




 本文探讨了在多台服务中如何共同消费Kafka消息,当前采用的方法是随机分区。通过配置和算法设计,确保了分区的生效,并提到存在其他自定义分区策略。
本文探讨了在多台服务中如何共同消费Kafka消息,当前采用的方法是随机分区。通过配置和算法设计,确保了分区的生效,并提到存在其他自定义分区策略。
之前的csdn找不回来了,决定重新注册一个。望支持~~~
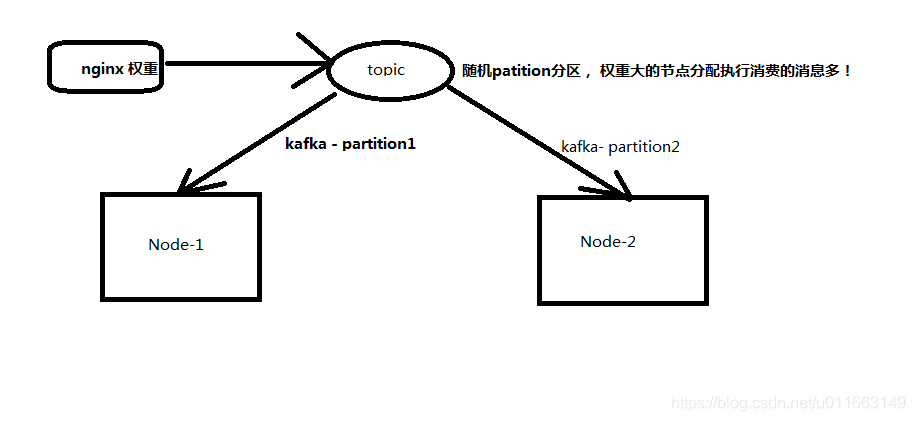
为了解决多台服务,共同消费kafka消息,目前采用的是随机partition。
画了个简图:
/**
* @ClassName: RiskPartitioner
* @author DHing
*
*/
public class RiskPartitioner implements Partitioner {
private Logger LOG = LoggerFactory.getLogger(getClass());
/* (非 Javadoc)
*
*
* @param topic
* @param key
* @param keyBytes
* @param value
* @param valueBytes
* @param cluster
* @return
* @see org.apache.kafka.clients.producer.Partitioner#partition(java.lang.String, java.lang.Object, byte[], java.lang.Object, byte[], org.apache.kafka.common.Cluster)
*这个方法就决定了消息往哪个分区里面发送
这个方法的返回值就是表示我们的数据要去哪个分区,如果返回值是0,表示我们的数据去0分区
*/
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









