






转自好友的公众号:https://mp.weixin.qq.com/s/7LN8A8JkVoALf3FStBaGHg)
jmeter 开源的java开发的一个压力测试工具。
jmeter查看结果树乱码:
1、在jmeter的bin目录下找到jmeter.properties这个文件
添加上 sampleresult.default.encoding=utf-8
2、重启jmeter
jmeter body data里面有乱码怎么解决
1、在jmeter的bin目录下找到jmeter.properties这个文件
添加上 jsyntaxtextarea.font.family=Hack
2、重启jmeter
一.添加线程组:
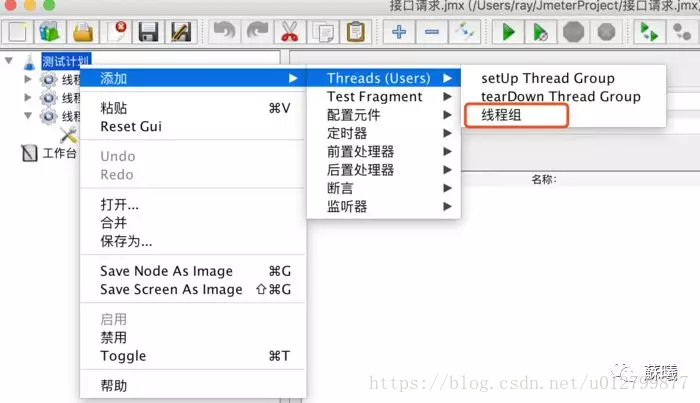
二.用户定义的变量
线程组>添加>配置元件>用户定义的变量
注:填写正确的值,然后通过名称进行调用。调用格式为: I P ! [ 在 这 里 插 入 图 片 描 述 ] ( h t t p s : / / i m g − b l o g . c s d n . n e t / 20181015143746439 ? w a t e r m a r k / 2 / t e x t / a H R 0 c H M 6 L y 9 i b G 9 n L m N z Z G 4 u b m V 0 L 3 U w M T I 3 O T k 4 N z c = / f o n t / 5 a 6 L 5 L 2 T / f o n t s i z e / 400 / f i l l / I 0 J B Q k F C M A = = / d i s s o l v e / 70 ) 注 : 填 写 正 确 的 值 , 然 后 通 过 名 称 进 行 调 用 。 调 用 格 式 为 : {IP}  注:填写正确的值,然后通过名称进行调用。调用格式为: IP注:填写正确的值,然后通过名称进行调用。调用格式为:{IP}
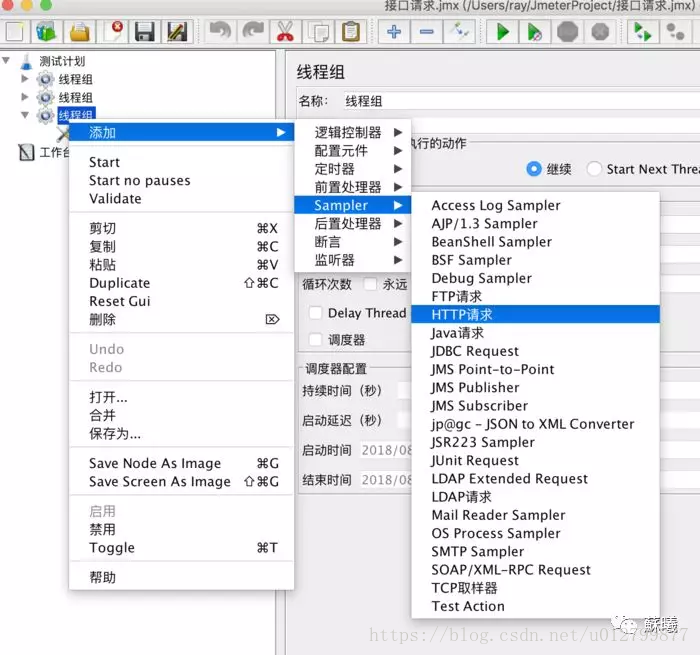
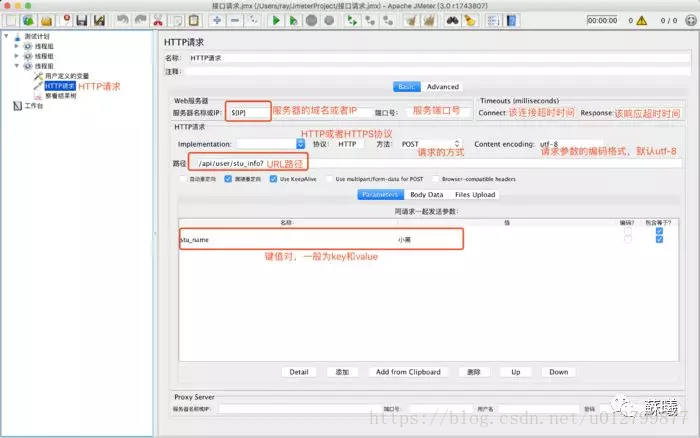
三.HTTP请求:
线程组>添加>Sampler>HTTP请求
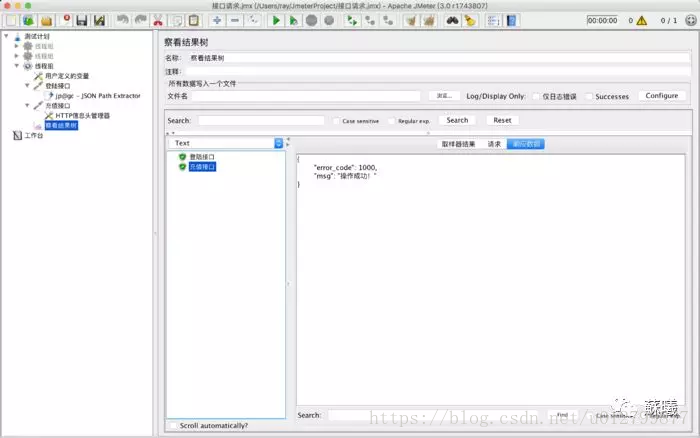
四.察看结果树
线程组>添加>监听器>察看结果树
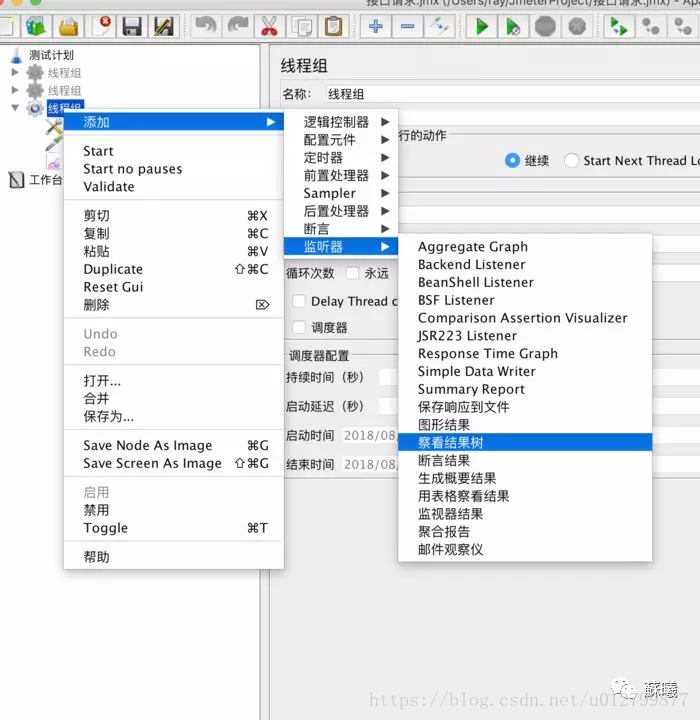
请求数据:HTTP请求的相关信息,有raw和HTTP两种类型展示。
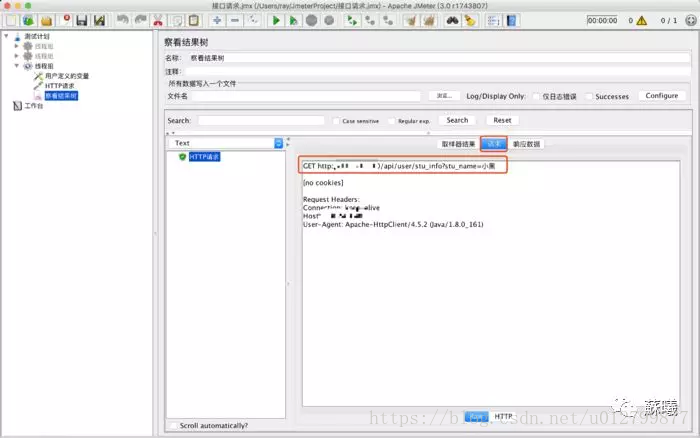
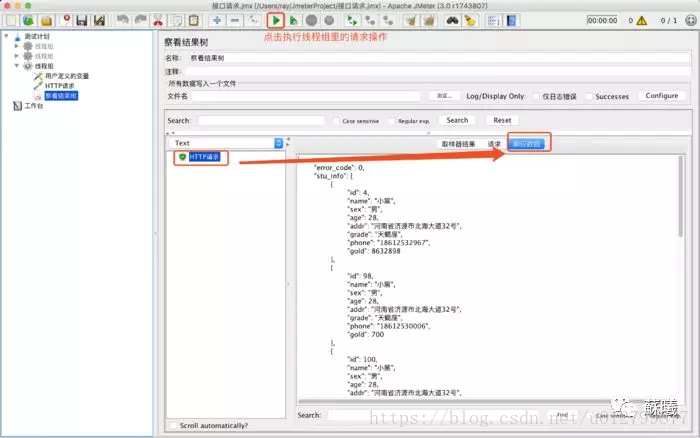
响应数据:HTTP请求所得到的响应数据。响应数据有正确和错误。
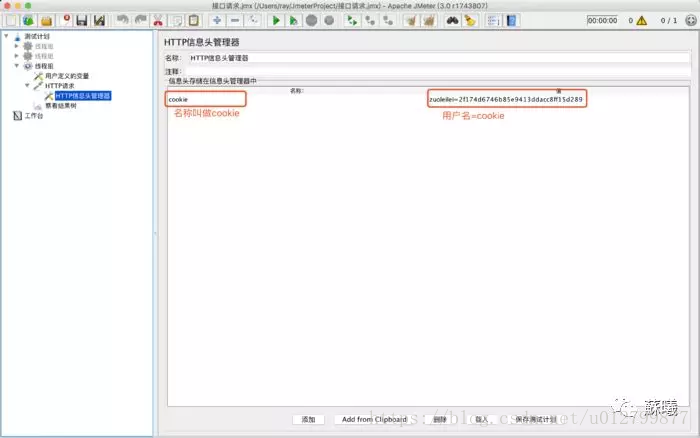
五.HTTP信息头管理器:
HTTP信息头管理器可以添加到线程组下,也可以添加到HTTP请求下。一般我们视情况而定。
六.jp@gc - JSON Path Extractor插件
Jmeter中,可以使用jp@gc - JSON Path Extractor插件来提取响应结果。接口响应结果,通常为HTML、JSON格式的数据,对于HTML的响应结果的提取,可以通过正则表达式,也可以通过XPath 来提取。
对于JSON格式的数据,可以通过正则表达式、JSON Extractor插件、BeanShell 来提取。
本次说下如何通过JSON Extractor 插件来提取JSON响应结果。
比如说,接口返回的JSON响应结果如下格式,如何获取登陆接口的sign呢
{
"error_code": 0,
"login_info": {
"login_time": "20180813235609",
"sign": "2f174d6746b85e9413ddacc8ff15d289",
"userId": 8059
}
}
具体操作步骤:
a、需要下载插件,下载地址为:https://jmeter-plugins.org/wiki/JSONPathExtractor/ 下载后解压以后将lib和lib/ext中的jar包放到安装目录对应位置,重启即可。
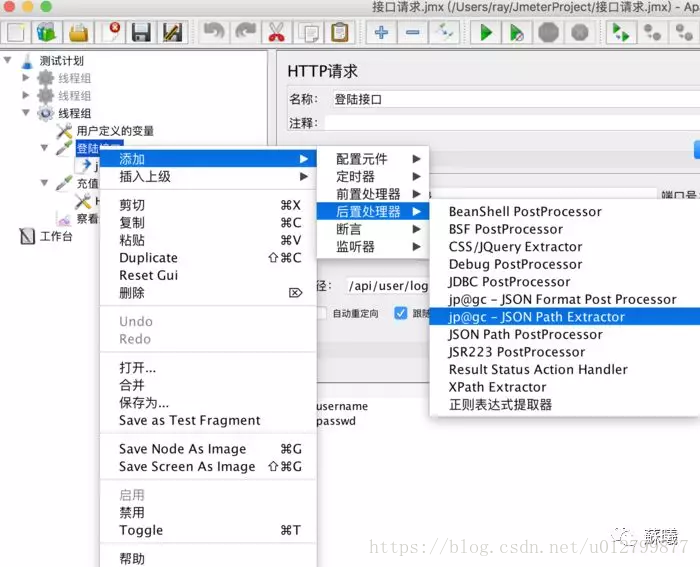
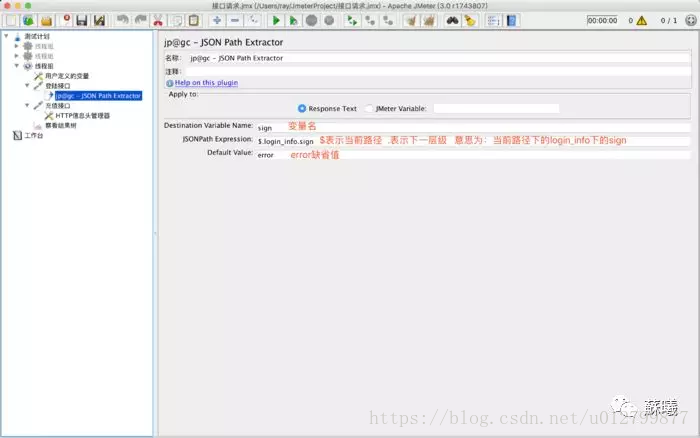
b.添加一个jp@gc - JSON Path Extractor,设置对应的参数
备注: JSON中 data 是一个对象数组, data[0] 代表取的是第一个对象数组,data[*] 代表取全部。
因该响应只有一条数据,可以忽略。若有多条记录,则需要固定取值。如:$.login_inf[0].sign 意思为取第一组json里面那个sign值。
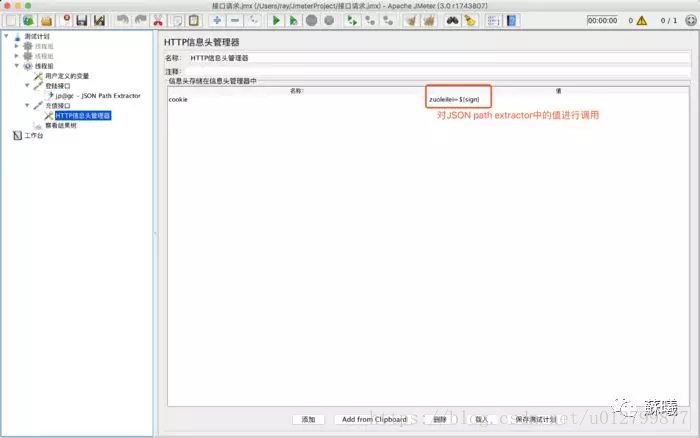
c.调用jp@gc - JSON Path Extractor
七.参数化的几种方式:
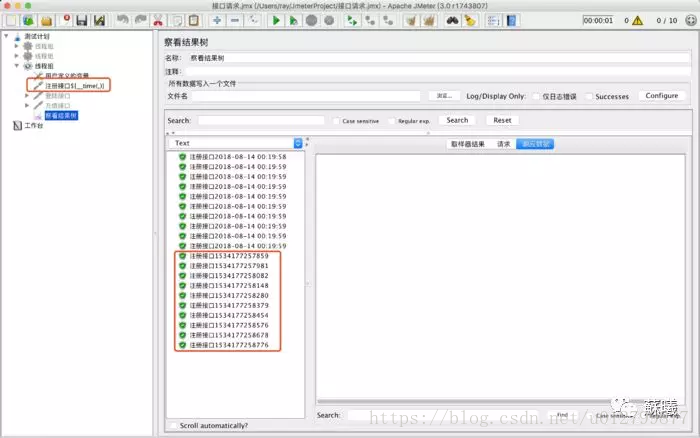
a. 使用时间戳${__time(,)}
b.使用当前时间${__time(YYYYMMdd-HH:mm:ss,)}
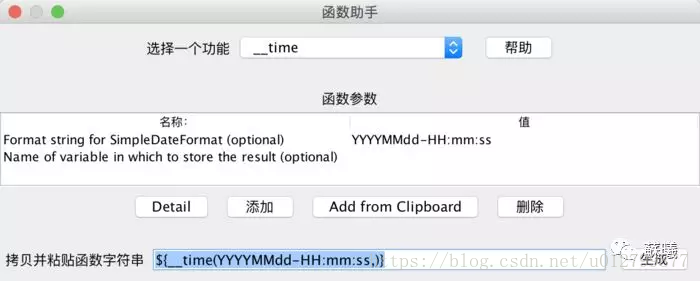
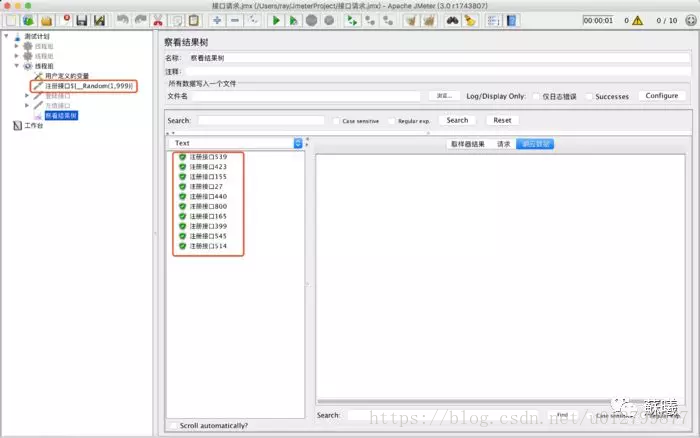
c.随机数${__Random(,)}
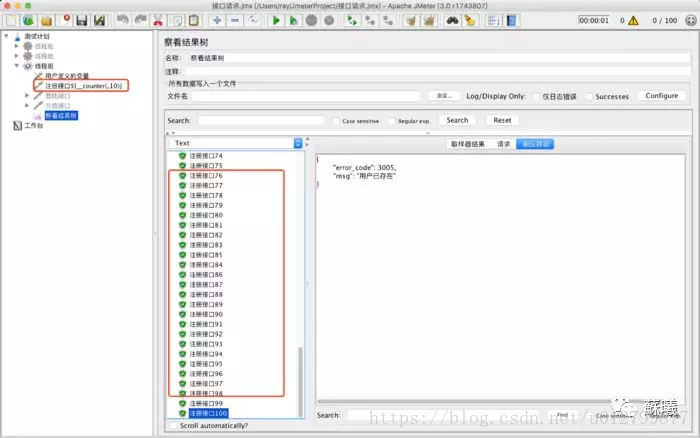
d.按顺序的${__counter(,)}
注:${__counter(,)}的初始值默认从1开始,设置起始值无效,设置结束值也无效。可以根据线程数控制。
如:设置100线程数,{__counter(,10)}结束值为10,执行结果为100条。
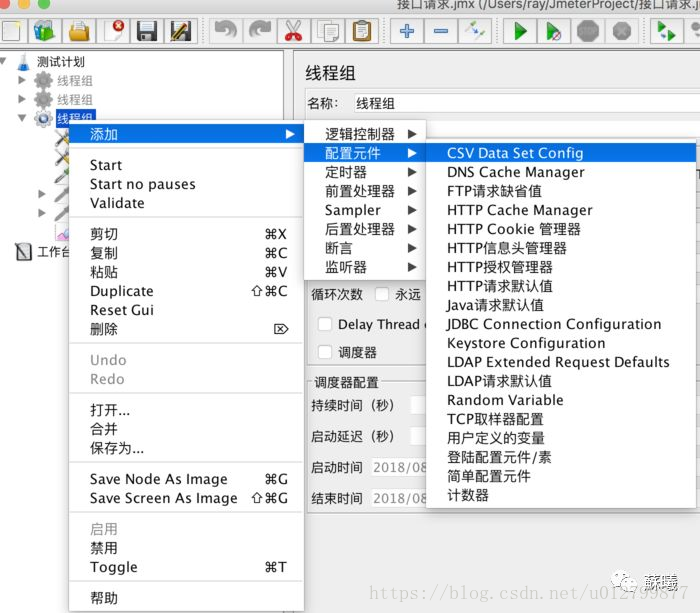
e.通过文件进行参数化
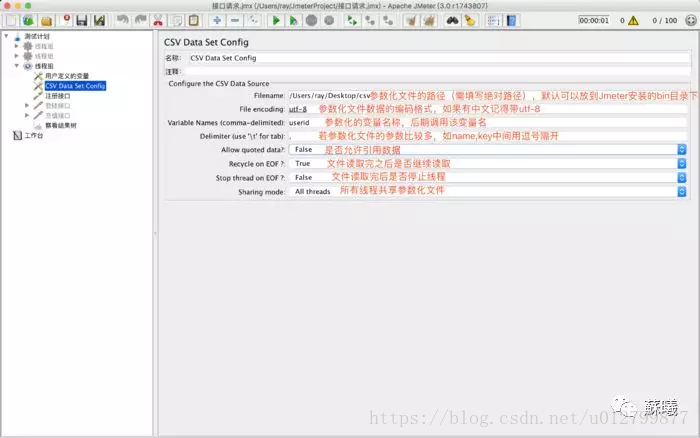
首先,添加>配置元件>CSV Data Set Config
2.设置CSV Data Set Config的各项值
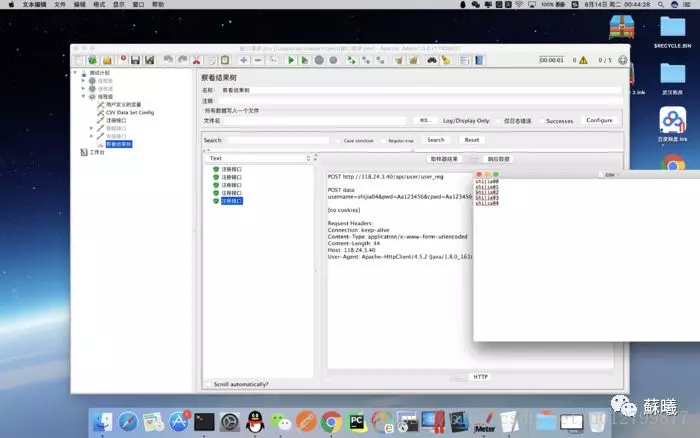
如图,验证参数化正确

















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









