







以GoogLeNet模型为例子说明配置train_val.prototxt训练文件:
模块化结构图:从下往上看
需要用到的caffe.proto文件地址在:caffe-windows\src\caffe\proto可查看。
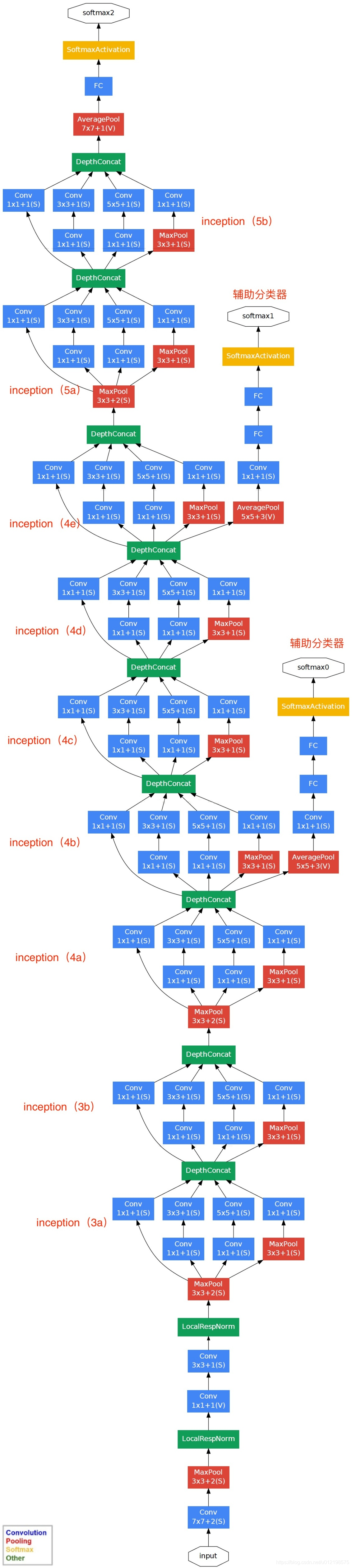
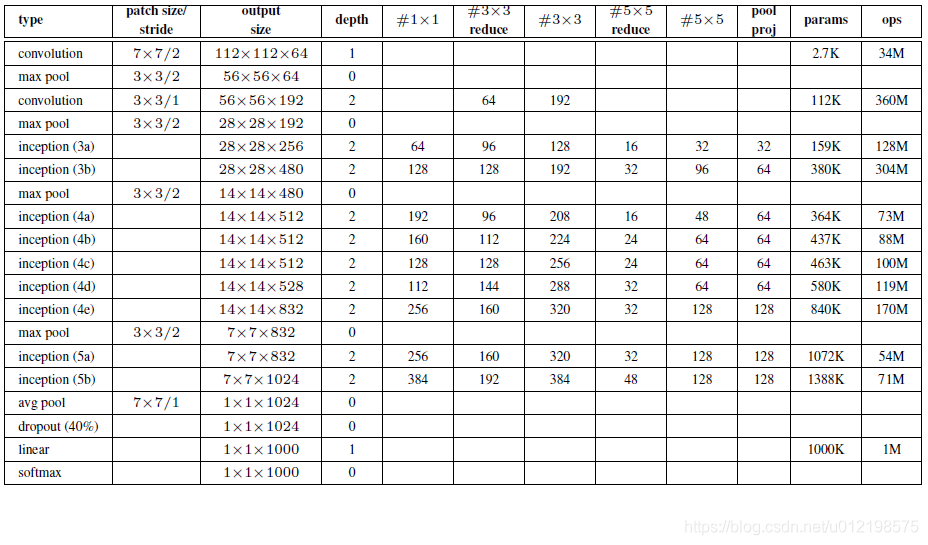
GoogLeNet网络结构明细表解析如下:
0、输入
原始输入图像为224x224x3,且都进行了零均值化的预处理操作(图像每个像素减去均值)。
1、第一层(卷积层)
使用7x7的卷积核(滑动步长2,padding为3),64通道,输出为112x112x64,卷积后进行ReLU操作
经过3x3的max pooling(步长为2),输出为((112 - 3+1)/2)+1=56,即56x56x64,再进行ReLU操作
2、第二层(卷积层)
使用3x3的卷积核(滑动步长为1,padding为1),192通道,输出为56x56x192,卷积后进行ReLU操作
经过3x3的max pooling(步长为2),输出为((56 - 3+1)/2)+1=28,即28x28x192,再进行ReLU操作
3a、第三层(Inception 3a层)
分为四个分支,采用不同尺度的卷积核来进行处理
(1)64个1x1的卷积核,然后RuLU,输出28x28x64
(2)96个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x96,然后进行ReLU计算,再进行128个3x3的卷积(padding为1),输出28x28x128
(3)16个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x16,进行ReLU计算后,再进行32个5x5的卷积(padding为2),输出28x28x32
(4)pool层,使用3x3的核(padding为1),输出28x28x192,然后进行32个1x1的卷积,输出28x28x32。
将四个结果进行连接,对这四部分输出结果的第三维并联,即64+128+32+32=256,最终输出28x28x256
3b、第三层(Inception 3b层)
(1)128个1x1的卷积核,然后RuLU,输出28x28x128
(2)128个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x128,进行ReLU,再进行192个3x3的卷积(padding为1),输出28x28x192
(3)32个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x32,进行ReLU计算后,再进行96个5x5的卷积(padding为2),输出28x28x96
(4)pool层,使用3x3的核(padding为1),输出28x28x256,然后进行64个1x1的卷积,输出28x28x64。
将四个结果进行连接,对这四部分输出结果的第三维并联,即128+192+96+64=480,最终输出输出为28x28x480
第四层(4a,4b,4c,4d,4e)、第五层(5a,5b)……,与3a、3b类似,在此就不再重复。
配置train_val.prototxt文件:
name: "GoogleNet"
layer: 层,有类型为"Convolution" ,"ReLU","Pooling","LRN","Concat","Dropout","InnerProduct", "SoftmaxWithLoss","Accuracy"等
层对应在caffe.proto文件中的"engineParameter"工程参数有:
- ConvolutionParameter //卷积层参数
- PReLUParameter //Relu层参数
- PoolingParameter //池化参数
- LRNParameter //局部归一化参数
- ConcatParameter //拼接层参数:将多特征在指定channel维度进行拼接
- DropoutParameter //剔除参数
- InnerProductParameter //全连接层参数
- LossParameter //损失参数
- AccuracyParameter //正确率参数
举个例子:
根据caffe.proto文件找LayerParameter数据结构:
LayerParameter关键词:(其实不需要这么多,我提取了几个用的到的加以说明)
message LayerParameter {
optional string name = 1; // the layer name
optional string type = 2; // the layer type
repeated string bottom = 3; // the name of each bottom blob
repeated string top = 4; // the name of each top blob// The train / test phase for computation.
optional Phase phase = 10;// The amount of weight to assign each top blob in the objective.
// Each layer assigns a default value, usually of either 0 or 1,
// to each top blob.
repeated float loss_weight = 5;// Specifies training parameters (multipliers on global learning constants,
// and the name and other settings used for weight sharing).
repeated ParamSpec param = 6;// The blobs containing the numeric parameters of the layer.
repeated BlobProto blobs = 7;// Specifies whether to backpropagate to each bottom. If unspecified,
// Caffe will automatically infer whether each input needs backpropagation
// to compute parameter gradients. If set to true for some inputs,
// backpropagation to those inputs is forced; if set false for some inputs,
// backpropagation to those inputs is skipped.
//
// The size must be either 0 or equal to the number of bottoms.
repeated bool propagate_down = 11;// Rules controlling whether and when a layer is included in the network,
// based on the current NetState. You may specify a non-zero number of rules
// to include OR exclude, but not both. If no include or exclude rules are
// specified, the layer is always included. If the current NetState meets
// ANY (i.e., one or more) of the specified rules, the layer is
// included/excluded.
repeated NetStateRule include = 8;
repeated NetStateRule exclude = 9;// Parameters for data pre-processing.
optional TransformationParameter transform_param = 100;// Parameters shared by loss layers.
optional LossParameter loss_param = 101;// Layer type-specific parameters.
//
// Note: certain layers may have more than one computational engine
// for their implementation. These layers include an Engine type and
// engine parameter for selecting the implementation.
// The default for the engine is set by the ENGINE switch at compile-time.
optional AccuracyParameter accuracy_param = 102;
optional ArgMaxParameter argmax_param = 103;
optional BatchNormParameter batch_norm_param = 139;
optional BiasParameter bias_param = 141;
optional ConcatParameter concat_param = 104;
optional ContrastiveLossParameter contrastive_loss_param = 105;
optional ConvolutionParameter convolution_param = 106;
optional CropParameter crop_param = 144;
optional DataParameter data_param = 107;
optional DropoutParameter dropout_param = 108;
optional DummyDataParameter dummy_data_param = 109;
optional EltwiseParameter eltwise_param = 110;
optional ELUParameter elu_param = 140;
optional EmbedParameter embed_param = 137;
optional ExpParameter exp_param = 111;
optional FlattenParameter flatten_param = 135;
optional HDF5DataParameter hdf5_data_param = 112;
optional HDF5OutputParameter hdf5_output_param = 113;
optional HingeLossParameter hinge_loss_param = 114;
optional ImageDataParameter image_data_param = 115;
optional InfogainLossParameter infogain_loss_param = 116;
optional InnerProductParameter inner_product_param = 117;
optional InputParameter input_param = 143;
optional LogParameter log_param = 134;
optional LRNParameter lrn_param = 118;
optional MemoryDataParameter memory_data_param = 119;
optional MVNParameter mvn_param = 120;
optional ParameterParameter parameter_param = 145;
optional PoolingParameter pooling_param = 121;
optional PowerParameter power_param = 122;
optional PReLUParameter prelu_param = 131;
optional PythonParameter python_param = 130;
optional RecurrentParameter recurrent_param = 146;
optional ReductionParameter reduction_param = 136;
optional ReLUParameter relu_param = 123;
optional ReshapeParameter reshape_param = 133;
optional ScaleParameter scale_param = 142;
optional SigmoidParameter sigmoid_param = 124;
optional SoftmaxParameter softmax_param = 125;
optional SPPParameter spp_param = 132;
optional SliceParameter slice_param = 126;
optional TanHParameter tanh_param = 127;
optional ThresholdParameter threshold_param = 128;
optional TileParameter tile_param = 138;
optional WindowDataParameter window_data_param = 129;
}
- optional string name = 1; // 层名
- optional string type = 2; // 层类型
- repeated string bottom = 3; // 上一层名字
- repeated string top = 4; // 下一层名字
- repeated ParamSpec param = 6; // 定义训练集参数 (学习率系数 和 名字 以及权重等)ParamSpec是一个数据结构
- repeated NetStateRule include = 8; //网络状态(是否包含在网络中)内置Phase:Train Or Test
- optional TransformationParameter transform_param = 100; //格式化数据,用于数据准备
ParamSpec关键词:
- optional float lr_mult = 3 [default = 1.0]; // 学习率的系数
- optional float decay_mult = 4 [default = 1.0]; // 权值衰减率
TransformationParameter 数据结构:较为简单不做过多解释
message TransformationParameter {
// For data pre-processing, we can do simple scaling and subtracting the
// data mean, if provided. Note that the mean subtraction is always carried
// out before scaling.
optional float scale = 1 [default = 1];
// Specify if we want to randomly mirror data.
optional bool mirror = 2 [default = false];
// Specify if we would like to randomly crop an image.
optional uint32 crop_size = 3 [default = 0];
// mean_file and mean_value cannot be specified at the same time
optional string mean_file = 4;
// if specified can be repeated once (would subtract it from all the channels)
// or can be repeated the same number of times as channels
// (would subtract them from the corresponding channel)
repeated float mean_value = 5;
// Force the decoded image to have 3 color channels.
optional bool force_color = 6 [default = false];
// Force the decoded image to have 1 color channels.
optional bool force_gray = 7 [default = false];
}
name: "GoogleNet"
layer { #训练参数
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true #镜像:随机水平翻转图片
crop_size: 224
mean_value: 104 #图像中心化 原图各通道减去mean_value
mean_value: 117
mean_value: 123
}
data_param {
source: "examples/imagenet/ilsvrc12_train_lmdb" #数据地址
batch_size: 32 #每次取32张图片训练
backend: LMDB #数据格式LMDB
}
}
layer { #测试参数
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 224
mean_valu 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









