




最近研究了一下GraphRAG,写了一个文档转换工具还有图可视化工具,结合langchain构建RAG经验,还有以前的数据平台,做了一个知识库概要设计,具体应用欢迎留言探讨。
一、GraphRAG整体概述
GraphRAG图基检索增强生成,从原始文本中提取知识图谱、构建社区层次结构、为这些社区生成摘要,然后在执行基于RAG的任务时利用这些结构。旨在利用知识图谱和大语言模型(LLMs)来提升信息处理能力和问答能力。而标准RAG是一种基础版本的检索增强生成架构,采用前置处理流程,通过chunk方式来切割文档,使用纯文本片段的朴素语义进行搜索。
当面临以下情况时,GraphRAG比标准RAG有更好的表现:当一些实体(名词)占比比较小,通过标准RAG无法正确召回时;当希望通过实体关系正向和反向查询内容,通过实体关系实现很正确召回时;通过GlobalSearch对整体进行总结和洞见时。
二、图基检索增强生成平台架构

基本思路:
[用户端]
│
▼
[文档预处理层] → 统一文本化
│
▼
[GraphRAG索引管道] → 知识图谱构建
│
▼
[检索与问答引擎] → 用户交互接口
1、文档预处理模块
输入: 支持PDF(含扫描件)/DOCX/IMG/HTML/TXT等文件类型
处理流程:
主要利用Marker处理扫描版PDF(OCR识别),MarkitDown处理结构化文档,使用LLM增强可以对于文档中出现的图片进行描述以及提高pdf扫描件的识别准确性和处理速度,最后统一输出UTF-8编码的TXT文件。
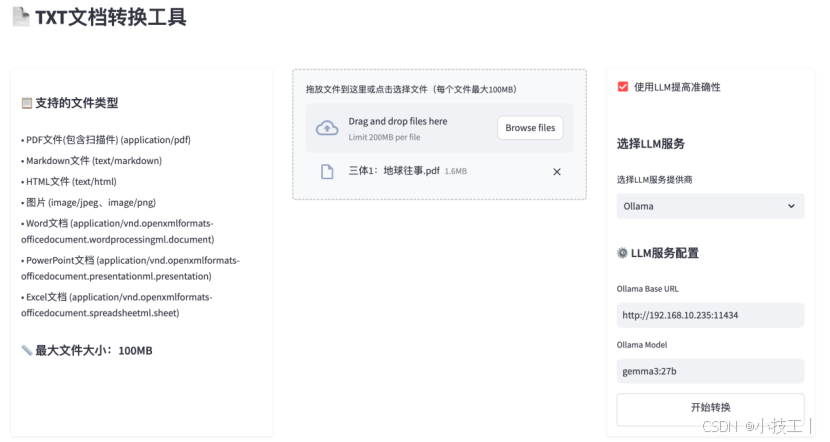
这个工程是利用streamlit构建的一个简单的app,通过上传一个或多个文件,转换txt后批量下载一个zip文件。如果涉及扫描件或者图谱建议勾选“使用LLM提高准确性”。
实践挑战:上述流程主要是对各类文档进行文本提取,实际还需要对提取的文本进行清洗,提高文本质量,作为graphrag索引管道的输入,文本质量关系着构建的知识图谱的质量。
2、GraphRAG索引管道
**输入:**经过预处理的txt文档。
处理流程:
通过运行GraphRAG索引管道,会将输入语料库切成一系列TextUnits,这些TextUnits充当流程其余部分的可分析单元,并在我们的输出中提供细粒度的引用。关于知识图谱提取是使用配置的LLM(支持lm-studio本地大模型)来抽取这些实体、关系、社区等信息,使用Leiden 技术对图形执行分层聚类,这有助于全面了解数据集。
下图是基本的工作流:
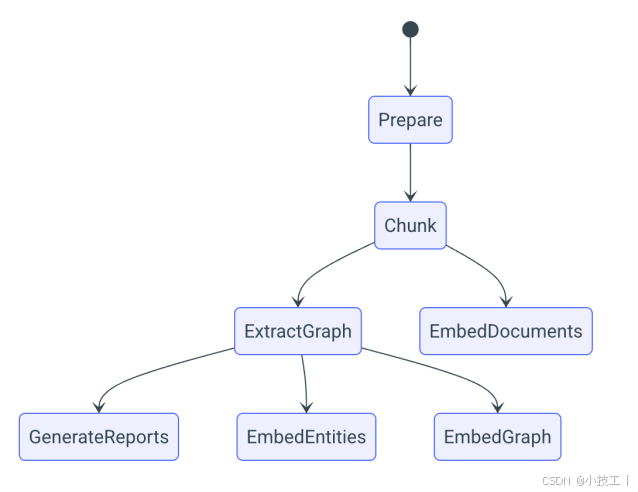
默认情况下,管道的输出存储为本地Parquet文件,嵌入将写入默认配置的lancedb矢量存储。
实践挑战:
- 知识图谱提取需用到LLM,会消耗大量的token,估算token数量级是个挑战。
- 实践中使用的大模型不同,需要相应的优化提示词,graphrag提供的prompt auto tune效果不太理想。实际测试下来,在社区报告提取过程中经常报错,需要手动优化提示词。
- 管道输出的数据默认存储在本地文件(parquet和lancedb),如果结合其他数据源通过langchain或llamaindex实现多路召回,则需要实现指定数据库的接入。可以使用postgresql数据同AEG和pgvector拓展实现图和向量查询,或者分别接入单独的图数据库和向量数据库,例如neo4j和Milvus。
- 知识图谱质量评估也是一个挑战。不过可以通过图形化展示很直观的看到:点、边、社区等信息。其次,就是提供给LocalSearch中对应的entitylD,GlobalSearch中的community reqportID引用信息,并根据这些ID获取进一步信息,进行查询和可视化展示。
下图仅为知识图谱可视化展示:
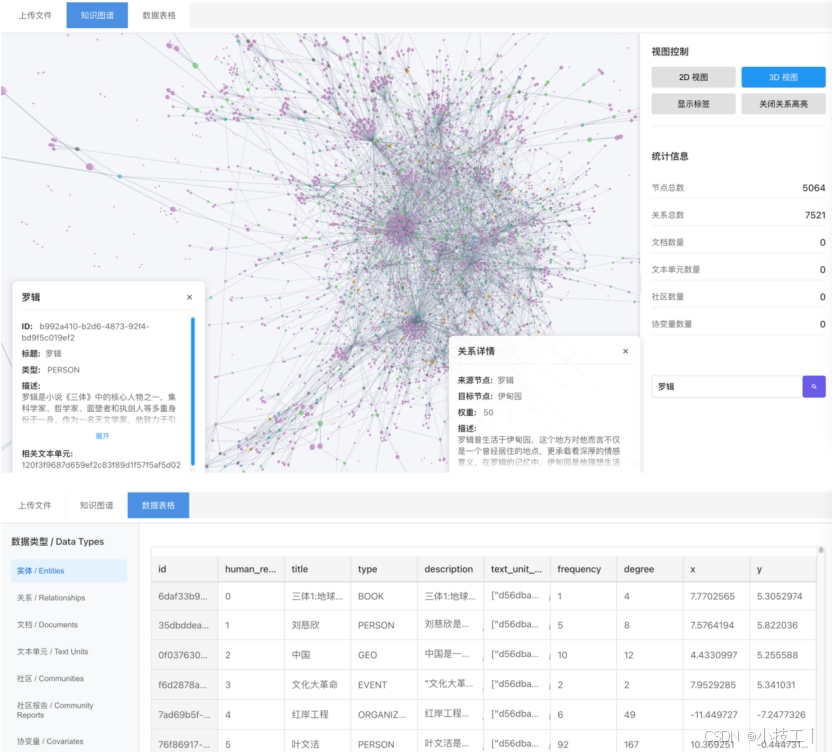
这个工程分成前后端,可以上传对应的parque文件,存入postgres数据库,前端查询出实体和关系信息解析成2d或3d图形,同时提供parque文件对应的table。其中主要使用 react-force-graph-2d 和 react-force-graph-3d来构建2d或3d图形。目前可以通过查询模式,或者点击交互模式,找到对应节点信息和关系信息。
3、检索与问答引擎
GraphRAG的查询接口主要有LocalSearch、GlobalSearch和Driftsearch。
- LocalSearch主要是将知识图谱中的结构化数据与输入文档中的非结构化数据相结合,能够在查询时使用相关实体信息来增强LLM上下文。它非常适合回答需要了解输入文档中提到的特定实体的问题。
- GlobalSearch主要使用来自图的社区信息和社区报告作为LLM的上下文,对于需要聚合数据、集中信息来组成答案的全局查询有很好的支持。
- Driftsearch具有灵活遍历的动态推理,结合了全局搜索和本地搜索的特征,以平衡计算成本和质量结果的方法生成详细的响应。
localsearch 和标准rag一样,只查找相关实体缩关联的社区信息,构建查询上下文,对于全局类型的问题不能很好的回答。而GlobalSearch过程需要遍历某一层的社区,如果对应的知识图谱巨大的,社区很多的话,需要消耗大量的token,花费很长时间才能得到最终答案。DriftSearch就是在两种采取一个权衡。
4、graphrag实践挑战
- 1)实际使用速度比较慢,主要原因包括:
- 初始化时间:加载知识图谱
- 查询复杂度:通过向量查询实体,构建上下文
- LLM调用:调用LLM,生成token
时间成本、价格成本主要是在llm调用上,可以通过提示词工程优化。目前能优化的点主要就是:提示词优化和增加大语言模型的理解次数。
- 2)难以评估graphrag好坏,除了rag评估的主要指标,知识图谱质量评估也是一个挑战。
改进RAG的两个方向:对数据进行处理,提高数据质量和索引。对检索生成的结果进行评估。
5、检索增强生成评估
Ragas 框架提供了一系列工具和技术,借助 Ragas可以合成生成一个多样化的测试数据集客观的衡量RAG系统性能。后面研究看看。


















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











