




 本文介绍了一种计算Top-K精度、召回率和F1分数的方法,适用于机器学习中多个预测结果的评估。通过实例展示了如何对同一样本的Top-K预测结果进行评估,并提供了Python代码实现。
本文介绍了一种计算Top-K精度、召回率和F1分数的方法,适用于机器学习中多个预测结果的评估。通过实例展示了如何对同一样本的Top-K预测结果进行评估,并提供了Python代码实现。
sklearn.metrics中的评估函数只能对同一样本的单个预测结果进行评估,如下所示:
from sklearn.metrics import classification_report
y_true = [0, 5, 0, 3, 4, 2, 1, 1, 5, 4]
y_pred = [0, 2, 4, 5, 2, 3, 1, 1, 4, 2]
print(classification_report(y_true, y_pred))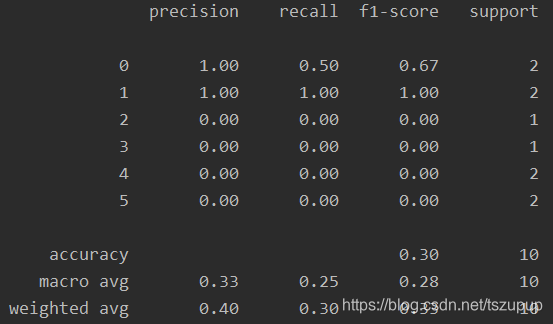
而我们经常会遇到需要对同一样本的top-k个预测结果进行评估的情况,此时算法针对单个样本的预测结果是一个按可能性排序的列表,如下所示:
y_true = [0, 5, 0, 3, 4, 2, 1, 1, 5, 4]
y_pred = [[0, 0, 2, 1, 5],
[2, 2, 4, 1, 4],
[4, 5, 1, 3, 5],
[5, 4, 2, 4, 3],
[2, 0, 0, 2, 3],
[3, 3, 4, 1, 4],
[1, 1, 0, 1, 2],
[1, 4, 4, 2, 4],
[4, 1, 3, 3, 5],
[2, 4, 2, 2, 3]]针对以上这种情况,我们要如何评估算法的好坏呢?我们需要precision@k、recall@k和f1_score@k等指标,下面给出计算这些指标的函数及示例。
from _tkinter import _flatten
# 统计所有的类别
def get_unique_labels(y_true, y_pred) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 220
220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









