




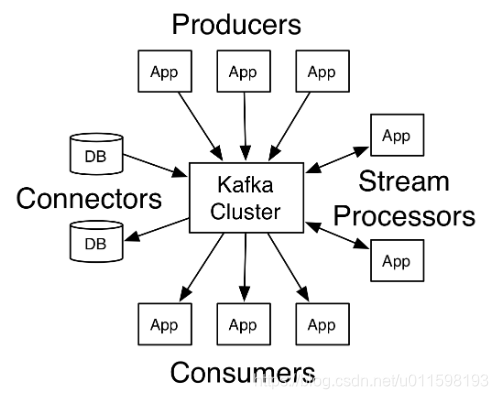
 ApachecKafka是一款强大的分布式流数据处理平台,具备发布订阅、容错存储及实时处理三大特性。广泛应用于实时数据管道搭建及流数据应用构建。Kafka集群通过topics分类存储记录流,支持key-value数据结构,提供Producer、Consumer、Streams及Connector四大核心API,实现高效数据处理。
ApachecKafka是一款强大的分布式流数据处理平台,具备发布订阅、容错存储及实时处理三大特性。广泛应用于实时数据管道搭建及流数据应用构建。Kafka集群通过topics分类存储记录流,支持key-value数据结构,提供Producer、Consumer、Streams及Connector四大核心API,实现高效数据处理。
Apachec Kafka是一个分布式流数据处理平台,有以下3个关键特性:
- 对记录流的
发布和订阅,类似消息队列或消息系统; - 以
容错的方式存储记录流; - 能
实时处理流数据。
Kafka常用于以下2种应用:
- 构建实时流数据管道以从系统或应用中获取数据;
- 构建实时流应用以处理流数据;
为理解Kafka如何工作,首先了解几个概念:
- Kafka作为集群运行在一个或多个服务器上,这些服务器可以跨多个数据中心;
- Kafka集群将记录流存储在称为
topics的类别中; - 每个记录都包含一个key,value和timestamp。
Kafka有4类核心API:
Producer API:负责让应用程序向一个或多个Kafkatopic发送记录流;Consumer API:负责让应用程序订阅一个或多个topic,并处理放松到这些topic上的数据;Streams API:允许应用程序充当流处理器,使用来自一个或多个topic的输入流,并生成到一个或多个输出topic的输出流,从而有效地将输入流转换为输出流;Connector API:允许构建和运行可重用的生产者或消费者,将Kafkatopic连接到现有的应用程序或数据系统。例如,到关系数据库的连接器可能会捕获对表的每次更改。
Topic
Topic是发布记录的类别名称。每个topic允许有0个、1个或多个订阅其数据的消费者。
对每个topic,Kafka集群都维护一个分区日志:
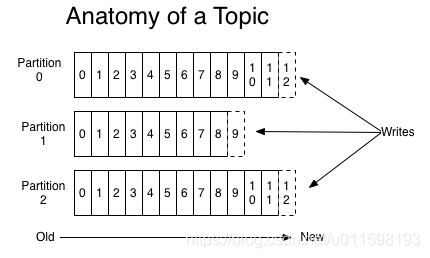
每个分区都是一个有序的、不可变的记录序列,这些记录连续地附加到一个结构化的提交日志中。分区中的每条记录都被分配了一个连续id号(偏移量,offset),该偏移量惟一地标识分区中的每条记录。
实际上,消费者惟一保留的元数据是该消费者在日志中的偏移量。这个偏移量由消费者自己维护:通常消费者在读取记录时将线性地推进它的偏移量,所以它可以按照自己喜欢的任何顺序使用记录。例如,消费者可以重置为较早的偏移量,以便重新处理来自过去的数据,或者跳过到最近的记录,从“现在”开始消费。
这些特性的组合意味着Kafka消费消息非常轻量——他们可以随意消费数据,而不会对集群或其他消费者造成太大影响。例如可以使用命令行工具“跟踪”任何topic的内容,而不需要更改任何现有消费者所使用的内容。
日志中的分区有几个用途:
- 允许日志扩展到超出单个服务器所能容纳的大小:每个单独的分区必须适合承载它的服务器,但是一个主题可能有多个分区,因此它可以处理任意数量的数据;
- 提高并行度。
Distribution
日志的分区分布在Kafka集群中的服务器上,每个服务器处理数据并请求共享分区。为了容错,每个分区被复制到多个可配置的服务器上。
每个分区都有一个充当leader的服务器和0个或多个充当follower的服务器。leader处理分区的所有读和写请求,而follower被动地复制leader。如果leader失败,其中一个follower将自动成为新的leader。每个服务器充当它的某些分区的leader和其他分区的follower,因此集群内的负载非常平衡。
Geo-replication
Kafka MirrorMaker对集群提供异地备份支持,消息可以复制到多个数据中心或云区域,以此提供备份/恢复和数据本地化支持 。
Producer
生产者可以向感兴趣的topic发送数据。哪些记录被发送到哪个topic的哪个分区由生产者决定,这些可以通过轮询的方式以达到负载均衡,也可以通过自定义的分区函数决定。
Consumer
消费者通过一个消费者组名来标记自己,topic的每条消息都只会被发送到每个订阅他的消费者组的一个消费者实例上。
- 如果每个
消费者都属于同一个消费者组,每条消息只会被发送到一个消费者实例处理; - 如果每个
消费者都属于不同的消费者组,消息就会被广播到所有的消费者实例。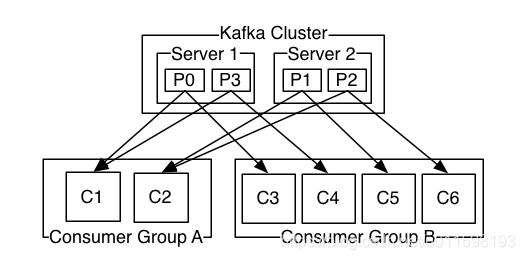

















 4567
4567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









