



一、模型简介
Transformer 是一种基于自注意力机制(Self-Attention)的深度学习模型架构,其完全抛弃了传统的循环结构(如 RNN、LSTM),通过注意力机制和并行计算,高效建模长距离依赖关系,在多项自然语言处理任务中取得了突破性成果。
Transformer 的提出奠定了后续一系列预训练语言模型的基础。基于 Transformer 架构,研究者发展出了 BERT(用于理解任务)、GPT 系列(用于生成任务)、T5、BART 等模型,这些模型广泛应用于机器翻译、文本摘要、问答系统、情感分析等领域,成为自然语言处理的主流范式。
随着多模态模型的发展(如图文、语音、视频的结合),Transformer 架构也被不断扩展和适配,应用范围除了ChatGPT等大模型外,已超越文本,广泛进入计算机视觉、语音识别、机器人控制、蛋白质结构预测等多个领域,展现出极强的通用性和扩展能力。
二、总体架构
Transformer分为Encoder(编码器)和Decoder(解码器)两部分:
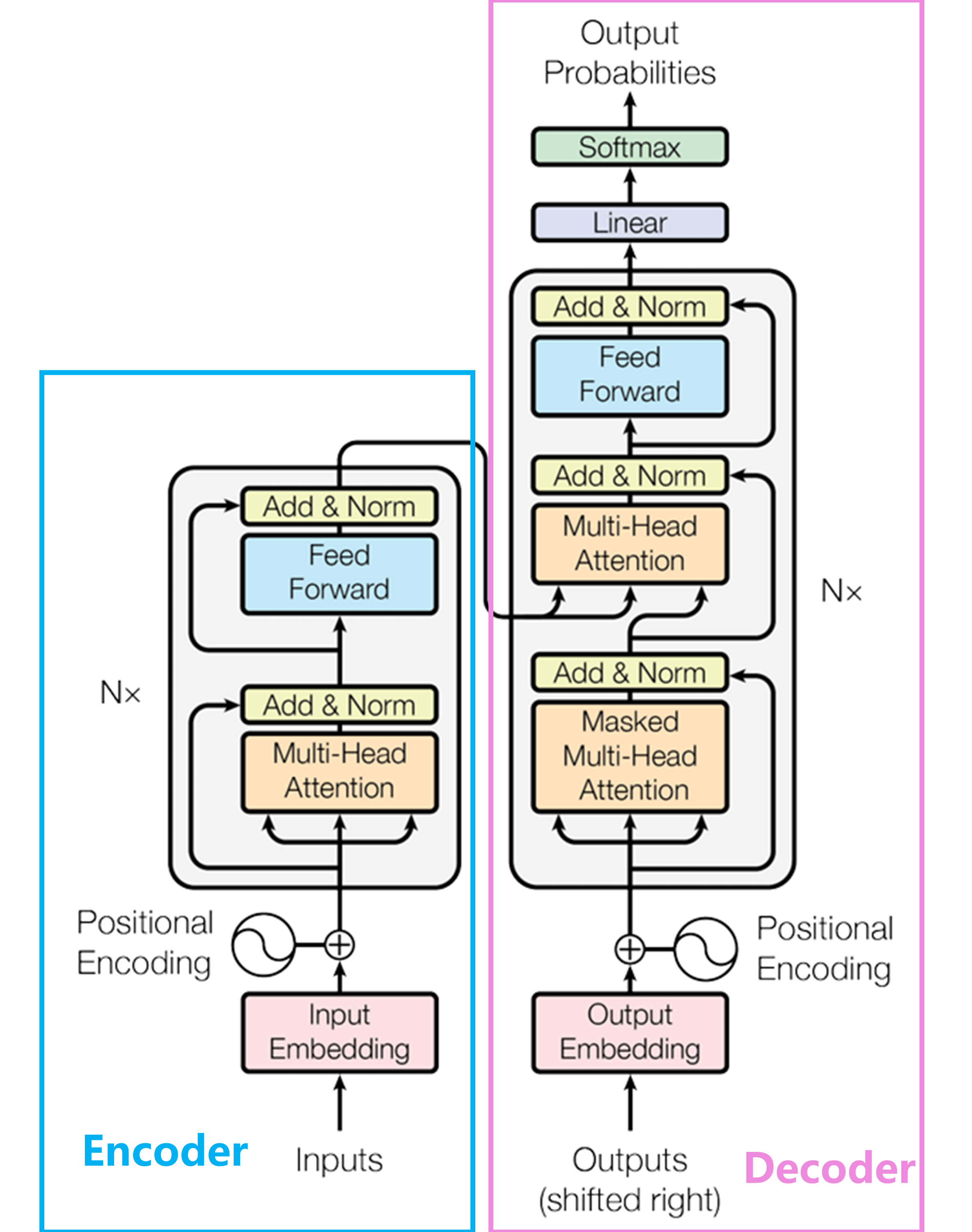
其中Encoder部分由输入、Encoder blocks组成,Decoder部分由输入、Decoder blocks、输出组成:
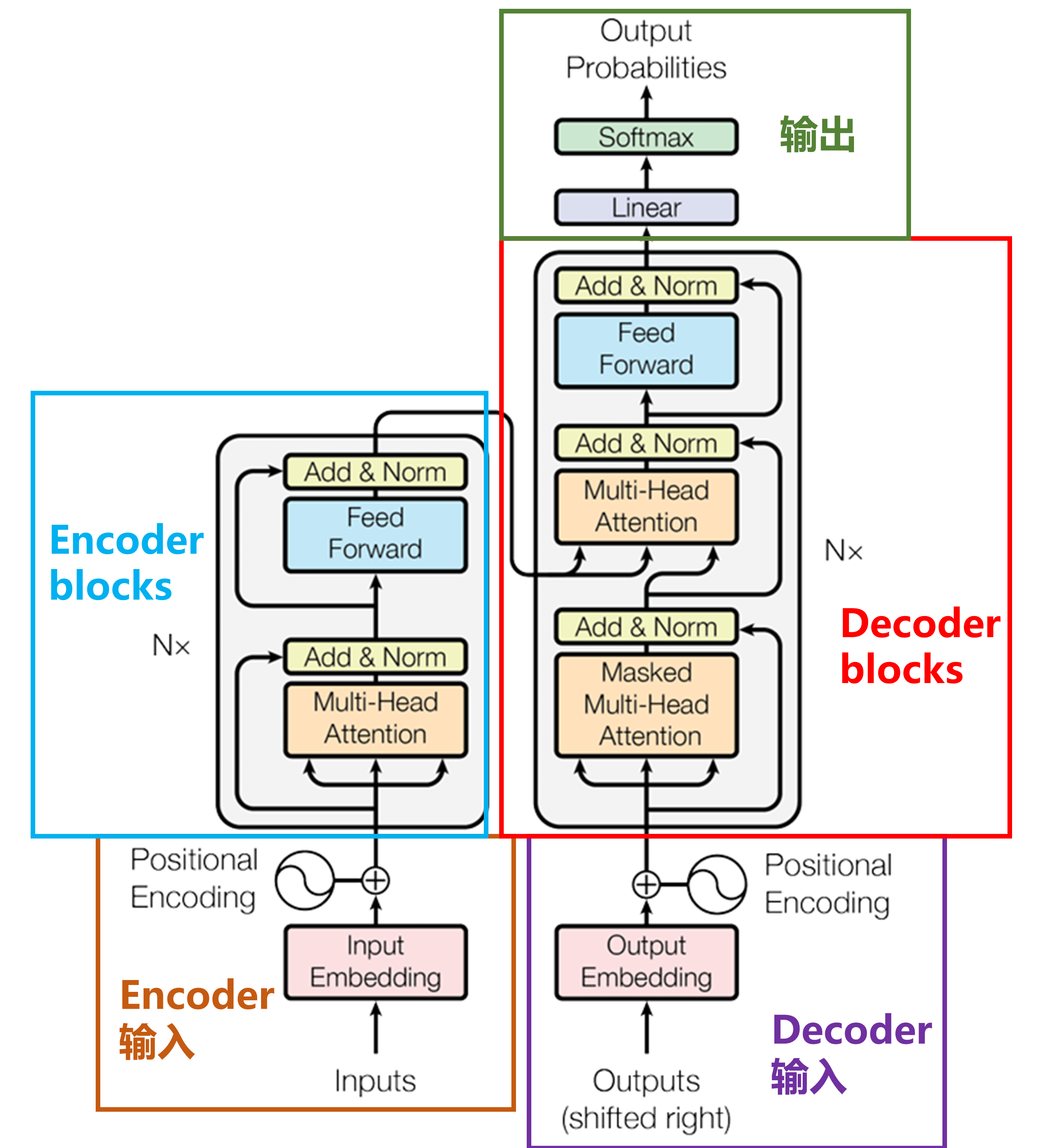
需要注意的是,Encoder block和Decoder block各重复了N次(一般为6)
三、训练及推理流程
推理流程
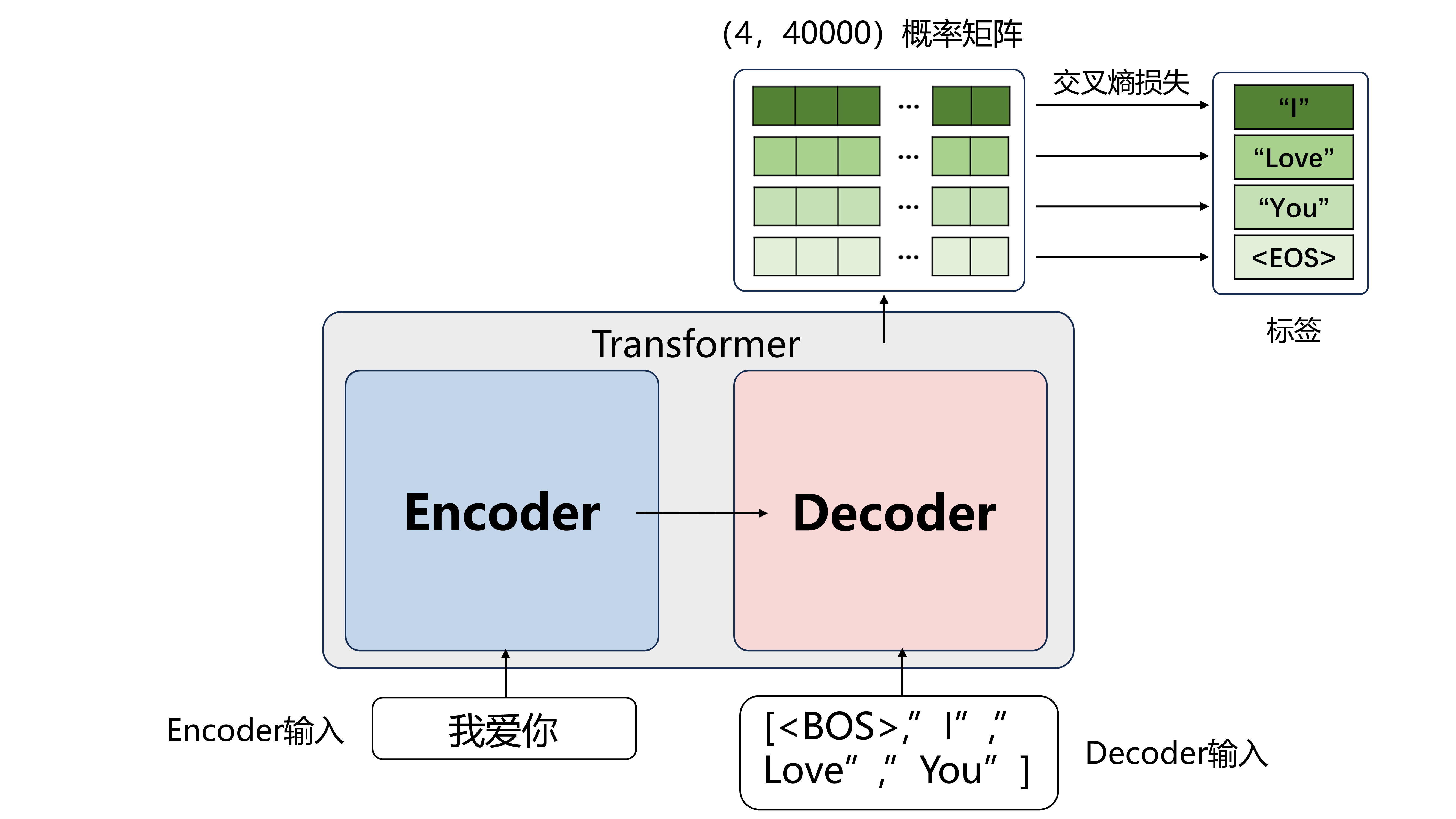
以翻译“我爱你”为例,先将Transformer当作一个黑箱,只研究输入输出,Transformer简化模型图如下
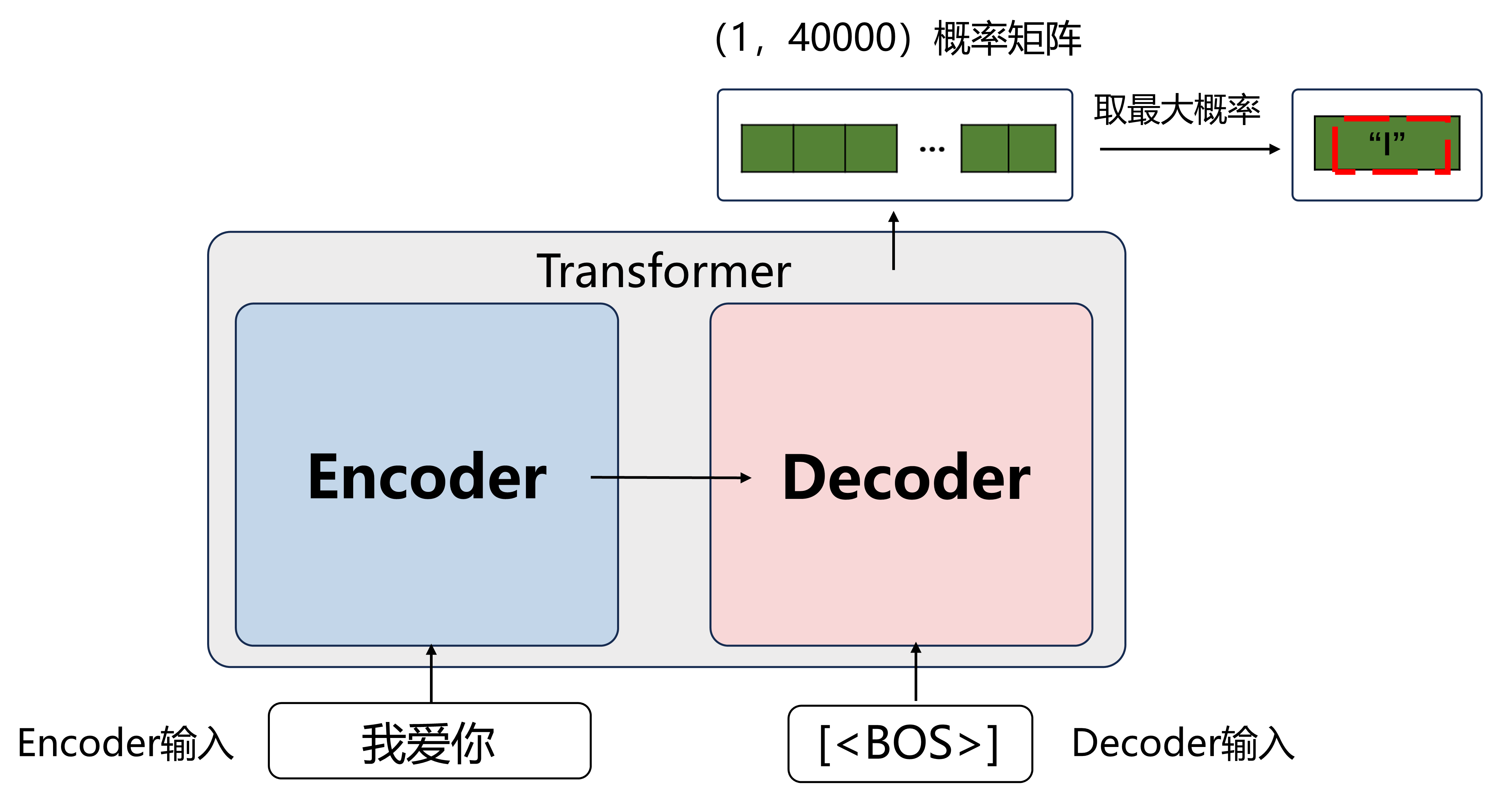
Encoder的输入就是要翻译的文本“我爱你”
Decoder的输入是当前已经翻译出的话
Transformer翻译时是自回归生成,即一个词一个词地翻译:
比方说翻译“我爱你”时是先翻译出“I”,再翻译出“Love”,再翻译出“You“
最一开始Decoder先输入起始符<BOS>
最终模型输出了(1,40000)的概率矩阵,一行代表目前翻译到了第一个词,40000是词表个数
每列代表某个词的概率,取概率最大的一个词
此时“I”概率最大,则翻译出的第一个词是“I”
此时再将[<BOS>, “I”]输入进Decoder:
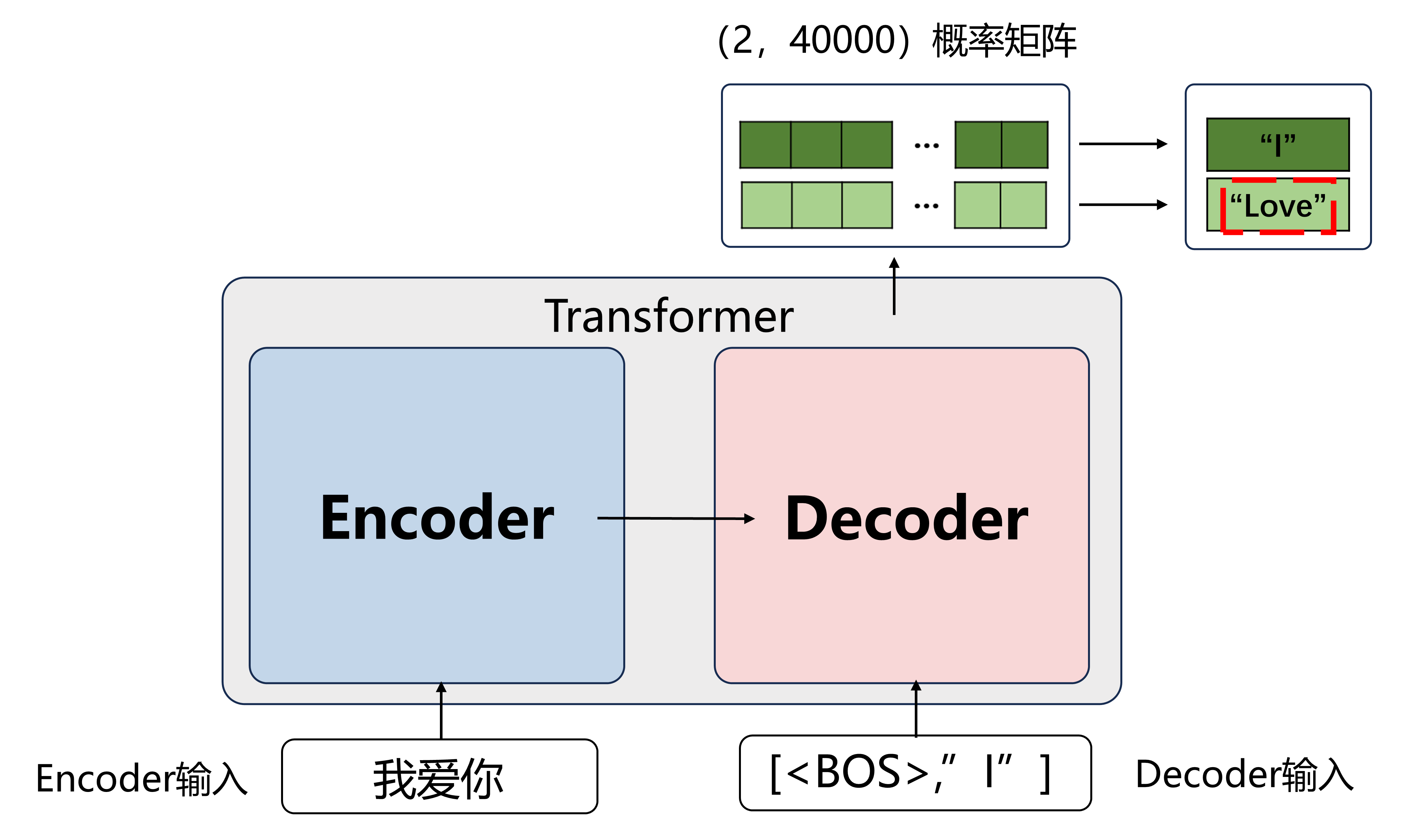
(推理过程Encoder的输入一直是“我爱你”,所以Encoder不用每次都算,每次都用第一次的输出就好)
经过运算,Decoder的输出是一个(2×40000)的概率矩阵,其中2是已经翻译出的词数
取其中每行概率最大的那个词(其实只关心最后一行,概率值最大的词是“Love”,则下一个词是“Love”)
Transformer没有向前纠错机制
例如之前已经生成“I”了,在生成“Love”时的第一行概率最大的不是“I”,也不会去修改“I”了
所以推理时只关心最后一行
再将[<BOS>, “I”, “Love”]输入进Decoder,生成“You”
将[<BOS>, “I”, “Love”, “You”]输入进Decoder,生成结束符<EOS>,翻译结束
训练流程
训练时不用像推理时一遍遍地运算
而是Decoder直接输入[<BOS>, “I”, “Love”, “You”]
得出的四行概率矩阵计算与标签[“I”, “Love”, “You”, <EOS>]的交叉熵损失
具体是计算每一行的交叉熵,然后求平均
L = − l o g P c L=-logP_c L=−logPc
其中Pc是真实标签在预测中的概率
比方计算第一行的交叉熵,就是找到这一行“I”对应的概率Pc,然后求负对数
四、各模块结构详解
1.Encoder 输入
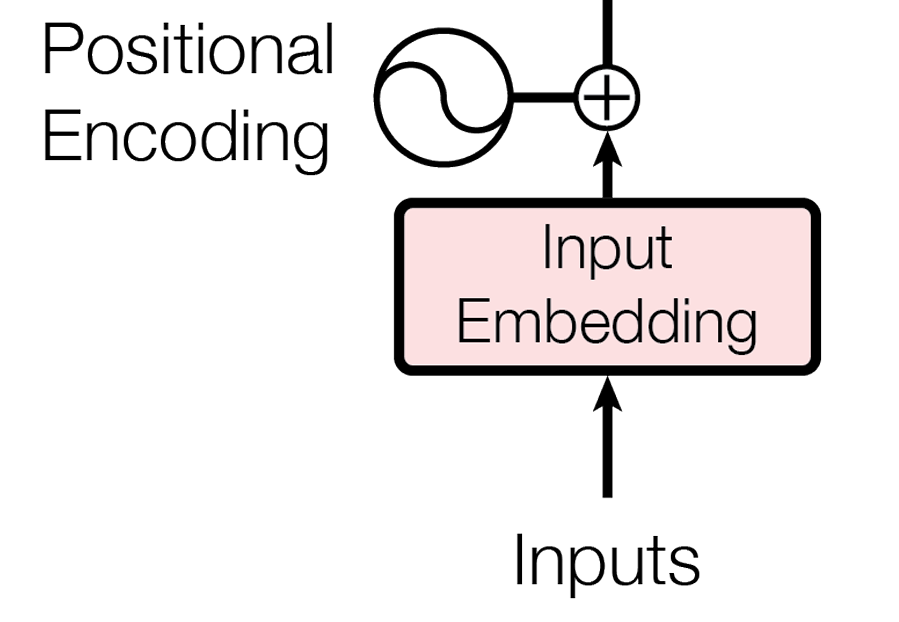
以翻译任务为例,想要翻译“我爱你”这句话,Inputs为“我爱你”,Embedding会将文字映射到d_model维度的向量,位置编码为每个字添加其在整体中的位置信息,具体来说:
Input Embedding
将单词或字符映射为连续的向量表示
Transformer中先用随机映射将文字映射为向量,在训练中不断优化映射(功能与word2vec相似,但word2vec在训练中是静态的)
在中文翻译中,一般词表里有常用的 5,000 个汉字,embedding 维度设为 512(d_model=512)
embedding = nn.Embedding(num_embeddings=5000, embedding_dim=512)
将“我”字映射到向量,假设“我”字在词表中的id为1024:
embedding(torch.tensor([1024]))# tensor of shape [1, 512]
这样便可将“我”字映射到[1,512]的向量中,其余字同理
Positional Encoding
由于Transformer模型本身不具备处理序列顺序的能力,但因为在文本信息的处理时,当前单词是跟前后单词有关联系的,因此需要在输入嵌入层( input Embedding)后加入位置编码(positional encoding),以提供位置信息
首先给出公式:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
1000
0
2
i
/
d_model
)
PE(pos,2i)=sin(\frac{pos}{10000^{2i/\text{d\_model}}})
PE(pos,2i)=sin(100002i/d_modelpos)
P E ( p o s , 2 i + 1 ) = c o s ( p o s 1000 0 2 i / d_model ) PE(pos,2i+1)=cos(\frac{pos}{10000^{2i/\text{d\_model}}}) PE(pos,2i+1)=cos(100002i/d_modelpos)
其中pos为字在语句中的位置,i为向量的位置索引。
| Token | pos |
|---|---|
| 我 | 0 |
| 爱 | 1 |
| 你 | 2 |
“我”字的位置编码向量为
[
s
i
n
(
0
1000
0
2
∗
0
/
d_model
)
,
c
o
s
(
0
1000
0
2
∗
1
/
d_model
)
,
s
i
n
(
0
1000
0
2
∗
2
/
d_model
)
,
.
.
.
,
c
o
s
(
0
1000
0
2
∗
511
/
d_model
)
]
[sin(\frac{0}{10000^{2*0/\text{d\_model}}}), cos(\frac{0}{10000^{2*1/\text{d\_model}}}), sin(\frac{0}{10000^{2*2/\text{d\_model}}}), ...,cos(\frac{0}{10000^{2*511/\text{d\_model}}})]
[sin(100002∗0/d_model0),cos(100002∗1/d_model0),sin(100002∗2/d_model0),...,cos(100002∗511/d_model0)]
其与d_model维度相同,共512维
"爱"字的位置编码向量为
[
s
i
n
(
1
1000
0
2
∗
0
/
d_model
)
,
c
o
s
(
1
1000
0
2
∗
1
/
d_model
)
,
s
i
n
(
1
1000
0
2
∗
2
/
d_model
)
,
.
.
.
,
c
o
s
(
1
1000
0
2
∗
511
/
d_model
)
]
[sin(\frac{1}{10000^{2*0/\text{d\_model}}}), cos(\frac{1}{10000^{2*1/\text{d\_model}}}), sin(\frac{1}{10000^{2*2/\text{d\_model}}}), ...,cos(\frac{1}{10000^{2*511/\text{d\_model}}})]
[sin(100002∗0/d_model1),cos(100002∗1/d_model1),sin(100002∗2/d_model1),...,cos(100002∗511/d_model1)]
最后将Input Embedding生成的512维向量和位置编码生成的512维向量相加,即完成输入处理
2.Encoder blocks
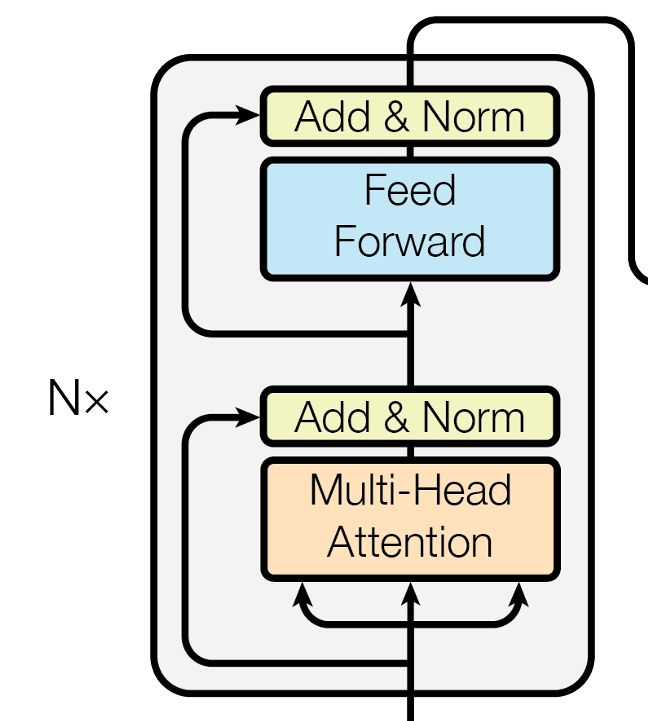
注意力机制
首先讲橙色部分的多头注意力机制,其由N个头的自注意力组成
自注意力机制
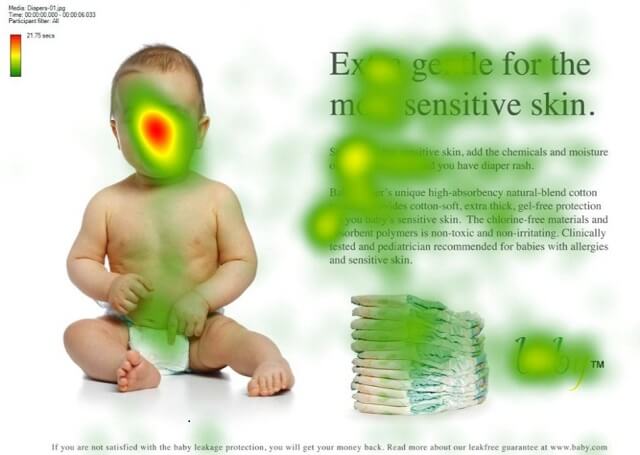
如上图,当考虑“婴儿在干什么”时,人们对图片各区域的关注程度不同,越重点关注的区域颜色越深。这便是注意力机制的由来,在语言翻译任务中,句子中每个词需要关注其他词的程度不同,比如
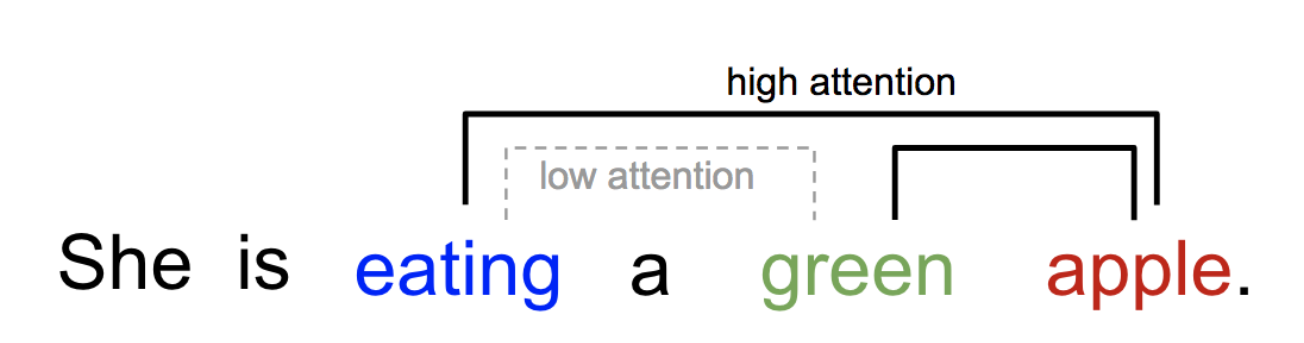
“eating”后面会有一种食物,“eating”与“apple”的Attention Score更高,而“green”只是修饰食物“apple”的修饰词,和“eating”关系不大。
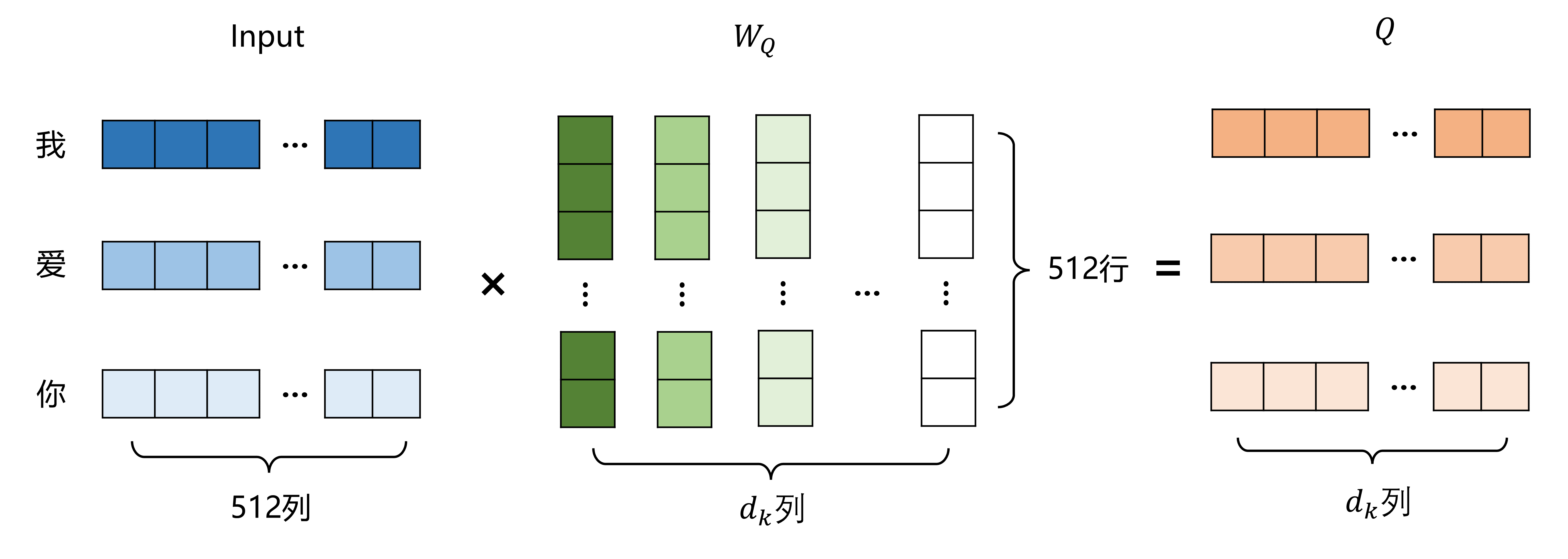
Transformer中实现注意力机制使用了QKV矩阵,首先将block模块的输入分别乘上WQ,WK,WV矩阵,得到QKV矩阵,其中WQ,WK,WV矩阵为注意力模块中的可学习矩阵
实际代码中是直接使用
WQ=nn.Liner(d_model, dk)
Q=WQ(Input)
将input映射到(3,dk)维度
实际代码中其实是映射到d_model维度:
关系到后面的多头注意力,直接计算的8个头,省的计算8次再拼接
K,V矩阵同理,其中dk一般设置为
d
k
=
d_model
/
h
d_k=\text{d\_model}/h
dk=d_model/h
本例中d_model为512,h为多头注意力的数量,后面会讲到,一般为8,因此本例中dk为64
再对QKV矩阵进行处理:
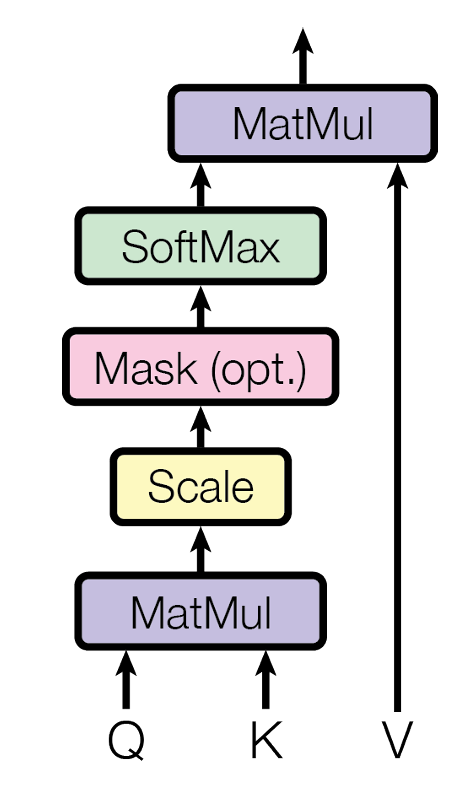
用公式表示就是:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
为什么要除以根号dk?:
为了减小方差,防止梯度过大
以上是实现过程,下面讲一讲如何理解QKV
QKV可以分别这样理解:
- Q:Query(查询),每个词分别提出问题:这个句子中谁和我最相关?
- K:Key,每个词的特征
- V:Value,每个词的实际语义
首先每个词提问:其他词谁和我最相关(Q)?所有词提供自己的身份(K),得到注意力权重矩阵(这个词更关注其他哪个词,比如“我”和“爱”对应的权重矩阵值较大,表示“我”比较关注“爱”字,那么在接下来的加权组合中,会将“爱”字的V值线性融合进“我”字中,“我”字不太关注“你”字,“你”的V值就对新的“我”的V值影响不大。
具体来说,
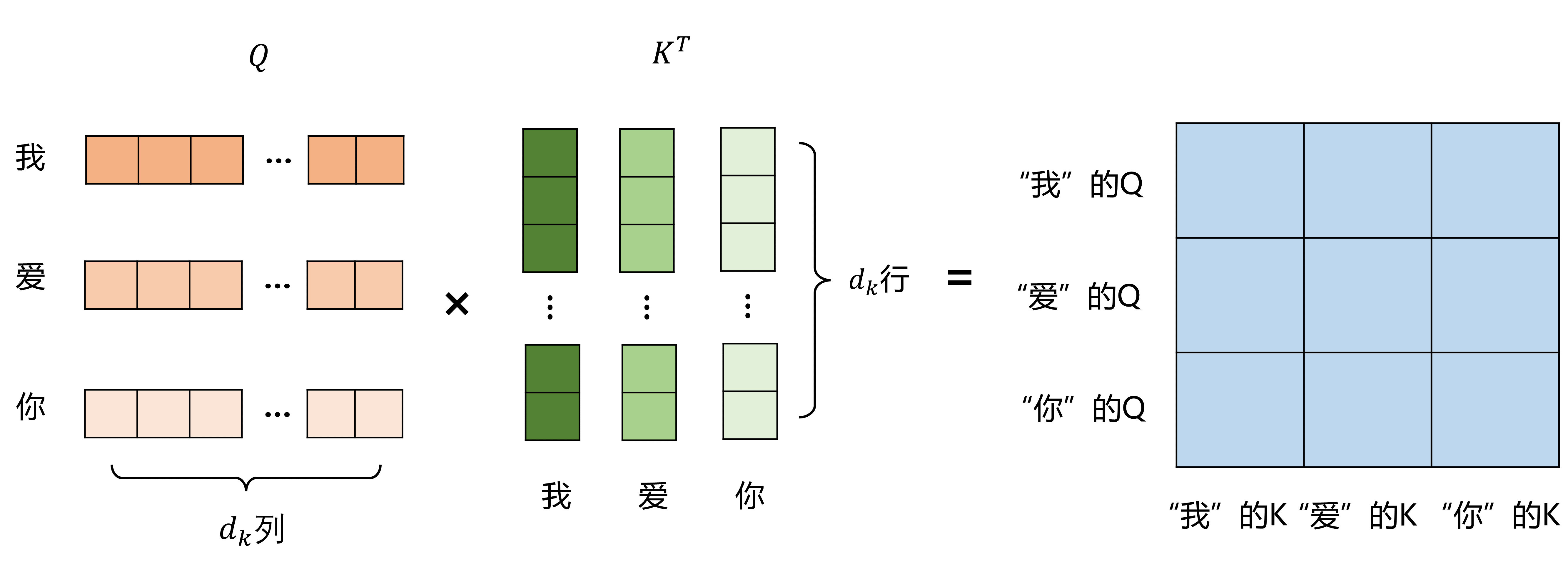
Q*K^T矩阵表示每个词对其他词的关注程度,比如第一行第二列数值较大,就意味着“我”比较关注“爱”字,第一行第三列的数值较小,就意味着“我”不太关注“你”字,即“你”字对“我”的影响不大
注意力矩阵再乘上V矩阵,即得到每个词融合其他词后的新V值:
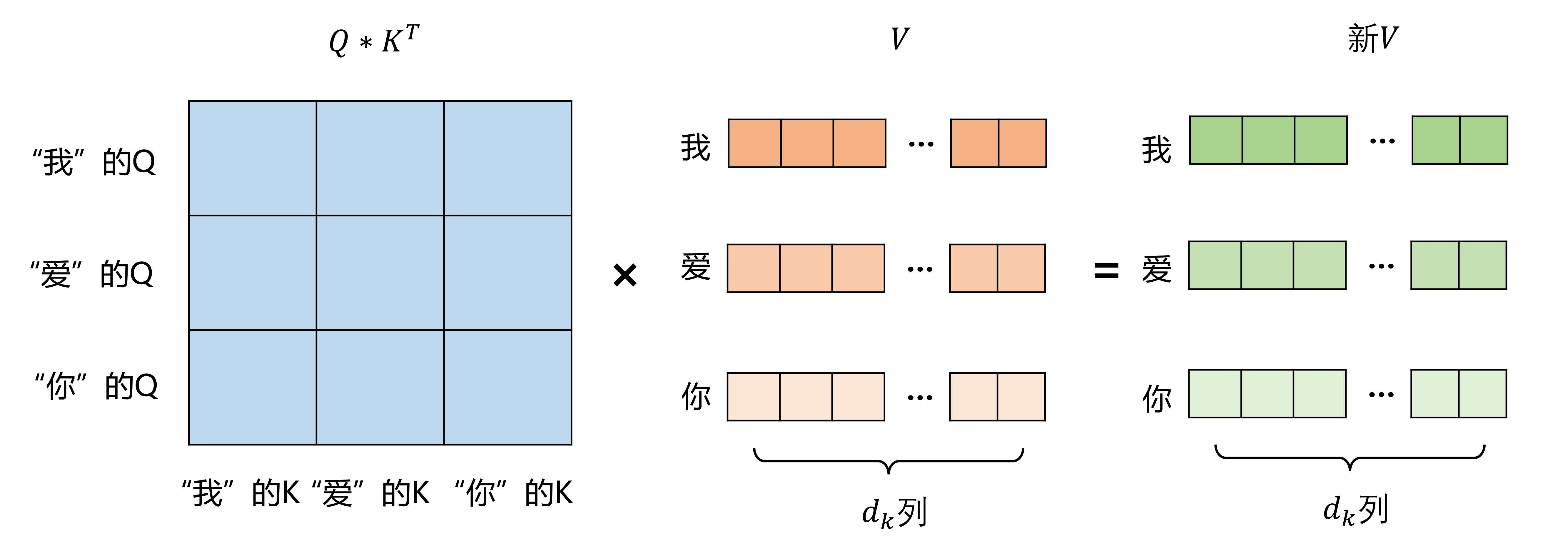
举个例子:
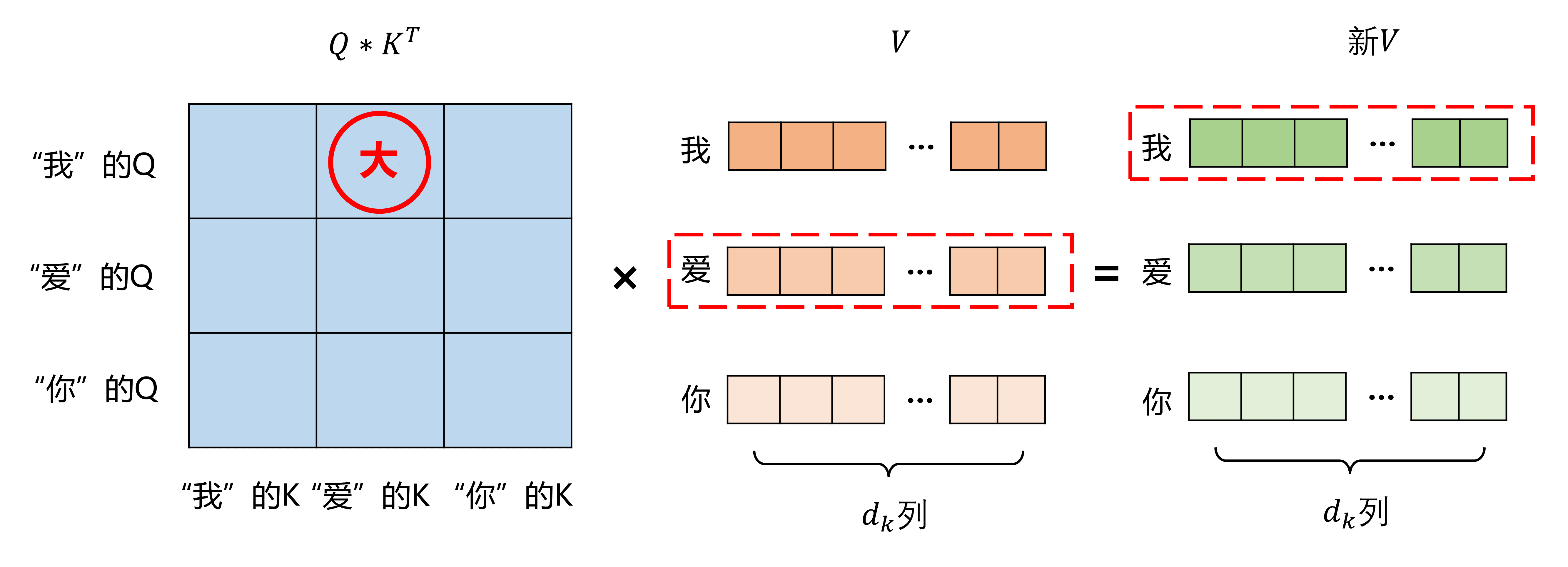
第一行第二列的数值较大,意味着“我”比较关注“爱”字,即“爱”字对“我”的影响较大,则在新的V值中,“我”的V就融合了比较多的“爱”的V
为什么输入已经有语义了,还要提炼出V值?:
原始词向量是“通用信息”,Value 是“为当前注意力任务精细提炼的表达”
多头注意力机制
为了增强拟合性能,Transformer对Attention继续扩展,提出了多头注意力(Multi-Head Attention)。
对于同样的输入,定义多组不同的WQ, WK, WV,每组分别按上述计算生成不同的Q, K, V,最后叠加并经过一层线性层得到和原始输入维度相同的输出。
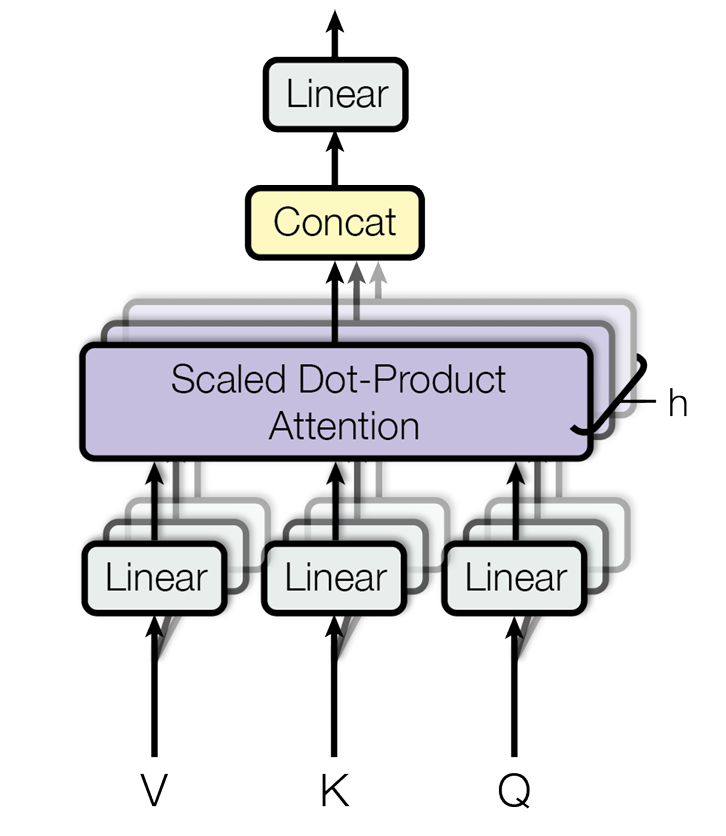
因为上面每个自注意力模块得到的V值维度为(3,dk),其中3是因为“我爱你”长度为3,由于上面讲到dk定义为
d
k
=
d_model
/
h
d_k=\text{d\_model}/h
dk=d_model/h
所以h个头注意力输出concat后的维度为(3,d_model),与原始输入一致。
残差和层归一化
在经过橙色的多头注意力机制后,进行了残差和层归一化的操作:
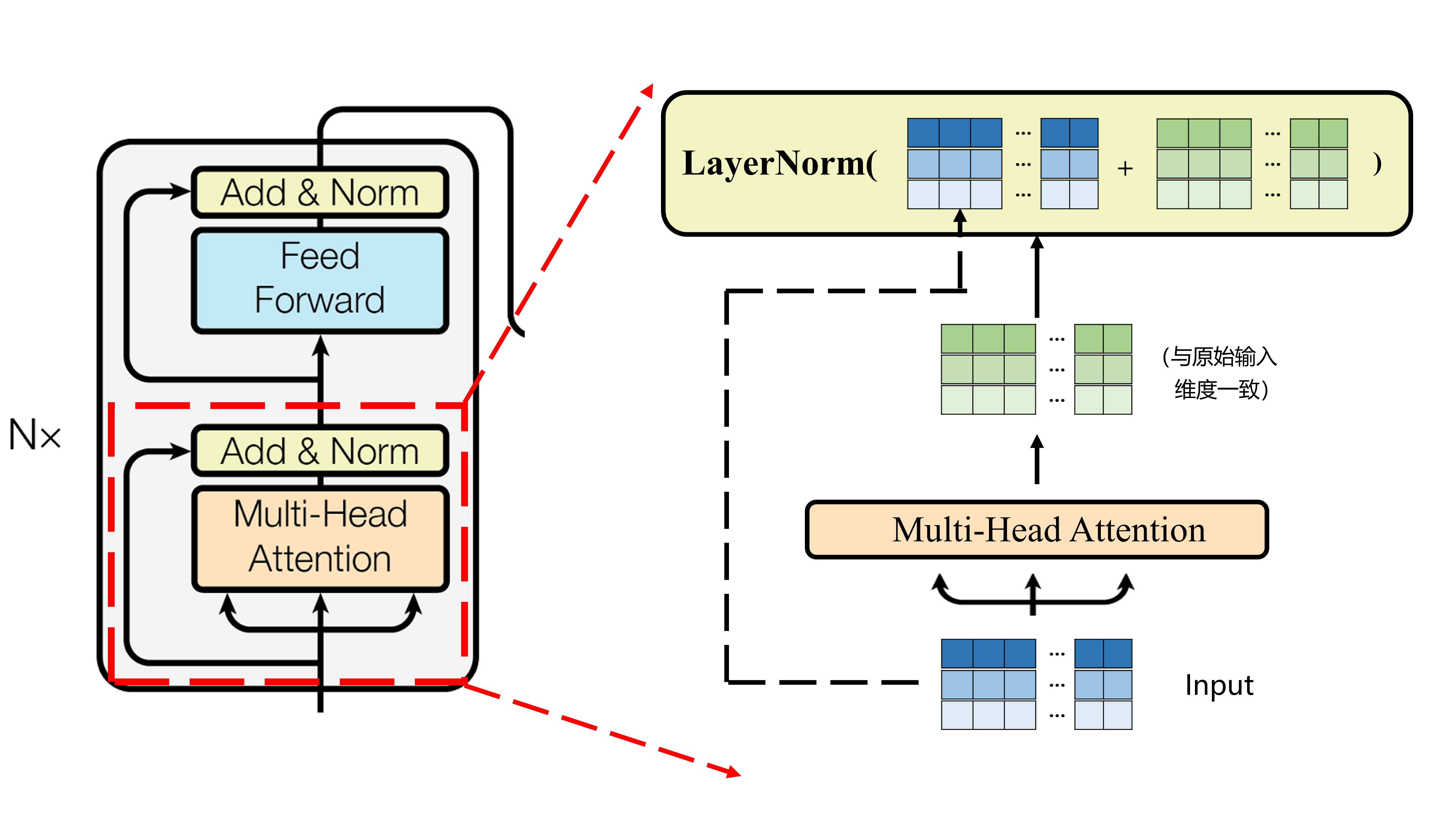
残差连接
在深度神经网络发展历程中,出现了“网络退化”(Degradation Problem)现象:当网络深度超过某临界值(如VGG-19的19层)后,模型在训练集和测试集上的准确率均出现显著下降,这一现象无法简单归因于过拟合或梯度消失问题。
为了解决这一问题,何恺明等人提出了残差连接:
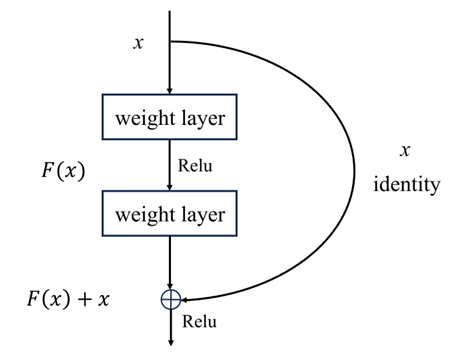
即在通过神经网络后再加上原始输入的值,保证了增加这层网络后性能不低于没有这层网络的结构。
在Transformer中也应用了这一思想,在注意力机制后面增加了残差连接(注意力机制的输出结果与原始输入相加后再进行后续操作),保证增加注意力机制后的性能不低于之前。
层归一化
归一化一般有批归一化(BatchNorm)和层归一化(LayerNorm)
批归一化的使用场景如下:
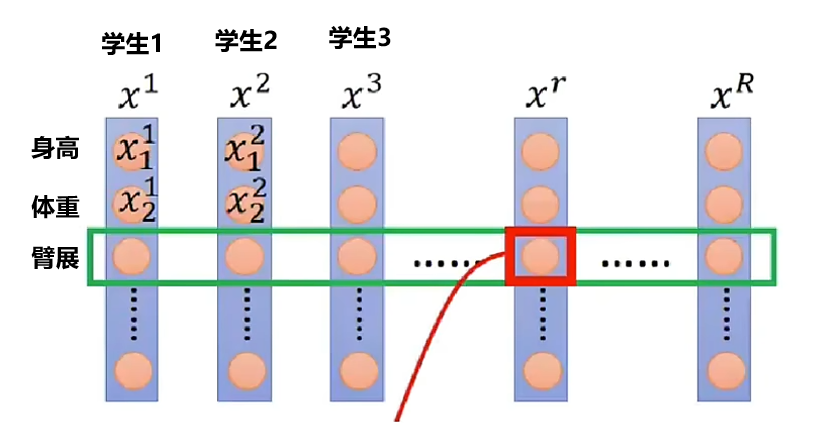
每个batch中所有样本的同一维度代表同一性质,BatchNorm对同一维度的数据进行归一化,即对所有人的身高、体重分别进行归一化
而在翻译任务中,

同一维度上的“我”和“今”没有任何关系,“爱”和“天”也没有,因此使用批归一化无法有效进行归一化。
而层归一化即
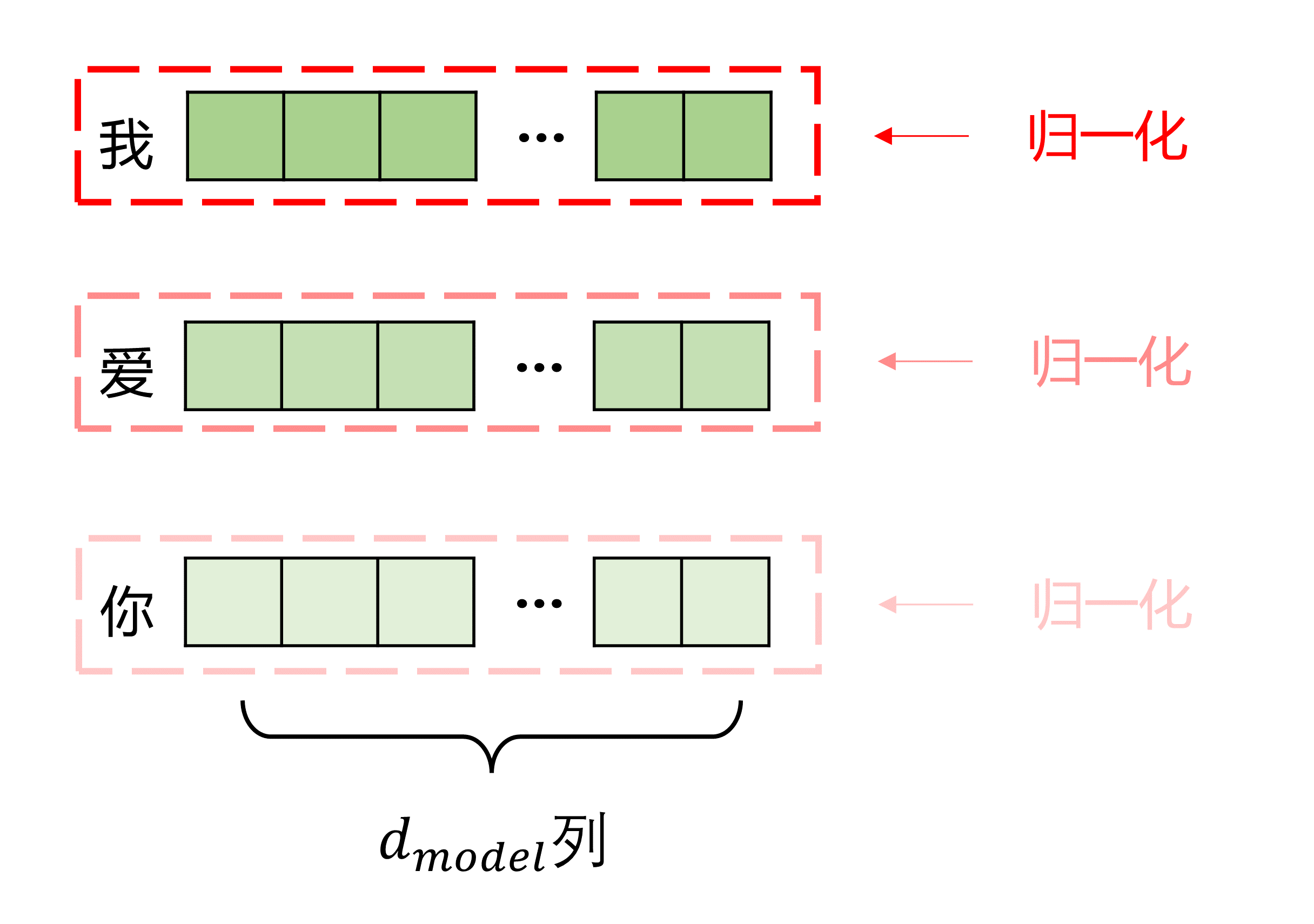
在残差后每个token的维度上进行归一化,明显更适合翻译任务
Transformer中使用Layernorm可以让模型在训练中更快收敛、更稳定、更容易训练深层结构
前馈神经网络
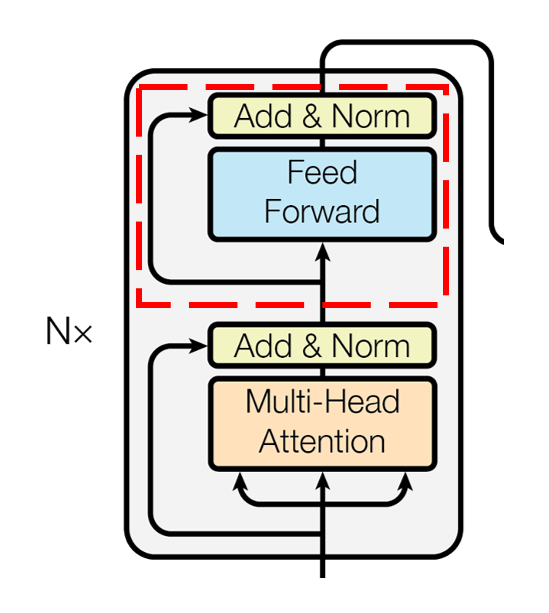
将前面部分的输出再经过一个双层的前馈神经网络,再进行和上面相同的残差和层归一化操作,没有什么难点
输出维度依旧是(3,512),这便是encoder的输出。
3.Decoder输入
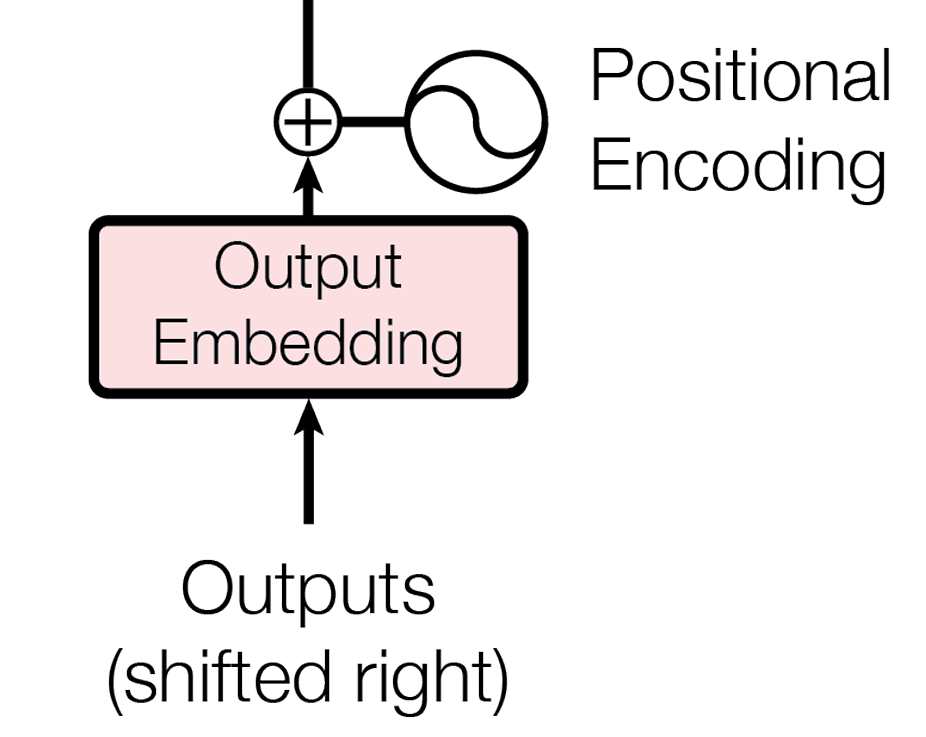
Decoder的输入部分和Encoder的输入部分结构完全一样,都是经过了Embedding和位置编码
这里只讲结构,用途和训练流程下面再讲
4.Decoder blocks
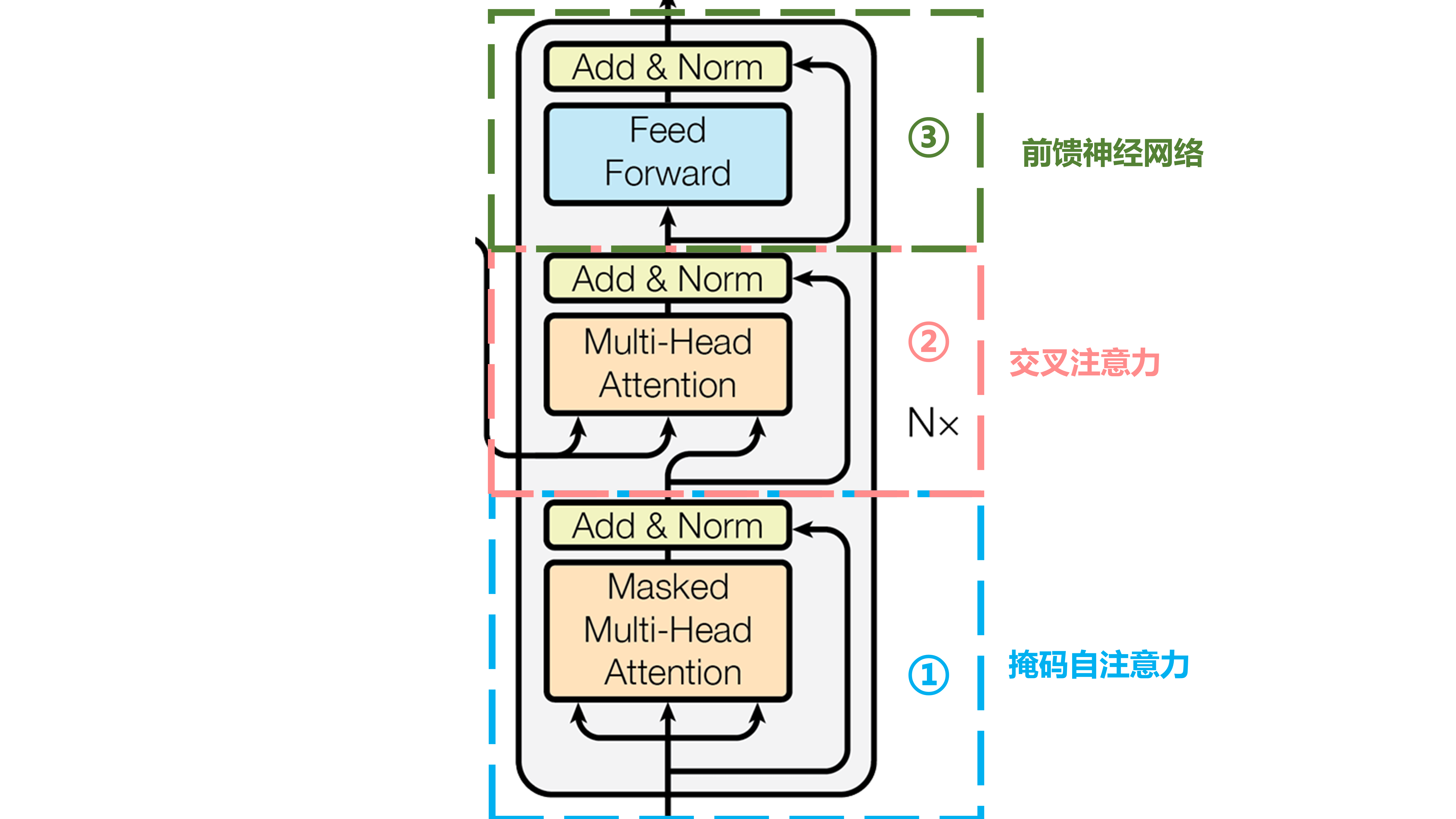
Decoder blocks分为三个部分:掩码自注意力,交叉注意力,前馈神经网络
掩码自注意力
这里大体和Encoder中的多头注意力机制相同,只是多了一个掩码机制
因为训练时Decoder一次性输入“我爱你”三个字时,是不允许“我”字看到“爱”字和“你”字的,
这和Transformer的推理流程有关:
Transformer推理流程:一个字一个字地推理,Encoder的输入是[“我”, “爱”, “你”],一开始Decoder的输入是开始符<BOS>,这时Decoder的输出概率最大的是”I“,保持Encoder不变,Decoder的输入变成[<BOS>, “I”],Decoder输出”Love“,再将Decoder的输入变成[<BOS>, “I”, “Love”],Decoder的输出为”You“,再将Decoder的输入变成[<BOS>, “I”, “Love”, “You”],Decoder的输出为结束符<EOS>,翻译结束。
所以推理时每个字看不到后面的字,训练时也就不能让他看到
首先同样是经过WQ,WK,WV生成QKV矩阵
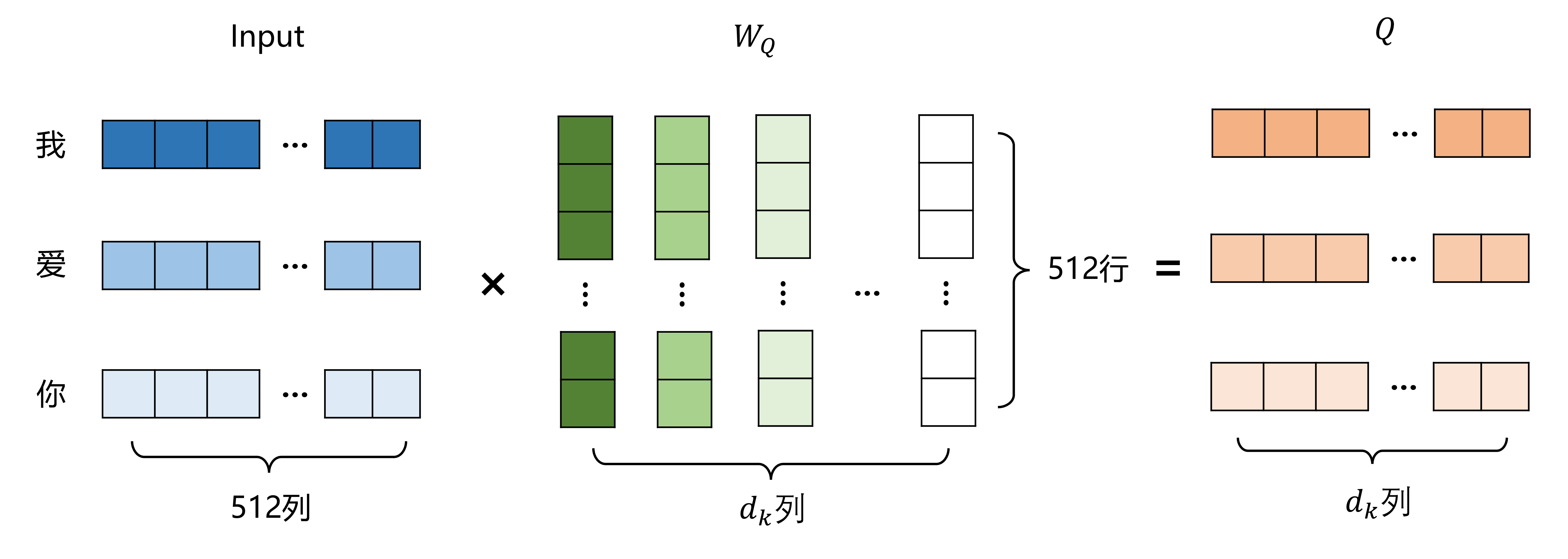
在计算
Q
K
T
d
k
\frac{QK^T}{\sqrt{d_k}}
dkQKT
生成注意力矩阵后,进行掩码操作,即
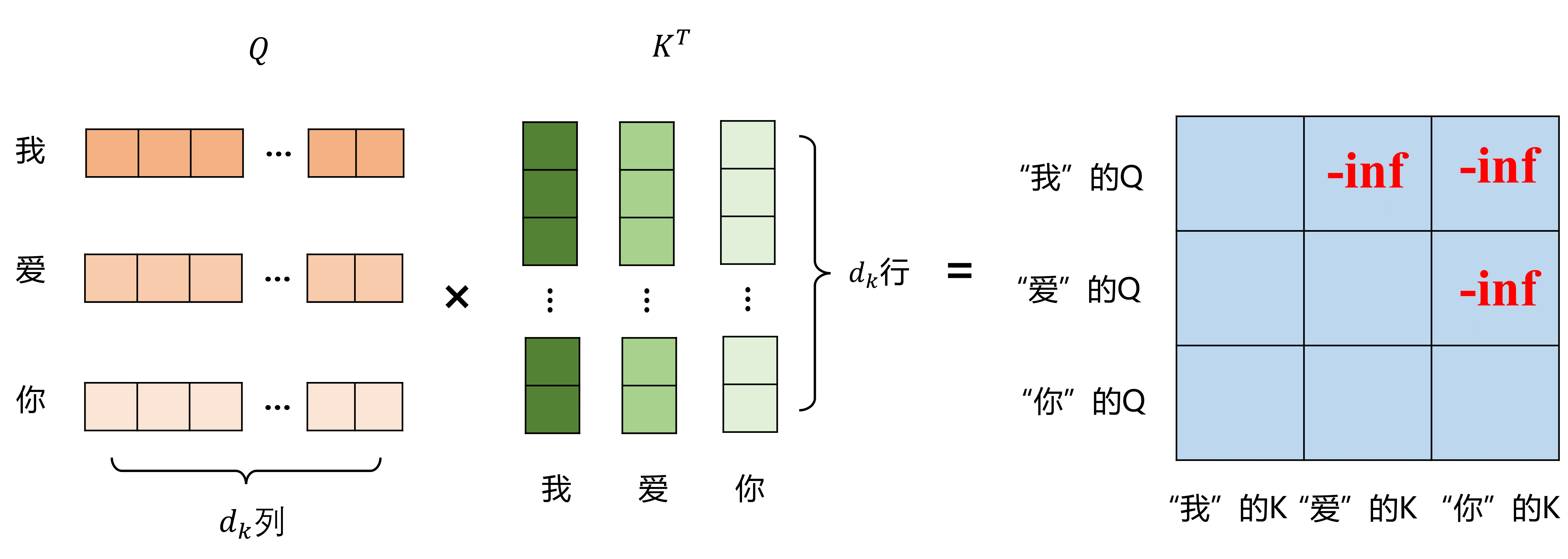
在注意力矩阵的上三角进行掩码操作,保证每个字看不到后面的字,因为在推理阶段,是一个字一个字地给出的
操作就是将上三角都赋负无穷的值,然后再进行softmax的操作
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
V矩阵不用做额外操作
残差和层归一化操作和前面一样
交叉注意力
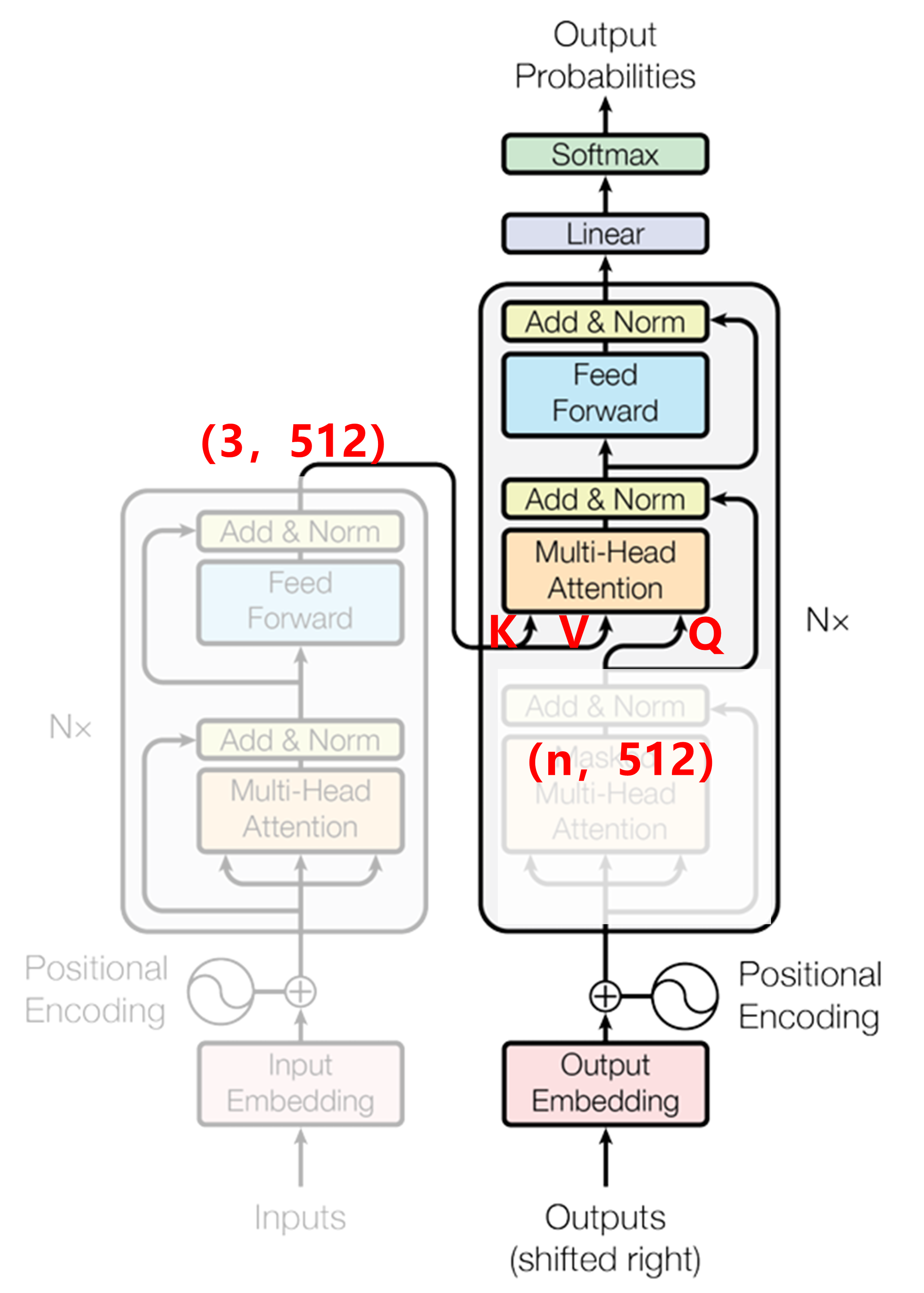
可以看作Decoder 在 “询问” Encoder:
👉「我目前已经生成了这么多目标词,我该注意输入句子的哪个部分?」
因此由Decoder提供Q,Encoder提供KV,这里需要注意Decoder提供的是Q
前面已经讲过Encoder输出一个(3,512)的高维语义矩阵,其分别经过可学习的WK,WV矩阵
K
=
(
3
,
512
)
@
(
512
,
d
k
)
=
(
3
,
d
k
)
K=(3,512)@(512,dk)=(3,dk)
K=(3,512)@(512,dk)=(3,dk)
V = ( 3 , 512 ) @ ( 512 , d k ) = ( 3 , d k ) V=(3,512)@(512,dk)=(3,dk) V=(3,512)@(512,dk)=(3,dk)
生成KV矩阵
Decoder在掩码自注意力模块输出(n,512)矩阵,其中n代表当前已生成的token数,即Decoder的输入token数
如Decoder输入为[<BOS>,“I”]时,n为2,Decoder输入为[<BOS>,“I”,“Love”]时,n为3
Q = ( n , 512 ) @ ( 512 , d k ) = ( n , d k ) Q=(n, 512) @ (512, dk)=(n,dk) Q=(n,512)@(512,dk)=(n,dk)
则注意力矩阵的维度为
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
=
(
n
,
d
k
)
@
(
d
k
,
3
)
@
(
3
,
d
k
)
=
(
n
,
d
k
)
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V=(n,dk)@(dk,3)@(3,dk)=(n,dk)
Attention(Q,K,V)=softmax(dkQKT)V=(n,dk)@(dk,3)@(3,dk)=(n,dk)
同样经过多头后,生成(n,512)的矩阵
残差和层归一化与前面相同
前馈神经网络
前馈神经网络结构与Encoder中相同
6个blocks
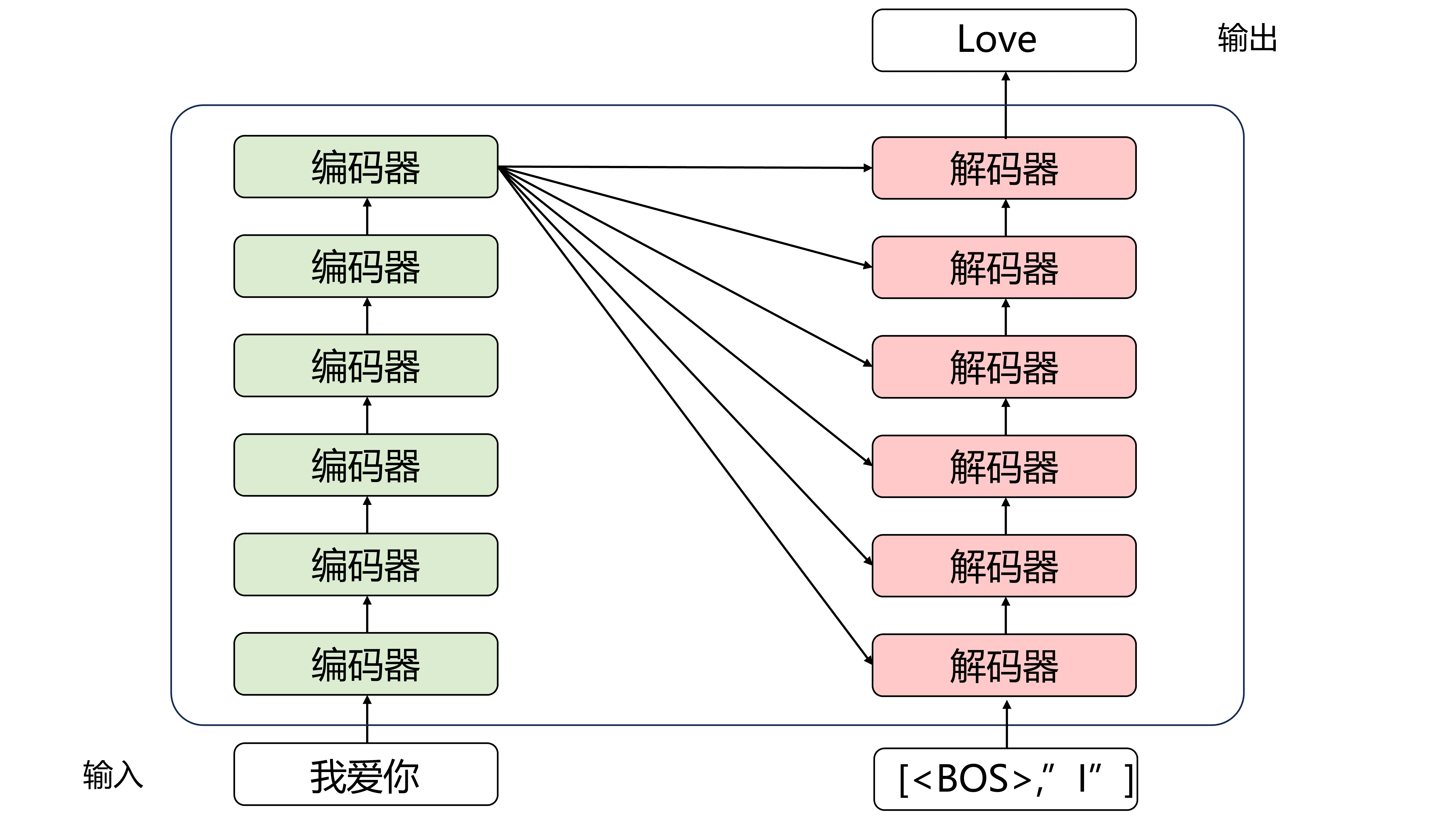
这是省略了其他结构的简略图,Encoder中6轮编码后就不变了,其一直输入给每一轮的解码器
每个解码器以上一个解码器的输出和编码器的输出为输入
5.输出模块
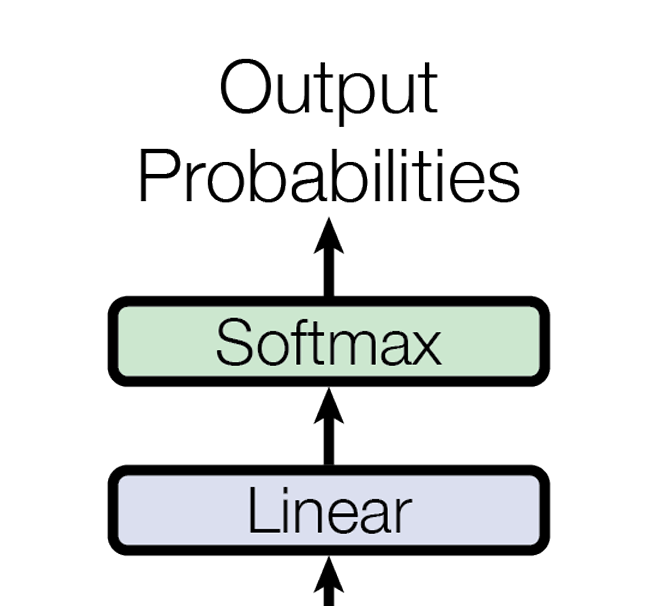
输出模块由一个线性层和softmax组成
线性层是一个简单的单层神经网络,目的是把block的输出(n,512)映射到词表大小(n, 40000)
假设词表大小为50000
再进行softmax,取最后一行概率最大的一个词作为本次输出
这里有个小技巧:
线性层的参数与embedding网络中的一层参数共享,可以节省参数量,提高性能
五、Vision Transformer
Transformer最初被提出是用在翻译任务中,后续被发现在图像任务中也能取得很好的表现
1.总体架构
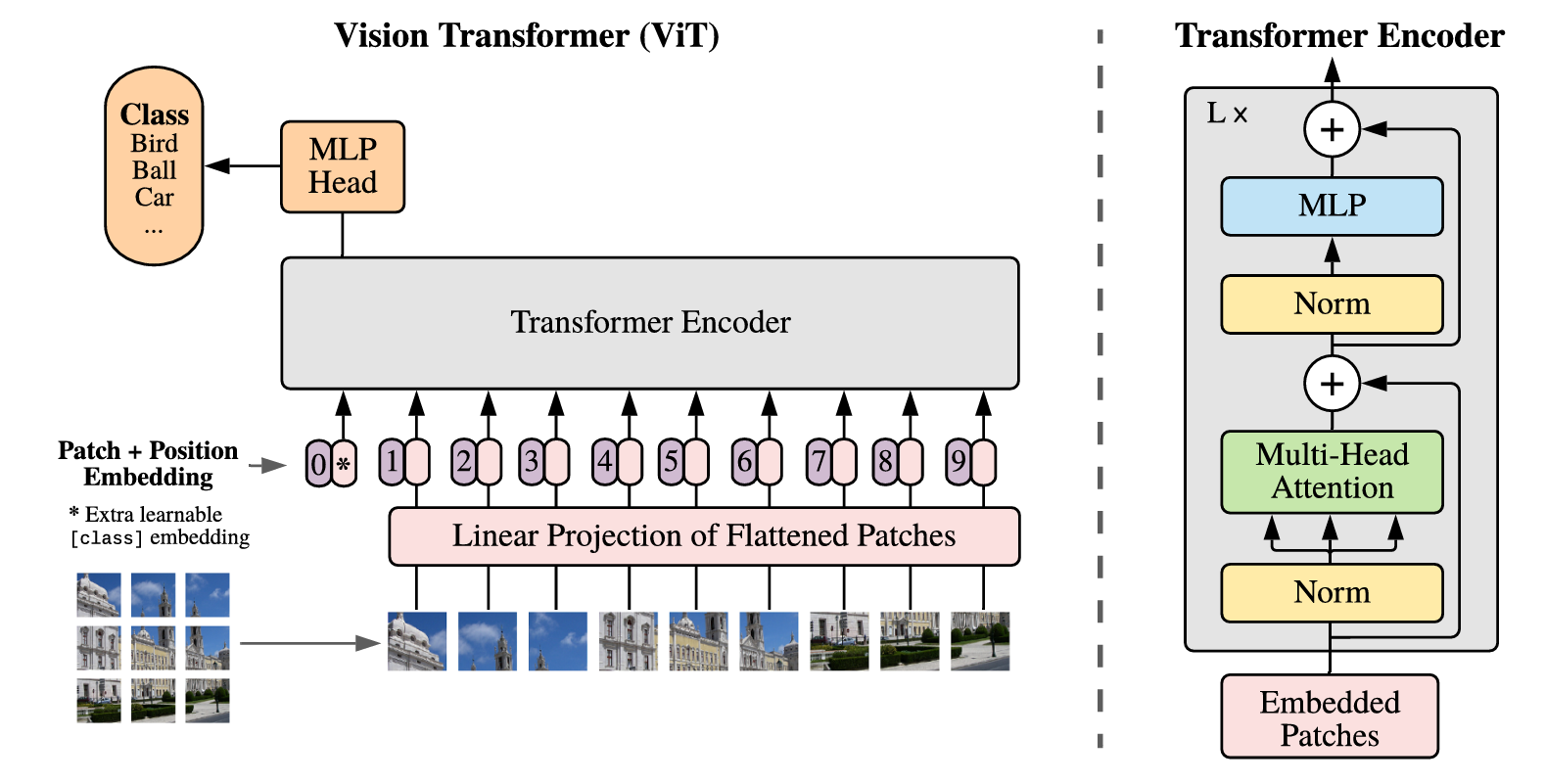
然后经过Transformer的L个Encoder
最后经过MLP,输出
2.Patch embedding
先将224×224像素的图片分割为14×14个patch,每个patch大小为16×16×3:
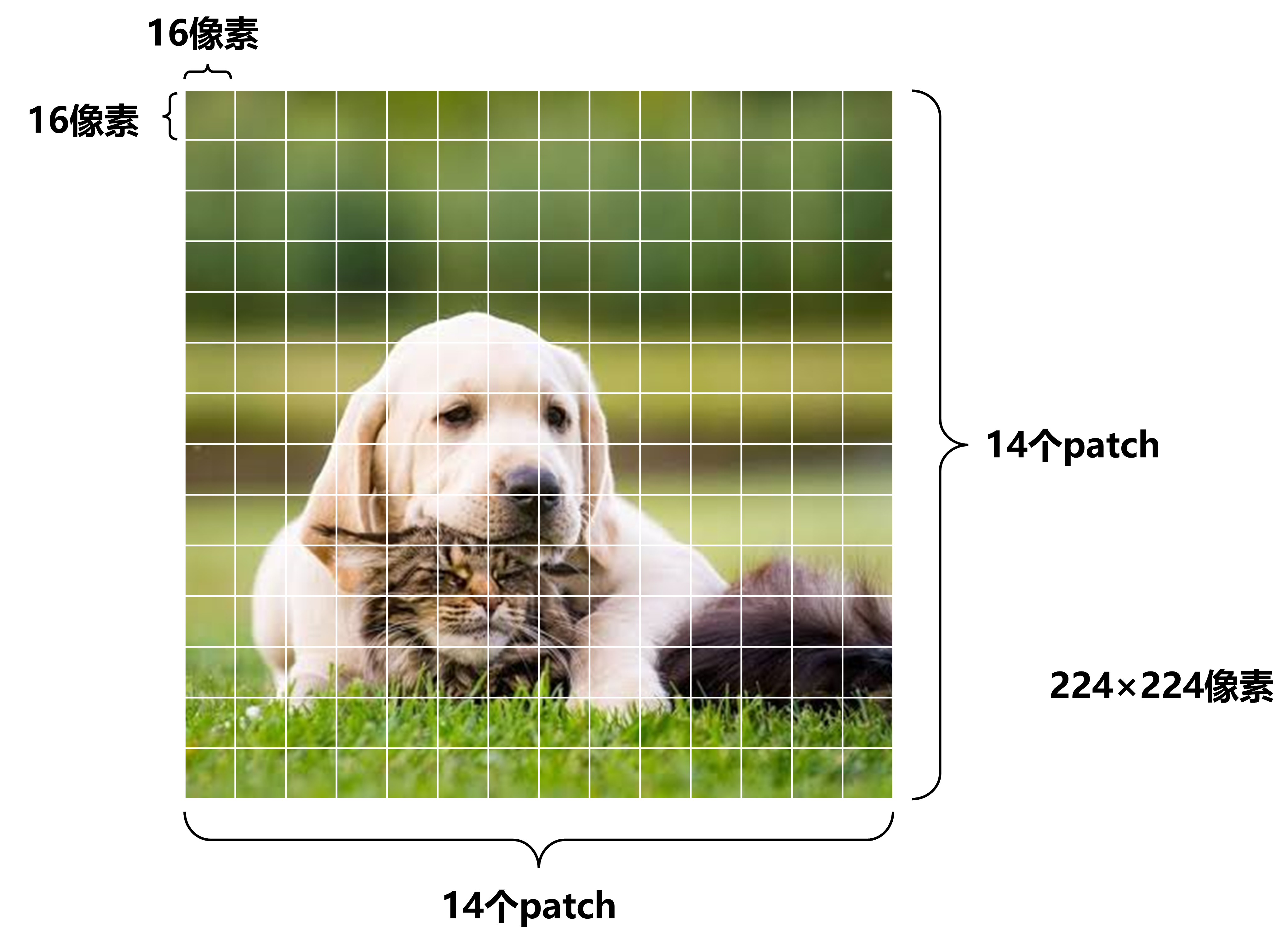
将每个patch展平成一维(长度为16×16×3=768)
将14×14(196)个patch合并组成196×768的矩阵
将这个矩阵经过一层神经网络,映射到高维度(base版本映射后还是196×768维)
3.添加 class token
参考BERT,在刚刚得到的矩阵上插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样是一个768维向量
其作用是聚合整张图像的全局特征,以便最后用于分类任务。
- 它是一个 可学习的向量,训练中不断调整。
- 和其他 patch token 一样参与每一层的 多头注意力机制。
- 每一层都可以让 class token 和其他 patch token 互相“交流”信息。
- 最终,class token 吸收了整张图像中各个 patch 的信息。
- 最后一层 transformer 输出时,直接取 class token 的输出(shape:
(1, D))作为整张图像的表示,再送入分类头(一个线性层)
添加后输出为(197×768)
4.位置编码
生成一个(197×768)的可学习矩阵,直接加上刚刚的输出
原文中实验表明这种可学习的1d位置嵌入性能不比2d差
5.Transformer Encoder
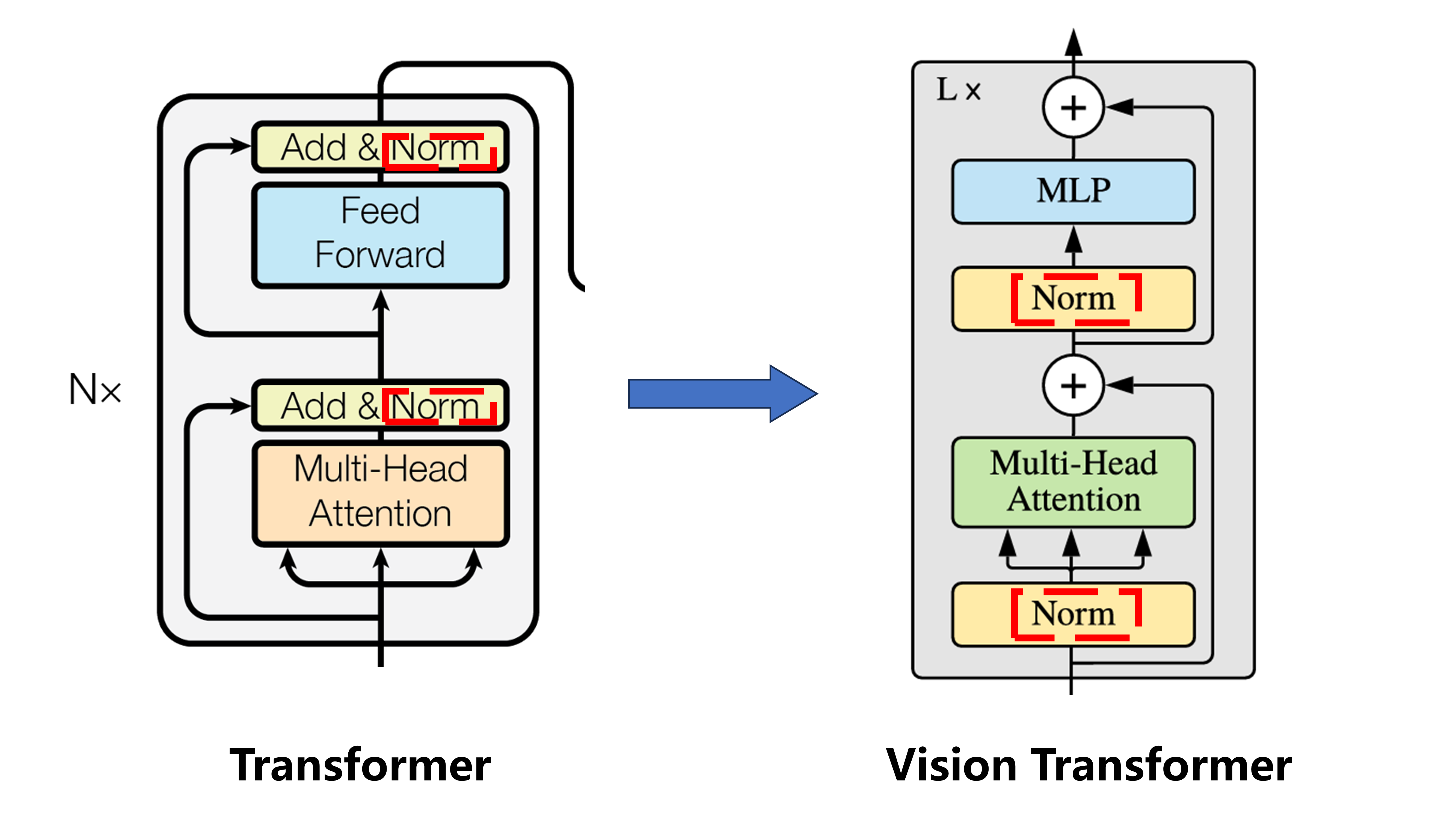
Vision Transformer中Encoder block和Transformer中结构基本相同,只有一点不同:
就是层归一化的顺序
Transformer中:多头注意力→残差相加→层归一化→线性层→残差相加→层归一化
Vision Transformer中:层归一化→多头注意力→残差相加→层归一化→线性层→残差相加
base版本中Encoder block重复12次
Encoder不改变维度,因此Encoder的输出还是(197×768)
6.MLP
训练ImageNet21K时是由Linear+tanh激活函数+Linear组成
但是迁移到ImageNet1K上或者自己的数据上时,只用一个Linear即可
这里只取Encoder输出的第一行输入进NLP(也就是 class token 对应的向量)
输出是分类的个数
参考:

















 2169
2169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









