







 本文介绍了一种利用Hadoop MapReduce进行数据预处理的方法,包括数据清洗、格式化及输出处理等步骤,实现了从原始数据到可用于数据分析的目标数据转换。
本文介绍了一种利用Hadoop MapReduce进行数据预处理的方法,包括数据清洗、格式化及输出处理等步骤,实现了从原始数据到可用于数据分析的目标数据转换。
Hadoop大数据招聘网数据分析综合案例
- Hadoop大数据综合案例1-Hadoop2.7.3伪分布式环境搭建
- Hadoop大数据综合案例2-HttpClient与Python招聘网数据采集
- Hadoop大数据综合案例3-MapReduce数据预处理
- Hadoop大数据综合案例4-Hive数据分析
- Hadoop大数据综合案例5-SSM可视化基础搭建
- Hadoop大数据综合案例6–数据可视化(SpringBoot+ECharts)
由于海量数据的来源是广泛的,数据类型也是多而繁杂的,因此,数据中会夹杂着不完整的、重复的以及错误的数据,如果直接使用这些原始数据的话,会严重影响数据决策的效率。因此,对原始数据进行预处理是大数据分析和应用过程中的关键环节。
数据分析
查看我们采集的数据,通过观察它的数据结构以及分析我们所需要的维度选择合适的预处理方案。
通过JSON格式化工具对数据文件page1的数据内容进行格式化处理,查看储存了职位信息的result字段。
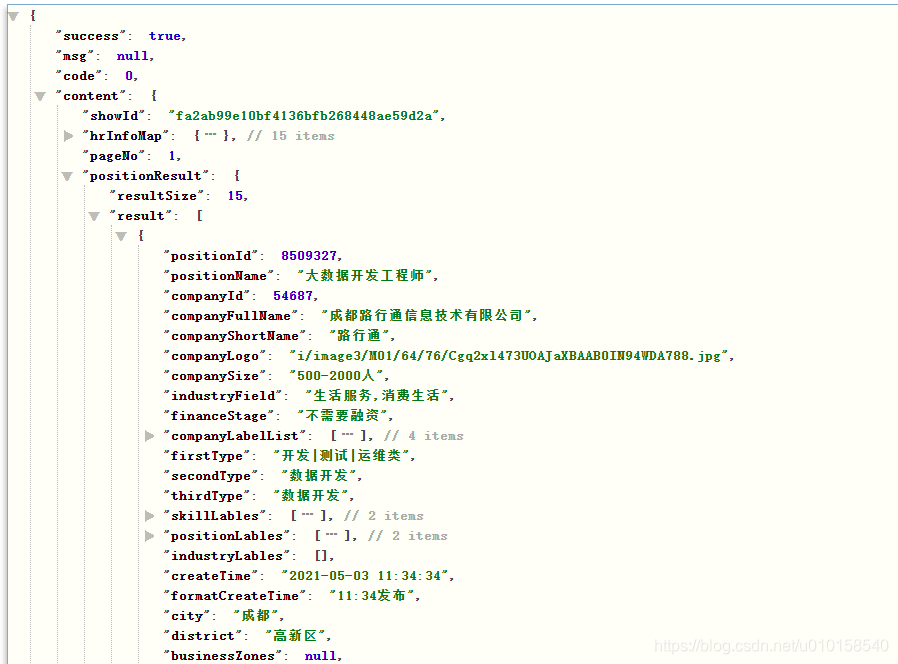
MapReduce程序实现数据预处理的过程
通过编写MapReduce程序,实现将采集的源数据进行预处理得到目标数据的过程。

JSON数据清洗代码实现
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
package org.apache.ssm;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.codehaus.jackson.JsonNode;
import org.codehaus.jackson.map.ObjectMapper;
import java.io.IOException;
public class ClearDataJob {
// Mapper类
public static class ClearDataMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
// jackson 实例对象,用于JSON数据解析
private ObjectMapper mapper = new ObjectMapper();
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 把每一行数据转换为JSON对象JsonNode
JsonNode jsonNode = mapper.readTree(value.toString());
// 获取content对象下的positionResult对象下的result集合
JsonNode nodes = jsonNode.get("content").get("positionResult").get("result");
// 遍历result集合,获取每一条招聘信息数据
for (JsonNode node : nodes) {
// 获取招聘信息数据中的city维度,并转换为字符串类型
String city = node.get("city").asText();
// 获取招聘信息数据中的salary维度,转换为字符串类型,把工资中的单位k去除
String salary = node.get("salary").asText().replaceAll("k", "");
// 获取招聘信息数据中的companyLabelList维度,并调用自定义方法把数组转为指定分隔符的字符串
String company = JsonNodeToStr(node.get("companyLabelList"), "-");
// 获取招聘信息数据中的skillLables维度,并调用自定义方法把数组转为指定分隔符的字符串
String skill = JsonNodeToStr(node.get("skillLables"), "-");
// 把要输出文件的维度传递给自定义方法join,并指定分割符,返回拼接好的字符串
Text info = join(",", city, salary, company, skill);
//System.out.println(info);
// 把清洗后的招聘信息写到指定的输出文件中
context.write(info, NullWritable.get());
}
}
/**
* @apiNote 根据输入的字符串和分割符拼接字符串
* @param sep 分割符
* @param args 各维度数据,是一个可变参数数组
* @return 返回根据指定分割符拼接好的字符串
*/
private Text join(String sep, String... args) {
StringBuffer sb = new StringBuffer();
for (String arg : args) {
sb.append(arg).append(sep);
}
return new Text(sb.substring(0,sb.length()-1));
}
/**
* @apiNote 遍历JsonNode数组,根据指定分割符返回对应的字符串
* @param nodes JsonNode数组或集合
* @param sep 分割符
* @return 返回拼接好的字符串
*/
private String JsonNodeToStr(JsonNode nodes,String sep) {
StringBuffer sb = new StringBuffer();
for (JsonNode node : nodes) {
sb.append(node.asText()).append(sep);
}
return sb.length() == 0 ? "" : sb.substring(0, sb.length() - 1);
}
}
// 程序运行主方法
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ClearDataJob.class);
// 指定输入输出的文件格式
job.setInputFormatClass(CombineTextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
// 指定Mapper类以及输出key和value的类型
job.setMapperClass(ClearDataMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 指定输入和输出文件所在路径,如果输出文件路径已经存在则删除
FileInputFormat.setInputPaths(job, new Path("hdfs://node:9000/lagou/20210503/*"));
Path path = new Path("E:\\lagou\\output");
FileSystem fs = path.getFileSystem(conf);
if (fs.exists(path)) {
fs.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
// 执行MapReduce任务,并关闭文件系统
System.exit(job.waitForCompletion(true) ? 0 : 1);
fs.close();
System.out.println("清洗完毕..");
}
}
Permission denied: user=Administrator, access=WRITE, inode="/lagou_output/_temporary/0":root:supergroup:drwxr-xr-x
在hdfs-site.xml 文件中指定权限设置:dfs.permissions.enabled=false,即可
上海,10-13,,Oracle-SQL-hive-Cognos
上海,10-15,带薪年假-岗位晋升-领导好-五险一金,数据仓库-Hadoop-Spark-Hive
上海,10-18,,Spark
上海,10-18,绩效奖金-五险一金-带薪年假-年度旅游,Hadoop-Spark
上海,10-20,通讯津贴-交通补助-双休-弹性工作,自动化测试-系统软件测试-CDP
上海,12-18,股票期权-绩效奖金-专项奖金-年底双薪,数据仓库-Hadoop-MySQL
上海,12-20,节日礼物-年底双薪-专项奖金-带薪年假,DBA-数据仓库-MySQL-SQLServer
上海,12-20,节日礼物-年底双薪-专项奖金-带薪年假,数据仓库-DBA
上海,12-24,项目奖金-零食无限量-牛逼的同事-境外旅游,
上海,13-19,年底双薪-带薪年假-交通补助-通讯津贴,Hadoop
上海,13-25,股票期权-扁平化管理-万亿市场-绩效奖金,Hive-MySQL-Hadoop-Spark
................................
修改输入输出路径打jar包
修改main方法,添加参数判断以及参数路径读取
if (args.length != 2) {
System.err.println("Usage: yarn jar <jarPath> <in> <out>");
System.exit(2);
}
// 指定输入和输出文件所在路径,如果输出文件路径已经存在则删除
FileInputFormat.setInputPaths(job, new Path(args[0]));
Path path = new Path(args[1]);
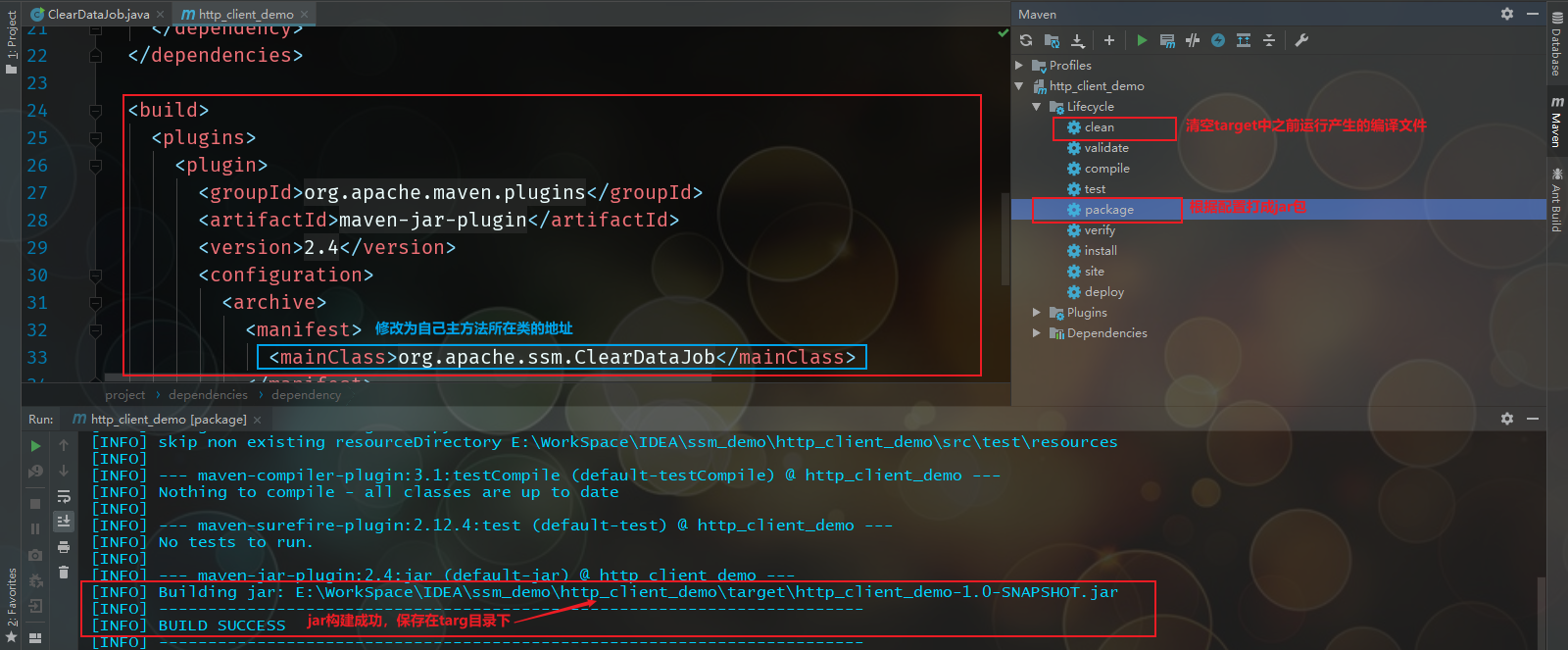
修改pom.xml文件,追加打包插件和配置主方法所在类路径
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<mainClass>org.apache.ssm.ClearDataJob</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
把jar上传到linux系统中执行
[root@node ~]# yarn jar http_client_demo-1.0-SNAPSHOT.jar /lagou/20210503 /lagou/output

下一章 使用Hive对各维度数据进行分析,把分析结果使用Sqoop工具导出到MySQL数据库中,后续使用Java开源框架SSM进行操作,方便ECharts图表展示


















 1971
1971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











