




目录
1.3 违反 SRP 的 3 个典型场景(C++ 开发者必中)
3.2.1 日志模块:FileLogger.h/.cpp(只负责日志)
3.2.2 数据库模块:MysqlDao.h/.cpp(只负责数据库)
3.2.3 通知模块:SmsNotification.h/.cpp(只负责短信)
3.2.4 订单核心模块:OrderService.h/.cpp(只负责订单核心逻辑)
4.2 场景 2:模块级别的 SRP—— 拆分臃肿的网络模块
五、实战避坑指南:C++ 开发者容易踩的 5 个 SRP 误区

class 卑微码农:
def __init__(self):
self.技能 = ['能读懂十年前祖传代码', '擅长用Ctrl+C/V搭建世界', '信奉"能跑就别动"的玄学']
self.发量 = 100 # 初始发量
self.咖啡因耐受度 = '极限'
def 修Bug(self, bug):
try:
# 试图用玄学解决问题
if bug.严重程度 == '离谱':
print("这一定是环境问题!")
else:
print("让我看看是谁又没写注释...哦,是我自己。")
except Exception as e:
# 如果try块都救不了,那就...
print("重启一下试试?")
self.发量 -= 1 # 每解决一个bug,头发-1
# 实例化一个我
我 = 卑微码农()引言:为什么你写的 C++ 代码越维护越难?

作为 C++ 开发者,你大概率遇到过这些窒息场景:
- 接手一个老项目,打开
OrderSystem.cpp文件瞬间懵了 ——3000 多行代码里塞了订单创建、库存扣减、日志记录、短信通知、数据库操作,堪称 “一站式全能工具”; - 产品要求给订单加个 “加急标识”,你只是加了一行
order->is_urgent = true,结果编译通过后,日志输出乱码、库存扣减重复、甚至支付回调超时,排查半天才发现是修改时不小心动了相邻的日志格式化逻辑; - 团队协作时,你和同事同时修改
UserManager.cpp,他改用户登录逻辑,你加用户权限校验,频繁出现代码冲突,每次合并都要花半小时核对; - 想复用 “日志记录” 功能到新模块,却发现它和订单逻辑深度耦合,只能复制粘贴代码,导致项目中出现 N 个相似的日志函数,后续修改要改 N 处。
这些问题的根源,不是你 C++ 语法不熟练,也不是逻辑思维不够强,而是忽略了面向对象设计的 “第一块基石”—— 单一职责原则(Single Responsibility Principle,简称 SRP)。
很多 C++ 开发者沉迷于钻研语法特性(比如模板、智能指针、并发编程),却轻视了设计原则的重要性。但实际开发中,糟糕的设计比糟糕的代码更致命—— 语法错误能被编译器发现,而设计缺陷会潜伏在项目中,随着代码量增长和需求变更,最终让项目变得难以维护,甚至被推翻重写。
这篇文章就带你彻底吃透单一职责原则,没有枯燥的理论堆砌,只有 C++ 实战场景 + 可运行代码 + 真实踩坑经验。不管你是刚入门 C++ 的新手,还是想提升代码质量的初中级开发者,读完这篇文章,都能学会用 SRP 重构代码,告别 “改一行崩一片” 的噩梦。
一、先搞懂:单一职责原则到底是什么?
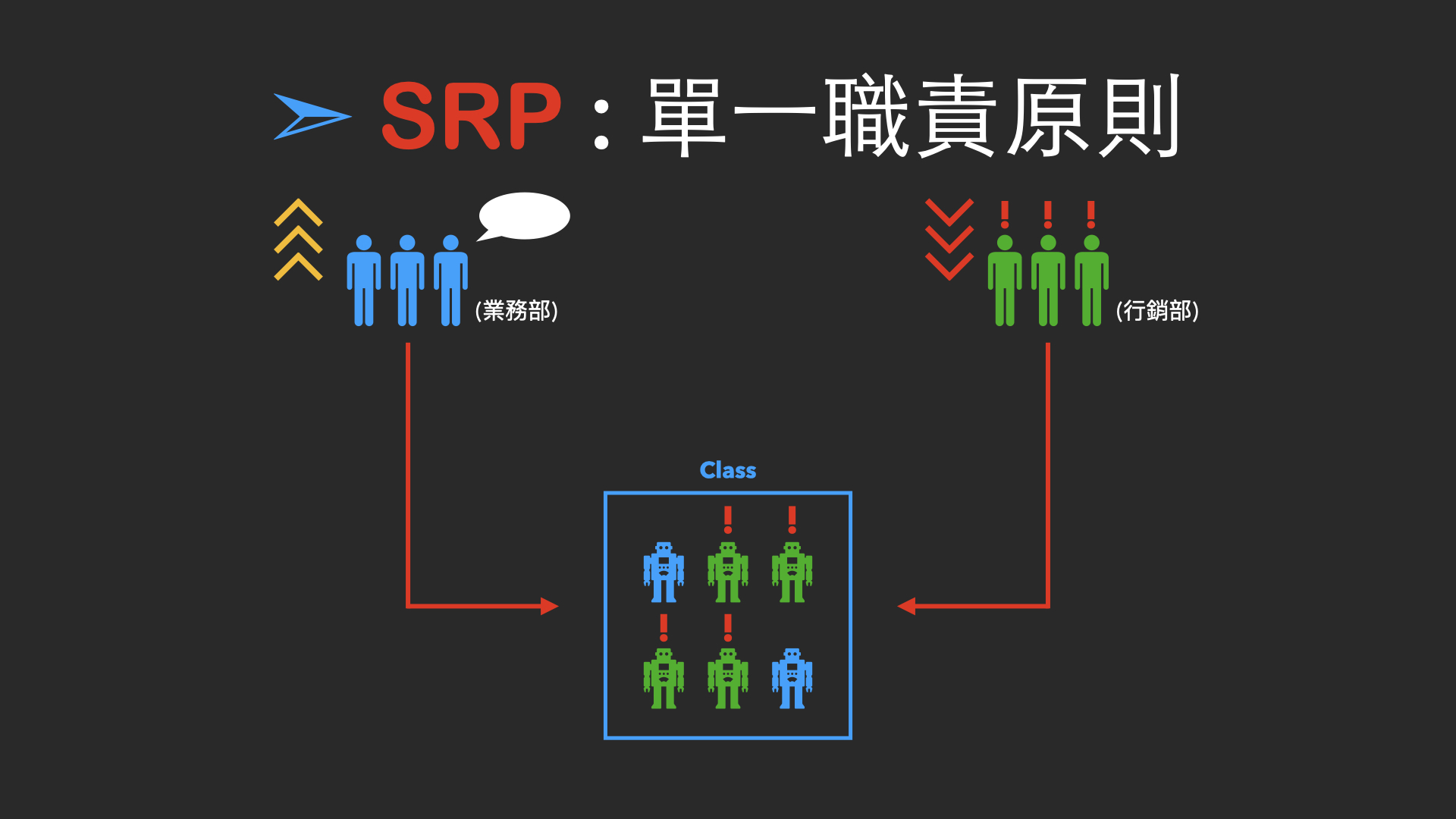
1.1 核心定义:一个类 / 模块 / 函数,只做一件事
单一职责原则的核心是 “职责边界清晰”——一个软件实体(类、模块、函数)应该只有一个引起它变化的原因。
这里的 “软件实体” 包含三个层面,也是我们实际开发中需要重点关注的:
- 类级别的 SRP:一个类只负责一个业务功能,比如 “订单类” 只处理订单相关逻辑,“日志类” 只处理日志相关逻辑;
- 模块级别的 SRP:一个模块(比如一个
.h+.cpp` 文件对)只封装一个独立的功能模块,比如 “日志模块”“数据库模块”“网络模块”; - 函数级别的 SRP:一个函数只完成一个具体的操作,比如 “计算订单总价”“读取配置文件”“发送网络请求”。
用一句通俗的话解释:让每个部分只干自己的 “本职工作”,不越权、不跨界。
1.2 为什么 “引起变化的原因” 是核心?
很多人会把 SRP 简单理解为 “一个类只有一个方法”,这是典型的误解。一个类可以有多个方法,只要这些方法都围绕同一个核心职责,并且这些方法的变化原因是一致的,就符合 SRP。
比如 “日志类” 可以有info()“warn()“error()三个方法,它们的变化原因都是 “日志格式需要修改” 或 “日志输出目标需要变更”(比如从控制台输出改为文件输出),这就符合 SRP;而如果日志类里加了一个calculate_order_price()方法,这个方法的变化原因是 “订单计价规则变更”,和日志类的核心职责无关,就违反了 SRP。
所以判断是否符合 SRP 的关键,不是 “有多少个方法”,而是 “有多少个独立的变化原因”。
1.3 违反 SRP 的 3 个典型场景(C++ 开发者必中)
在 C++ 开发中,违反 SRP 的场景非常普遍,尤其是在新手或赶进度的项目中:
- “万能类” 泛滥:一个类包揽所有相关不相关的功能,比如
OrderHandler类既处理订单创建、修改、取消,又负责日志记录、数据库存储、短信通知,代码行数轻松破万; - “超长函数” 横行:一个函数写几百行代码,从参数校验、业务逻辑、数据处理到结果返回全在里面,比如
process_data()函数既读取文件,又解析数据,还进行计算和存储; - 模块边界模糊:一个模块依赖另一个模块的内部实现,比如 “订单模块” 直接操作 “用户模块” 的私有成员变量,导致两个模块绑定在一起,修改一个模块必须同步修改另一个。
1.4 违反 SRP 的 4 大致命后果
为什么我们必须重视 SRP?因为违反它会带来一系列连锁问题,让项目维护成本呈指数级增长:
- 可读性差:新接手的开发者需要花大量时间理解一个 “万能类” 的所有功能,比如想改日志格式,却要在订单处理的代码中翻找半天;
- 维护成本高:修改一个功能时,很可能影响其他不相关的功能,比如改订单取消逻辑,不小心破坏了日志输出格式;
- 扩展性差:新增功能只能往现有类 / 函数中 “堆代码”,让 “万能类” 越来越臃肿,形成恶性循环;
- 复用性低:因为类 / 模块耦合严重,无法单独抽离出来复用,比如想在另一个项目中使用日志功能,却因为它依赖订单逻辑而无法直接复用;
- 测试困难:一个类承担多个职责,导致单元测试需要覆盖所有场景,测试用例复杂且冗余,甚至无法单独测试某个功能。
二、C++ 反例实战:一个违反 SRP 的 “万能订单类”

为了让大家更直观地感受违反 SRP 的问题,我们用 C++ 实现一个真实场景中的 “万能订单类”,看看它到底有多难用。
2.1 需求背景
假设我们需要实现一个简单的订单处理功能,核心需求包括:
- 创建订单(校验参数、生成订单号);
- 保存订单到数据库;
- 记录订单操作日志;
- 发送短信通知给用户。
2.2 违反 SRP 的 C++ 实现代码
#include <iostream>
#include <string>
#include <ctime>
#include <mysql/mysql.h> // 假设使用MySQL数据库
#include <vector>
// 违反单一职责原则的万能订单类:包揽订单处理、日志、数据库、短信4个职责
class OrderHandler {
public:
// 构造函数:初始化数据库连接(硬编码,实际项目中更混乱)
OrderHandler() {
// 数据库连接逻辑(本应属于数据库模块)
conn_ = mysql_init(nullptr);
if (!mysql_real_connect(conn_, "localhost", "root", "123456", "test_db", 3306, nullptr, 0)) {
std::cerr << "数据库连接失败:" << mysql_error(conn_) << std::endl;
}
}
// 析构函数:关闭数据库连接
~OrderHandler() {
if (conn_) {
mysql_close(conn_);
}
}
// 核心功能:创建订单(包含4个职责的逻辑)
bool createOrder(const std::string& userId, const std::string& productId, int quantity, double price) {
// 职责1:订单参数校验(订单核心职责)
if (userId.empty() || productId.empty() || quantity <= 0 || price <= 0) {
std::cerr << "订单参数非法" << std::endl;
return false;
}
// 职责1:生成订单号(订单核心职责)
std::string orderId = generateOrderId();
std::cout << "生成订单号:" << orderId << std::endl;
// 职责2:记录操作日志(日志职责)
logOperation("用户" + userId + "创建订单:" + orderId + ",商品:" + productId + ",数量:" + std::to_string(quantity));
// 职责3:保存订单到数据库(数据库职责)
std::string sql = "INSERT INTO orders(order_id, user_id, product_id, quantity, price, create_time) "
"VALUES('" + orderId + "', '" + userId + "', '" + productId + "', " + std::to_string(quantity) + ", " + std::to_string(price) + ", NOW())";
if (!executeSql(sql)) {
std::cerr << "订单保存失败" << std::endl;
return false;
}
// 职责4:发送短信通知(通知职责)
sendSms(userId, "您的订单" + orderId + "已创建成功,总价:" + std::to_string(quantity * price) + "元");
std::cout << "订单创建成功" << std::endl;
return true;
}
private:
MYSQL* conn_; // 数据库连接(本应属于数据库模块)
// 生成订单号(订单核心职责)
std::string generateOrderId() {
// 简单实现:时间戳+随机数
time_t now = time(nullptr);
char timeStr[20];
strftime(timeStr, sizeof(timeStr), "%Y%m%d%H%M%S", localtime(&now));
return std::string(timeStr) + std::to_string(rand() % 1000);
}
// 记录操作日志(日志职责)
void logOperation(const std::string& msg) {
// 输出到控制台(实际项目中可能写入文件)
time_t now = time(nullptr);
char timeStr[20];
strftime(timeStr, sizeof(timeStr), "[%Y-%m-%d %H:%M:%S]", localtime(&now));
std::cout << timeStr << " [INFO] " << msg << std::endl;
}
// 执行SQL语句(数据库职责)
bool executeSql(const std::string& sql) {
if (mysql_query(conn_, sql.c_str())) {
std::cerr << "SQL执行失败:" << mysql_error(conn_) << ",SQL:" << sql << std::endl;
return false;
}
return true;
}
// 发送短信通知(通知职责)
void sendSms(const std::string& userId, const std::string& msg) {
// 模拟短信发送(实际项目中可能调用第三方接口)
std::cout << "向用户" << userId << "发送短信:" << msg << std::endl;
}
};
// 主函数测试
int main() {
OrderHandler orderHandler;
// 创建订单
orderHandler.createOrder("user1001", "product2001", 2, 99.9);
return 0;
}
2.3 反例代码的致命问题分析
上面的代码看似实现了需求,但在实际开发中会带来一系列问题,每一个都让维护者头疼:
- 代码臃肿,可读性差:
OrderHandler类包揽了 4 个完全独立的职责,代码行数多,逻辑混乱,新开发者需要花大量时间理清哪个部分对应哪个功能; - 修改牵一发而动全身:如果需要修改日志格式(比如增加日志级别),必须修改
OrderHandler类的logOperation方法;如果数据库密码变更,需要修改OrderHandler的构造函数;如果短信接口变更,需要修改sendSms方法 —— 任何一个职责的变更都要改动这个 “万能类”,风险极高; - 复用性为零:如果另一个模块(比如用户模块)需要记录日志,无法直接复用
logOperation方法,因为它属于OrderHandler类,和订单逻辑绑定; - 测试困难:要测试
createOrder方法,必须先搭建 MySQL 数据库环境,否则数据库连接失败会导致整个测试无法进行;而且无法单独测试 “订单生成” 或 “日志记录” 功能,必须测试完整流程; - 耦合严重:数据库连接、日志逻辑、短信发送都被硬编码在
OrderHandler类中,无法替换实现,比如想把日志从控制台输出改为文件输出,或者把 MySQL 换成 PostgreSQL,都需要大量修改代码; - 并发风险:
conn_是OrderHandler的成员变量,如果多个线程同时调用createOrder方法,会导致数据库连接并发访问,出现数据错乱或崩溃。
2.4 需求变更后的噩梦:修改代码引发连锁反应
假设过了一段时间,产品提出两个新需求:
- 日志需要写入文件,而不是控制台;
- 短信通知可配置,部分用户不需要发送短信。
我们来看看修改这些需求会遇到什么问题:
- 修改日志输出方式:需要修改
logOperation方法,把控制台输出改为文件写入。但logOperation是OrderHandler的私有方法,修改后可能影响其他依赖该方法的逻辑(比如如果有其他地方调用了它);而且文件操作需要处理文件打开、关闭、权限等问题,会让OrderHandler类的代码更臃肿; - 添加短信配置开关:需要在
createOrder方法中增加判断逻辑,比如传入一个needSms参数,决定是否发送短信。这会修改createOrder的函数签名,所有调用该方法的地方都需要同步修改;同时,短信配置可能需要从配置文件读取,这又会让OrderHandler类增加 “读取配置” 的新职责,进一步违反 SRP。
更可怕的是,修改过程中很可能引入新的 bug,比如修改logOperation时不小心删了订单号的输出,或者添加needSms判断时逻辑写错,导致所有用户都收不到短信。
三、C++ 重构实战:遵循 SRP,让代码清爽可维护

针对上面的反例,我们按照单一职责原则进行重构,核心思路是职责拆分—— 把OrderHandler类的 4 个职责拆分为 4 个独立的类,每个类只负责自己的核心功能,然后通过 “组合” 的方式关联起来。
3.1 重构思路:职责拆分与模块划分
首先明确每个职责的边界,拆分为以下 4 个独立的模块(类):
- 订单核心模块(OrderService):只负责订单相关的核心逻辑,包括参数校验、订单号生成、订单信息封装,不涉及日志、数据库、短信;
- 日志模块(FileLogger):只负责日志记录,支持控制台输出、文件输出等多种方式,提供统一的日志接口;
- 数据库模块(MysqlDao):只负责数据库操作,封装数据库连接、SQL 执行等逻辑,提供订单数据的增删改查接口;
- 通知模块(SmsNotification):只负责短信通知,提供发送短信的接口,支持配置开关。
模块之间通过 “依赖注入” 的方式关联,即一个模块不直接创建另一个模块的实例,而是通过构造函数或参数传入,这样可以灵活替换模块的实现,降低耦合。
3.2 重构后的 C++ 代码(完整可运行)
3.2.1 日志模块:FileLogger.h/.cpp(只负责日志)
// FileLogger.h
#ifndef FILE_LOGGER_H
#define FILE_LOGGER_H
#include <string>
#include <fstream>
#include <ctime>
// 日志级别枚举
enum class LogLevel {
INFO,
WARN,
ERROR
};
// 日志类:只负责日志记录,符合单一职责原则
class FileLogger {
public:
// 构造函数:指定日志文件路径
explicit FileLogger(const std::string& logFilePath);
~FileLogger();
// 禁止拷贝和赋值(避免日志文件被多次打开)
FileLogger(const FileLogger&) = delete;
FileLogger& operator=(const FileLogger&) = delete;
// 日志记录接口(支持不同级别)
void log(LogLevel level, const std::string& msg);
private:
std::ofstream logFile_; // 日志文件流
// 生成日志时间戳
std::string getTimestamp();
// 转换日志级别为字符串
std::string levelToString(LogLevel level);
};
#endif // FILE_LOGGER_H
// FileLogger.cpp
#include "FileLogger.h"
#include <iostream>
// 构造函数:打开日志文件
FileLogger::FileLogger(const std::string& logFilePath) {
logFile_.open(logFilePath, std::ios::app);
if (!logFile_.is_open()) {
std::cerr << "日志文件打开失败:" << logFilePath << std::endl;
}
}
// 析构函数:关闭日志文件
FileLogger::~FileLogger() {
if (logFile_.is_open()) {
logFile_.close();
}
}
// 生成时间戳
std::string FileLogger::getTimestamp() {
time_t now = time(nullptr);
char timeStr[20];
strftime(timeStr, sizeof(timeStr), "[%Y-%m-%d %H:%M:%S]", localtime(&now));
return std::string(timeStr);
}
// 日志级别转换
std::string FileLogger::levelToString(LogLevel level) {
switch (level) {
case LogLevel::INFO: return "[INFO]";
case LogLevel::WARN: return "[WARN]";
case LogLevel::ERROR: return "[ERROR]";
default: return "[UNKNOWN]";
}
}
// 记录日志(同时输出到控制台和文件)
void FileLogger::log(LogLevel level, const std::string& msg) {
std::string logMsg = getTimestamp() + " " + levelToString(level) + " " + msg + "\n";
// 输出到控制台
std::cout << logMsg;
// 写入日志文件
if (logFile_.is_open()) {
logFile_ << logMsg;
logFile_.flush(); // 立即刷新,避免日志丢失
}
}
3.2.2 数据库模块:MysqlDao.h/.cpp(只负责数据库)
// MysqlDao.h
#ifndef MYSQL_DAO_H
#define MYSQL_DAO_H
#include <string>
#include <mysql/mysql.h>
#include <memory>
// 订单数据结构(数据模型,与数据库表对应)
struct OrderData {
std::string orderId;
std::string userId;
std::string productId;
int quantity;
double price;
};
// 数据库访问类:只负责订单数据的数据库操作,符合单一职责原则
class MysqlDao {
public:
// 构造函数:传入数据库连接参数(依赖注入,灵活配置)
MysqlDao(const std::string& host, const std::string& user, const std::string& passwd,
const std::string& dbName, unsigned int port);
~MysqlDao();
// 禁止拷贝和赋值
MysqlDao(const MysqlDao&) = delete;
MysqlDao& operator=(const MysqlDao&) = delete;
// 保存订单到数据库
bool saveOrder(const OrderData& orderData);
private:
MYSQL* conn_; // 数据库连接
// 初始化数据库连接
bool initConnection();
};
#endif // MYSQL_DAO_H
// MysqlDao.cpp
#include "MysqlDao.h"
#include <iostream>
// 构造函数:初始化连接参数
MysqlDao::MysqlDao(const std::string& host, const std::string& user, const std::string& passwd,
const std::string& dbName, unsigned int port) {
conn_ = mysql_init(nullptr);
if (!conn_) {
std::cerr << "MySQL初始化失败" << std::endl;
return;
}
// 设置字符集(避免中文乱码)
mysql_options(conn_, MYSQL_SET_CHARSET_NAME, "utf8");
// 连接数据库
if (!mysql_real_connect(conn_, host.c_str(), user.c_str(), passwd.c_str(),
dbName.c_str(), port, nullptr, 0)) {
std::cerr << "数据库连接失败:" << mysql_error(conn_) << std::endl;
mysql_close(conn_);
conn_ = nullptr;
} else {
std::cout << "数据库连接成功" << std::endl;
}
}
// 析构函数:关闭数据库连接
MysqlDao::~MysqlDao() {
if (conn_) {
mysql_close(conn_);
conn_ = nullptr;
}
}
// 保存订单
bool MysqlDao::saveOrder(const OrderData& orderData) {
if (!conn_) {
std::cerr << "数据库未连接" << std::endl;
return false;
}
// 构造SQL语句(实际项目中应使用预处理语句,避免SQL注入)
std::string sql = "INSERT INTO orders(order_id, user_id, product_id, quantity, price, create_time) "
"VALUES('" + orderData.orderId + "', '" + orderData.userId + "', '" + orderData.productId + "', "
+ std::to_string(orderData.quantity) + ", " + std::to_string(orderData.price) + ", NOW())";
// 执行SQL
if (mysql_query(conn_, sql.c_str())) {
std::cerr << "SQL执行失败:" << mysql_error(conn_) << ",SQL:" << sql << std::endl;
return false;
}
// 检查受影响的行数
if (mysql_affected_rows(conn_) <= 0) {
std::cerr << "订单保存失败:无数据插入" << std::endl;
return false;
}
return true;
}
3.2.3 通知模块:SmsNotification.h/.cpp(只负责短信)
// SmsNotification.h
#ifndef SMS_NOTIFICATION_H
#define SMS_NOTIFICATION_H
#include <string>
#include <memory>
// 短信通知类:只负责发送短信,符合单一职责原则
class SmsNotification {
public:
// 构造函数:传入是否启用短信开关(配置灵活)
explicit SmsNotification(bool enable = true) : enable_(enable) {}
// 发送短信通知
void sendSms(const std::string& userId, const std::string& msg);
// 设置短信开关
void setEnable(bool enable) { enable_ = enable; }
private:
bool enable_; // 短信开关
};
#endif // SMS_NOTIFICATION_H
// SmsNotification.cpp
#include "SmsNotification.h"
#include <iostream>
// 发送短信(模拟调用第三方接口)
void SmsNotification::sendSms(const std::string& userId, const std::string& msg) {
if (!enable_) {
std::cout << "短信功能已禁用,未发送通知给用户" << userId << std::endl;
return;
}
// 模拟短信发送逻辑(实际项目中可能调用HTTP接口或SDK)
std::cout << "【短信通知】用户" << userId << ":" << msg << std::endl;
}
3.2.4 订单核心模块:OrderService.h/.cpp(只负责订单核心逻辑)
// OrderService.h
#ifndef ORDER_SERVICE_H
#define ORDER_SERVICE_H
#include <string>
#include <memory>
#include "FileLogger.h"
#include "MysqlDao.h"
#include "SmsNotification.h"
// 订单服务类:只负责订单核心逻辑,符合单一职责原则
class OrderService {
public:
// 构造函数:依赖注入日志、数据库、通知模块(不直接创建,降低耦合)
OrderService(std::shared_ptr<FileLogger> logger,
std::shared_ptr<MysqlDao> mysqlDao,
std::shared_ptr<SmsNotification> smsNotification)
: logger_(logger), mysqlDao_(mysqlDao), smsNotification_(smsNotification) {}
// 核心功能:创建订单
bool createOrder(const std::string& userId, const std::string& productId, int quantity, double price);
private:
std::shared_ptr<FileLogger> logger_; // 日志模块(智能指针管理生命周期)
std::shared_ptr<MysqlDao> mysqlDao_; // 数据库模块
std::shared_ptr<SmsNotification> smsNotification_; // 通知模块
// 生成唯一订单号
std::string generateOrderId();
// 订单参数校验
bool validateOrderParams(const std::string& userId, const std::string& productId, int quantity, double price);
};
#endif // ORDER_SERVICE_H
// OrderService.cpp
#include "OrderService.h"
#include <ctime>
#include <cstdlib>
// 初始化随机数种子(只初始化一次)
static void initRandomSeed() {
static bool initialized = false;
if (!initialized) {
srand(static_cast<unsigned int>(time(nullptr)));
initialized = true;
}
}
// 订单参数校验
bool OrderService::validateOrderParams(const std::string& userId, const std::string& productId, int quantity, double price) {
if (userId.empty()) {
if (logger_) {
logger_->log(LogLevel::ERROR, "订单参数校验失败:用户ID为空");
}
return false;
}
if (productId.empty()) {
if (logger_) {
logger_->log(LogLevel::ERROR, "订单参数校验失败:商品ID为空");
}
return false;
}
if (quantity <= 0) {
if (logger_) {
logger_->log(LogLevel::ERROR, "订单参数校验失败:数量必须大于0,当前:" + std::to_string(quantity));
}
return false;
}
if (price <= 0) {
if (logger_) {
logger_->log(LogLevel::ERROR, "订单参数校验失败:价格必须大于0,当前:" + std::to_string(price));
}
return false;
}
return true;
}
// 生成订单号(时间戳+随机数,确保唯一)
std::string OrderService::generateOrderId() {
initRandomSeed();
// 时间戳(精确到秒)
time_t now = time(nullptr);
char timeStr[20];
strftime(timeStr, sizeof(timeStr), "%Y%m%d%H%M%S", localtime(&now));
// 3位随机数(降低重复概率)
int randomNum = rand() % 1000;
char randomStr[4];
snprintf(randomStr, sizeof(randomStr), "%03d", randomNum); // 补零,确保3位
return std::string(timeStr) + randomStr;
}
// 创建订单(核心逻辑,只关注订单本身)
bool OrderService::createOrder(const std::string& userId, const std::string& productId, int quantity, double price) {
// 1. 参数校验
if (!validateOrderParams(userId, productId, quantity, price)) {
return false;
}
// 2. 生成订单号
std::string orderId = generateOrderId();
if (logger_) {
logger_->log(LogLevel::INFO, "用户" + userId + "生成订单号:" + orderId);
}
// 3. 封装订单数据
OrderData orderData;
orderData.orderId = orderId;
orderData.userId = userId;
orderData.productId = productId;
orderData.quantity = quantity;
orderData.price = price;
// 4. 保存订单到数据库(调用数据库模块,不关心实现)
if (!mysqlDao_->saveOrder(orderData)) {
if (logger_) {
logger_->log(LogLevel::ERROR, "订单" + orderId + "保存到数据库失败");
}
return false;
}
// 5. 发送短信通知(调用通知模块,不关心实现)
double totalPrice = quantity * price;
std::string smsMsg = "您的订单" + orderId + "已创建成功!商品:" + productId + ",数量:" + std::to_string(quantity) + ",总价:" + std::to_string(totalPrice) + "元";
smsNotification_->sendSms(userId, smsMsg);
// 6. 记录成功日志
if (logger_) {
logger_->log(LogLevel::INFO, "订单" + orderId + "创建成功,用户:" + userId + ",总价:" + std::to_string(totalPrice));
}
return true;
}
3.2.5 主函数:测试与调用示例
// main.cpp
#include <iostream>
#include <memory>
#include "OrderService.h"
#include "FileLogger.h"
#include "MysqlDao.h"
#include "SmsNotification.h"
int main() {
// 1. 创建各个模块的实例(配置集中管理,灵活替换)
auto logger = std::make_shared<FileLogger>("order_log.txt"); // 日志文件路径
auto mysqlDao = std::make_shared<MysqlDao>("localhost", "root", "123456", "test_db", 3306); // 数据库配置
auto smsNotification = std::make_shared<SmsNotification>(true); // 启用短信通知
// 2. 创建订单服务实例(依赖注入,模块解耦)
OrderService orderService(logger, mysqlDao, smsNotification);
// 3. 测试创建订单
std::cout << "=== 测试创建合法订单 ===" << std::endl;
bool result1 = orderService.createOrder("user1001", "product2001", 2, 99.9);
std::cout << "订单创建结果:" << (result1 ? "成功" : "失败") << std::endl;
std::cout << "\n=== 测试创建非法订单(数量为0) ===" << std::endl;
bool result2 = orderService.createOrder("user1002", "product2002", 0, 199.9);
std::cout << "订单创建结果:" << (result2 ? "成功" : "失败") << std::endl;
std::cout << "\n=== 测试禁用短信通知 ===" << std::endl;
smsNotification->setEnable(false); // 禁用短信
bool result3 = orderService.createOrder("user1003", "product2003", 1, 299.9);
std::cout << "订单创建结果:" << (result3 ? "成功" : "失败") << std::endl;
return 0;
}
3.3 编译与运行说明(确保可复现)
3.3.1 编译命令(GCC)
g++ -std=c++11 main.cpp OrderService.cpp FileLogger.cpp MysqlDao.cpp SmsNotification.cpp -o order_system -lmysqlclient
- 依赖:需要安装 MySQL 开发库(
libmysqlclient-dev),Ubuntu 系统可通过sudo apt-get install libmysqlclient-dev安装; - C++ 标准:使用 C++11 及以上(支持智能指针、 nullptr 等特性)。
3.3.2 数据库表结构(提前创建)
CREATE DATABASE IF NOT EXISTS test_db;
USE test_db;
CREATE TABLE IF NOT EXISTS orders (
id INT AUTO_INCREMENT PRIMARY KEY,
order_id VARCHAR(50) NOT NULL UNIQUE COMMENT '订单号',
user_id VARCHAR(50) NOT NULL COMMENT '用户ID',
product_id VARCHAR(50) NOT NULL COMMENT '商品ID',
quantity INT NOT NULL COMMENT '数量',
price DOUBLE NOT NULL COMMENT '单价',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3.3.3 运行结果示例
数据库连接成功
=== 测试创建合法订单 ===
[2025-05-20 15:30:45] [INFO] 用户user1001生成订单号:20250520153045123
[2025-05-20 15:30:45] [INFO] 订单20250520153045123创建成功,用户:user1001,总价:199.8
【短信通知】用户user1001:您的订单20250520153045123已创建成功!商品:product2001,数量:2,总价:199.8元
订单创建结果:成功
=== 测试创建非法订单(数量为0) ===
[2025-05-20 15:30:45] [ERROR] 订单参数校验失败:数量必须大于0,当前:0
订单创建结果:失败
=== 测试禁用短信通知 ===
[2025-05-20 15:30:45] [INFO] 用户user1003生成订单号:20250520153045456
[2025-05-20 15:30:45] [INFO] 订单20250520153045456创建成功,用户:user1003,总价:299.9
短信功能已禁用,未发送通知给用户user1003
订单创建结果:成功
同时,当前目录下会生成order_log.txt日志文件,记录所有日志信息,便于后续排查问题。
3.4 重构后的核心优势(对比反例)
重构后的代码完全遵循单一职责原则,相比反例有以下 6 大优势:
- 可读性极强:每个类的职责清晰,
FileLogger只管日志,MysqlDao只管数据库,新开发者一眼就能看懂每个模块的作用; - 维护成本极低:修改某个功能时,只需改动对应模块,比如修改日志格式只改
FileLogger,更换数据库只改MysqlDao,不会影响其他模块; - 扩展性极佳:新增功能时只需新增模块,比如想添加 “邮件通知”,只需新增
EmailNotification类,无需修改OrderService;想把日志输出到 ELK,只需新增ElkLogger类,替换FileLogger实例即可; - 复用性极高:每个模块都是独立的,
FileLogger可以直接复用在用户模块、商品模块,MysqlDao可以扩展其他表的操作; - 测试方便:可以单独测试每个模块,比如测试
FileLogger只需调用log方法,无需依赖数据库;测试OrderService时可以用 mock 对象替代真实的数据库和日志模块; - 配置灵活:通过依赖注入传入模块实例,数据库配置、日志文件路径、短信开关等都可以集中管理,便于部署和维护。
四、扩展实战:单一职责原则的 3 个应用场景

单一职责原则不仅适用于类,还可以扩展到模块、函数、甚至项目结构。下面通过 3 个真实场景,展示 SRP 在 C++ 开发中的广泛应用。
4.1 场景 1:函数级别的 SRP—— 拆分超长处理函数

在 C++ 开发中,超长函数是违反 SRP 的重灾区,比如一个process_data()函数写了 500 行,包含读取文件、解析数据、过滤数据、计算结果、保存结果 5 个操作。
反例代码(违反 SRP)
// 违反SRP:一个函数做5件事
bool processData(const std::string& inputPath, const std::string& outputPath) {
// 1. 读取文件
std::ifstream inFile(inputPath);
if (!inFile.is_open()) {
std::cerr << "文件打开失败:" << inputPath << std::endl;
return false;
}
std::string content((std::istreambuf_iterator<char>(inFile)), std::istreambuf_iterator<char>());
inFile.close();
// 2. 解析数据(JSON格式)
std::vector<DataItem> dataItems;
Json::Value root;
Json::Reader reader;
if (!reader.parse(content, root)) {
std::cerr << "JSON解析失败" << std::endl;
return false;
}
for (auto& item : root) {
DataItem data;
data.id = item["id"].asString();
data.value = item["value"].asDouble();
dataItems.push_back(data);
}
// 3. 过滤数据(保留value>100的项)
std::vector<DataItem> filteredItems;
for (auto& item : dataItems) {
if (item.value > 100) {
filteredItems.push_back(item);
}
}
// 4. 计算结果(求和)
double sum = 0;
for (auto& item : filteredItems) {
sum += item.value;
}
// 5. 保存结果
std::ofstream outFile(outputPath);
if (!outFile.is_open()) {
std::cerr << "文件打开失败:" << outputPath << std::endl;
return false;
}
outFile << "过滤后数据量:" << filteredItems.size() << std::endl;
outFile << "总和:" << sum << std::endl;
outFile.close();
return true;
}
重构正例(遵循 SRP)
将每个操作拆分为独立的函数,每个函数只做一件事:
// 数据结构
struct DataItem {
std::string id;
double value;
};
// 职责1:读取文件内容
std::string readFile(const std::string& filePath) {
std::ifstream inFile(filePath);
if (!inFile.is_open()) {
std::cerr << "文件打开失败:" << filePath << std::endl;
return "";
}
std::string content((std::istreambuf_iterator<char>(inFile)), std::istreambuf_iterator<char>());
inFile.close();
return content;
}
// 职责2:解析JSON数据
std::vector<DataItem> parseJson(const std::string& jsonStr) {
std::vector<DataItem> dataItems;
Json::Value root;
Json::Reader reader;
if (!reader.parse(jsonStr, root)) {
std::cerr << "JSON解析失败" << std::endl;
return dataItems;
}
for (auto& item : root) {
DataItem data;
data.id = item["id"].asString();
data.value = item["value"].asDouble();
dataItems.push_back(data);
}
return dataItems;
}
// 职责3:过滤数据
std::vector<DataItem> filterData(const std::vector<DataItem>& dataItems, double threshold) {
std::vector<DataItem> filteredItems;
for (auto& item : dataItems) {
if (item.value > threshold) {
filteredItems.push_back(item);
}
}
return filteredItems;
}
// 职责4:计算总和
double calculateSum(const std::vector<DataItem>& dataItems) {
double sum = 0;
for (auto& item : dataItems) {
sum += item.value;
}
return sum;
}
// 职责5:保存结果到文件
bool saveResult(const std::string& filePath, const std::vector<DataItem>& dataItems, double sum) {
std::ofstream outFile(filePath);
if (!outFile.is_open()) {
std::cerr << "文件打开失败:" << filePath << std::endl;
return false;
}
outFile << "过滤后数据量:" << dataItems.size() << std::endl;
outFile << "总和:" << sum << std::endl;
outFile.close();
return true;
}
// 主函数:组合各个功能(协调者角色,不做具体工作)
bool processData(const std::string& inputPath, const std::string& outputPath) {
// 1. 读取文件
std::string jsonStr = readFile(inputPath);
if (jsonStr.empty()) {
return false;
}
// 2. 解析JSON
std::vector<DataItem> dataItems = parseJson(jsonStr);
if (dataItems.empty()) {
std::cerr << "解析后无数据" << std::endl;
return false;
}
// 3. 过滤数据
std::vector<DataItem> filteredItems = filterData(dataItems, 100.0);
if (filteredItems.empty()) {
std::cerr << "过滤后无数据" << std::endl;
return false;
}
// 4. 计算总和
double sum = calculateSum(filteredItems);
// 5. 保存结果
return saveResult(outputPath, filteredItems, sum);
}
重构后的函数职责清晰,修改任何一个步骤(比如修改过滤规则、更换数据格式)都只需改动对应的函数,而且每个函数都可以单独测试和复用。
4.2 场景 2:模块级别的 SRP—— 拆分臃肿的网络模块

在 C++ 项目中,网络模块经常被设计成 “万能模块”,既处理 TCP 连接、数据收发,又负责协议解析、数据序列化、错误处理,导致模块臃肿难以维护。
重构思路(遵循 SRP)
将网络模块拆分为 4 个独立的模块,每个模块只负责一个层面的功能:
- TCP 模块(TcpClient/TcpServer):只负责 TCP 连接的建立、断开、数据收发,不关心数据内容;
- 协议解析模块(ProtocolParser):只负责将二进制数据解析为业务对象,或将业务对象序列化为二进制数据;
- 序列化模块(Serializer):只负责数据的序列化(比如 JSON、Protobuf)和反序列化;
- 错误处理模块(ErrorHandler):只负责网络错误的统一处理(比如重连、日志记录、告警)。
核心代码示例
// 1. TCP模块:只负责TCP连接和数据收发
class TcpClient {
public:
bool connect(const std::string& host, unsigned int port);
bool disconnect();
ssize_t sendData(const std::vector<char>& data);
ssize_t recvData(std::vector<char>& data, size_t bufferSize);
};
// 2. 序列化模块:只负责Protobuf序列化
class ProtobufSerializer {
public:
template <typename T>
std::vector<char> serialize(const T& msg) {
std::vector<char> data(msg.ByteSizeLong());
msg.SerializeToArray(data.data(), data.size());
return data;
}
template <typename T>
bool deserialize(const std::vector<char>& data, T& msg) {
return msg.ParseFromArray(data.data(), data.size());
}
};
// 3. 协议解析模块:只负责协议头解析和数据分离
class ProtocolParser {
public:
// 协议格式:[4字节长度][4字节命令号][数据内容]
bool parseHeader(const std::vector<char>& data, uint32_t& length, uint32_t& cmd);
std::vector<char> getBody(const std::vector<char>& data);
};
// 4. 错误处理模块:只负责错误处理
class NetworkErrorHandler {
public:
void handleConnectError(const std::string& host, unsigned int port);
void handleSendError(ssize_t sendLen, size_t dataLen);
void handleRecvError(ssize_t recvLen);
};
// 业务模块:组合各个网络相关模块
class BusinessClient {
public:
BusinessClient()
: tcpClient_(), serializer_(), parser_(), errorHandler_() {}
bool sendBusinessMsg(const BusinessMsg& msg) {
// 1. 序列化业务数据
std::vector<char> bodyData = serializer_.serialize(msg);
// 2. 构造协议包(添加头信息)
std::vector<char> pkgData = buildPkg(msg.cmd(), bodyData);
// 3. 发送数据(调用TCP模块)
ssize_t sendLen = tcpClient_.sendData(pkgData);
if (sendLen != pkgData.size()) {
errorHandler_.handleSendError(sendLen, pkgData.size());
return false;
}
return true;
}
private:
TcpClient tcpClient_;
ProtobufSerializer serializer_;
ProtocolParser parser_;
NetworkErrorHandler errorHandler_;
// 构造协议包
std::vector<char> buildPkg(uint32_t cmd, const std::vector<char>& bodyData) {
std::vector<char> pkgData;
uint32_t length = bodyData.size() + 4; // 长度=命令号4字节+数据长度
pkgData.insert(pkgData.end(), reinterpret_cast<char*>(&length), reinterpret_cast<char*>(&length) + 4);
pkgData.insert(pkgData.end(), reinterpret_cast<char*>(&cmd), reinterpret_cast<char*>(&cmd) + 4);
pkgData.insert(pkgData.end(), bodyData.begin(), bodyData.end());
return pkgData;
}
};
4.3 场景 3:项目结构级别的 SRP—— 划分目录结构

在大型 C++ 项目中,目录结构的设计也需要遵循单一职责原则,每个目录只存放一个功能模块的代码,避免不同模块的代码混杂在一起。
遵循 SRP 的项目目录结构示例
project/
├── src/
│ ├── base/ # 基础模块(工具类、常量定义,只负责基础功能)
│ │ ├── logger/ # 日志模块(只负责日志)
│ │ ├── config/ # 配置模块(只负责配置读取)
│ │ └── utils/ # 工具函数(只负责通用工具)
│ ├── network/ # 网络模块(只负责网络通信)
│ │ ├── tcp/ # TCP模块
│ │ ├── proto/ # 协议和序列化模块
│ │ └── error/ # 网络错误处理模块
│ ├── data/ # 数据模块(只负责数据存储和访问)
│ │ ├── mysql/ # MySQL访问模块
│ │ ├── redis/ # Redis访问模块
│ │ └── model/ # 数据模型定义
│ ├── business/ # 业务模块(只负责业务逻辑)
│ │ ├── order/ # 订单业务
│ │ ├── user/ # 用户业务
│ │ └── product/ # 商品业务
│ └── main/ # 入口模块(只负责程序启动和模块组装)
├── include/ # 头文件(与src目录结构对应)
├── test/ # 测试模块(只负责测试)
│ ├── unit/ # 单元测试
│ └── integration/ # 集成测试
└── build/ # 构建产物
这种目录结构的优势在于:
- 模块边界清晰,新开发者能快速找到对应功能的代码;
- 多人协作时,不同开发者负责不同目录,减少代码冲突;
- 后续扩展时,只需新增目录(比如新增
payment/支付模块),不影响现有结构。
五、实战避坑指南:C++ 开发者容易踩的 5 个 SRP 误区

单一职责原则看似简单,但在实际应用中很容易走向极端,要么 “过度拆分”,要么 “拆分不足”。下面列出 5 个常见误区,帮助你正确应用 SRP。
误区 1:认为 “一个类只能有一个方法”
很多新手把 SRP 理解为 “一个类只能有一个方法”,这是完全错误的。一个类可以有多个方法,只要这些方法都围绕同一个核心职责,并且变化原因一致。
比如FileLogger类有info()“warn()“error()三个方法,它们的变化原因都是 “日志格式修改”,这完全符合 SRP;而如果一个类有log()和saveOrder()两个方法,变化原因完全不同,才违反 SRP。
误区 2:过度拆分,导致代码碎片化
比如把 “订单参数校验” 拆分为UserIdValidator“ProductIdValidator“QuantityValidator三个类,每个类只有一个校验方法,这就是过度拆分。
过度拆分的后果是:
- 代码结构复杂,需要创建大量小类,增加维护成本;
- 调用时需要组合多个类,降低代码可读性;
- 编译时间变长,因为需要编译更多的文件。
判断标准:如果拆分后的类之间必须紧密配合才能完成一个简单功能,且这些类的变化原因一致,就不需要拆分。
误区 3:忽略 “职责的粒度”,拆分不足或过度
SRP 的 “职责” 粒度没有绝对标准,需要根据项目规模和团队协作方式灵活调整:
- 小型项目(单人开发):职责粒度可以粗一些,比如把日志和配置放在同一个模块,减少代码复杂度;
- 大型项目(多人协作):职责粒度需要细一些,比如把日志模块拆分为 “日志接口”“控制台日志实现”“文件日志实现”,方便多人并行开发和维护。
误区 4:把 “组合” 当 “拆分”,依然存在隐式耦合
比如把OrderHandler类的日志功能拆分为LogHelper类,但OrderHandler直接在内部创建LogHelper实例,并且LogHelper依赖OrderHandler的私有成员变量,这依然是耦合的。
正确的做法是:
- 拆分后的模块通过接口交互,不依赖对方的内部实现;
- 通过依赖注入传入模块实例,而不是在内部创建;
- 模块之间只传递必要的公开数据,不访问对方的私有成员。
误区 5:在性能敏感场景过度追求 SRP
在 C++ 开发中,性能是重要考量因素。如果某个功能是性能热点(比如高频调用的函数),过度拆分可能会增加函数调用开销或内存开销。
比如在游戏开发中,帧循环内的渲染逻辑,如果拆分为太多小函数,可能会因为函数调用开销影响帧率。这时可以适当合并职责,优先保证性能,再考虑可维护性。
原则:在性能敏感场景,可适当放宽 SRP,在性能和可维护性之间寻找平衡;在非性能敏感场景,优先遵循 SRP。
六、总结:单一职责原则的核心要点与实践建议

6.1 核心要点提炼
- 核心定义:一个软件实体(类、模块、函数)只有一个引起它变化的原因;
- 判断标准:不是 “有多少个方法”,而是 “有多少个独立的变化原因”;
- 核心价值:降低耦合、提高可读性、简化维护、增强复用性;
- 应用范围:类、模块、函数、目录结构,甚至项目架构。
6.2 C++ 实战建议
- 新手入门:从拆分 “万能类” 和 “超长函数” 开始,比如把自己项目中超过 500 行的类拆分为多个职责单一的类,超过 100 行的函数拆分为多个小函数;
- 团队协作:按职责分配模块,比如 A 负责日志模块,B 负责数据库模块,C 负责业务模块,避免多人同时修改同一个文件;
- 依赖注入:C++ 中使用智能指针(
std::shared_ptr)实现依赖注入,让模块之间通过接口交互,降低耦合; - 接口抽象:对于可能替换实现的模块(比如日志、数据库),先定义抽象接口(纯虚类),再实现具体类,便于替换和测试;
- 灵活变通:SRP 是 “指南” 而非 “铁律”,在性能敏感场景或小型项目中,可适当放宽,避免过度设计。
6.3 最后一句话
单一职责原则的本质,是 “边界思维”—— 在开发中始终思考 “这个类 / 模块 / 函数的职责边界是什么”,通过清晰的边界划分,让代码从 “混乱臃肿” 变得 “清爽有序”。
坚持使用 SRP,你会发现:修改需求不再是噩梦,接手老项目不再头疼,团队协作不再频繁冲突,代码质量和开发效率都会得到质的提升。


















 168万+
168万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









