分块大小为64M,则A文件会被分割成4个block,每个block都是64M。
当我们使用flink读取文件A的时候,如果设置的并行度为2,则源码中:
final long splitSize = Math.max(minSplitSize, Math.min(maxSplitSize, blockSize));
minSplitSize默认是0,maxSplitSize = 256 / 2 = 128M(总大小/并行度),blockSize=64M,算出来的splitSize就是64M。
如果我们读取文件A的时候,并行度设置为8:
minSplitSize默认是0,maxSplitSize = 256 / 8 = 32M(总大小/并行度),blockSize=64M,算出来的splitSize就是32M,相当于一个HDFS中的block(64M)会切分成Flink中的两个split(32M),当然,不是整数倍时,里面也有相应的逻辑来处理。
得到inputSplits后,会根据它来初始化ExecutionJobVertex中的splitAssigner,最终SourceTask执行的时候,就会请求来得到一个split。具体流程:
DataSourceTask.invoke()执行的时候,会调用getInputSplits()方法,该方法会发送消息给JobManager,JobManager中会调用RequestNextInputSplit()方法,通过对应的ExecutionJobVertex中的splitAssigner来分配split给DataSourceTask。
在splitAssigner对DataSourceTask进行split分配的时候,会考虑数据本地性,优先分配在其本地的数据给DataSourceTask,如果没有本地的则会分配一个远程的。该部分代码在LocatableInputSplitAssigner.getNextInputSplit()中可以看到。

















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









