




1 概述
1.1 消息分区
微观分区信息:
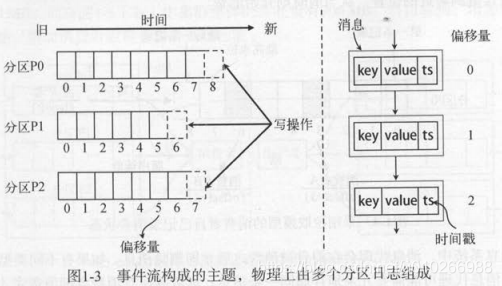
宏观分区信息:
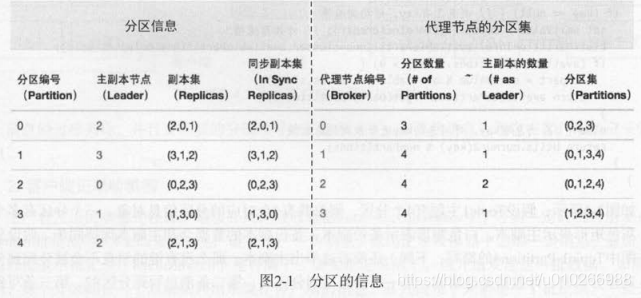
如何保证消息消费的顺序性?
1)同一分区内的消息是有序的;
2)设置消息key,相同key的消息会发到同一个分区。
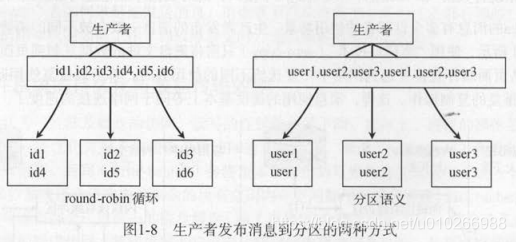
1.2 生产者发送消息
消息没有Key——轮询;
消息有Key——根据key选择分区。
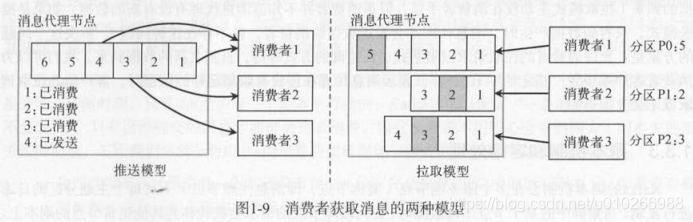
1.3 消费模型
推拉(push/poll)模型,kafka选择了拉,由消费者主动获取消息 并记录消费进度。
老版本的kafka的消费进度保存在zk中,新版本的在服务端开启了一个专用主题 _offset_topic 用于记录消费进度。
拉取模型的缺点:需要不断轮询。解决办法:拉取请求以阻塞式、长轮询的方式等待,或者拉取指定数量的字节。
1.4 文件持久化
利用磁盘缓存和零拷贝技术提升文件持久化和传输性能。
1.5 副本机制
每个分区会有若干个备份副本:
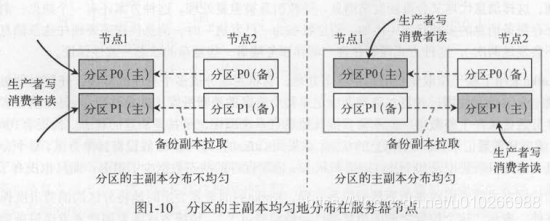
ISR副本(In-Sync Replicas):
1)节点必须和ZK保持会话;
2)如果这个节点是某个分区的备份副本,它必须对分区主副本的写操作进行复制,并且复制的进度不能落后太多 。
客户端针对分区的读写请求,只能发生在分区的主副本上。
副本选主机制:
kafka使用多副本机制保证高可用,即每个分区都会有多个副本,其中主副本负责消息的读、写,备份副本只用来备份数据、不参与客户端的读写。那么当分区创建、分区上线或者分区重分配的时候,kafka是怎么选出分区的leader副本的呢?
早期用zk,会产生脑裂和羊群效应。现在用Kafka Controller。
(1)阶段1:用zk选出Kafka Controller。
所有broker在zk中创建临时节点 /controller,创建成功的那个broker成为Kafka Controller。当/controller节点被删除或数据发生变化时,会触发新一轮选举。
zk中会维护一个持久节点 /controller_epoch记录当前的控制器是第几代控制器,所有与控制器交互的请求都会携带controller_epoch字段,用于判断该请求是否已过期。
(2)阶段2:用Kafka Controller选出主副本。
按照AR(分区的所有副本)集合中副本的顺序查找第一个存活的副本,并且该副本在ISR(同步中的副本)集合中。
2 生产者
2.1 同步、异步发送消息
异步:
prod.send(new ProducerRecord(), new Callback(){
@Override
public void onCompletion() {
...
}
})同步:
prod.send(new ProducerRecord()).get()总结:
1)异步加了回调
2)同步在send方法返回的Future加get阻塞住。
3)同步和异步的底层都是异步发送
2.2 生产者发送消息经历的过程
------------ 以下操作都在客户端完成 -----------------
1)为消息选择分区(PartitionInfo)
消息没有key,使用轮询得方式挨个选择分区;
消息有key,计算hash,对分区数进行求余运算,得到分区编号。
2) 记录收集器(RecordAccumulator)
收集器维护一个批记录(RecordBatch),一批记录满了才会发送出去,否则继续攒消息。
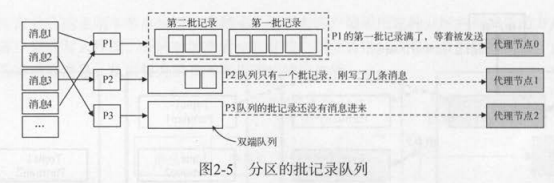
3)消息发送线程
按分区直接发送、按分区的目标节点发送,kafka选择了按分区的目标节点发送,减少网络开销。
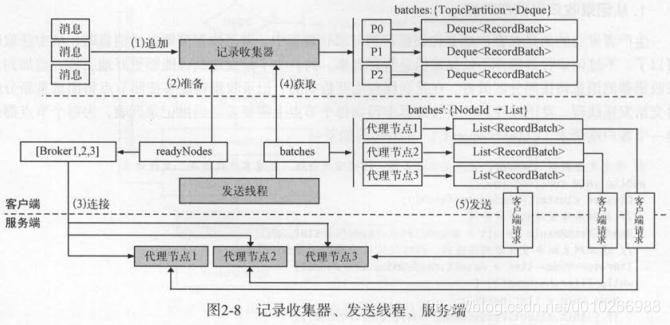
4) 客户端网络连接对象
NetworkClient
ready(): 从记录收集器获取准备完毕的节点,并连接所有准备好的节点;
send():为每个节点创建一个客户端连接,将请求暂存在节点对应的通道(InFlightRequests)中,没有真正发送出去;
poll():真正执行网络请求,向节点发送请求、读取相应。
InFlightRequests:
InFlightRequests类包含一个节点到双端队列的映射结构 。 在准备发送客户端请求时,请求将添加到指定节点对应的队列中;在收到响应后 ,才会将请求从队列中移除 。
发送限制:
针对同一个服务端,如果上一个客户端请求还没有发送完成,则不允许发送新的客户端请求。
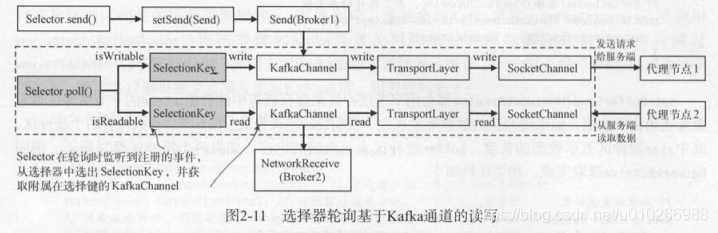
5)选择器
生产者客户端会按照节点对消息进行分组,每个节点对应一个客户端请求,那么一个生产者客户端需要管理到多个服务端节点的网络连接。
SelectionKey.attach( KafkaChannel),将kafka通道和选择器绑定。
3 消费者
3.1 消费者分组
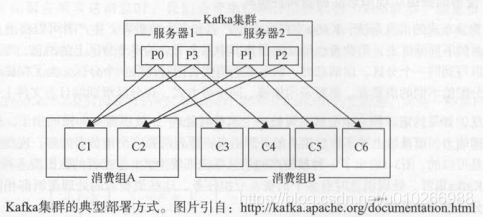
对同一个消费组来说,一个分区只能分给一个消费者,但一个消费者可以消费多个分区。
准确的说,“一个分区只能被一个消费者中的一个线程处理”。
基于分组实现消息的广播和单播:
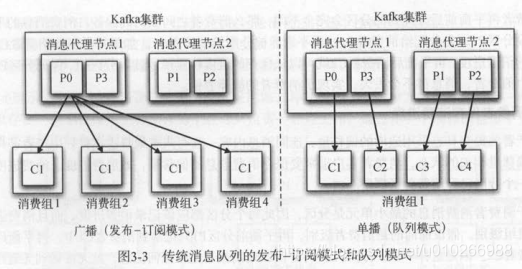
3.2 消费者保存消费进度
老版本的消费进度保存在zk,新版本的保存在服务端的一个特殊主题(_consumer_offsets)里。
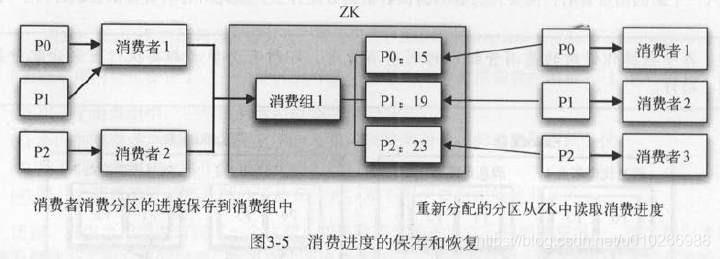
虽然分区是以消费者级别被消费的,但分区的消费进度要保存成消费组级别的 。
消费者再均衡时,能获取到消费组的消费进度,接着往后消费。
3.3 消费者拉取消息
使用队列作为缓冲:
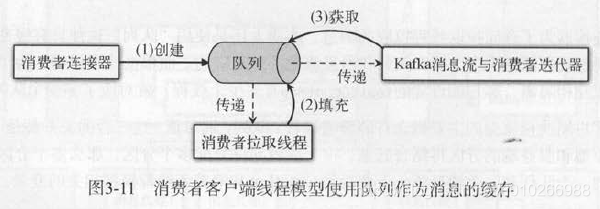
每个线程都对应一个队列,每个队列 都对应了一个消息流,只要队列中有数据,就能从消息流中迭代读取出消息。
消费者拉取消息的过程:
消费者拉取管理器在创建拉取线程时, 会将表示分区及其分区信息对象的全局partitionMap作为
类级别的变量传给每个拉取线程,但每个拉取线程在拉取时实际上只会负责一部分的分区。拉取线程
在拉取到分区数据后,需要将拉取结果保存到分区信息的队列中。
消费者和备份副本拉取消息的区别:
Kafka中有两种对象会拉取消息一一消费者和备份副本,消费者的偏移量保存在zk,备份副本的偏移量保存在自己本地内存。

消费者和备份剧本的拉取线程在收到拉取消息后处理方式不同,比如备份副本会把数据写到自己
本地的日志文件中,消费者则会把数据填充到分区信息对象的队歹lj 中供消费者客户端应用程序获取。
新版消费者:
使用异步请求(RequestFuture)拉取消息
3.4 消费者提交分区偏移量
提交偏移量的时机涉及几种传递语义:
1)At most once:先提交再处理
2)At least once:先处理再提交
3)Exactly once:重复消息+幂等
偏移量提交到哪?
1)提交到zk
由消费者提交到zk,但其实记录的是消费组的偏移量。
缺点:消费者每次提交分区偏移量都要和zk通信一次,如果集群中的分区很多,成千上万的分区,所有消费者都和zk通信会产生大量网络请求,会产生性能问题。
2)提交到kafka内部主题(_consumer_offsets)
这个内部主题也是有多个分片的。
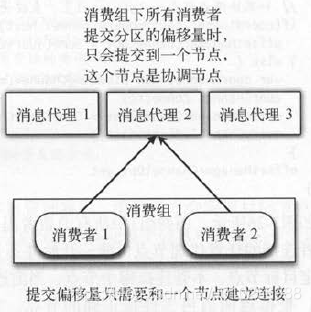
每个消费组只连接一个节点是最好的,这个节点负宽管理一个消费组所有消费者所有分区的偏移量, 叫作偏移量管理器(OffsetManager)。
4 Spring中使用kafka
4.1 生产者
新建Producer配置文件:
<!-- 定义producer的参数 -->
<bean id="producerProperties" class="java.util.HashMap">
<constructor-arg>
<map>
<entry key="bootstrap.servers" value="#{disconfPropertiesReader['kafka.bootstrap.servers']}"/>
<entry key="clusterName" value="#{disconfPropertiesReader['kafka.cluster.name']}" />
<entry key="acks" value="all"/>
<entry key="retries" value="1"/>
<entry key="batch.size" value="5"/>
<entry key="linger.ms" value="1"/>
<entry key="key.serializer" value="org.apache.kafka.common.serialization.StringSerializer"/>
<entry key="value.serializer" value="org.apache.kafka.common.serialization.StringSerializer"/>
</map>
</constructor-arg>
</bean>
<!-- 创建kafkaTemplate bean,使用的时候,只需要注入这个bean,即可使用template的send消息方法 -->
<bean id="testKafkaTemplate" class="org.springframework.kafka.core.KafkaTemplate">
<constructor-arg ref="producerFactory"/>
<constructor-arg name="autoFlush" value="true"/>
<property name="defaultTopic" value="${kafka.xxx.topic}"/>
</bean>新建Producer类:
@Service
public class TestKafkaProducer {
@Resource
private KafkaTemplate<String, String> testKafkaTemplate;
public void asyncSendMessage(String message) {
testKafkaTemplate.sendDefault(message)
.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(final SendResult<String, String> message) {
LogConstant.BUS.info("kafka sent success, message={}, with offset={}.", message,
message.getRecordMetadata().offset());
}
@Override
public void onFailure(final Throwable throwable) {
LogConstant.BUS.error("kafka sent callback onFailure, message={}.", message, throwable);
// 添加报警
}
});
}
}
4.2 消费者
新建Consumer配置文件:
<bean id="commentConsumerProperties" class="java.util.HashMap">
<constructor-arg>
<map>
<entry key="bootstrap.servers" value="${kafka.xxx.brokers}"/>
<entry key="group.id" value="${xxx.kafka.group.id}"/>
<entry key="clusterName" value="${xxx.kafka.cluster.name}"/>
<entry key="enable.auto.commit" value="false"/>
<entry key="session.timeout.ms" value="60000"/>
<entry key="max.partition.fetch.bytes" value="10485760"/>
<entry key="key.deserializer" value="org.apache.kafka.common.serialization.StringDeserializer"/>
<entry key="value.deserializer" value="org.apache.kafka.common.serialization.StringDeserializer"/>
</map>
</constructor-arg>
</bean>新建Producer类:
public class GoodsCommentConsumer implements BatchAcknowledgingMessageListener<String, String> {
@Override
public void onMessage(List<ConsumerRecord<String, String>> consumerRecords, Acknowledgment acknowledgment) {
if (CollectionUtils.isEmpty(consumerRecords)) {
return;
}
consumerRecords.forEach(record -> {
String recordValue = record.value();
if (StringUtils.isBlank(recordValue)) {
return;
}
try {
// 消息转成Bean、幂等落库
} catch (Exception e) {
}
});
// 处理完一批消息后手动提交offset
acknowledgment.acknowledge();
}
}
5 其他
5.1 RocketMQ与Kafka对比
https://www.cnblogs.com/BYRans/p/6100653.html
5.2 RocketMq事务消息
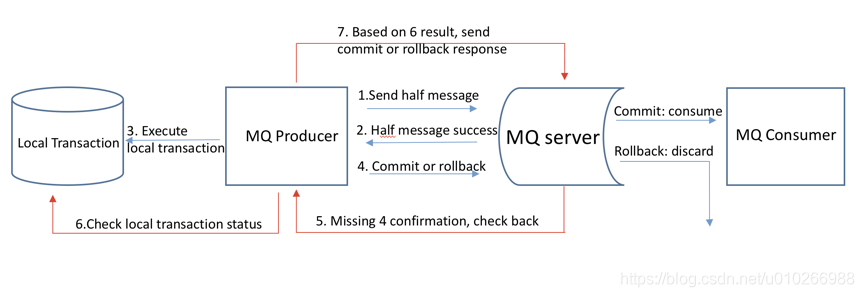
rocketMq会有一个half message的概念,就是消息虽然投递到server了,但是消费者还拿不到,要本地事务提交成功之后,commit这个half message,消费者才能拉取到。

















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









