




 本文介绍了一种使用自定义注解和AOP技术实现日志存储的方法。通过定义注解OperateLog并结合AOP切面,可以自动记录请求模块、业务方法、操作人员类型等信息,并在方法执行前后进行日志记录。
本文介绍了一种使用自定义注解和AOP技术实现日志存储的方法。通过定义注解OperateLog并结合AOP切面,可以自动记录请求模块、业务方法、操作人员类型等信息,并在方法执行前后进行日志记录。
这里我们介绍下使用自定义注解,加aop来实现日志的存储
首先自定义注解
import com.etc.mainboot.enums.BusinessType;
import com.etc.mainboot.enums.OperatorType;
import java.lang.annotation.*;
/**
* 操作日志记录处理
*/
@Documented
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface OperateLog {
/**
* 请求模块-title
*/
String title() default "";
/**
* 请求具体业务方法
*/
BusinessType bizType() default BusinessType.OTHER;
/**
* 操作人员类型
*/
OperatorType operateType() default OperatorType.OTHER;
/**
* 是否保存请求参数,默认false
*/
boolean isSaveData() default false;
}
编写AOP切面
package com.etc.mainboot.aop;
import com.etc.mainboot.annotation.OperateLog;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.Signature;
import org.aspectj.lang.annotation.*;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import javax.servlet.http.HttpServletRequest;
import java.lang.reflect.Method;
import java.util.Map;
/**
* aop切面处理
* 对模块、方法、参数的日志处理
* @Aspect注解切面,@PointCut定义切点,标记方法
* @author ChenDang
* @date 2019/5/28 0028
*/
@Aspect
@Component
public class LogAspect {
/**
* 此处定义切点是注解方法,这里使用注解的方式。
* 也可以使用aop最原始的支撑包名的方式
*/
@Pointcut("@annotation(com.etc.mainboot.annotation.OperateLog)")
public void operateLog(){}
/**
* 环绕增强,在这里进行日志操作
*/
@Around("operateLog()")
public Object doAround(ProceedingJoinPoint joinPoint) throws Throwable{
Object res = null;
long time = System.currentTimeMillis();
try {
//方法继续执行
res = joinPoint.proceed();
time = System.currentTimeMillis() - time;
return res;
} finally {
try {
//方法执行完成后增加日志
addOperationLog(joinPoint,res,time);
}catch (Exception e){
System.out.println("LogAspect 操作失败:" + e.getMessage());
e.printStackTrace();
}
}
}
private void addOperationLog(JoinPoint joinPoint, Object res, long time){
//joinPoint.getSignature()获取封装了署名的对象,在该对象中可以获取目标方法名,
//所属类的class等信息
MethodSignature signature = (MethodSignature)joinPoint.getSignature();
String method = signature.getDeclaringTypeName() + "." + signature.getName();
System.out.println("拦截方法名:"+method);
//获取注解对象,取到注解里定义的字段
OperateLog annotation = signature.getMethod().getAnnotation(OperateLog.class);
if(annotation != null) {
String title = annotation.title();
String bizType = annotation.bizType().name();
String operateType = annotation.operateType().name();
boolean isSaveData = annotation.isSaveData();
System.out.println("title:"+title+",bizType:"+bizType+",operateType:"+operateType+",isSaveData:"+isSaveData);
//获取参数
HttpServletRequest request = ((ServletRequestAttributes)(RequestContextHolder.getRequestAttributes())).getRequest();
Map<String, String[]> map =request.getParameterMap();
if (map == null || map.isEmpty()) {
return;
}
//输出参数
for(String key : map.keySet()){
System.out.println("key:"+key+",value="+map.get(key));
}
}
//TODO 这里保存日志
System.out.println("记录日志:");
}
@Before("operateLog()")
public void doBeforeAdvice(JoinPoint joinPoint){
System.out.println("进入方法前执行.....");
}
/**
* 处理完请求,返回内容
* @param ret
*/
@AfterReturning(returning = "ret", pointcut = "operateLog()")
public void doAfterReturning(Object ret) {
System.out.println("方法的返回值 : " + ret);
}
/**
* 后置异常通知
*/
@AfterThrowing("operateLog()")
public void throwss(JoinPoint jp){
System.out.println("方法异常时执行.....");
}
/**
* 后置最终通知,final增强,不管是抛出异常或者正常退出都会执行
*/
@After("operateLog()")
public void after(JoinPoint jp){
System.out.println("方法最后执行.....");
}
/**
* 是否存在注解,如果存在就获取
*/
private OperateLog getAnnotationLog(JoinPoint joinPoint) {
Signature signature = joinPoint.getSignature();
MethodSignature methodSignature = (MethodSignature) signature;
Method method = methodSignature.getMethod();
if (method != null) {
return method.getAnnotation(OperateLog.class);
}
return null;
}
}
编写Controller,测试
package com.etc.mainboot;
import com.etc.mainboot.annotation.OperateLog;
import com.etc.mainboot.enums.BusinessType;
import com.etc.mainboot.enums.OperatorType;
import com.etc.mainboot.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/index")
public class IndexController {
@Autowired
UserService userService;
@OperateLog(title = "hello",bizType = BusinessType.QUERY,operateType = OperatorType.CUSTOMER)
@RequestMapping("/hello")
public String hello(){
userService.hello();
return "hello world";
}
}
编写Service和实现类
public interface UserService {
public void hello();
}
@Service
public class UserServiceImpl implements UserService {
@Async("asyncServiceExecutor")
@Override
public void hello(){
System.out.println("当前运行的线程名称:" + Thread.currentThread().getName());
}
}
这里我们使用了线程池管理
@Configuration
@EnableAsync
public class ThreadExecutorConfig {
@Bean
public Executor asyncServiceExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
//配置核心线程数
executor.setCorePoolSize(10);
//配置最大线程数
executor.setMaxPoolSize(10);
//配置队列大小
executor.setQueueCapacity(99999);
//配置线程池中的线程的名称前缀
executor.setThreadNamePrefix("async-service-thread-");
// rejection-policy:当pool已经达到max size的时候,如何处理新任务
// CALLER_RUNS:不在新线程中执行任务,而是有调用者所在的线程来执行
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//执行初始化
executor.initialize();
return executor;
}
}
访问controller
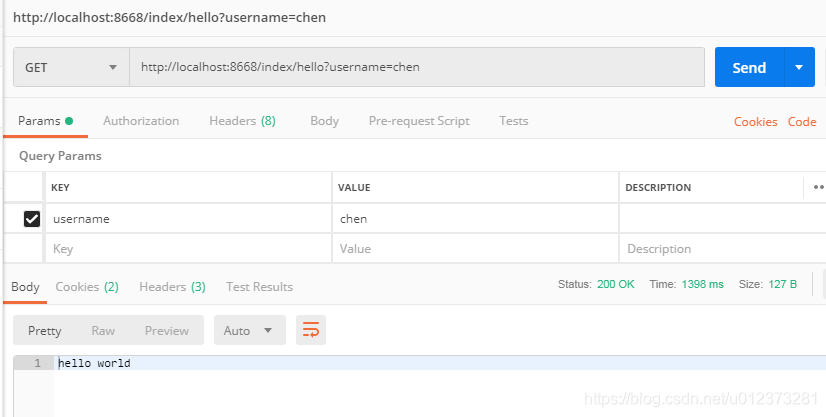
看下控制台输出结果
==========================================
进入方法前执行.....
拦截方法名:com.etc.mainboot.IndexController.hello
当前运行的线程名称:async-service-thread-3
title:hello,bizType:QUERY,operateType:CUSTOMER,isSaveData:false
key:username,value=[Ljava.lang.String;@63cf387f
记录日志:
方法最后执行.....
方法的返回值 : hello world
===================================
总结
使用自定义注解+aop,实现日志的存储。在环绕通知doAround里,我们可以获取访问方法和注解相关信息,以及request请求里的信息,包含参数、参数值、请求方法、客户端信息等等,然后在doAround里,保存信息到数据库,这里我就没有写数据库操作了,大家自己写下。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









