




 本文介绍如何在IDEA中使用KafkaConsumer API获取Kafka消费数据,包括创建KafkaConsumer实例,配置Properties工具类及hbase_consumer.properties文件,实现从指定主题连续读取并打印数据。
本文介绍如何在IDEA中使用KafkaConsumer API获取Kafka消费数据,包括创建KafkaConsumer实例,配置Properties工具类及hbase_consumer.properties文件,实现从指定主题连续读取并打印数据。
在IDEA中通过api获取kafka消费的数据
1、创建KafkaConsumer
package kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import utils.PropertiesUtil;
import java.util.Arrays;
/**
* @author tony
* @version v1.0.0 2019-02-27 下午 10:14
*/
public class HBaseConsumer {
public static void main(String[] args){
KafkaConsumer<String,String> kafkaConsumer = new KafkaConsumer<>(PropertiesUtil.properties);
kafkaConsumer.subscribe(Arrays.asList(PropertiesUtil.getProperty("kafka.topics")));
while(true){
ConsumerRecords<String,String> records = kafkaConsumer.poll(100);
for(ConsumerRecord<String,String> cr : records){
String orivalue = cr.value();
System.out.println(orivalue);
}
}
}
}
2、配置工具类PropertiesUtil
package utils;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
/**
* @author tony
* @version v1.0.0 2019-02-27 下午 9:51
*/
public class PropertiesUtil {
public static Properties properties = null;
static {
//获取配置文件,方便维护
InputStream is = ClassLoader.getSystemResourceAsStream("hbase_consumer.properties");
properties = new Properties();
try {
properties.load(is);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 获取参数值
* @param key
* @return
*/
public static String getProperty(String key){
return properties.getProperty(key);
}
}
3、hbase_consumer.properties配置文件
# 设置kafka的brokerlist
bootstrap.servers=bigdata121:9092,bigdata122:9092,bigdata123:9092,bigdata124:9092,bigdata125:9092
# 设置消费者所属的消费组
group.id=hbase_consumer_group
# 设置是否自动确认offset
enable.auto.commit=true
# 自动确认offset的时间间隔
auto.commit.interval.ms=30000
# 设置key,value的反序列化类的全名
key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 以下为自定义属性设置
# 设置本次消费的主题
kafka.topics=calllog
# 设置HBase的一些变量
hbase.calllog.regions=6
hbase.calllog.namespace=ns_ct
hbase.calllog.tablename=ns_ct:calllog
该配置文件需要放在resource目录下
在window中的hosts文件中定义好集群主机名和ip之间的映射关系
在服务器启动
zk集群
zkServer.sh start
kafka集群
bin/kafka-server-start.sh config/server.properties &
启动flume搜集数据
bin/flume-ng agent --conf /root/hd/flume/conf/ --name a1 --conf-file /root/flume-kafka.conf
启动数据生成脚本
sh data.sh
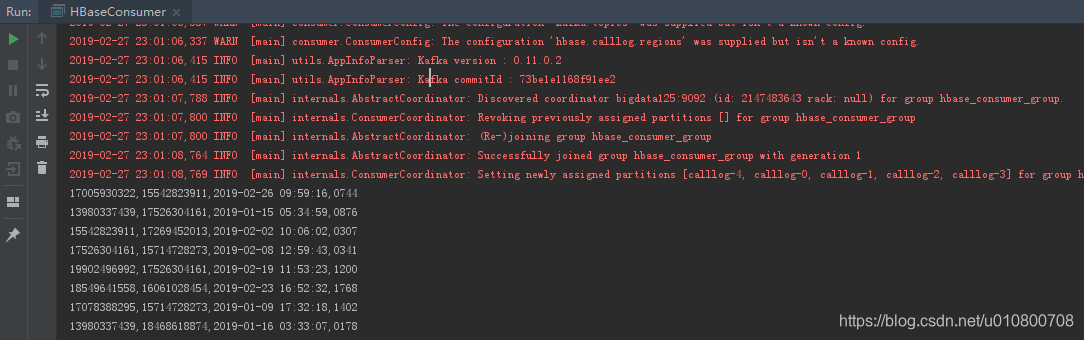
idea运行main程序,就可以看到控制台打印的数据了。

















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









