






#include <iostream>
int main()
{
std::cout<<"Hello World\n";
while(int i = 0){
std::cout<<"test....\n"<<std::endl;
}
std::cout<<"test end....\n"<<std::endl;
return 0;
}

2
#include <iostream>
#include <vector>
using namespace std;
int main(void)
{
vector<int>array;
array.push_back(100);
array.push_back(300);
array.push_back(300);
array.push_back(300);
array.push_back(300);
array.push_back(500);
vector<int>::iterator itor;
for(itor=array.begin();itor!=array.end();itor++)
{
if(*itor==300)
{
itor=array.erase(itor);
}
}
for(itor=array.begin();itor!=array.end();itor++)
{
cout<<*itor<<"\n";
}
return 0;
}
输出的结果会是什么呢?
需要注意erase()函数,vector::erase():从指定容器删除指定位置的元素或某段范围内的元素
讲解:也就是会出现当删除第一个300元素的时候,iteractor迭代器会跳到第二个值为300的位置,然后在for循环里面又++一次了,所以迭代器就跳到了第三个300元素的位置,然后这第三个300删除了,然后又跳过第四个300,到了500,最后结束循环
所以最后的结果是:
100
300(第二个)
300(第四个)
500
需要把循环的规则给改一下

#include <iostream>
#include <vector>
using namespace std;
int main(void)
{
vector<int>array;
array.push_back(100);
array.push_back(300);
array.push_back(300);
array.push_back(300);
array.push_back(300);
array.push_back(500);
vector<int>::iterator itor;
for(itor=array.begin();itor!=array.end();)
{
if(*itor==300)
{
itor=array.erase(itor);
}else{
itor++;
}
}
for(itor=array.begin();itor!=array.end();itor++)
{
cout<<*itor<<"\n";
}
return 0;
}

归纳总结一下erase函数
#include <iostream>
#include <vector>
using namespace std;
int main(void)
{
vector<int>array;
array.push_back(100);
array.push_back(300);
array.push_back(300);
array.push_back(300);
array.push_back(300);
array.push_back(500);
vector<int>::iterator itor;
std::string str = "hello world";
str.erase();
str.erase(str.begin() + 1, str.end() - 2);
/*
for(itor=array.begin();itor!=array.end();)
{
if(*itor==300)
{
itor=array.erase(itor);
}else{
itor++;
}
}*/
std::cout<<"===="<<std::endl;
for(auto x = str.begin(); x != str.end(); x++)
{
cout<<*x<<"\n";
}
std::cout<<"===="<<std::endl;
return 0;
}
/*
====
h
l
d
====
*/
总结来说,erase函数可以删除全部内容、删除所在位置的内容(注意迭代器的位置会自动加一)、删除指定范围内的内容
3 fopen函数操作
r 以只读方式打开文件,该文件必须存在。
r+ 以读/写方式打开文件,该文件必须存在。
rb+ 以读/写方式打开一个二进制文件,只允许读/写数据。
rt+ 以读/写方式打开一个文本文件,允许读和写。
w 打开只写文件,若文件存在则长度清为 0,即该文件内容消失,若不存在则创建该文件。
w+ 打开可读/写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
a 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留(EOF 符保留)。
a+ 以附加方式打开可读/写的文件。若文件不存在,则会建立该文件,如果文件存在,则写入的数据会被加到文件尾后,即文件原先的内容会被保留(原来的 EOF 符不保留)。
wb 以只写方式打开或新建一个二进制文件,只允许写数据。
wb+ 以读/写方式打开或建立一个二进制文件,允许读和写。
wt+ 以读/写方式打开或建立一个文本文件,允许读写。
at+ 以读/写方式打开一个文本文件,允许读或在文本末追加数据。
ab+ 以读/写方式打开一个二进制文件,允许读或在文件末追加数据。
4
#include <iostream>
#include <vector>
using namespace std;
int main(void)
{
int r = 5;
int l;
l = r++; // 先将 r 的值 5 赋给 l,然后 r 的值增加 1
// 此时 l = 5, r = 6
std::cout<<l<<" "<<r<<std::endl;
l = ++r; // 先将 r 的值增加 1,然后将 r 的值 7 赋给 l
// 此时 l = 7, r = 7
std::cout<<l<<" "<<r<<std::endl;
return 0;
}

5
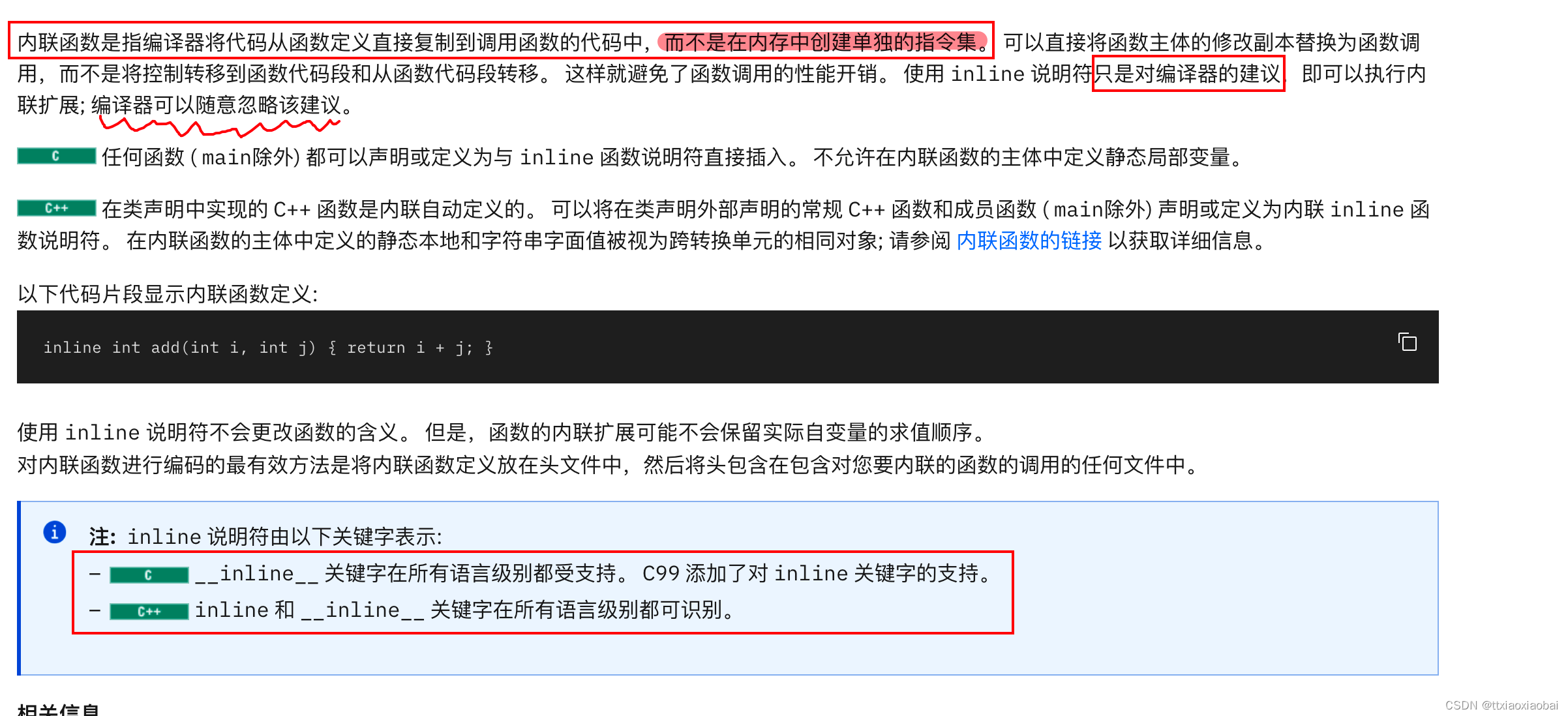
内联函数
来源
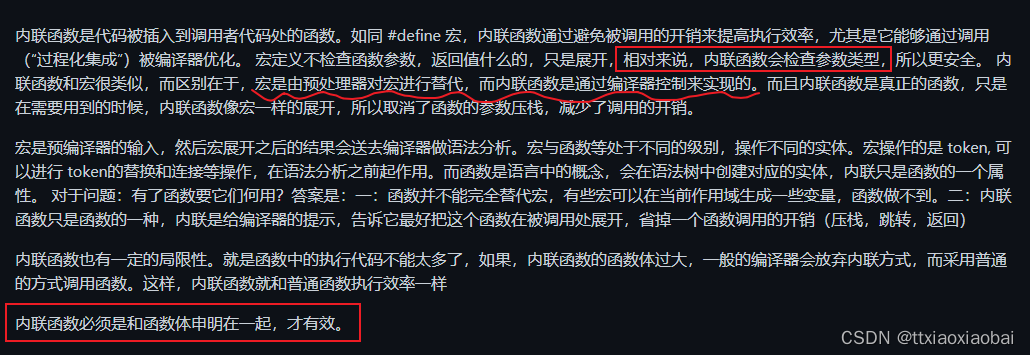
在effective c++ 笔记中看到了这样一句话, inline 替换 #define 有点疑惑,然后就查阅了相关的文章,宏定义是用预处理器处理,不会进行函数检查,而内联函数是经过编译器处理的,尽管有可能编译器不接受处理(因为原话大意是这样的,内联函数只是建议,而不是强制,编译器可能不受这条建议。)内联函数,比宏定义的优势在于会检查函数,但比真正函数的优势又在于,可以调高效率,减少开销。具体怎么减少开销?
首先我们先来讲一下函数是如何调用的。程序执行 函数调用 指令的时候,CPU执行调用函数的指令,将函数的参数赋值到堆栈中,然后控制权转移到指定的函数。CPU执行函数代码,将函数返回值存储到预定义的内存位置/寄存器中,并将控制权返回给被调函数。如果函数的执行时间少于从调用函数到被调函数的切换时间,这就会成为开销。对于大型函数/执行复杂任务的函数,执行时间会比调用时间多得多。对于小功能,由于小功能执行时间少于切换时间,因此会产生开销。
注意一下哪些函数尽量不要选择内联函数、声明定义内联函数时需要注意的地方、内联函数对调试不友好。



又听到隐式内联,又一下子懵了
//参考:https://stibel.icu/md/c++/basic/c++-basic-use.html
// 类内定义,隐式内联
class A {
int doA() { return 0; } // 隐式内联
}
// 类外定义,需要显式内联
class A {
int doA();
}
inline int A::doA() { return 0; } // 需要显式内联
进一步的

#include <iostream>
using namespace std;
class Base
{
public:
inline virtual void who()
{
cout << "I am Base\n";
}
virtual ~Base() {}
};
class Derived : public Base
{
public:
inline void who() // 不写inline时隐式内联
{
cout << "I am Derived\n";
}
};
int main()
{
// 此处的虚函数 who(),是通过类(Base)的具体对象(b)来调用的,编译期间就能确定了,所以它可以是内联的,但最终是否内联取决于编译器。
Base b;
b.who();//I am Base
// 此处的虚函数是通过指针调用的,呈现多态性,需要在运行时期间才能确定,所以不能为内联。
Base *ptr = new Derived();
ptr->who();//I am Derived
// 因为Base有虚析构函数(virtual ~Base() {}),所以 delete 时,会先调用派生类(Derived)析构函数,再调用基类(Base)析构函数,防止内存泄漏。
delete ptr;
ptr = nullptr;
return 0;
}
6
7

在64位系统下,分别定义如下两个变量:char *p[10]; char(*p1)[10];请问,sizeof§和sizeof (p1)分别值为____。
重点理解p跟谁结合了,跟[]结合,则p就是一个数组;跟*结合,p就是一个指针;
首先[]()的优先级一样,均大于*
char *p[10],p与[]结合,所以p就是一个数组,数组的元素比较特殊,是指针,指针大小为8,所以是10*8=80;
char(*p1)[10],与*结合,所以是一个指针,大小为8
# 注意 64位的指针大小为8B 32位的指针大小为4B

8
auto 变量类型推演,
register 建议编译器将该变量放入cpu,
static 静态变量,
extern 声明变量,常用于多文件需要使用同一变量时
register int a[1000]存储速率>>int a[1000]
register修饰符暗示编译程序相应的变量将被频繁地使用,如果可能的话,应将其保存在CPU的寄存器中,以加快其存储速度。
使用register修饰符有几点限制
(1)register变量必须是能被CPU所接受的类型。
这通常意味着register变量必须是一个单个的值,并且长度应该小于或者等于整型的长度。不过,有些机器的寄存器也能存放浮点数。
(2)因为register变量可能不存放在内存中,所以不能用“&”来获取register变量的地址。
(3)只有局部自动变量和形式参数可以作为寄存器变量,其它(如全局变量)不行。
在调用一个函数时占用一些寄存器以存放寄存器变量的值,函数调用结束后释放寄存器。此后,在调用另外一个函数时又可以利用这些寄存器来存放该函数的寄存器变量。
(4)局部静态变量不能定义为寄存器变量。不能写成:register static int a, b, c;
(5)由于寄存器的数量有限(不同的cpu寄存器数目不一),不能定义任意多个寄存器变量,而且某些寄存器只能接受特定类型的数据(如指针和浮点数),因此真正起作用的register修饰符的数目和类型都依赖于运行程序的机器,而任何多余的register修饰符都将被编译程序所忽略。
原文链接:https://blog.youkuaiyun.com/21aspnet/article/details/257511
9
#include<iostream>
#include<string>
using namespace std;
class A
{
friend long fun(A s)
{
if (s.x<3) {
return 1;
}
return s.x+fun(A(s.x - 1));
}
public:
A(long a)
{
x = a--;
}
private:
long x;
};
int main()
{
int sum=0;
for( int i=0; i<5; i++) {
sum += fun(A(i));
}
cout<<sum;
}
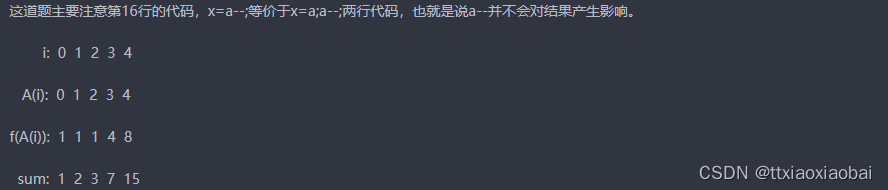
10
- malloc,calloc,realloc,free属于C函数库,而new/delete则是C++函数库;
-
多个-alloc的比较:
alloc:唯一在栈上申请内存的,无需释放;
malloc:在堆上申请内存,最常用;
calloc:malloc+初始化为0;
realloc:将原本申请的内存区域扩容,参数size大小即为扩容后大小,因此此函数要求size大小必须大于ptr内存大小。
参考1
参考2
11
12
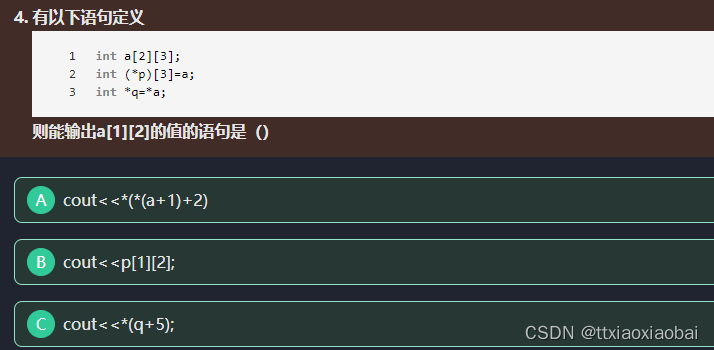
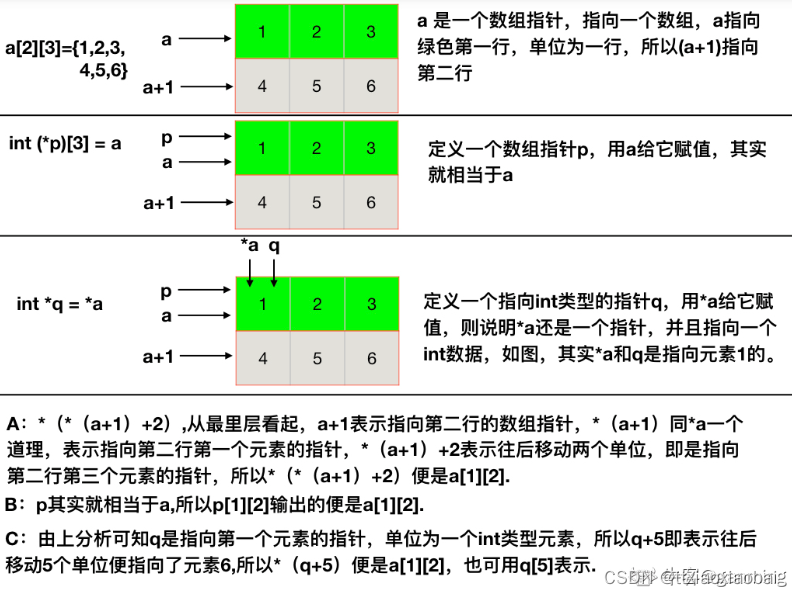
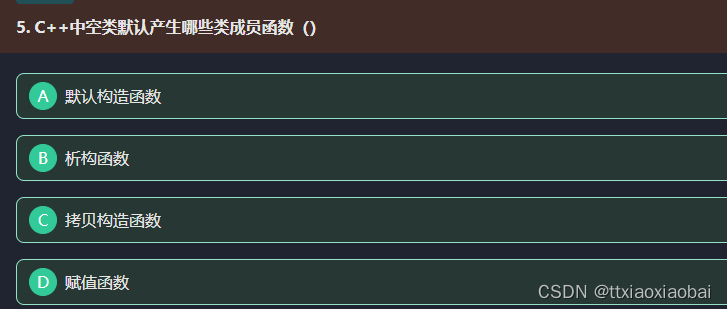
13 size 和strlen 都是统计显示的字符串长度,会忽略结束符 结束符 隐式
而sizeof 会显示系统分配给str 的真实内存大小
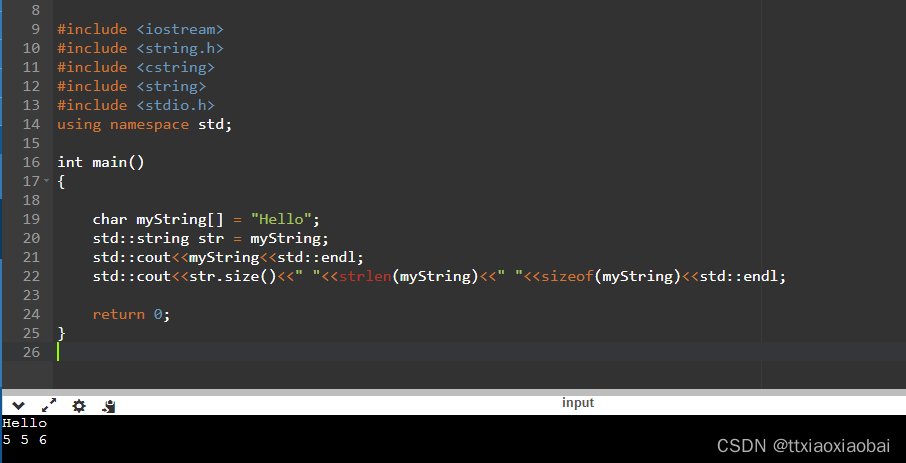

















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









