







DeepSeek-R1是DeepSeek人工智能公司开发的大语言模型(LLM),它使用强化学习技术,在DeepSeek-V3-Base的基础上,通过多阶段训练增强推理能力。该模型的一个显著特点是其强化学习步骤,用于完善模型响应,使其超越标准的预训练和微调过程。通过强化学习,DeepSeek-R1可以更有效地适应用户反馈和目标,最终提高响应的相关性和清晰度。此外,DeepSeek-R1还采用了思维链(CoT)方法,这意味着它能够分解复杂的查询,并逐步进行推理。这种引导式推理过程使模型能够生成更准确、更透明、更详细的回答。
该模型结合基于强化学习的微调与CoT功能,旨在生成结构化的回答,同时注重可解释性和用户交互。凭借其全面的功能,DeepSeek-R1作为一种可集成到各种工作流程(如Agents、逻辑推理和数据解释任务)中的多功能文本生成模型,已经引起了业界的广泛关注。
DeepSeek-R1采用了混合专家(MoE)架构,参数规模达到6710亿。MoE架构能够激活370亿参数,通过将查询路由到最相关的专家集群来实现高效推理,这种方法使模型能够在保持整体效率的同时,专注于不同的问题领域。
DeepSeek-R1蒸馏模型将DeepSeek-R1主模型的推理能力转化为更高效的架构,这些架构基于流行的开源模型,如Meta的Llama(8B和70B)和Hugging Face的Qwen(1.5B、7B、14B和32B)。模型蒸馏指的是训练更小、更高效的模型,将更大的DeepSeek-R1模型作为教师模型,以模仿其行为和推理模式的过程。例如DeepSeek-R1-Distill-Llama-8B在性能和效率之间实现了极佳的平衡,将该模型与Amazon SageMaker AI集成,您可以从亚马逊云科技可扩展基础架构中获益,同时保持高质量的语言模型功能。
Amazon SageMaker AI提供了多种选项来部署DeepSeek-R1模型的蒸馏版本,本文将介绍如何在Amazon SageMaker AI中使用其蒸馏模型。
解决方案概述
您可以在亚马逊云科技托管的机器学习基础设施中使用DeepSeek蒸馏模型,本文将展示如何在Amazon SageMaker AI推理端点上部署这些模型。
Amazon SageMaker AI为用户提供了多种用于部署的服务容器选项。
LMI容器:一种具有不同后端(vLLM、TensortRT-LLM和Neuron)的大模型推理(LMI)容器。更多详细信息,请参阅GitHub代码库。
TGI容器:一种Hugging Face文本生成接口(TGI)容器。更多详细信息,请参阅GitHub代码库。
GitHub代码库—LMI容器:
https://github.com/aws/deep-learning-containers/blob/master/available_images.md#large-model-inference-containers
GitHub代码库—TGI容器:
https://github.com/aws/deep-learning-containers/releases?q=tgi+AND+gpu&expanded=true
以下代码片段将以LMI容器为例。有关使用TGI、TensorRT-LLM和Neuron的更多部署示例,请参阅以下GitHub代码库。
GitHub代码库:
https://github.com/aws-samples/sagemaker-genai-hosting-examples/tree/main/Deepseek
LMI容器
LMI容器是一组专为大语言模型(LLM)推理而构建的高性能Docker容器。使用这些容器,您可以利用如vLLM、TensorRT-LLM和Transformers NeuronX等高性能开源推理库,在Amazon SageMaker端点上部署LLM,这些容器打包模型服务器与开源推理库,提供一体化的LLM服务解决方案。
LMI容器提供了许多功能,例如以下功能。
为Meta Llama、Mistral、Falcon等流行模型架构优化推理性能。
与vLLM、TensorRT-LLM、Transformers NeuronX等开源推理库集成。
持续批量处理,在高并发下实现吞吐量最大化。
Tokens流处理。
通过AWQ、GPTQ、FP8等实现量化。
使用张量并行进行多GPU推理。
提供LoRA微调模型服务。
文本嵌入功能,可将文本数据转换为数值向量。
支持推测解码,以降低延迟。
LMI容器通过与流行的推理库集成来提供这些功能,统一的配置格式使您能够跨库使用最新的优化和技术。要了解有关LMI组件的更多信息,请参阅LMI组件。
LMI组件:
https://docs.djl.ai/master/docs/serving/serving/docs/lmi/deployment_guide/index.html#components-of-lmi
准备条件
要运行示例笔记,您需要拥有亚马逊云科技账户以及具有管理创建资源权限的Amazon IAM角色。有关详细信息,请参阅创建亚马逊云科技账户。
创建亚马逊云科技账户:
https://docs.aws.amazon.com/accounts/latest/reference/manage-acct-creating.html
如果您是首次使用Amazon SageMaker Studio,您首先需要创建一个Amazon SageMaker域,此外您可能还需要申请增加相应Amazon SageMaker托管实例的服务配额。在本例中,您将在同一个Amazon SageMaker端点上托管基础模型和多个适配器,因此将使用ml.g5.2xlarge SageMaker托管实例。
部署DeepSeek-R1进行推理
以下是展示如何通过编程方式部署DeepSeek-R1-Distill-Llama-8B模型进行推理的步骤。部署模型的代码已在GitHub代码库中提供,您可以克隆该代码库并在Amazon SageMaker AI Studio中运行该笔记。
GitHub代码库—模型部署代码:
https://github.com/aws-samples/sagemaker-genai-hosting-examples/tree/main/Deepseek
1.配置Amazon SageMaker执行角色并导入必要的库。
!pip install --force-reinstall --no-cache-dir sagemaker==2.235.2
import json
import boto3
import sagemaker
# Set up IAM Role
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']左右滑动查看完整示意
在Amazon SageMaker上部署诸如DeepSeek-R1或其蒸馏变体的LLM有两种方法。
从Amazon S3存储桶部署未压缩的模型权重:在这种情况下,您需要将HF_MODEL_ID变量设置为包含模型工件的Amazon S3前缀。这种方法速度较快,通常只需几分钟就能从Amazon S3完成模型下载。
直接从Hugging Face Hub部署(需要互联网访问权限):您需要将HF_MODEL_ID设置为Hugging Face存储库或模型ID(例如,“deepseek-ai/DeepSeek-R1-Distill-Llama-8B”)。与使用Amazon S3相比,这种方法速度较慢,下载模型所需的时间可能会更多。如果启用了enable_network_isolation,则此方法将不起作用,因为它需要互联网访问权限,才能从Hugging Face Hub检索模型工件。
2.本示例选择直接从Hugging Face Hub部署模型。
vllm_config = {
"HF_MODEL_ID": "deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"OPTION_TENSOR_PARALLEL_DEGREE": "max",
"OPTION_ROLLING_BATCH": "vllm",
"OPTION_MAX_ROLLING_BATCH_SIZE": "16",
}左右滑动查看完整示意
OPTION_MAX_ROLLING_BATCH_SIZE参数限制了端点可处理的并发请求数,本例将其设置为16,以限制GPU内存需求。您在部署时,应根据自身延迟和吞吐量要求对其进行调整。
3.创建并部署模型。
# Create a Model object
lmi_model = sagemaker.Model(
image_uri = inference_image_uri,
env = vllm_config,
role = role,
name = model_name,
enable_network_isolation=True, # Ensures model is isolated from the internet
vpc_config={
"Subnets": ["subnet-xxxxxxxx", "subnet-yyyyyyyy"],
"SecurityGroupIds": ["sg-zzzzzzzz"]
}
)
# Deploy to SageMaker
lmi_model.deploy(
initial_instance_count = 1,
instance_type = "ml.g5.2xlarge",
container_startup_health_check_timeout = 1600,
endpoint_name = endpoint_name,
)左右滑动查看完整示意
4.发出推理请求。
sagemaker_client = boto3.client('sagemaker-runtime', region_name='us-east-1')
endpoint_name = predictor.endpoint_name
input_payload = {
"inputs": "What is Amazon SageMaker? Answer concisely.",
"parameters": {"max_new_tokens": 250, "temperature": 0.1}
}
serialized_payload = json.dumps(input_payload)
response = sagemaker_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType='application/json',
Body=serialized_payload
)左右滑动查看完整示意
性能和成本因素
ml.g5.2xlarge实例在性能和成本之间取得了良好平衡。对于大规模推理,可使用更大的批处理量进行实时推理,以优化成本和性能。您还可以使用批量转换进行离线、大规模推理来降低成本,以及监控端点使用情况优化成本。
清理
不再使用资源时,请及时清理。
predictor.delete_endpoint()安全性
您可以为DeepSeek-R1模型配置高级安全和基础架构设置,包括虚拟私有云(VPC)网络、服务角色权限、加密设置以及启用EnableNetworkIsolation以限制互联网访问。对于生产环境下的部署,审查这些设置以确保与组织的安全和合规要求保持一致至关重要。
默认情况下,模型在可访问互联网的共享亚马逊云科技托管VPC中运行。为了提高安全性和控制访问权限,您应根据自身需求,明确配置具有适当安全组和Amazon IAM策略的私有VPC。
Amazon SageMaker AI提供企业级安全功能,确保您的数据和应用程序的安全与隐私。除非得到您的指示,否则亚马逊云科技不会与模型提供商共享您的数据,而让您拥有对自有数据的完全控制权。这适用于所有专有模型和公开可用的模型,包括在Amazon SageMaker上的DeepSeek-R1模型。
更多详细信息,请参阅《在Amazon SageMaker AI中配置安全设置》。
在Amazon SageMaker AI中配置安全设置:
https://docs.aws.amazon.com/sagemaker/latest/dg/security.html
日志记录和监控
您可以使用Amazon CloudWatch监控Amazon SageMaker AI,Amazon CloudWatch会收集原始数据,并将其处理为可读的近乎实时的指标。这些指标可保留15个月,以便您分析历史趋势,更深入地了解应用程序的性能和健康状况。
您还可以配置警报以监控特定阈值,并在达到阈值时触发通知或自动操作,帮助您主动管理部署。
更多详细信息,请参阅《使用Amazon CloudWatch监控Amazon SageMaker AI指标》。
使用Amazon CloudWatch监控Amazon SageMaker AI指标:
https://docs.aws.amazon.com/sagemaker/latest/dg/monitoring-cloudwatch.html
最佳实践
建议您将LLM端点部署在VPC内,并置于专有子网之后且不设置互联网网关,同时最好确保没有出口流量。此外还应阻止来自互联网的入口流量,以最大限度地降低安全风险。
建议您应用防护机制,确保对传入和传出的模型响应进行安全性、偏差和毒性验证。您可以使用Amazon Bedrock Guardrails来保护Amazon SageMaker端点的模型响应。
更多详细信息,请参阅《DeepSeek-R1模型现已在Amazon Bedrock Marketplace和Amazon SageMaker JumpStart中可用》博文。
《DeepSeek-R1模型现已在Amazon Bedrock Marketplace和Amazon SageMaker JumpStart中可用》:
https://aws.amazon.com/blogs/machine-learning/deepseek-r1-model-now-available-in-amazon-bedrock-marketplace-and-amazon-sagemaker-jumpstart/
推理性能评估
本节将重点关注DeepSeek-R1蒸馏模型在Amazon SageMaker AI上的推理性能。评估LLM在端到端延迟、吞吐量和资源利用效率方面的性能,对于确保实际应用中的响应速度、可扩展性和成本效益至关重要。这些性能指标的优化,直接关系用户体验、系统可靠性以及大规模部署的可行性。本文测试了所有DeepSeek-R1蒸馏模型(1.5B、7B、8B、14B、32B和70B)在以下四个性能指标上的表现。
端到端延迟(从发送请求到接收响应之间的时间)。
吞吐量tokens。
首个tokens生成时间。
Tokens间延迟。
本次性能评估的核心目的,在于展示在通用流量场景下,不同硬件平台上DeepSeek-R1蒸馏模型的相对性能表现。本例并未针对每一种模型、硬件及用例组合的性能进行优化,因此这些测试结果不应被视作特定模型在特定实例类型上所能达到的最佳性能表现。您应根据自有数据集、流量模式以及I/O序列长度,独立开展性能测试。
用例
本文对以下用例进行了测试。
1.容器或模型配置:本例使用的是LMI容器v14,除MAX_MODEL_LEN设置为10000(无分块前缀和前缀缓存)外,其余均为默认参数。在具有多个加速器的实例上,本例将模型分片到所有可用的GPU上。
2.Tokens:本文使用两种输入tokens长度样本,评估了Amazon SageMaker端点托管的DeepSeek-R1蒸馏模型的性能。在测量不同指标的平均值之前,先各运行了50次测试,然后在并发数为10的情况下重复测试。
短长度测试:输入tokens 512个,输出tokens 256个。
中等长度测试:输入tokens 3072个,输出tokens 256个。
3.硬件:在多种实例类型上测试了蒸馏模型,每个实例的GPU数量分别为1、4或8个。在下表中,绿色单元格表示模型已在该特定实例类型上进行了测试,而红色则表示模型未在该实例类型上进行测试,这可能是因为该实例对于给定的模型而言过大,或者内存太小而无法容纳模型。
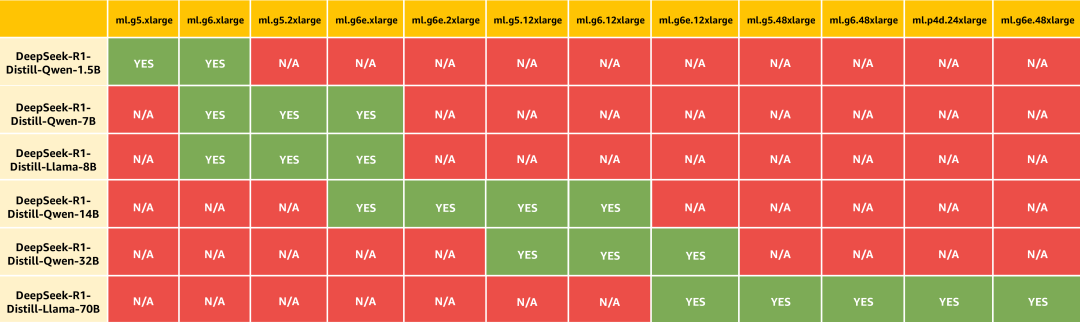
箱线图
下文将使用箱线图来可视化模型性能。箱线图是一种简洁的可视化摘要,它使用箱线显示数据集的中位数、四分位距(IQR)和潜在离群值,而触须则延伸到最小和最大的非离群值。通过观察中位数在箱形中的位置、箱形大小以及触须长度,您可以快速评估数据的中心趋势、变异性和偏态,如下图所示。
1
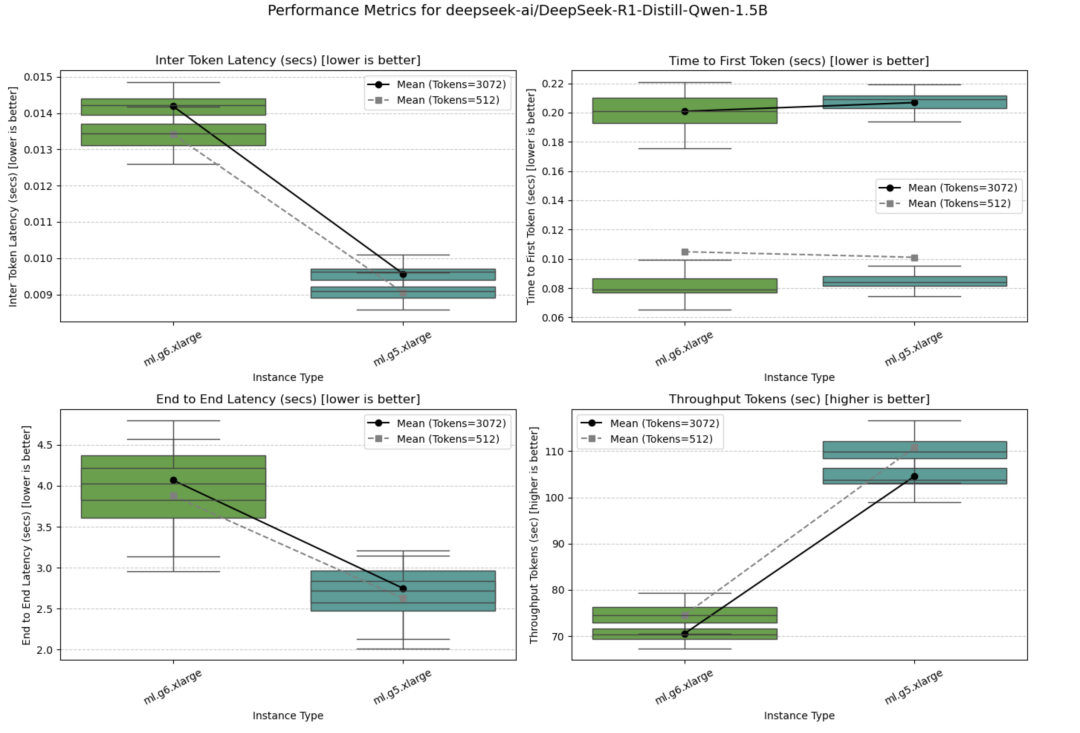
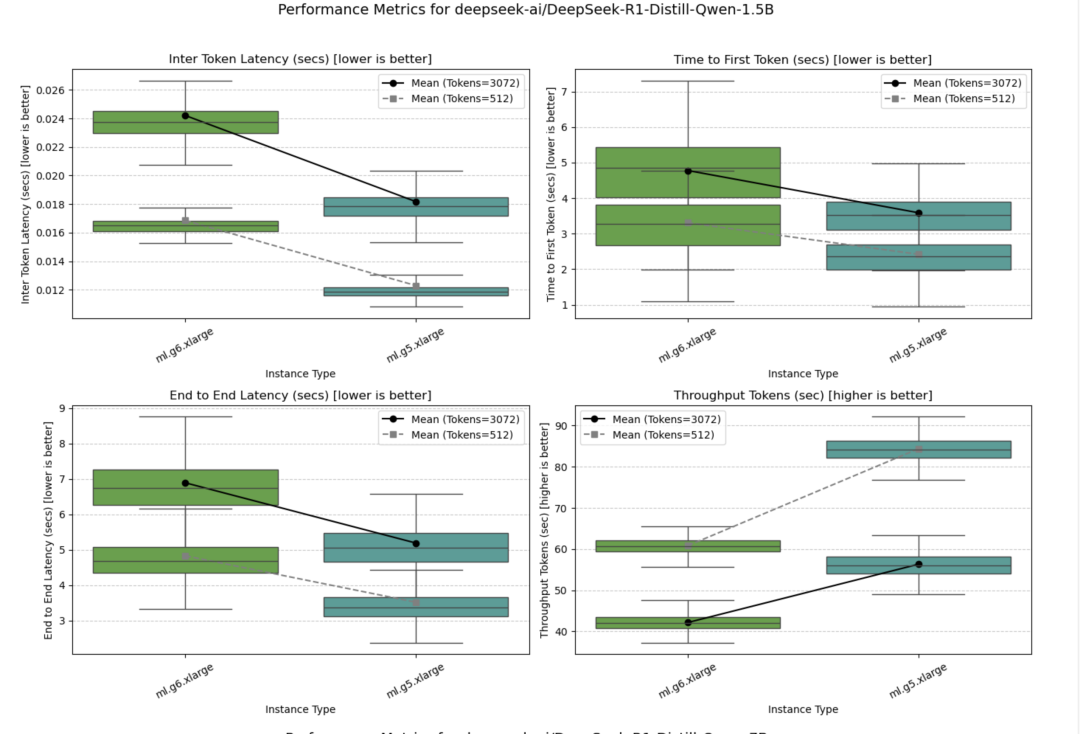
DeepSeek-R1-Distill-Qwen-1.5B
该模型可以部署在单个GPU实例上。结果表明,在所有测量的性能指标和并发设置下,ml.g5.xlarge实例的表现均优于ml.g6.xlarge实例。
并发量=1时的测试结果如下图所示。
并发量=10时的测试结果如下图所示。
2
DeepSeek-R1-Distill-Qwen-7B
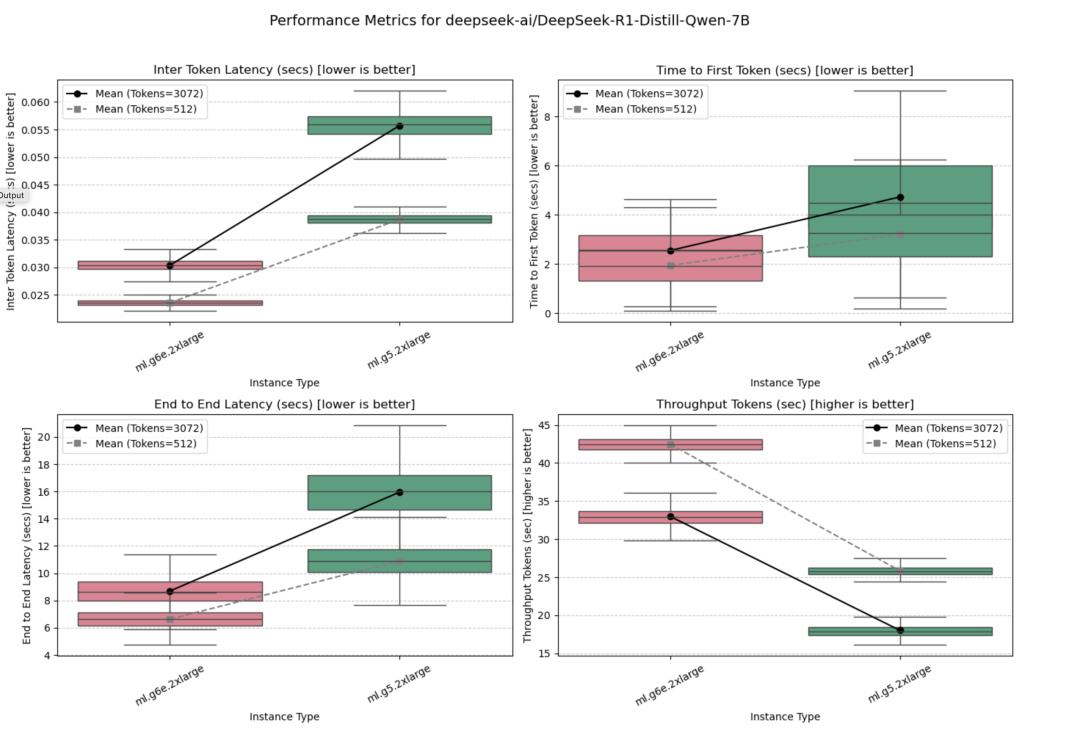
该模型在ml.g5.2xlarge和ml.g6e.2xlarge实例上进行了测试,在所有实例中,ml.g6e.2xlarge的性能表现最佳。
并发量=1时的测试结果如下图所示。
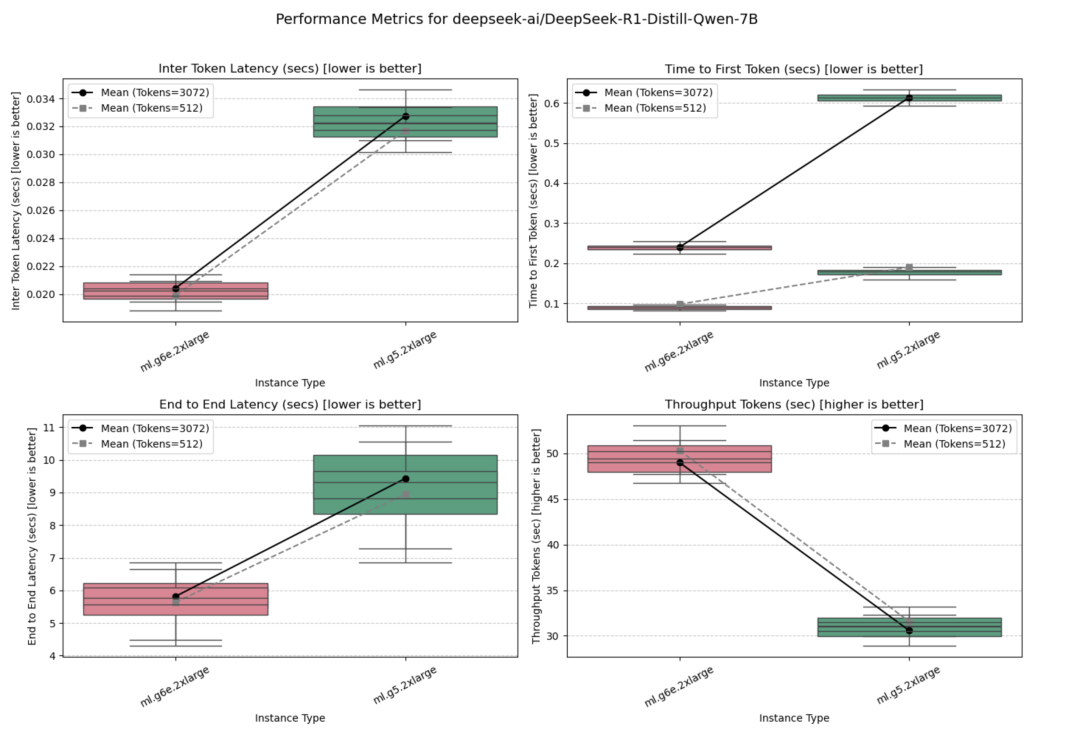
并发量=10时的测试结果如下图所示。
3
DeepSeek-R1-Distill-Llama-8B
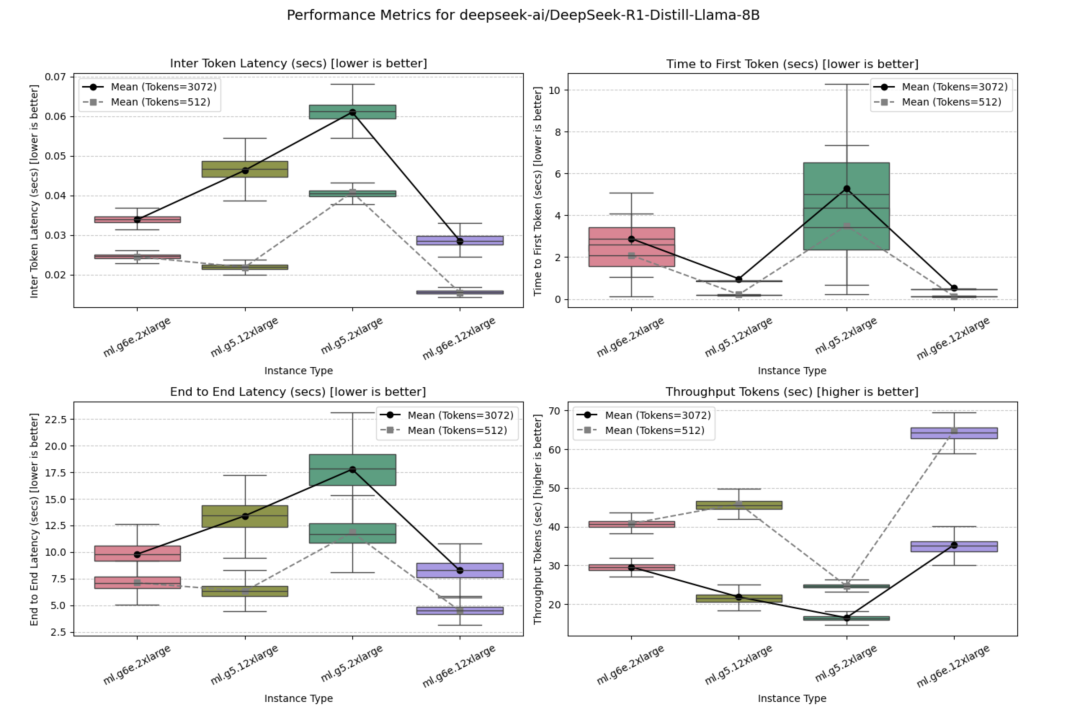
该模型在ml.g5.2xlarge、ml.g5.12xlarge、ml.g6e.2xlarge和ml.g6e.12xlarge实例上进行了基准测试,其中ml.g6e.12xlarge在所有实例中性能表现最佳。
并发量=1时的测试结果如下图所示。
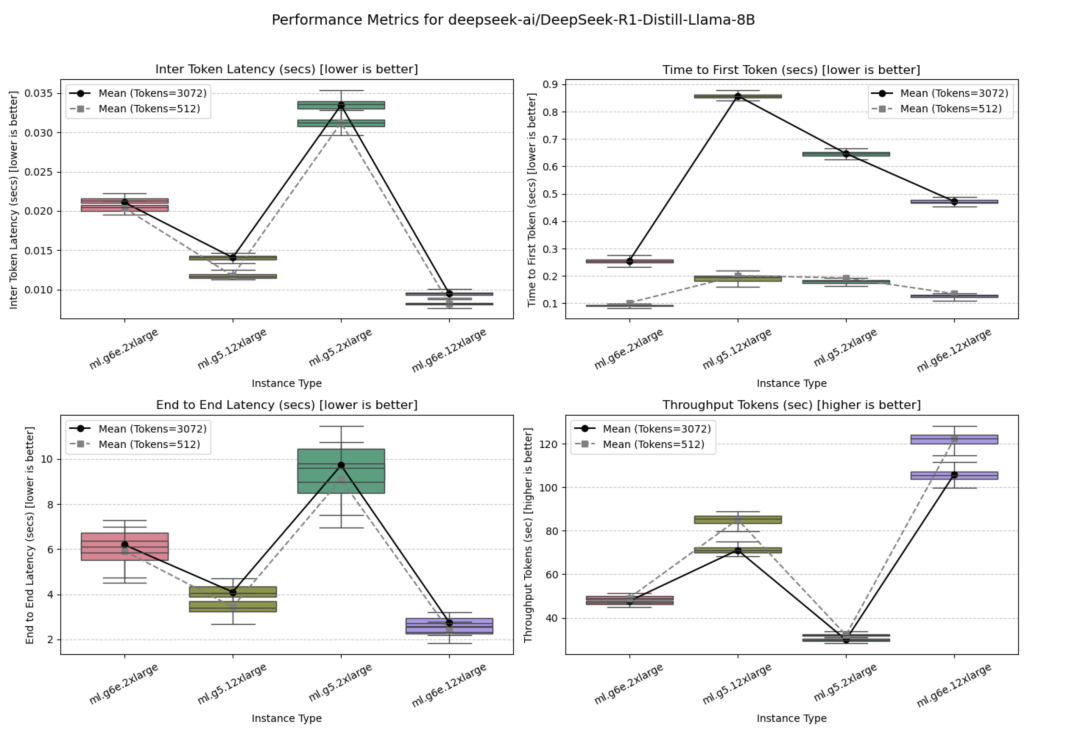
并发量=10时的测试结果如下图所示。
4
DeepSeek-R1-Distill-Qwen-14B
该模型在ml.g6.12xlarge、ml.g5.12xlarge、ml.g6e.48xlarge和ml.g6e.12xlarge实例上进行了测试。其中,配备8个GPU的ml.g6e.48xlarge实例表现最佳。
并发量=1时的测试结果如下图所示。
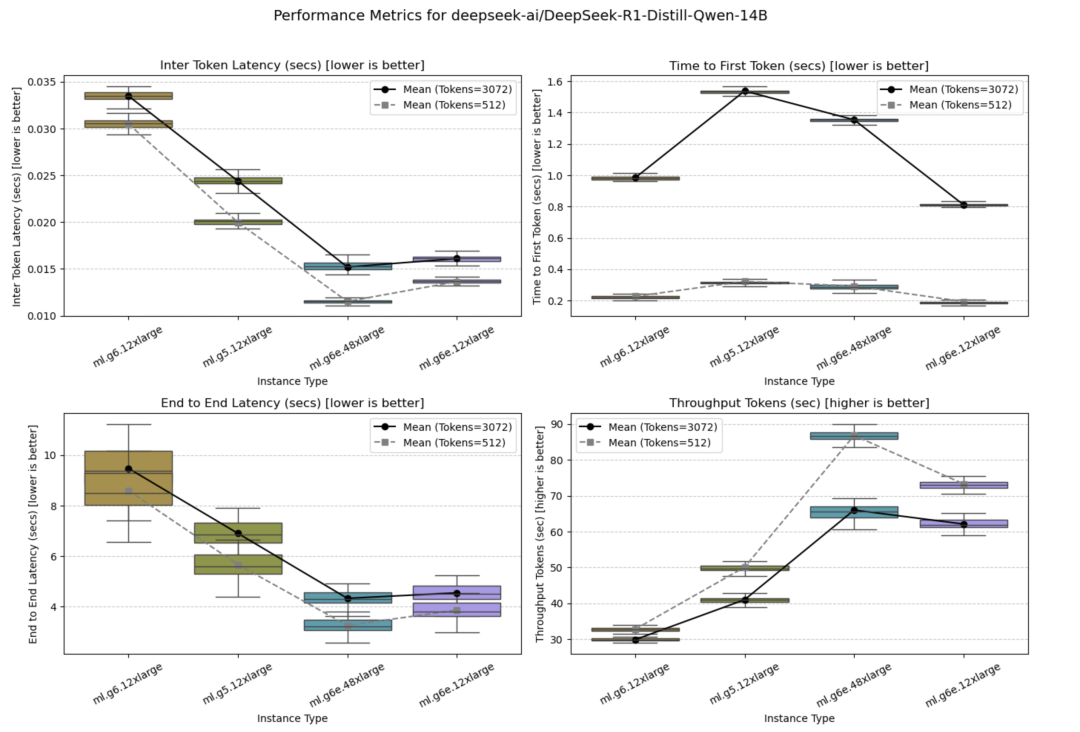
并发量=10时的测试结果如下图所示。
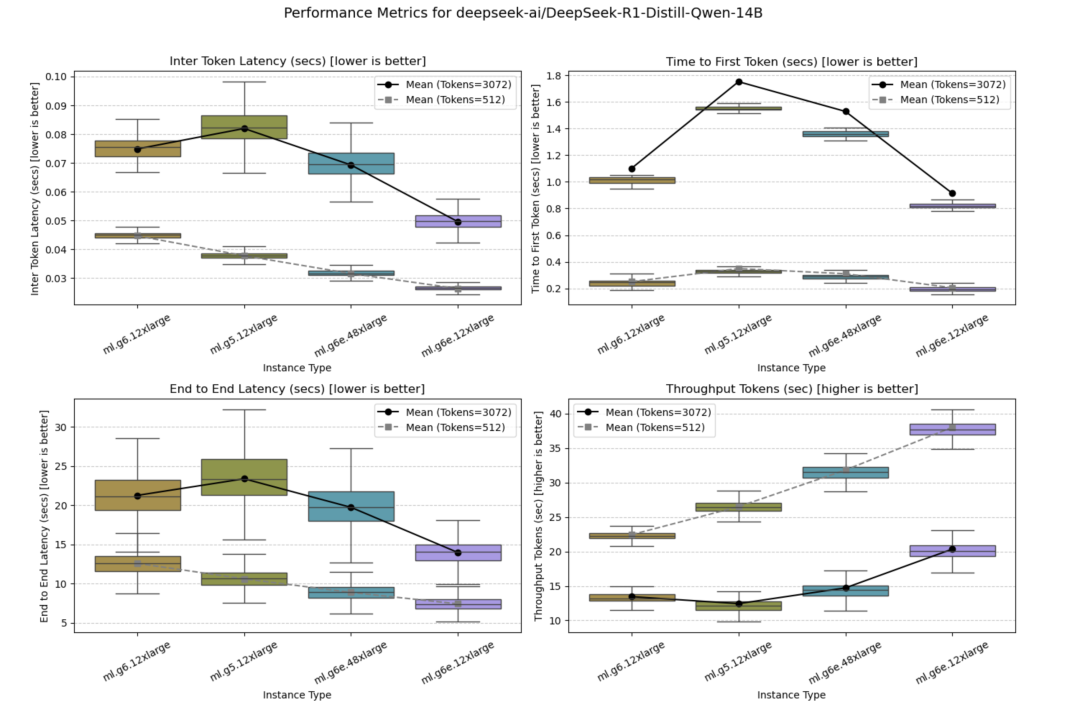
5
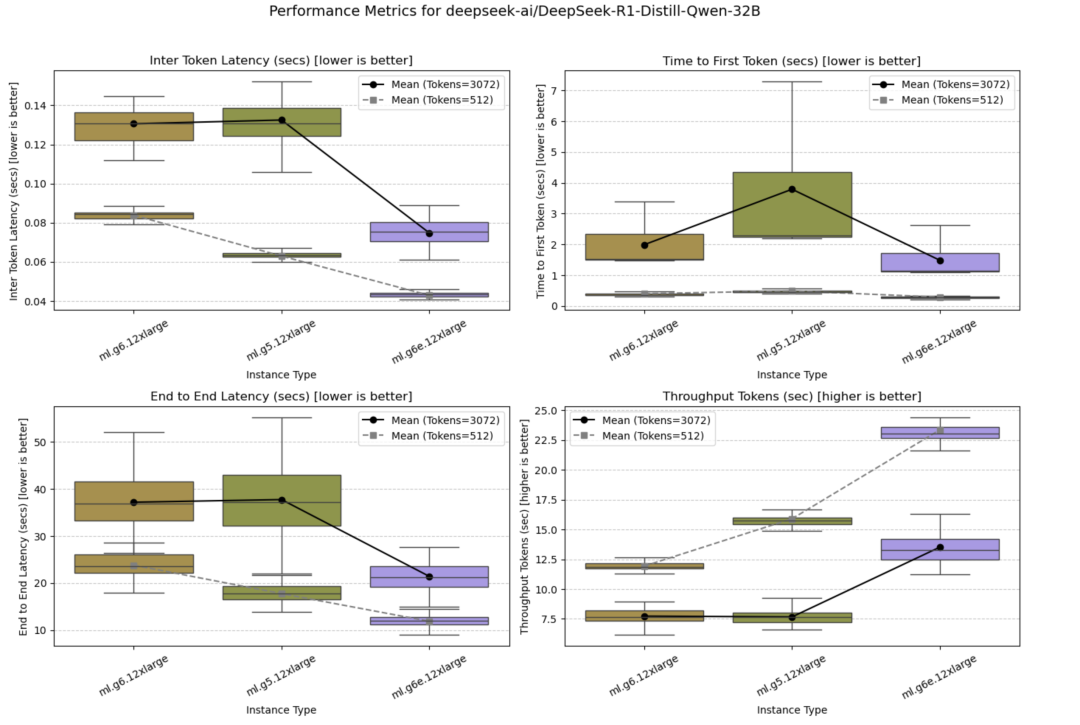
DeepSeek-R1-Distill-Qwen-32B
由于该模型体量相当大,所以只在多GPU实例上进行了部署,即ml.g6.12xlarge、ml.g5.12xlarge和ml.g6e.12xlarge。在所有并发设置下,最新一代实例(ml.g6e.12xlarge)表现最佳。
并发量=1时的测试结果如下图所示。
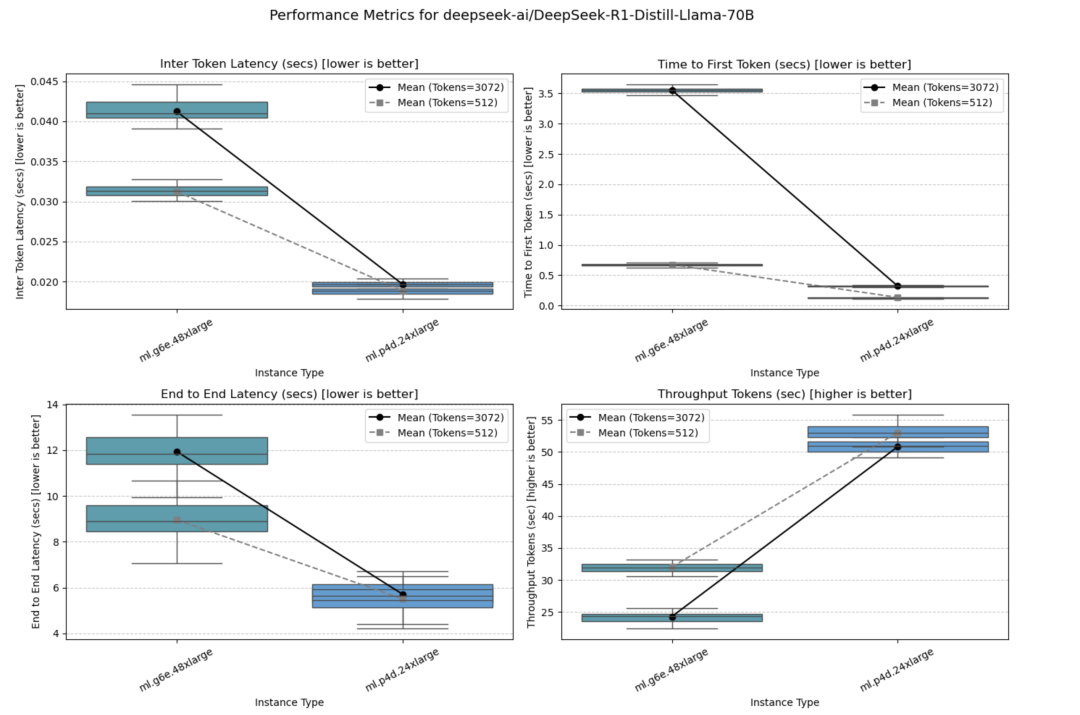
并发量=10时的测试结果如下图所示。
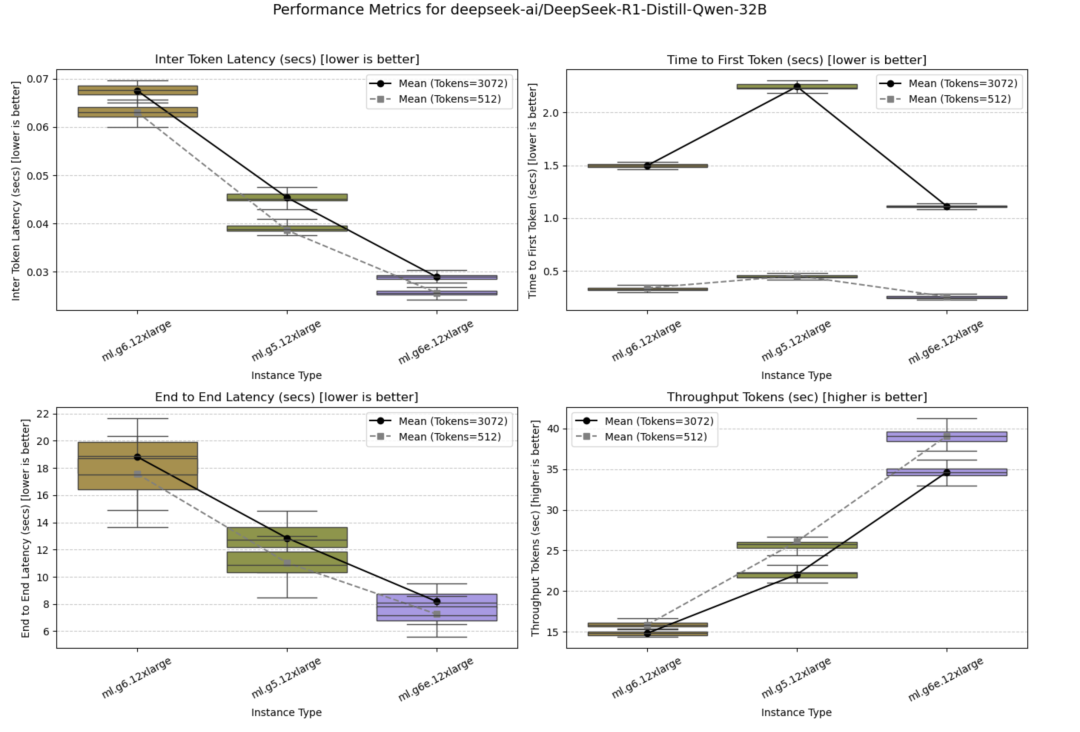
6
DeepSeek-R1-Distill-Llama-70B
在ml.g6e.48xlarge和ml.p4d.24xlarge两个不同的8 GPU实例上测试了该模型,后者表现最佳。
并发量=1时的测试结果如下图所示。
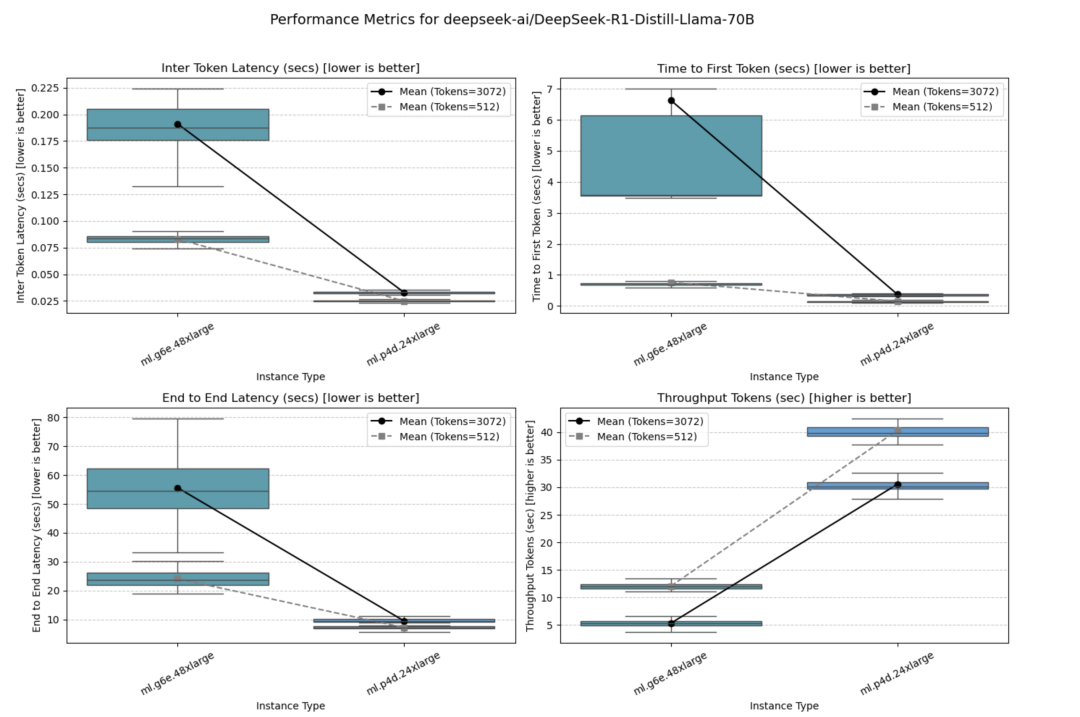
并发量=10时的测试结果如下图所示。
总结
在Amazon SageMaker AI上部署DeepSeek-R1模型,为寻求在其应用中使用先进语言模型的企业提供了强大解决方案。通过结合DeepSeek强大的模型与Amazon SageMaker AI托管的基础设施,为自然语言处理任务提供了可扩展且高效的路径。
本文基于四个关键的推理指标,利用13种不同的NVIDIA加速器实例类型,全面评估了所有DeepSeek-R1蒸馏模型的性能,这一分析为选择部署DeepSeek-R1解决方案的最佳实例类型,提供了宝贵的参考见解。
完整代码,请参阅以下GitHub代码库。
1.使用Amazon SageMaker端点和Amazon SageMaker大模型推理容器,部署DeepSeek模型Quantized LLaMA 3.1 70B Instruct Model:
https://github.com/aws-samples/sagemaker-genai-hosting-examples/blob/main/Deepseek/Deepseek-llama70b-LMI.ipynb
2.在Amazon SageMaker上从HuggingFace Hub部署DeepSeek R1大语言模型:
https://github.com/aws-samples/sagemaker-genai-hosting-examples/blob/main/Deepseek/DeepSeek-R1-Llama8B-LMI-TGI-Deploy.ipynb
3.使用LMI容器在Amazon SageMaker上部署deepseek-ai/DeepSeek-R1-Distill-*模型:
https://github.com/aws-samples/sagemaker-genai-hosting-examples/blob/main/Deepseek/DeepSeek-R1-Distill-TRTLLM.ipynb
4.使用Amazon SageMaker大模型推理容器在Amazon Inferentia上部署DeepSeek R1 Llama:
https://github.com/aws-samples/sagemaker-genai-hosting-examples/blob/main/Deepseek/Deepseek-llama8b-LMI-inferentia.ipynb
5.使用Amazon SageMaker Training和@remote装饰器对基础模型进行交互式微调:
https://github.com/aws-samples/amazon-sagemaker-llm-fine-tuning-remote-decorator
其他相关资源,请参阅以下内容。
Amazon SageMaker文档:
https://docs.aws.amazon.com/sagemaker
Deepseek模型中心:
https://huggingface.co/deepseek-ai
Amazon SageMaker上的Hugging Face:
https://huggingface.co/docs/sagemaker
本篇作者

Dmitry Soldatkin
亚马逊云科技高级人工智能与机器学习解决方案架构师,致力于帮助客户设计和构建人工智能与机器学习解决方案。Dmitry的工作涵盖广泛的机器学习应用场景,聚焦于生成式AI、深度学以及在企业层面推广机器学习,曾帮助过包括保险、金融服务、公用事业和电信等在内的多个行业的公司。

Vivek Gangasani
亚马逊云科技推理领域首席专业解决方案架构师。他协助新兴的生成式AI公司利用亚马逊云科技服务和加速计算能力构建创新解决方案。目前,他专注于开发微调和优化大语言模型推理性能的策略。

Prasanna Sridharan
亚马逊云科技首席生成式AI与机器学习架构师,专注于为企业客户设计和实施人工智能与机器学习以及生成式AI解决方案。他热衷于帮助亚马逊云科技客户构建创新的生成式AI应用,创建可扩展的前沿AI解决方案,以推动业务转型。

Pranav Murthy
亚马逊云科技人工智能与机器学习专业解决方案架构师。专注于帮助客户在Amazon SageMaker上构建、训练、部署和迁移机器学习工作负载。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9467
9467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









