






1
介绍
当 Kubernetes pod 关闭时,幕后会发生什么?在 Kubernetes 中,了解 pod 终止的复杂性对于维护应用程序的稳定性和效率至关重要。当 pod 终止时,这不仅仅是简单的关闭;它涉及一个定义明确的生命周期,以确保最小的中断和数据丢失。这个过程称为正常终止,对于处理正在进行的请求和在最终删除 pod 之前执行必要的清理任务至关重要。
本指南介绍了 Pod 终止期间的每个生命周期阶段,详细介绍了优雅处理的机制、资源优化策略、持久数据管理以及常见终止问题的故障排除技术。读完本博客后,您将彻底了解如何在 Kubernetes 环境中有效管理 Pod 终止,确保运行顺畅高效。
2
Pod 终止的生命周期阶段
在 Kubernetes 中,优雅终止意味着系统会给 Pod 时间来完成正在进行的请求,并在移除它们之前干净地关闭它们。这有助于避免中断和数据丢失。Kubernetes 支持优雅终止 Pod,它通过以下步骤实现:
当要求终止 pod 时,Kubernetes 会更新对象状态并将其标记为“终止”。
Kubernetes 会向 pod 中每个容器的主进程发送 SIGTERM 信号。
SIGTERM 信号表示容器中的进程应停止。进程有一段宽限期(默认为 30 秒)来正常关闭。
如果宽限期过后进程仍在运行,Kubernetes 将发送 SIGKILL 信号强制该进程终止。
要优雅地终止 pod,您可以将 terminationGracePeriodSeconds 添加到规范中,或者添加 kubectl delete pods–grace-period=
下面包含正常终止的时间序列图:
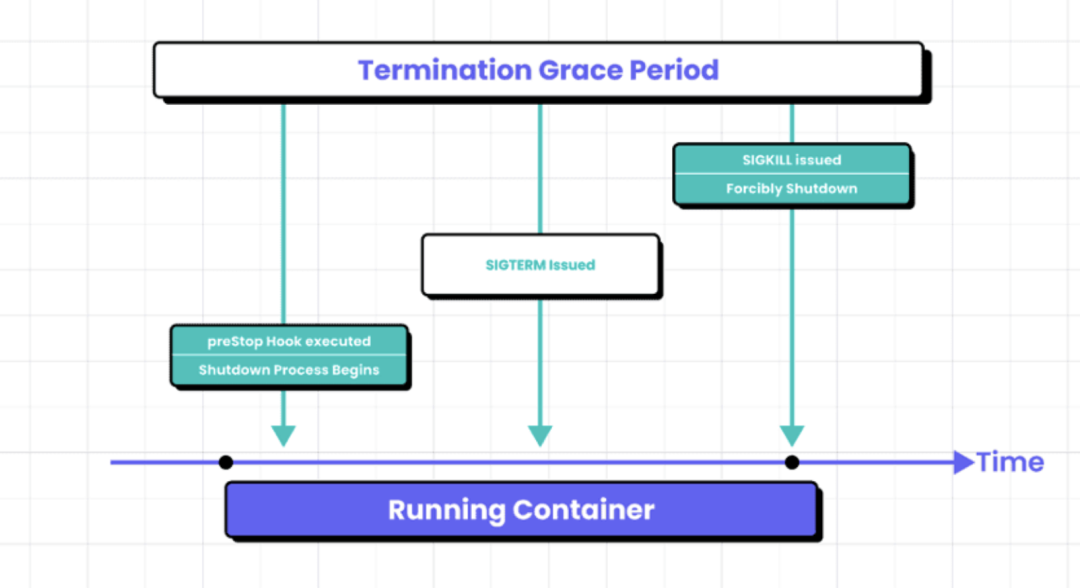
在容器终止之前执行“preStop”钩子。
当请求终止 pod 时,Kubernetes 将运行 preStop 钩子(如果已定义),向容器发送 SIGTERM 信号,然后等待宽限期,再发送 SIGKILL 信号。
下面是如何在 pod 配置中定义 preStop 钩子的示例:
apiVersion: v1kind: Podmetadata: name: my-podspec: containers: - name: my-container image: my-image lifecycle: preStop: exec: command: ["/bin/sh", "-c", "echo Hello from the preStop hook"]在此示例中,preStop 钩子运行一个命令,将一条消息打印到容器的标准输出。
preStop 钩子是放置以下代码的最佳位置:
等待连接关闭
清理资源
通知其他组件关闭
注意:请记住,Kubernetes 将运行 preStop 钩子,然后等待宽限期(默认 30 秒),然后强制终止容器。如果您的 preStop 钩子耗时超过宽限期,Kubernetes 将中断它。
3
影响 Pod 终止的因素
资源限制如何影响 pod 终止决策。
由于资源限制导致的 Pod 驱逐:Kubernetes 节点会监控表明系统资源不足的情况。当 CPU、内存、磁盘空间或文件系统 inode 等资源达到某些阈值时,节点会进入“DiskPressure”或“MemoryPressure”状态。在这种情况下,kubelet(每个节点上运行的 Kubernetes 代理)会尝试通过驱逐 Pod 来回收资源。服务质量较低的 Pod(例如超出其请求的 BestEffort 或 Burstable Pod)将首先被驱逐。
由于内存不足/CrashloopBackoff 导致 Pod 终止:如果节点内存严重不足,Linux 内核的内存不足 (OOM) Killer 进程将启动并开始终止进程以释放内存。在 Kubernetes 环境中,这可能会导致您的 Pod 突然终止。这不是正常终止,因此通常应避免这种情况。您可以通过为 Pod 设置适当的资源请求和限制来缓解此类情况。
由于无法调度的 Pod 而导致 Pod 终止:创建 Pod 时,如果任何节点中都没有足够的资源来满足 Pod 的资源请求,则 Pod 将保持待定状态。如果 Pod 长时间处于未调度状态,则可能导致 Pod 终止。
优化资源配置以缓解潜在问题的策略。
设置资源请求和限制:对于每个 Pod,您可以指定资源请求和限制。请求是 Kubernetes 为 Pod 保证的资源量,限制是 Pod 可以使用的最大资源量。通过适当设置这些,您可以确保您的 Pod 拥有所需的资源,并防止它们消耗过多资源并影响其他 Pod。
resources: limits: cpu: "1" memory: 1000Mi requests: cpu: 200m memory: 500Mi使用服务质量类别:Kubernetes 根据资源请求和限制将 Pod 分配到服务质量 (QoS) 类别(Guaranteed、Burstable 或 BestEffort)。QoS 类别越高的 Pod 被驱逐的可能性就越小。您可以通过调整这些设置来优化资源分配,将最关键的 Pod 分配到 Guaranteed 类别。
保证 pod 中的所有容器都有 CPU 和内存请求和限制,并且它们是平等的。
resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "64Mi" cpu: "250m"可突发:Pod 中至少有一个容器有 CPU 或内存请求。或者如果限制和请求数超过
resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"resources:{}命名空间资源配额:您可以使用 ResourceQuotas 来限制命名空间中可使用的资源总量。这可以防止单个团队或项目的过度消耗。在命名空间内,您还可以使用 LimitRanges 为各个 Pod 设置资源请求和限制的默认值和约束。
apiVersion: v1kind: ResourceQuotametadata: name: compute-resourcesspec: hard: pods: "10" requests.cpu: "1" requests.memory: 1Gi limits.cpu: "2" limits.memory: 2Gi节点亲和性规则:这些规则允许您根据节点标签影响 Pod 的调度位置。例如,您可以使用节点亲和性来确保高内存 Pod 调度在高内存节点上。
apiVersion: v1kind: Podmetadata: name: with-node-affinityspec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: disktype operator: In values: - ssd containers: - name: nginx-container image: nginx污点和容忍度:污点允许节点排斥一组 Pod,并且可以向 Pod 添加容忍度,以允许(但不要求)将它们调度到具有匹配污点的节点上 kubectl taint nodes node1 key=value:NoSchedule
apiVersion: v1kind: Podmetadata: name: my-podspec: containers: - name: my-container image: my-image tolerations: - key: "key" operator: "Equal" value: "value" effect: "NoSchedule"自动扩展:使用 HPA 和 VPA 来扩展和调整部署大小
4
处理持久数据和存储
在 Kubernetes 中,StatefulSet 可确保每个 Pod 获得唯一且固定的身份,这对于维护数据库等应用程序的状态非常重要。在 Pod 终止方面,Kubernetes 在 StatefulSet 中的处理方式与其他 Pod 控制器(如 Deployments 或 ReplicaSet)略有不同。
以下是 Kubernetes 在 StatefulSet 中处理 pod 终止的步骤:
缩减/删除:当 StatefulSet 缩减或委托销毁时,Kubernetes 将以相反的顺序终止 Pod,从最高到最低,以确保保持状态。例如,如果您有名为 web-0、web-1、web-2 的 Pod,并且缩减规模,则将首先删除 web-2,然后删除 web-1,依此类推。
优雅终止:与其他 Pod 一样,StatefulSet Pod 也会经历优雅终止过程。删除 Pod 时,Kubernetes 将发送 SIGTERM 信号以允许 Pod 优雅关闭。它允许 Pod 完成处理任何正在进行的请求并在被删除之前准备关闭。如果进程未在宽限期内(默认 30 秒)退出,则会发送 SIGKILL 信号以强制关闭它。
PreStop Hook:如果在 StatefulSet 中的 Pod 规范中定义了 preStop 生命周期钩子,它将在 Pod 终止之前执行。这提供了在删除 Pod 之前执行任何清理或最终操作的机会。
Pod 标识:使用 StatefulSet,Pod 的标识在重新调度时得以保留。如果某个节点发生故障并且需要重新调度 Pod,则替换 Pod 将具有相同的网络标识(名称和主机名),并且如果使用持久卷,则替换 Pod 将具有来自同一 PersistentVolumeClaim (PVC) 的相同数据。
Pod 存储:如果 StatefulSet 中的 Pod 已附加存储,则删除 Pod 时不会删除存储 (PVC)。这可确保如果使用相同标识调度了新 Pod,它可以从旧 Pod 停止的位置恢复。
5
解决 Pod 终止问题
识别与 pod 终止相关的常见问题:
Pod 卡在终止状态:有时,Pod 可能由于各种原因(例如存储问题、终止器卡在删除中或网络问题)卡在终止状态。
Pod 中断预算:如果您设置了 Pod 中断预算 (PDB),该预算限制了由于自愿中断而同时关闭的复制应用程序的 Pod 数量,它可以防止 Pod 自愿终止。实用的故障排除技巧和解决方案:
Pod 卡在 Terminating 状态:对于卡在 Terminating 状态的 Pod,您可以使用 kubectl delete pod–grace-period=0 –force 强制删除 Pod。但是,这应该是最后的手段,因为它可能会导致数据丢失。最好通过检查 Pod 描述(kubectl describe pod)并查找任何错误来确定根本原因。
Pod 中断预算:如果您有一个 PDB 阻止 Pod 终止,则可能需要重新考虑 PDB 设置。如有必要,您可以删除 PDB,但请注意,这可能会影响应用程序的可用性。始终考虑影响并相应地规划停机时间。
6
结论
充分了解 Kubernetes 中的 Pod 终止可确保应用程序在工作负载增长时顺利运行。通过掌握 Kubernetes 工具、正确配置资源和使用最佳实践,您可以创建一个弹性环境。最终,对 Kubernetes pod 终止采取周到的方法不仅可以提高基础设施的稳定性和可扩展性,还可以使团队能够更快地提供更高质量的服务,同时最大限度地减少对最终用户的干扰。
推荐
原创不易,随手关注或者”在看“,诚挚感谢!

















 4739
4739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









