







 本文介绍如何在MapReduce中自定义Value类型的实现步骤。通过一个具体案例,讲解了自定义TrafficWritable类来处理特定数据格式的方法,并展示了如何实现Writable接口以支持序列化和反序列化。
本文介绍如何在MapReduce中自定义Value类型的实现步骤。通过一个具体案例,讲解了自定义TrafficWritable类来处理特定数据格式的方法,并展示了如何实现Writable接口以支持序列化和反序列化。
序列化在分布式环境的两大作用:进程间通信,永久存储。
Writable接口, 是根据 DataInput 和 DataOutput 实现的简单、有效的序列化对象.
MR的任意Value必须实现Writable接口:

MR的key必须实现WritableComparable接口,WritableComparable继承自Writable和Comparable接口:

(本节先讲自定义value值,下一节再讲自定义key值,根据key值进行自定义排序)
以一个例子说明,自定义数据类型(例子来源于学习的课程):
原始数据是由若干条下面数据组成:
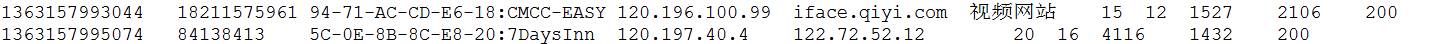
数据格式及字段顺序如下:
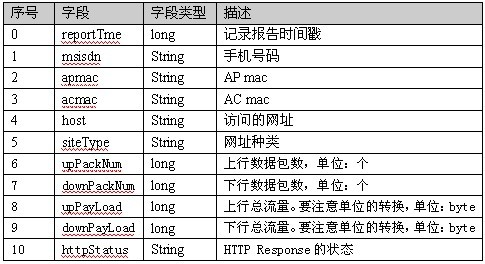
现在要做的工作是以“手机号码”为关键字,计算同一个号码的
upPackNum, downPackNum,upPayLoad,downPayLoad四个累加值
。
运用MapReduce解决问题思路:
1、框架将数据分成<k1,v1>,k1是位置标记,v1表示一行数据;
2、map函数输入
<k1,v1>,输入
<k2,v2>,k2是选定数据的第1列(从0开始),v2是自定义的数据类型,包含第六、七、八、九列封装后的数据;
3、框架将<k2,v2>依据k2关键字进行map排序,然后进行combine过程,再进行Reduce段排序,得到<k2,list(v2...)>;
4、reduce函数处理
<k2,list(v2...)>,以k2为关键字,计算list的内容。
要自定义的数据类型是Value值,因此要继承
Writable接口,
自定义数据类型如下
:
import
java.io.DataInput;
import
java.io.DataOutput;
import
java.io.IOException;
import
org.apache.hadoop.io.Writable;
public
class
TrafficWritable
implements
Writable {
long
upPackNum, downPackNum,upPayLoad,downPayLoad;
public
TrafficWritable() {
//这个构造函数不能省,否则报错
super
();
// TODO Auto-generated constructor stub
}
public
TrafficWritable(String upPackNum, String downPackNum, String upPayLoad,
String downPayLoad) {
super
();
this
.upPackNum = Long.parseLong(upPackNum);
this
.downPackNum = Long.parseLong(downPackNum);
this
.upPayLoad = Long.parseLong(upPayLoad);
this
.downPayLoad = Long.parseLong(downPayLoad);
}
@Override
public
void
write(DataOutput out)
throws
IOException {
//序列化
// TODO Auto-generated method stub
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
}
@Override
public
void
readFields(DataInput in)
throws
IOException {
//反序列化
// TODO Auto-generated method stub
this
.upPackNum=in.readLong();
this
.downPackNum=in.readLong();
this
.upPayLoad=in.readLong();
this
.downPayLoad=in.readLong();
}
@Override
public
String toString() {
//不加toStirng函数,最后输出内存的地址
return
upPackNum +
"\t"
+ downPackNum +
"\t"
+ upPayLoad +
"\t"
+ downPayLoad;
}
}
最后实现map函数和Reduce函数如下,基本框架和wordCount相同:
import
java.io.DataInput;
import
java.io.DataOutput;
import
java.io.IOException;
import
org.apache.hadoop.io.Writable;
public
class
TrafficWritable
implements
Writable {
long
upPackNum, downPackNum,upPayLoad,downPayLoad;
public
TrafficWritable() {
//这个构造函数不能省,否则报错
super
();
// TODO Auto-generated constructor stub
}
public
TrafficWritable(String upPackNum, String downPackNum, String upPayLoad,
String downPayLoad) {
super
();
this
.upPackNum = Long.parseLong(upPackNum);
this
.downPackNum = Long.parseLong(downPackNum);
this
.upPayLoad = Long.parseLong(upPayLoad);
this
.downPayLoad = Long.parseLong(downPayLoad);
}
@Override
public
void
write(DataOutput out)
throws
IOException {
//序列化
// TODO Auto-generated method stub
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
}
@Override
public
void
readFields(DataInput in)
throws
IOException {
//反序列化
// TODO Auto-generated method stub
this
.upPackNum=in.readLong();
this
.downPackNum=in.readLong();
this
.upPayLoad=in.readLong();
this
.downPayLoad=in.readLong();
}
@Override
public
String toString() {
//不加toStirng函数,最后输出内存的地址
return
upPackNum +
"\t"
+ downPackNum +
"\t"
+ upPayLoad +
"\t"
+ downPayLoad;
}
}
最终输出结果如下:
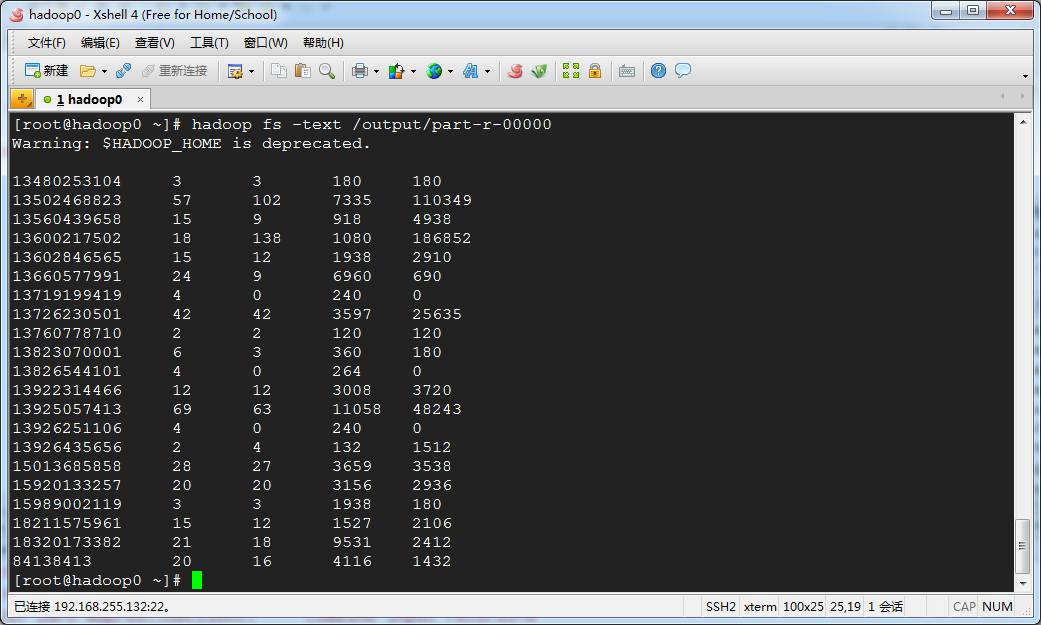
附实验数据下载地址:
https://yunpan.cn/cqcEy6QSzUEs7 访问密码 2fb1。数据来源:网易云课堂hadoop大数据实战

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









