







转载来自个人知乎文章:https://www.zhihu.com/people/yin-xing-pan/
场景:
简单的问答系统,绕不开的是query语句与KB数据库之间的相似匹配。
我们通过分类算法来判断用户的意图,通过命名实体识别来提取实体信息,使用问答框架来控制问答流程和基本话术轮次等。
但最终的核心依然是 语义相似匹配。
https://arxiv.org/pdf/1810.04805.pdfarxiv.org
问题:
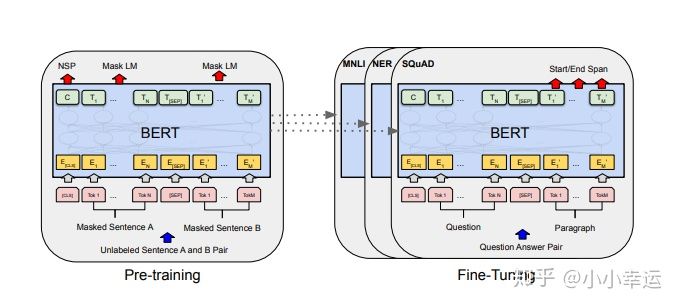
单一的bert模型,通过输入两个语句【query】与KB中的标准问题【key】到一个input中,因为attention原因,会导致模型会将query与key之间相互影响。
详见
https://arxiv.org/pdf/1908.10084.pdfarxiv.org
方案:
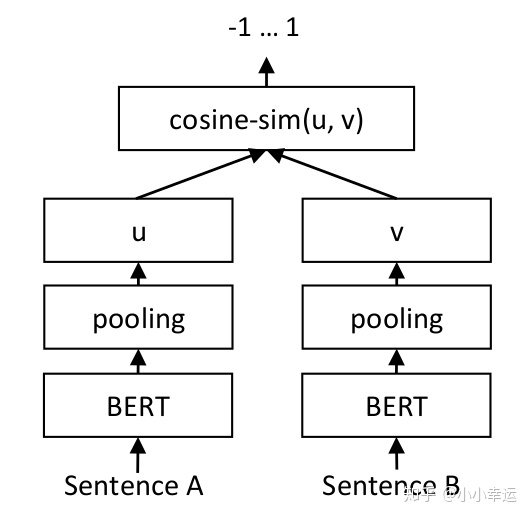
因此孪生bert模型横空出世,使用两个bert结构,参数共享,将独立两个sentence进行训练,
将输出的结果,进行池化,再使用 余弦相似计算作为损失函数或者 连接一个全连接神经网络
进行分类。
工程:
sentence-transformers 为我们提供了模型的实现,实现细节我们后面再detail专栏进行解读
创建虚拟环境:python -m venv venv
激活虚拟环境:
linux: source venv/bin/activate
windows: venv/Scripts/activate.bat
安装pytorch:大于等于1.2.0
pip install torch===1.2.0 torchvision===0.4.0 -f https://download.pytorch.org/whl/torch_stable.html
安装sentence-transformers
pip install sentence-transformers
环境安装完成后,我们需要下载预训练模型,直接使用代码进行下载特别慢,因此查看源码,找到模型下载地址:
Index of /reimers/sentence-transformers/v0.2/public.ukp.informatik.tu-darmstadt.de

SentenceTransformer('distilbert-base-nli-mean-tokens') 加载对应的预训练模型,如果你直接这么写将会进行网络下载,推荐使用
SentenceTransformer('/path/本地下载模型')
from sentence_transformers import SentenceTransformer, SentencesDataset, InputExample, losses
from torch.utils.data import DataLoader
#Define the model. Either from scratch of by loading a pre-trained model
model = SentenceTransformer('distilbert-base-nli-mean-tokens')
#Define your train examples. You need more than just two examples...
train_examples = [InputExample(texts=['My first sentence', 'My second sentence'], label=0.8),
InputExample(texts=['Another pair', 'Unrelated sentence'], label=0.3)]
#Define your train dataset, the dataloader and the train loss
train_dataset = SentencesDataset(train_examples, model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=16)
train_loss = losses.CosineSimilarityLoss(model)
#Tune the model
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=1, warmup_steps=100)
训练完模型后,进行语义搜索
from sentence_transformers import SentenceTransformer, util
import torch
embedder = SentenceTransformer('模型文件')
# Corpus with example sentences, 你在你的kb数据里面的k-v 的标准问题,通过k 就能获取answer
corpus = ['A man is eating food.',
'A man is eating a piece of bread.',
'The girl is carrying a baby.',
'A man is riding a horse.',
'A woman is playing violin.',
'Two men pushed carts through the woods.',
'A man is riding a white horse on an enclosed ground.',
'A monkey is playing drums.',
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder.encode(corpus, convert_to_tensor=True)
# Query sentences: 用户输入的一系列搜索语句
queries = ['A man is eating pasta.', 'Someone in a gorilla costume is playing a set of drums.', 'A cheetah chases prey on across a field.']
# Find the closest 5 sentences of the corpus for each query sentence based on cosine similarity
top_k = 5
for query in queries:
query_embedding = embedder.encode(query, convert_to_tensor=True)
cos_scores = util.pytorch_cos_sim(query_embedding, corpus_embeddings)[0]
cos_scores = cos_scores.cpu()
#We use torch.topk to find the highest 5 scores
top_results = torch.topk(cos_scores, k=top_k)
print("\n\n======================\n\n")
print("Query:", query)
print("\nTop 5 most similar sentences in corpus:")
for score, idx in zip(top_results[0], top_results[1]):
print(corpus[idx], "(Score: %.4f)" % (score))
以上,我们实现了简单版本的相似匹配。
下一步我们一同攻克 知识图谱大关,为我们的问答系统技术实现完成闭环

















 3387
3387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









