







 超级会员免费看
超级会员免费看
 本文详细介绍了Spark 1.6及之后的内存管理,包括executor.memory如何包含spark.memory.fraction,以及堆内和堆外内存的划分。堆外内存可通过spark.memory.offHeap.size配置,并探讨了Execution和Storage内存的动态借用。文章还提到了统一内存管理的内存区域,如Execution Memory、Storage Memory、Other/User Memory和Reserved Memory,以及它们在总内存中的比例分配。
本文详细介绍了Spark 1.6及之后的内存管理,包括executor.memory如何包含spark.memory.fraction,以及堆内和堆外内存的划分。堆外内存可通过spark.memory.offHeap.size配置,并探讨了Execution和Storage内存的动态借用。文章还提到了统一内存管理的内存区域,如Execution Memory、Storage Memory、Other/User Memory和Reserved Memory,以及它们在总内存中的比例分配。
spark1.6及之后:
堆内内存:
spark.executor.memory 包含 spark.memory.fraction;
spark.memory.fraction 包含 spark.memory.storageFraction;
spark.executor.memory = reserved memory(300MB)+usable memory
usable memory = unified memory(60%,spark.memory.fraction) + other(40%,1-spark.memory.fraction)
unified memory = storage memory(50%,spark.memory.storageFraction) + execution memory (1-spark.memory.storageFraction)
堆外内存:
通过 spark.memory.offHeap.enabled 参数开启,并由 spark.memory.offHeap.size 指定堆外内存的大小,单位是字节(占用的空间划归 JVM OffHeap 内存)。
堆外内存只区分 Execution 内存和 Storage 内存:
spark.memory.offHeap.size = storage memory(50%,spark.memory.storageFraction) + execution memory (1-spark.memory.storageFraction)
storage memory = 堆内storage memory + 堆外storage memory
execution memory = 堆内execution memory + 堆外execution memory
spark 2.4.5
Application Properties
| Property Name | Default | Meaning |
|---|---|---|
spark.app.name | (none) | The name of your application. This will appear in the UI and in log data. |
spark.driver.cores | 1 | Number of cores to use for the driver process, only in cluster mode. |
spark.driver.maxResultSize | 1g | Limit of total size of serialized results of all partitions for each Spark action (e.g. collect) in bytes. Should be at least 1M, or 0 for unlimited. Jobs will be aborted if the total size is above this limit. Having a high limit may cause out-of-memory errors in driver (depends on spark.driver.memory and memory overhead of objects in JVM). Setting a proper limit can protect the driver from out-of-memory errors. |
spark.driver.memory | 1g | Amount of memory to use for the driver process, i.e. where SparkContext is initialized, in the same format as JVM memory strings with a size unit suffix ("k", "m", "g" or "t") (e.g. 512m, 2g).Note: In client mode, this config must not be set through the SparkConf directly in your application, because the driver JVM has already started at that point. Instead, please set this through the --driver-memory command line option or in your default properties file. |
spark.driver.memoryOverhead | driverMemory * 0.10, with minimum of 384 | The amount of off-heap memory to be allocated per driver in cluster mode, in MiB unless otherwise specified. This is memory that accounts for things like VM overheads, interned strings, other native overheads, etc. This tends to grow with the container size (typically 6-10%). This option is currently supported on YARN and Kubernetes. |
spark.executor.memory | 1g | Amount of memory to use per executor process, in the same format as JVM memory strings with a size unit suffix ("k", "m", "g" or "t") (e.g. 512m, 2g). |
spark.executor.pyspark.memory | Not set | The amount of memory to be allocated to PySpark in each executor, in MiB unless otherwise specified. If set, PySpark memory for an executor will be limited to this amount. If not set, Spark will not limit Python's memory use and it is up to the application to avoid exceeding the overhead memory space shared with other non-JVM processes. When PySpark is run in YARN or Kubernetes, this memory is added to executor resource requests. NOTE: Python memory usage may not be limited on platforms that do not support resource limiting, such as Windows. |
spark.executor.memoryOverhead | executorMemory * 0.10, with minimum of 384 | The amount of off-heap memory to be allocated per executor, in MiB unless otherwise specified. This is memory that accounts for things like VM overheads, interned strings, other native overheads, etc. This tends to grow with the executor size (typically 6-10%). This option is currently supported on YARN and Kubernetes. |
Memory Management
| Property Name | Default | Meaning |
|---|---|---|
spark.memory.fraction | 0.6 | Fraction of (heap space - 300MB) used for execution and storage. The lower this is, the more frequently spills and cached data eviction occur. The purpose of this config is to set aside memory for internal metadata, user data structures, and imprecise size estimation in the case of sparse, unusually large records. Leaving this at the default value is recommended. For more detail, including important information about correctly tuning JVM garbage collection when increasing this value, see this description. |
spark.memory.storageFraction | 0.5 | Amount of storage memory immune to eviction, expressed as a fraction of the size of the region set aside by spark.memory.fraction. The higher this is, the less working memory may be available to execution and tasks may spill to disk more often. Leaving this at the default value is recommended. For more detail, see this description. |
spark.memory.offHeap.enabled | false | If true, Spark will attempt to use off-heap memory for certain operations. If off-heap memory use is enabled, then spark.memory.offHeap.size must be positive. |
spark.memory.offHeap.size【堆外内存】 | 0 | The absolute amount of memory in bytes which can be used for off-heap allocation. This setting has no impact on heap memory usage, so if your executors' total memory consumption must fit within some hard limit then be sure to shrink your JVM heap size accordingly. This must be set to a positive value when spark.memory.offHeap.enabled=true. |
spark.memory.useLegacyMode | false | Whether to enable the legacy memory management mode used in Spark 1.5 and before. The legacy mode rigidly partitions the heap space into fixed-size regions, potentially leading to excessive spilling if the application was not tuned. The following deprecated memory fraction configurations are not read unless this is enabled: spark.shuffle.memoryFractionspark.storage.memoryFractionspark.storage.unrollFraction |
spark.shuffle.memoryFraction | 0.2 | (deprecated) This is read only if spark.memory.useLegacyMode is enabled. Fraction of Java heap to use for aggregation and cogroups during shuffles. At any given time, the collective size of all in-memory maps used for shuffles is bounded by this limit, beyond which the contents will begin to spill to disk. If spills are often, consider increasing this value at the expense of spark.storage.memoryFraction. |
spark.storage.memoryFraction | 0.6 | (deprecated) This is read only if spark.memory.useLegacyMode is enabled. Fraction of Java heap to use for Spark's memory cache. This should not be larger than the "old" generation of objects in the JVM, which by default is given 0.6 of the heap, but you can increase it if you configure your own old generation size. |
spark.storage.unrollFraction | 0.2 | (deprecated) This is read only if spark.memory.useLegacyMode is enabled. Fraction of spark.storage.memoryFraction to use for unrolling blocks in memory. This is dynamically allocated by dropping existing blocks when there is not enough free storage space to unroll the new block in its entirety. |
spark.storage.replication.proactive | false | Enables proactive block replication for RDD blocks. Cached RDD block replicas lost due to executor failures are replenished if there are any existing available replicas. This tries to get the replication level of the block to the initial number. |
spark.cleaner.periodicGC.interval | 30min | Controls how often to trigger a garbage collection. This context cleaner triggers cleanups only when weak references are garbage collected. In long-running applications with large driver JVMs, where there is little memory pressure on the driver, this may happen very occasionally or not at all. Not cleaning at all may lead to executors running out of disk space after a while. |
spark.cleaner.referenceTracking | true | Enables or disables context cleaning. |
spark.cleaner.referenceTracking.blocking | true | Controls whether the cleaning thread should block on cleanup tasks (other than shuffle, which is controlled by spark.cleaner.referenceTracking.blocking.shuffle Spark property). |
spark.cleaner.referenceTracking.blocking.shuffle | false | Controls whether the cleaning thread should block on shuffle cleanup tasks. |
spark.cleaner.referenceTracking.cleanCheckpoints | false | Controls whether to clean checkpoint files if the reference is out of scope. |
http://spark.apache.org/docs/2.4.5/configuration.html#available-properties
spark.memory.fractionexpresses the size ofMas a fraction of the (JVM heap space - 300MB) (default 0.6). The rest of the space (40%) is reserved for user data structures, internal metadata in Spark, and safeguarding against OOM errors in the case of sparse and unusually large records.spark.memory.storageFractionexpresses the size ofRas a fraction ofM(default 0.5).Ris the storage space withinMwhere cached blocks immune to being evicted by execution.
The value of spark.memory.fraction should be set in order to fit this amount of heap space comfortably within the JVM’s old or “tenured” generation. See the discussion of advanced GC tuning below for details.
http://spark.apache.org/docs/2.4.5/tuning.html#memory-management-overview
首先我们知道在执行 Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种 JVM 进程,前者为主控进程,负责创建 Spark 上下文,提交 Spark 作业(Job),并将作业转化为计算任务(Task),在各个 Executor 进程间协调任务的调度,后者负责在工作节点上执行具体的计算任务,并将结果返回给 Driver,同时为需要持久化的 RDD 提供存储功能。由于 Driver 的内存管理相对来说较为简单,本文主要对 Executor 的内存管理进行分析,下文中的 Spark 内存均特指 Executor 的内存。
另外,Spark 1.6 之前使用的是静态内存管理 (StaticMemoryManager) 机制,StaticMemoryManager 也是 Spark 1.6 之前唯一的内存管理器。在 Spark1.6 之后引入了统一内存管理 (UnifiedMemoryManager) 机制,UnifiedMemoryManager 是 Spark 1.6 之后默认的内存管理器,1.6 之前采用的静态管理(StaticMemoryManager)方式仍被保留,可通过配置 spark.memory.useLegacyMode 参数启用。这里仅对统一内存管理模块 (UnifiedMemoryManager) 机制进行分析。
Executor内存总体布局
默认情况下,Executor不开启堆外内存,因此整个 Executor 端内存布局如下图所示:
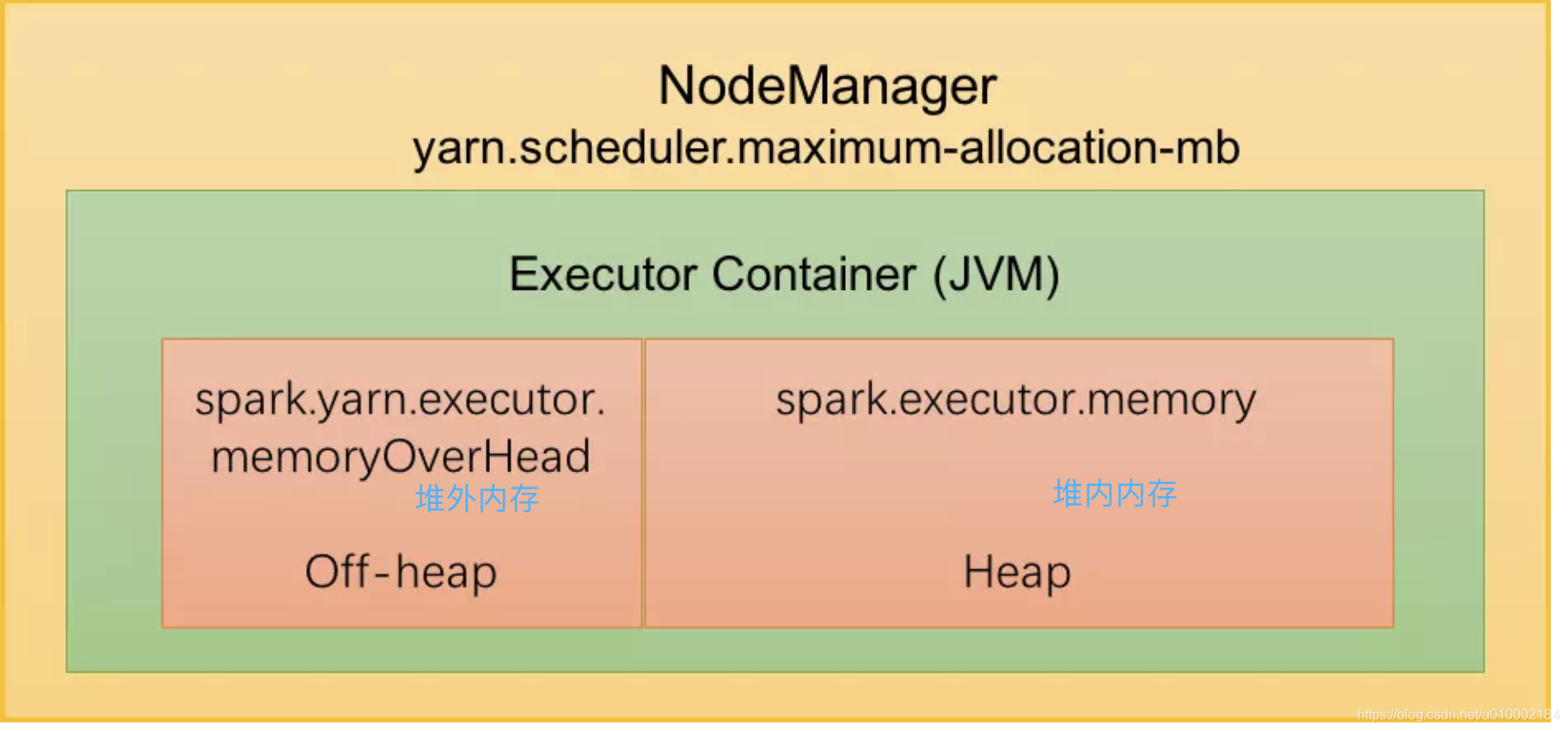
我们可以看到在Yarn集群管理模式中,Spark 以 Executor Container 的形式在 NodeManager 中运行,其可使用的内存上限由 yarn.scheduler.maximum-allocation-mb 指定,我们称之为 MonitorMemory。
整个Executor内存区域分为两块:
1、JVM堆外内存
大小由 spark.yarn.executor.memoryOverhead 参数指定。默认大小为 executorMemory【由spark.executor.memory配置】 * 0.10, with minimum of 384m。
此部分内存主要用于JVM自身,字符串, NIO Buffer(Driect Buffer)等开销。此部分为用户代码及Spark 不可操作的内存,不足时可通过调整参数解决。
The amount of off-heap memory (in megabytes) to be allocated per executor. This is memory that accounts for things like VM overheads, interned strings, other native overheads, etc. This tends to grow with the executor size (typically 6-10%).
2、堆内内存(ExecutorMemory)
大小由 Spark 应用程序启动时的 –executor-memory 或 spark.executor.memory 参数配置,即JVM最大分配的堆内存 (-Xmx)。Spark为了更高效的使用这部分内存,对这部分内存进行了逻辑上的划分管理。我们在下面的统一内存管理会详细介绍。
NOTES
对于Yarn集群,存在: ExecutorMemory + MemoryOverhead <= MonitorMemory,若应用提交之时,指定的 ExecutorMemory 与 MemoryOverhead 之和大于 MonitorMemory,则会导致 Executor 申请失败;若运行过程中,实际使用内存超过上限阈值,Executor 进程会被 Yarn 终止掉 (kill)。
统一内存管理
Spark 1.6之后引入了统一内存管理,包括了堆内内存 (On-heap Memory) 和堆外内存 (Off-heap Memory) 两大区域,下面对这两块区域进行详细的说明。
堆内内存 (On-heap Memory)
默认情况下,Spark 仅仅使用了堆内内存。Spark 对堆内内存的管理是一种逻辑上的“规划式”的管理,Executor 端的堆内内存区域在逻辑上被划分为以下四个区域:
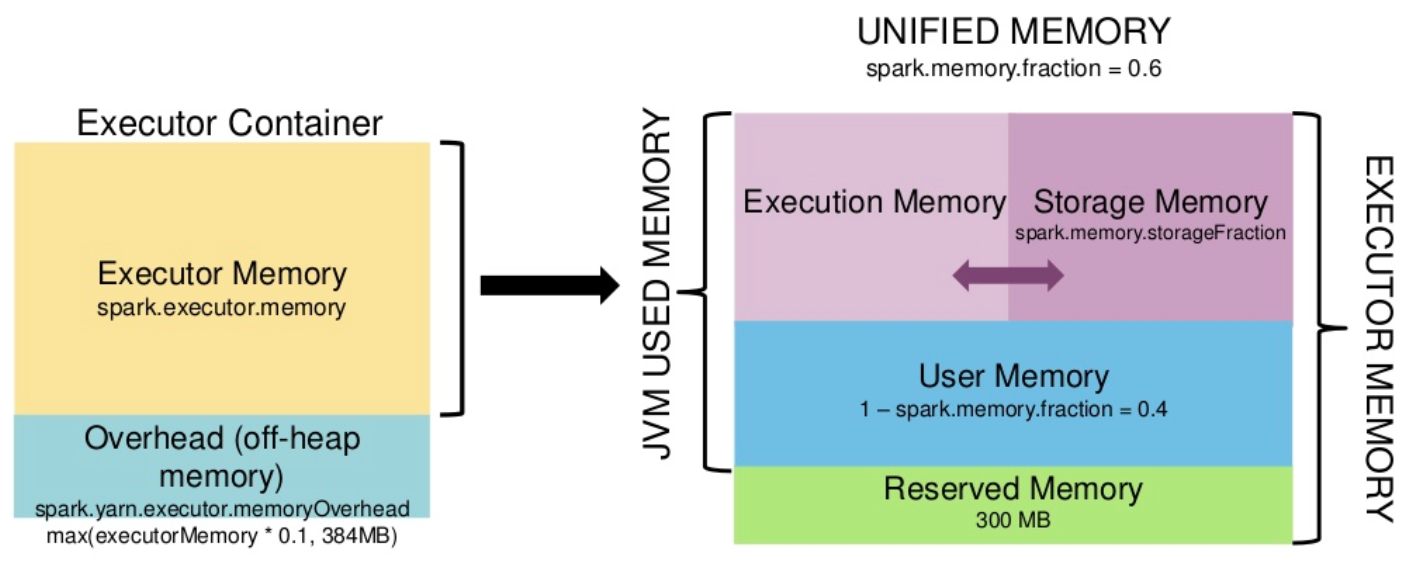
- 执行内存 (Execution Memory) : 主要用于存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据;
- 存储内存 (Storage Memory) : 主要用于存储 spark 的 cache 数据,例如RDD的缓存、unroll数据;
- 用户内存(User Memory): 主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息;
- 预留内存(Reserved Memory): 系统预留内存,会用来存储Spark内部对象。
下面的图对这个四个内存区域的分配比例做了详细的描述:
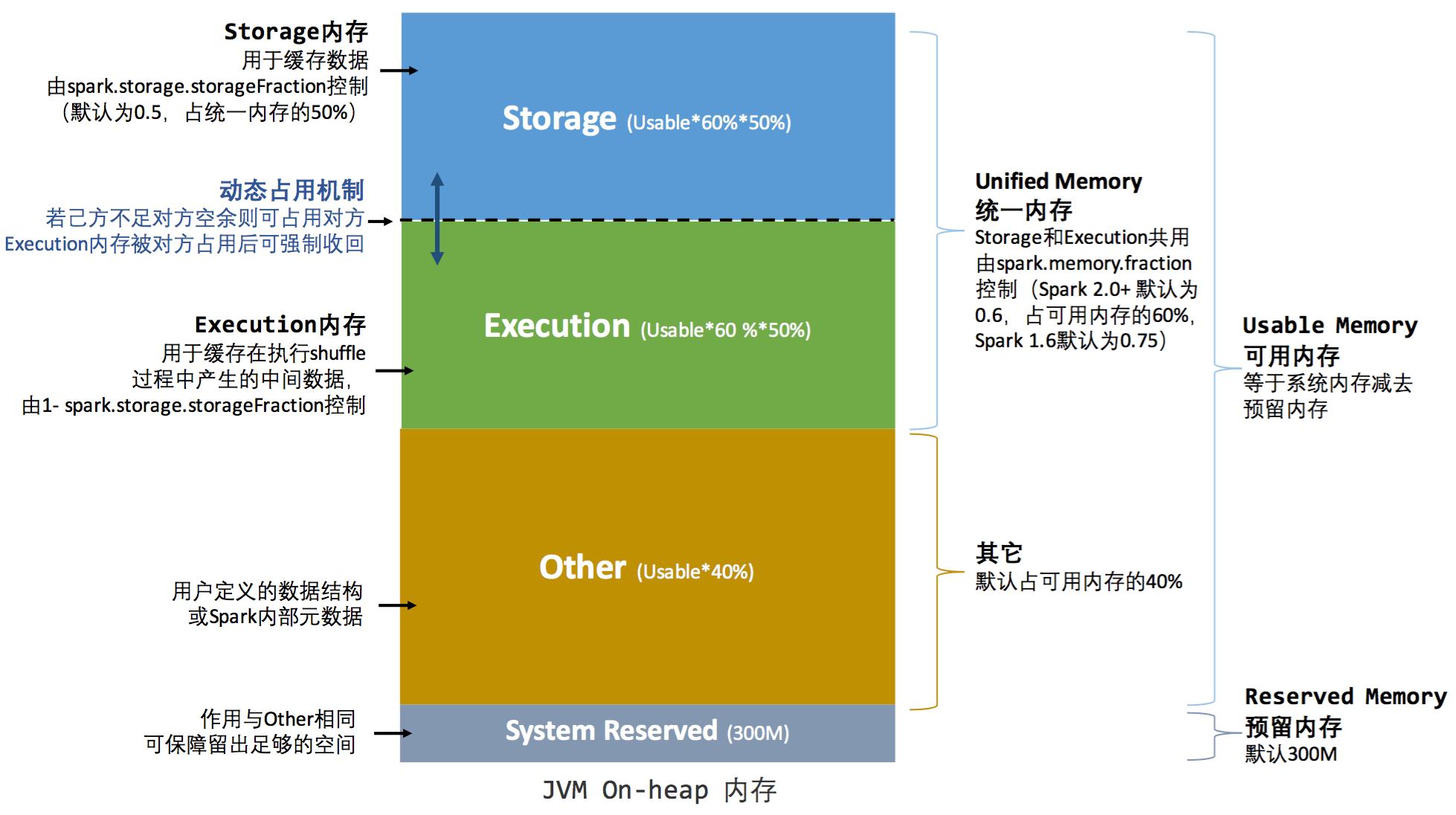
1、存储内存 (Storage Memory)
主要用于存储 spark 的 cache 数据,例如 RDD 的缓存、广播(Broadcast)数据、和 unroll 数据。内存占比为 UsableMemory * spark.memory.fraction * spark.memory.storageFraction,Spark 2+ 中,默认初始状态下 Storage Memory 和 Execution Memory 均约占系统总内存的30%(1 * 0.6 * 0.5 = 0.3)。在 UnifiedMemory 管理中,这两部分内存可以相互借用,具体借用机制我们下一小节会详细介绍。
2、执行内存 (Execution Memory)
主要用于存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据。内存占比为 UsableMemory * spark.memory.fraction * (1 - spark.memory.storageFraction),Spark 2+ 中,默认初始状态下 Storage Memory 和 Execution Memory 均约占系统总内存的30%(1 * 0.6 * (1 - 0.5) = 0.3)。在 UnifiedMemory 管理中,这两部分内存可以相互借用,具体借用机制我们下一小节会详细介绍。
3、其他/用户内存 (Other/User Memory) : 主要用于存储 用户定义的数据结构或spark内部元数据。内存占比为 UsableMemory * (1 - spark.memory.fraction),在Spark2+ 中,默认占可用内存的40%(1 * (1 - 0.6) = 0.4)。
4、预留内存 (Reserved Memory)
系统预留内存,作用与Other相同,用来存储 用户定义的数据结构或spark内部元数据。其大小在代码中是写死的,其值等于 300MB,这个值是不能修改的(如果在测试环境下,我们可以通过 spark.testing.reservedMemory 参数进行修改);如果Executor分配的内存小于 1.5 * 300 = 450M 时,Executor将无法执行。
其中,usableMemory = executorMemory - reservedMemory,这个就是 Spark 可用内存。
NOTES
1、为什么设置300M预留内存
统一内存管理最初版本other这部分内存没有固定值 300M 设置,而是和静态内存管理相似,设置的百分比,最初版本占 25%。百分比设置在实际使用中出现了问题,若给定的内存较低时,例如 1G,会导致 OOM,具体讨论参考这里 Make unified memory management work with small heaps。因此,other这部分内存做了修改,先划出 300M 内存。
2、spark.memory.fraction 由 0.75 降至 0.6
spark.memory.fraction 最初版本的值是 0.75,很多分析统一内存管理这块的文章也是这么介绍的,同样的,在使用中发现这个值设置的偏高,导致了 gc 时间过长,spark 2.0 版本将其调整为 0.6,详细谈论参见 Reduce spark.memory.fraction default to avoid overrunning old gen in JVM default config。
堆外内存 (Off-heap Memory)
Spark 1.6 开始引入了 Off-heap memory (详见SPARK-11389)。这种模式不在 JVM 内申请内存,而是调用 Java 的 unsafe 相关 API 进行诸如 C 语言里面的 malloc() 直接向操作系统申请内存。这种方式下 Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。另外,堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。,缺点是必须自己编写内存申请和释放的逻辑。【钨丝计划】
默认情况下Off-heap模式的内存并不启用,我们可以通过 spark.memory.offHeap.enabled 参数开启,并由 spark.memory.offHeap.size 指定堆外内存的大小,单位是字节(占用的空间划归 JVM OffHeap 内存)。
如果堆外内存被启用,那么 Executor 内将同时存在堆内和堆外内存,两者的使用互补影响,这个时候 Executor 中的 Execution 内存是堆内的 Execution 内存和堆外的 Execution 内存之和,同理,Storage 内存也一样。其内存分布如下图所示:
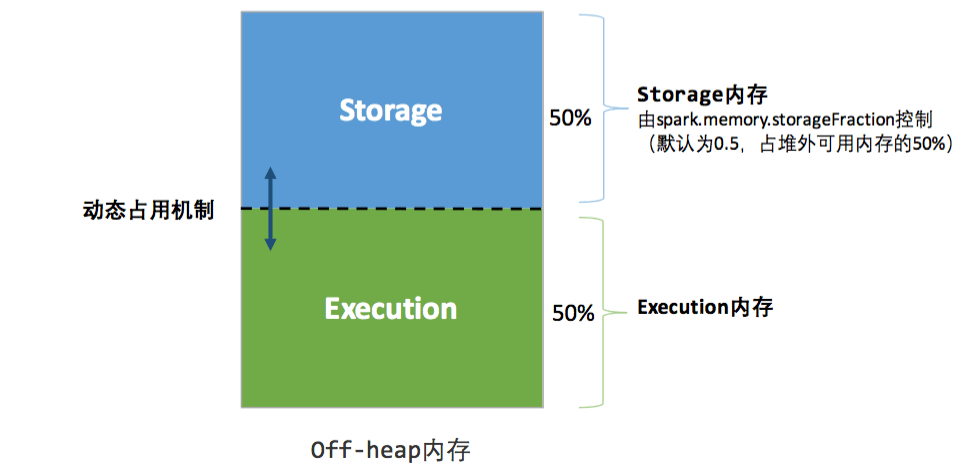
相比堆内内存,堆外内存只区分 Execution 内存和 Storage 内存:
1、存储内存 (Storage Memory)
内存占比为 maxOffHeapMemory * spark.memory.storageFraction,Spark 2+ 中,默认初始状态下 Storage Memory 和 Execution Memory 均约占系统总内存的50%(1 * 0.5 = 0.5)。在 UnifiedMemory 管理中,这两部分内存可以相互借用,具体借用机制我们下一小节会详细介绍。
2、执行内存 (Execution Memory)
内存占比为 maxOffHeapMemory * (1 - spark.memory.storageFraction),Spark 2+ 中,默认初始状态下 Storage Memory 和 Execution Memory 均约占系统总内存的50%(1 * (1 - 0.5) = 0.5)。在 UnifiedMemory 管理中,这两部分内存可以相互借用,具体借用机制我们下一小节会详细介绍。
转自 http://arganzheng.life/spark-executor-memory-management.html 【特别好!!】
---------------------------
一、新旧内存管理
1、旧有(1.6版本之前)的内存管理
概念上,内存空间被分成了三块独立的区域,每块区域的内存容量是按照JVM堆大小的固定比例进行分配的:
Execution:在执行shuffle、join、sort和aggregation时,用于缓存中间数据。通过spark.shuffle.memoryFraction进行配置,默认为0.2。
Storage:主要用于缓存数据块以提高性能,同时也用于连续不断地广播或发送大的任务结果。通过`spark.storage.memoryFraction进行配置,默认为0.6。
Other:这部分内存用于存储运行Spark系统本身需要加载的代码与元数据,默认为0.2。
无论是哪个区域的内存,只要内存的使用量达到了上限,则内存中存储的数据就会被放入到硬盘中,从而清理出足够的内存空间。这样一来,由于与执行或存储相关的数据在内存中不存在,就会影响到整个系统的性能,导致I/O增长,或者重复计算。
2、1.6版本之后
到了1.6版本,Execution Memory和Storage Memory之间支持跨界使用。当执行内存不够时,可以借用存储内存,反之亦然。
1.6版本的实现方案支持借来的存储内存随时都可以释放,但借来的执行内存却不能如此。
新的版本引入了新的配置项:
spark.memory.fraction(默认值为0.6):用于设置存储内存和执行内存占用堆内存的比例。若值越低,则发生spill和evict的频率就越高。注意,设置比例时要考虑Spark自身需要的内存量。
spark.memory.storageFraction(默认值为0.5):显然,这是存储内存所占spark.memory.fraction设置比例内存的大小。当整体的存储容量超过该比例对应的容量时,缓存的数据会被evict。
spark.memory.useLegacyMode(默认值为false):若设置为true,则使用1.6版本前的内存管理机制。此时,如下五项配置均生效:
spark.storage.memoryFraction
spark.storage.safetyFraction
spark.storage.unrollFraction
spark.shuffle.memoryFraction
spark.shuffle.safetyFraction
转自:https://blog.youkuaiyun.com/Evankaka/article/details/63683728

















 6096
6096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









