




上一节我们构造出如下结构的神经网络:
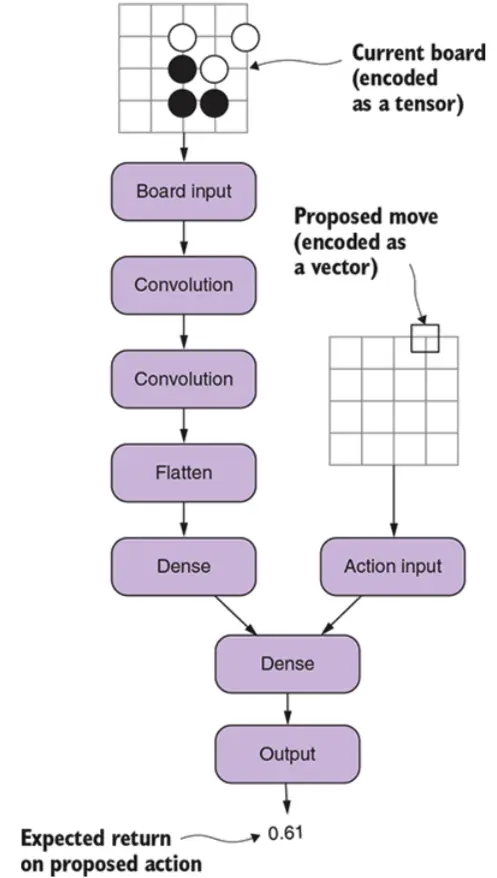
本节我们看看如何使用该网络训练围棋机器人。我们在标题中提到Q-Learning,它实际上是一种使用上面网络进行训练的算法流程。首先我们先定义执行Q-Learning算法的机器人对象:
class QAgent:
def __init(self, model, encoder):
#参数model就是我们构造的神经网络
self.model = model
self.encoder = encoder #对棋盘的编码
self.temperature = 0 #对应epsilong参数
def set_temperature(self, temperature):
self.temperature = temperature #该参数的值越大,机器人胆子就越大,就越多的进行随机落子
def set_collector(self, collector):
#collector包含了机器人对弈时的棋盘数据
self.collector = collector
在上面代码实现中,参数temperature对应上一章我们说过的epsilong参数,这个参数的值越大,QAgent的随机性就越强.同时代码中的collector根前几节一样,它收集了两个机器人对弈的大量棋盘数据,这些数据将用于执行Q-Learning算法。接着我们看看基于Q-Learning算法的围棋机器人如何选择落子策略:
def select_move(self, game_state):
board_tensor = self.encoder.encode(game_state 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1542
1542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









