




- Gemini 3 Pro:工程感知力实测
- Thinking Mode:API 账单的隐形杀手
- Bash Agent:从写代码到改代码
1. 别盯着那 1501 分,看它的空间直觉
LMSYS 榜单上那几分的波动对开发者来说毫无意义。GPT-5.2 逻辑再强,在处理复杂 UI 重构时依然会翻车。原因很简单:大多数模型是靠视觉 Token 强行转译,它们看不懂 Z-index 的层级逻辑。
Gemini 3 Pro 真正狠的地方在于原生多模态。我把一个 30 分钟的 React 项目交互录屏扔进去,它能直接根据视频帧还原组件的父子嵌套关系。这种空间直觉在 WebDev Arena 这种实战场景里是断层领先的。它不是在猜代码,它是真的看懂了页面是怎么长出来的。
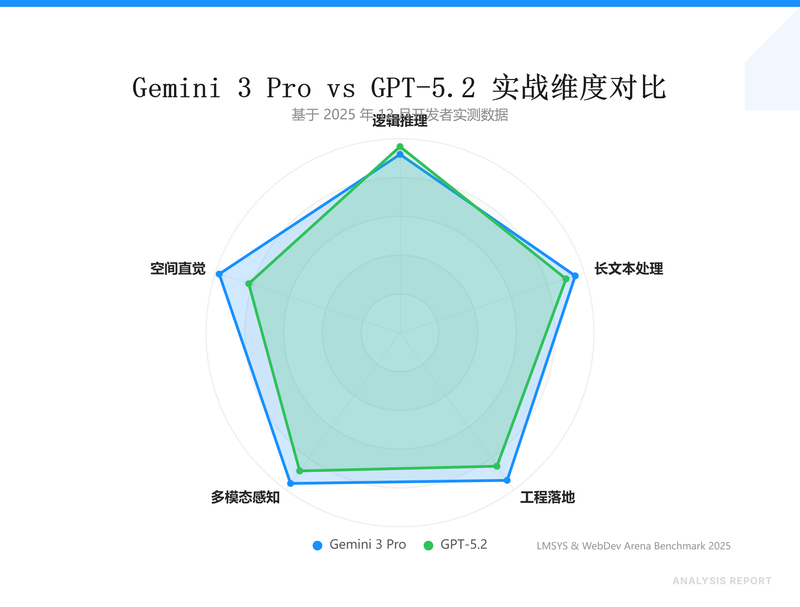
如果你在处理大规模存量代码迁移,或者需要 AI 读懂复杂的 3D 建模逻辑,Gemini 3 Pro 是目前唯一的选择。为了验证这种极限能力,我习惯在 NunuAI 上挂载多个模型做 A/B Test。它聚合了目前最顶级的模型,国内直连非常稳,省去了折腾 Google Cloud 账号的麻烦,适合拿来快速验证不同模型的感知差异。
2. 警惕 Thinking Mode 的跳表陷阱

Google 宣传的低价是有前提的。Gemini 3 的计费逻辑里藏着一个巨大的坑:200k Token 分水岭。
一旦你的 Prompt 超过 200k,输入单价会从 $2/M 翻倍到 $4/M。最要命的是那个 Thinking Mode(思考模式)。它产生的推理 Token 是全额计费的。你以为它在深思熟虑,实际上它每秒钟都在烧你的余额。
实操建议:
- 强制限流:在 API 调用时,通过
thought_config明确限制推理步数。如果只是做简单的格式转换,直接关掉 Thinking 模式,否则账单会让你怀疑人生。 - 缓存救命:Gemini 3 支持 1M 上下文,但别傻乎乎地每次都传全量文档。利用 Context Caching 把固定的 API 手册或旧代码库缓存起来,首字延迟(TTFT)能降 40%,成本能省下一大截
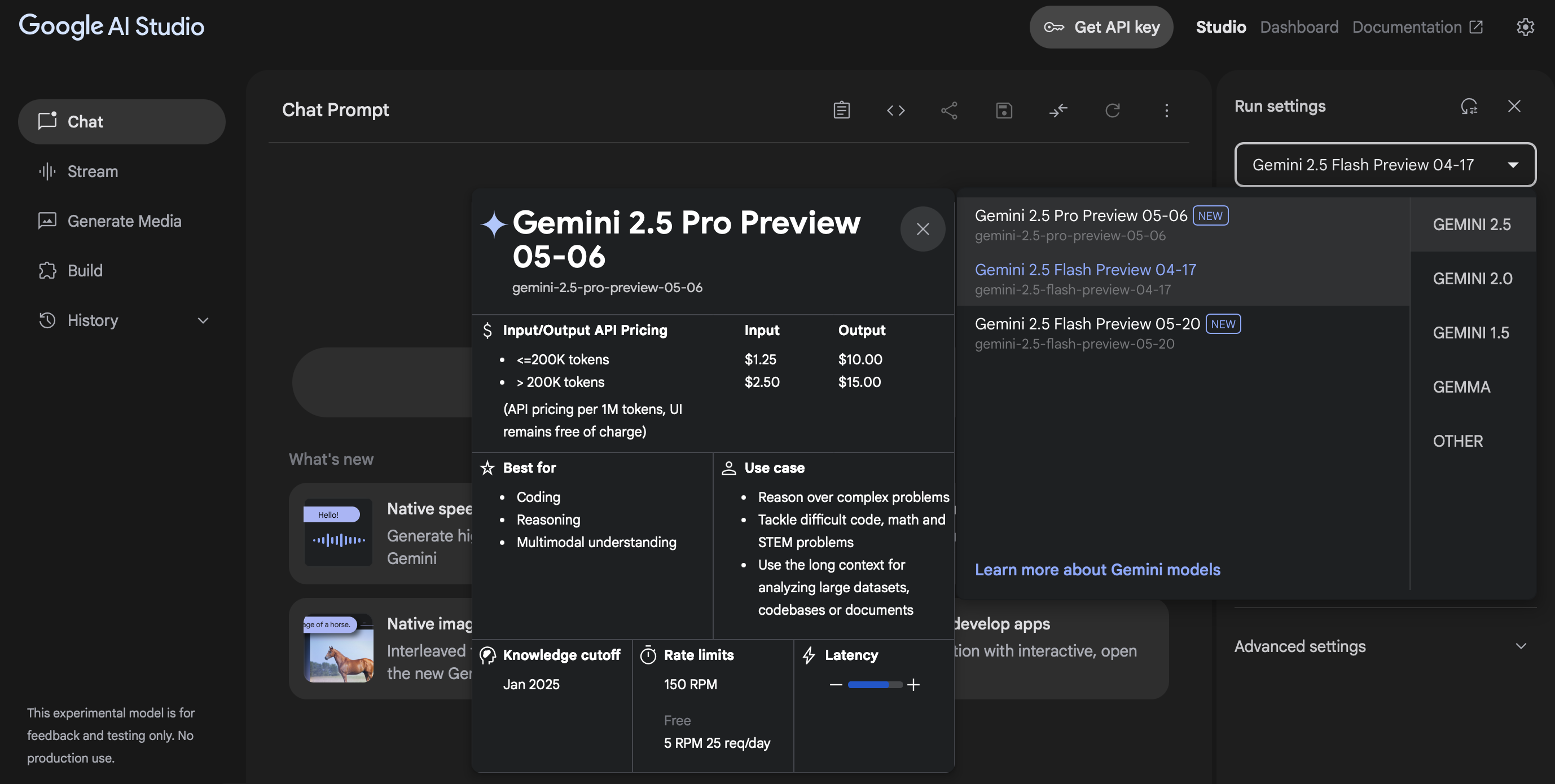
。
- 环境隔离:Vertex AI 的预览版经常有 64k 的逻辑截断。如果你发现模型突然变蠢,大概率是触发了平台的隐形限制,建议切回标准 API 模式。
3. Bash Agent:它终于不再只是一张嘴了
以前的 AI 修复 Bug 是给你一段代码让你自己去贴,Gemini 3 的 Client-Side Bash Tool 走的是监工路线。它能直接生成 Shell 指令并在受控环境执行。
全自动 Bug 修复流实操:
- 授权它访问日志目录:
cat /var/log/nginx/error.log | tail -n 50。 - 它会自主定位文件:
find . -name "config.py"。 - 直接执行修改:
sed -i 's/OLD_ENDPOINT/NEW_ENDPOINT/g' config.py。 - 跑测试闭环:
pytest tests/。
这种原生支持 Bash 的能力比 Python Sandbox 暴力得多。它能在一个 Session 里分析你整个 GitHub 仓库的依赖树,找出版本冲突并一键 Fix。

这种高阶操作对环境配置要求极高,如果你不想在本地折腾复杂的 API 环境,NunuAI 这种平台提供了现成的多模型调用接口和大量免费额度,非常适合拿来跑这种高频的 Agent 实验。
别再纠结谁是第一了。逻辑审美找 GPT-5.2,工程落地和多模态感知死磕 Gemini 3 Pro。根据账单和场景分工,才是职业开发者该干的事。

















 5836
5836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









