




原文连接:https://www.c-sharpcorner.com/article/C-Sharp-heaping-vs-stacking-in-net-part-i/
引言
虽然使用.NET Framework时我们不需要主动关心内存管理和垃圾回收,但为了保证程序的性能,对内存管理和垃圾回收还是应该有必要的了解。从根本上理解内存管理的工作方式,也可以帮助我们理解在项目中使用的每一个变量是如何工作的。在本篇中将带你一起了解堆和栈的基础,变量的类型以及他们是如何工作的。
在程序运行的过程中,.NET Framework将对象存储在两个空间里。如果你还不知道,我这就给你介绍一下栈(Stack)和堆(Heap),这俩东西都在帮助我们运行代码。他们寄存在设备的操作内存中,并包含我们程序运行所需要的所有信息。
堆和栈的区别
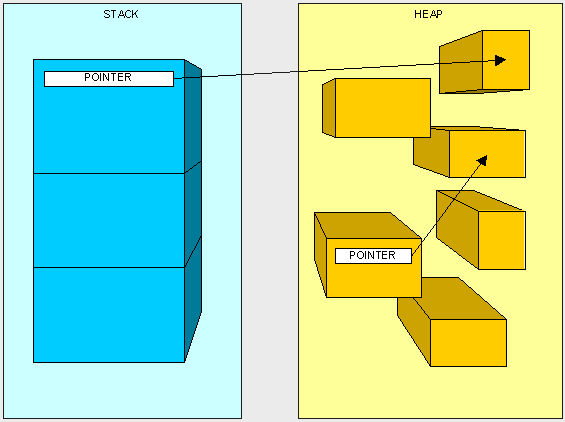
栈主要负责存储指令,堆主要负责保存对象和数据。
栈就像是一摞盒子,一个压着一个。每当我们调用一个方法(有时候也叫帧"frame")时,就会在栈的顶部压入一个指令用来告诉我们的程序该干什么。我们只能获取到最顶端的那个盒子。当我们最顶端的盒子用完以后(方法执行完毕)就把它扔掉,继续使用早先放进来的顶部的盒子。不同的是,堆是为了存储信息,而不关心命令的执行,所以堆中的任何信息都可以被随时访问到。在堆中没有像栈一样的读写限制。堆就像是我们洗好了但是没有整理的散乱在床上的衣服,我们可以快速的拿到我们想要的。栈就像是我们在壁橱中已经摞好的鞋盒,我们必须拿走上面的,才能得到下面的。
(译者曰:内存中的栈和数据结构的栈的性质是一样的,都是后进先出)

上图中的内容不能正确的表示在内存中的运行情况,只是为了帮助理解堆和栈的区别。
栈是自我维护的,也就是说他们主要关心自己的内存管理。当顶部的盒子已经不再使用以后,就会被取出来。至于堆,则需要考虑垃圾回收(GC),以保持堆的整洁(没有人希望到处都是的脏衣服,还散发出臭臭的味道)。
堆和栈上都有什么?
在代码运行的过程中,我们主要有四种类型的东东被放在堆和栈里面:值类型(Value Types)、引用类型(Reference Types)、指针(Pointers)、指令(Instructions)。
值类型
C#中,下面的所有类型都是值类型,因为他们都继承自System.ValueType:
- bool
- byte
- char
- decimal
- double
- enum
- float
- int
- long
- sbyte
- short
- struct
- uint
- ulong
- ushort
引用类型
下面列出的都是引用类型,他们继承自System.Object:
- class
- interface
- delegate
- object
- string
指针
第三种类型是类型的引用(a Reference to a Type),也就是指针。(译者注:在C#中)我们不会显示的使用指针,因为他们被CLR管理。指针和引用类型不同,当我们在说啥啥啥是引用类型的时候,意思是说我们通过指针来访问它。指针在内存中存储的内容是其他内存空间的地址。指针空间的开辟和我们在堆栈上开辟其他东东的空间一样,它的值可以是内存地址,也可以是Null。
指令
后面的内容将告诉你,指令是如何工作的...
怎样决定什么东西该去哪里?
记住这两条金科玉律:
- 引用类型一定去到堆中。这条够简单。
- 值类型和指针一般来说在哪里声明的就去到哪里。这条一丢丢的复杂,需要对栈的工作方式有一定的了解以后,才能分辨出这些东东是在哪里声明的。
栈在代码运行过程中用来表示各自线程(Thread)的进度。你可以把它理解为线程的状态,并且每个线程都有自己的栈。当代码在执行一个方法时,线程就开始执行那些被编译出来的在这个方法表中的指令,这会将该方法的参数压入到线程的栈中。当我们在执行这个方法时,会将遇到的变量也都压入到栈的顶部。举个栗子理解起来会更简单......
运行下面的代码:
public int AddFive(int pValue)
{
int result;
result = pValue + 5;
return result;
} 接下来看一下在栈的最顶部到底做了什么。切记,我们看到的这个栈,已经放了其他内容到里面。
当我们开始执行这个方法的时候,方法的参数首先被压入到栈内(之后我们会详细的讨论参数传递的问题)。
注意:这个方法是不再栈中的,只是作为参考。

然后,如果方法是第一次被执行,则会进行JIT编译,编译出的指令被加入到方法的表中。

在执行方法的时候,我们需要一定的内存留给result变量,它也被分配在栈中。

方法执行结束以后,我们得到被返回的result。

通过将指向可用内存的指针移动到AddFive()方法开始的地方,可以将栈中分配的内存清理掉,然后我们就可以访问上一个被装进栈中的方法了。

在这个例子中,变量result被分配到栈中,事实上,所有的在方法内部声明的值类型的变量,都会被分配在栈中。
现在,再来看看什么时候值类型会被分配到堆中。还记得这条规则吗,值类型在哪里声明的就到哪里去。当然,如果一个值类型声明在方法外部,但是在引用类型的内部,它就会跟着这个引用类型一起被分配到堆中。
再举个栗子。
假设我们有下面这个MyInt类,因为它是个class类型,所以它是个引用类型:
public class MyInt
{
public int MyValue;
} 并且将执行下面的这个方法:
public MyInt AddFive(int pValue)
{
MyInt result = new MyInt();
result.MyValue = pValue + 5;
return result;
} 跟前面一样,线程在执行这个方法的时候,会把它的参数也压入到栈中。
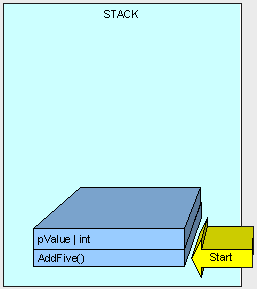
见证奇迹的时刻...
因为MyInt是一个引用类型,被分配在堆中,并且被一个栈中的指针所引用。

像第一个例子中一样,当AddFive方法执行完毕以后,我们执行清理...
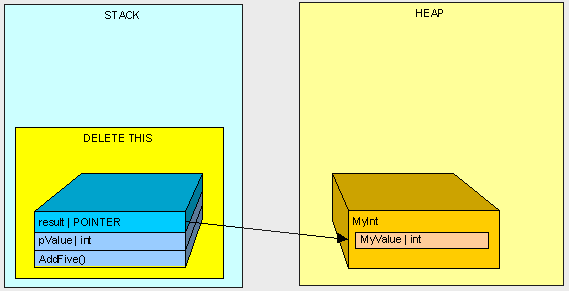
之后再也没有对MyInt的引用了,它成了堆中的孤儿。
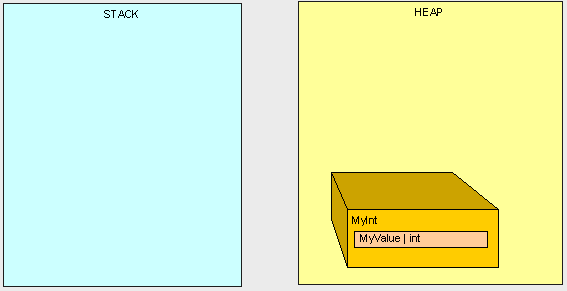
这时候就轮到GC表演了。当我们的程序达到一定的内存上限时,GC就会闪亮登场。GC会将所有的线程挂起(A FULL STOP),然后查找堆中的所有已经没用的对象,并且删除他们。然后GC会对堆中剩下的对象进行整理并且修改引用到这些对象的指针,不管是堆中的还是栈中的。你可以想象,这会造成巨大的内存开销。这也就时为什么对于编写高性能的代码来说,关注堆栈中的内容这么重要了。
(译者注:GC的详解看这里)
好吧,太棒了,但这对我有什么影响呢?
好问题!
当我们在使用引用类型时,我们是通过指针来完成的,而不是这个对象本身。当我们在使用值类型的时候,我们使用的是这个对象本身。这样说也许还不够清楚。
我们再来举个栗子。
假设我们执行下面的方法:
public int ReturnValue()
{
int x = new int();
x = 3;
int y = new int();
y = x;
y = 4;
return x;
} 我们将得到3这个值,很简单对吧。
如果我们使用之前的那个MyInt类:
public class MyInt
{
public int MyValue;
} 然后我们执行下面的这个方法:
public int ReturnValue2()
{
MyInt x = new MyInt();
x.MyValue = 3;
MyInt y = new MyInt();
y = x;
y.MyValue = 4;
return x.MyValue;
} 我们会得到什么?...4!
咋回事呢?x.MyValue怎么就变成4了呢?看看我们做的是不是有意义:
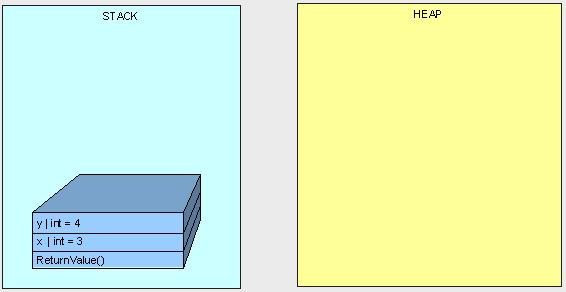
在第一个栗子里一切都在计划内执行的:
public int ReturnValue()
{
int x = 3;
int y = x;
y = 4;
return x;
} 
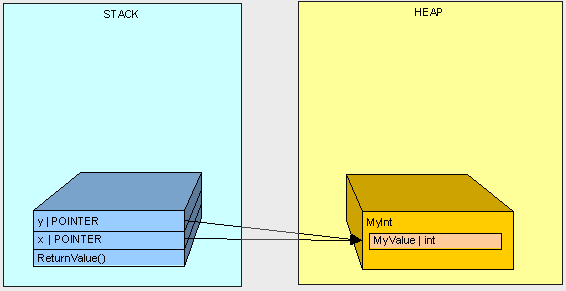
在后面的栗子里,我们没有得到预期的3。因为变量x和y的指针都指向了堆中的同一个对象。
public int ReturnValue2()
{
MyInt x;
x.MyValue = 3;
MyInt y;
y = x;
y.MyValue = 4;
return x.MyValue;
} 
希望这能够帮助你对值类型和引用类型的本质区别有更好的理解,并且对C#中的指针有基本的理解。在本系列的下一节中,我们将进一步讨论内存的管理,并具体讨论方法的参数问题。
Happy coding.

















 4126
4126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









