




 博客对比了ABAP中使用DELETE ADJACENT DUPLICATES和SELECT DISTINCT删除重复项的效率。普遍认为SELECT DISTINCT可能较慢,因为它涉及排序。然而,通过实际测试,发现在处理CDHDR表的数据时,两者在打开和处理SQL的速度上相差不大,SELECT DISTINCT在获取数据表速度上稍快,而DELETE ADJACENT DUPLICATES在处理已获取数据(包含排序)时更快。建议根据具体需求和环境进行选择。
博客对比了ABAP中使用DELETE ADJACENT DUPLICATES和SELECT DISTINCT删除重复项的效率。普遍认为SELECT DISTINCT可能较慢,因为它涉及排序。然而,通过实际测试,发现在处理CDHDR表的数据时,两者在打开和处理SQL的速度上相差不大,SELECT DISTINCT在获取数据表速度上稍快,而DELETE ADJACENT DUPLICATES在处理已获取数据(包含排序)时更快。建议根据具体需求和环境进行选择。
在网上看到很多优化文章说到,使用 DELETE ADJACENT DUPLICATES 比 SELECT DISTINCT要快,一般不推荐使用 SELECT DISTINCT。
因为都理解为SELECT DISTINCT执行的时候,需要先排序数据库数据,就感觉会比ABAP程序处理会慢。
个人一直认为,数据库取数速度取决于服务器性能,至于性能一般的服务器,感觉还是SELECT DISTINCT比较快。
则做一遍测试,各位可以自己测试再选择使用。
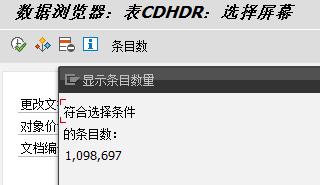
使用表为:CDHDR
数据量为:
代码如下:
DATA:lt_cdhdr TYPE TABLE OF cdhdr,
lt_cdhdr_01 TYPE TABLE OF cdhdr.
DATA: t1 TYPE p DECIMALS 3,
t2 TYPE p DECIMALS 3,
time_01 TYPE p DECIMALS 3,
time_02 TYPE p DECIMALS 3.
" 先把所有数据找出来,再删除重复项
CLEAR:t1,t2.
GET RUN TIME FIELD t1.
SELECT udate
FROM cdhdr
INTO CORRESPONDING FIELDS OF TABLE lt_cdhdr.
SORT lt_cdhdr by udate.
DELETE ADJACENT DUPLICATES FROM lt_cdhdr.
GET RUN TIME FIELD t2.
time_01 = t2 - t1.
time_01 = time_01 / 1000000.
" 直接调用删除重复的SQL语句
CLEAR:t1, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









