




目录
引言:为什么 Lambda 是 Python 开发者的 "精简利器"?
3.5 Lambda 与functools.reduce结合:归约计算
5.8 错误 8:Lambda 与sort函数的 key 参数误用
5.10 错误 10:过度使用 Lambda 导致代码可读性下降

class 卑微码农:
def __init__(self):
self.技能 = ['能读懂十年前祖传代码', '擅长用Ctrl+C/V搭建世界', '信奉"能跑就别动"的玄学']
self.发量 = 100 # 初始发量
self.咖啡因耐受度 = '极限'
def 修Bug(self, bug):
try:
# 试图用玄学解决问题
if bug.严重程度 == '离谱':
print("这一定是环境问题!")
else:
print("让我看看是谁又没写注释...哦,是我自己。")
except Exception as e:
# 如果try块都救不了,那就...
print("重启一下试试?")
self.发量 -= 1 # 每解决一个bug,头发-1
# 实例化一个我
我 = 卑微码农()引言:为什么 Lambda 是 Python 开发者的 "精简利器"?
在 Python 编程中,你是否经常遇到这样的场景:
- 想写一个简单的计算逻辑(比如两数相加、取绝对值),却觉得定义完整函数太繁琐;
- 使用
map、filter等高阶函数时,需要一个临时的小函数作为参数,不想单独定义; - 开发 GUI 或多线程程序时,需要简短的回调函数,希望代码更紧凑。

这时候,Lambda 表达式就能发挥巨大作用!它作为 Python 中的 "匿名函数",以简洁高效、即用即弃的特点,成为处理简单逻辑的 "精简利器"。一行代码就能定义一个函数,无需繁琐的def关键字和函数名,让代码更简洁、更易读。
Lambda 的应用远不止这些:数据处理、函数式编程、回调函数、参数传递等场景都能看到它的身影。无论是处理列表数据,还是编写简洁的业务逻辑,Lambda 都能帮你提升开发效率,让代码更优雅。
本文将从 "零基础理解" 到 "高级实战",用通俗的语言 + 可运行的示例,系统拆解 Python Lambda 表达式的核心原理与应用技巧。全程无晦涩概念堆砌,让你从 "会用" 到 "吃透",真正掌握这个 Python 开发者必备的高效工具。
一、基础铺垫:Lambda 表达式的 "前世今生"

在学习 Lambda 之前,我们先回顾 Python 函数的基本概念,理解 Lambda 作为 "匿名函数" 的定位和价值。
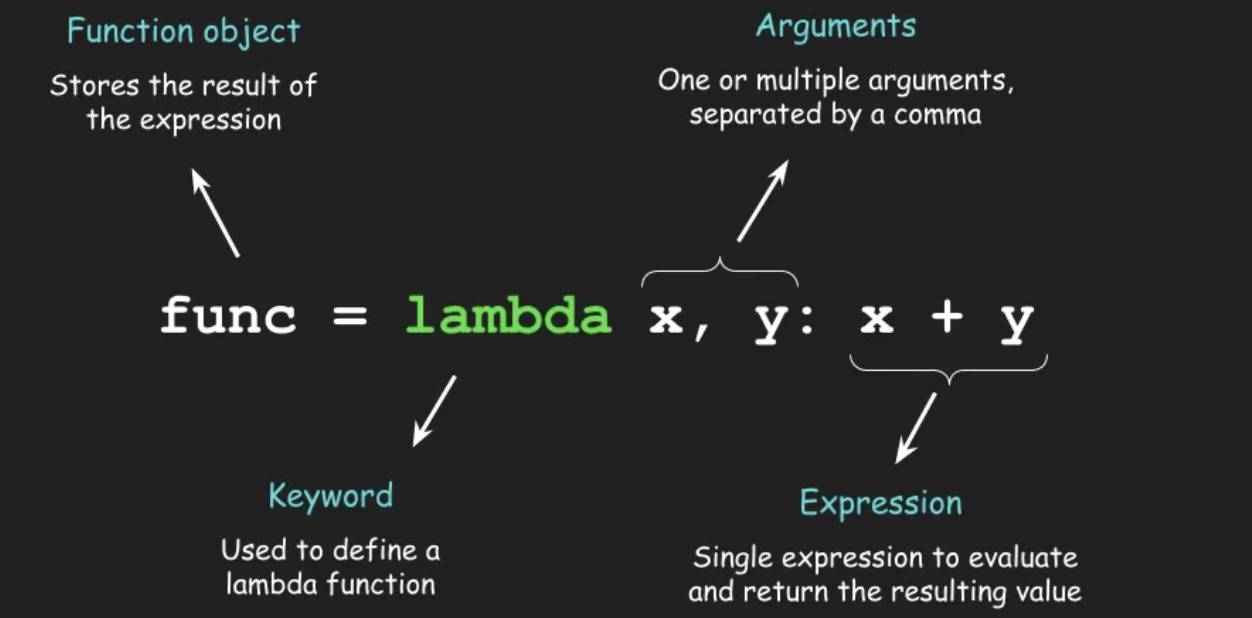
1.1 什么是 Lambda 表达式?
Lambda 表达式,又称 "匿名函数",是 Python 中定义简单函数的一种便捷方式。它不需要使用def关键字定义,也不需要指定函数名,通常用于实现逻辑简单、仅需一行代码的函数。
示例:Lambda 与普通函数的对比
# 普通函数:计算两数之和
def add(a, b):
return a + b
# Lambda表达式:同样实现两数之和(匿名函数)
lambda_add = lambda a, b: a + b
# 调用方式完全一致
print(add(10, 20)) # 输出:30
print(lambda_add(10, 20)) # 输出:30
可以看到,Lambda 表达式用一行代码实现了与普通函数相同的功能,且调用方式完全一致。
1.2 Lambda 表达式的语法规则
Lambda 表达式的语法格式非常简洁,核心结构如下:
lambda [参数1[, 参数2, ..., 参数n]]: 表达式
语法解析:
lambda:关键字,标记这是一个 Lambda 表达式;[参数1[, 参数2, ..., 参数n]]:可选参数,与普通函数的参数规则一致,支持位置参数、默认参数,但不支持可变参数(*args、**kwargs)和关键字参数;::分隔符,用于分隔参数列表和表达式;表达式:必须是单行代码,执行后的值作为 Lambda 函数的返回值,无需使用return关键字。
合法与非法 Lambda 示例
# 合法示例
lambda x: x * 2 # 单个参数,返回x的2倍
lambda x, y: x + y # 两个参数,返回求和结果
lambda x, y=10: x + y # 带默认参数,y默认值为10
# 非法示例
lambda x, y: x + y; x - y # 错误:表达式只能有一个
lambda x, *args: sum(x, *args) # 错误:不支持可变参数
lambda x: if x > 0: x else -x # 错误:表达式不能是复杂语句(需用三元运算符)
1.3 Lambda 的核心特点
Lambda 表达式与普通函数相比,有以下核心特点:
- 匿名性:没有函数名,通常赋值给变量使用,或作为参数传递给其他函数;
- 简洁性:仅能包含一个表达式,代码行数限制为一行;
- 即时性:适合临时使用的简单逻辑,无需单独定义函数;
- 返回值:表达式的结果即为返回值,无需显式使用
return。
示例:Lambda 的匿名性与即时性
# 直接调用Lambda(匿名使用,仅执行一次)
print((lambda x, y: x * y)(3, 4)) # 输出:12
# 赋值给变量后重复使用
multiply = lambda x, y: x * y
print(multiply(5, 6)) # 输出:30
print(multiply(7, 8)) # 输出:56
二、Lambda 基础用法:一行代码解决简单问题
Lambda 表达式的核心价值在于 "简洁",适合处理逻辑简单的场景。本节将介绍 Lambda 的基础用法,帮助你快速上手。
2.1 简单计算场景
Lambda 最适合实现简单的计算逻辑,比如加减乘除、取余、幂运算等。
示例:Lambda 实现常见计算
# 加法
add = lambda x, y: x + y
print(add(2, 3)) # 输出:5
# 减法
subtract = lambda x, y: x - y
print(subtract(10, 4)) # 输出:6
# 乘法
multiply = lambda x, y: x * y
print(multiply(5, 6)) # 输出:30
# 除法(保留两位小数)
divide = lambda x, y: round(x / y, 2) if y != 0 else 0
print(divide(10, 3)) # 输出:3.33
print(divide(10, 0)) # 输出:0
# 幂运算
power = lambda x, y: x ** y
print(power(2, 3)) # 输出:8
# 取绝对值
abs_val = lambda x: x if x >= 0 else -x
print(abs_val(-5)) # 输出:5
print(abs_val(3)) # 输出:3
2.2 作为参数传递给高阶函数
这是 Lambda 最常用的场景!Python 中的高阶函数(如map、filter、sorted)需要接收函数作为参数,Lambda 作为匿名函数,非常适合作为这些函数的参数。
2.2.1 与map函数结合:批量处理数据
map(function, iterable):将函数应用于可迭代对象的每个元素,返回新的可迭代对象。
示例:用 Lambda+map 批量处理列表
# 示例1:将列表中所有元素乘以2
nums = [1, 2, 3, 4, 5]
result = list(map(lambda x: x * 2, nums))
print(result) # 输出:[2, 4, 6, 8, 10]
# 示例2:将两个列表对应元素相加
list1 = [1, 2, 3]
list2 = [4, 5, 6]
result = list(map(lambda x, y: x + y, list1, list2))
print(result) # 输出:[5, 7, 9]
# 示例3:将字符串列表转换为大写
str_list = ["hello", "world", "python"]
result = list(map(lambda s: s.upper(), str_list))
print(result) # 输出:['HELLO', 'WORLD', 'PYTHON']
2.2.2 与filter函数结合:筛选数据
filter(function, iterable):根据函数返回值的布尔值,筛选可迭代对象中的元素,返回符合条件的元素组成的可迭代对象。
示例:用 Lambda+filter 筛选数据
# 示例1:筛选列表中的偶数
nums = [1, 2, 3, 4, 5, 6, 7, 8]
even_nums = list(filter(lambda x: x % 2 == 0, nums))
print(even_nums) # 输出:[2, 4, 6, 8]
# 示例2:筛选列表中的奇数
odd_nums = list(filter(lambda x: x % 2 != 0, nums))
print(odd_nums) # 输出:[1, 3, 5, 7]
# 示例3:筛选字符串列表中长度大于3的元素
str_list = ["a", "ab", "abc", "abcd", "abcde"]
long_strs = list(filter(lambda s: len(s) > 3, str_list))
print(long_strs) # 输出:['abcd', 'abcde']
# 示例4:筛选字典列表中满足条件的元素
users = [
{"name": "张三", "age": 20},
{"name": "李四", "age": 30},
{"name": "王五", "age": 25}
]
# 筛选年龄大于25的用户
adult_users = list(filter(lambda u: u["age"] > 25, users))
print(adult_users) # 输出:[{'name': '李四', 'age': 30}]
2.2.3 与sorted函数结合:自定义排序
sorted(iterable, key=None, reverse=False):对可迭代对象进行排序,key参数接收一个函数,用于指定排序的依据。
示例:用 Lambda+sorted 自定义排序
# 示例1:对列表按元素的绝对值排序
nums = [-5, 3, -2, 8, -1]
sorted_nums = sorted(nums, key=lambda x: abs(x))
print(sorted_nums) # 输出:[-1, -2, 3, -5, 8]
# 示例2:对字符串列表按长度排序
str_list = ["apple", "banana", "cherry", "date"]
sorted_strs = sorted(str_list, key=lambda s: len(s))
print(sorted_strs) # 输出:['date', 'apple', 'banana', 'cherry']
# 示例3:对字典列表按指定字段排序
users = [
{"name": "张三", "age": 20},
{"name": "李四", "age": 30},
{"name": "王五", "age": 25}
]
# 按年龄升序排序
sorted_by_age = sorted(users, key=lambda u: u["age"])
print(sorted_by_age) # 输出:[{'name': '张三', 'age': 20}, {'name': '王五', 'age': 25}, {'name': '李四', 'age': 30}]
# 按年龄降序排序
sorted_by_age_desc = sorted(users, key=lambda u: u["age"], reverse=True)
print(sorted_by_age_desc) # 输出:[{'name': '李四', 'age': 30}, {'name': '王五', 'age': 25}, {'name': '张三', 'age': 20}]
# 示例4:对元组列表按第二个元素排序
tuples = [(1, 3), (4, 1), (2, 5), (3, 2)]
sorted_tuples = sorted(tuples, key=lambda t: t[1])
print(sorted_tuples) # 输出:[(4, 1), (3, 2), (1, 3), (2, 5)]
2.3 作为函数的返回值
Lambda 表达式可以作为其他函数的返回值,实现 "动态生成函数" 的效果。
示例:Lambda 作为函数返回值
# 示例1:生成不同的计算函数
def create_calculator(operator):
if operator == "+":
return lambda x, y: x + y
elif operator == "-":
return lambda x, y: x - y
elif operator == "*":
return lambda x, y: x * y
elif operator == "/":
return lambda x, y: x / y if y != 0 else 0
# 生成加法函数
add = create_calculator("+")
print(add(2, 3)) # 输出:5
# 生成乘法函数
multiply = create_calculator("*")
print(multiply(4, 5)) # 输出:20
# 示例2:生成带系数的线性函数(y = kx + b)
def create_linear_func(k, b):
return lambda x: k * x + b
# 生成y = 2x + 3
func1 = create_linear_func(2, 3)
print(func1(1)) # 输出:5
print(func1(2)) # 输出:7
# 生成y = -x + 5
func2 = create_linear_func(-1, 5)
print(func2(3)) # 输出:2
print(func2(5)) # 输出:0
三、Lambda 进阶用法:处理复杂场景
基础用法只能发挥 Lambda 的部分价值,结合 Python 的其他特性,Lambda 可以处理更复杂的场景。本节将介绍 Lambda 的进阶用法,提升你的代码效率。
3.1 Lambda 与三元运算符结合:实现简单分支逻辑
Lambda 表达式仅支持单个表达式,无法直接使用if-else语句,但可以通过三元运算符实现简单的分支逻辑。
示例:Lambda + 三元运算符实现分支逻辑
# 示例1:判断数值正负
judge_sign = lambda x: "正数" if x > 0 else ("负数" if x < 0 else "零")
print(judge_sign(5)) # 输出:正数
print(judge_sign(-3)) # 输出:负数
print(judge_sign(0)) # 输出:零
# 示例2:求两个数中的较大值
max_val = lambda x, y: x if x > y else y
print(max_val(10, 20)) # 输出:20
print(max_val(15, 5)) # 输出:15
# 示例3:根据分数评级
grade = lambda score: "优秀" if score >= 90 else ("良好" if score >= 80 else ("及格" if score >= 60 else "不及格"))
print(grade(95)) # 输出:优秀
print(grade(85)) # 输出:良好
print(grade(70)) # 输出:及格
print(grade(50)) # 输出:不及格
# 示例4:处理空值
process_null = lambda val, default: val if val is not None else default
print(process_null("hello", "world")) # 输出:hello
print(process_null(None, "world")) # 输出:world
3.2 Lambda 与列表推导式 / 字典推导式结合
将 Lambda 表达式与推导式结合,可以快速实现复杂的数据处理逻辑。
示例:Lambda + 推导式处理数据
# 示例1:生成一个包含Lambda函数的列表,实现不同的计算
funcs = [
lambda x: x + 10,
lambda x: x * 10,
lambda x: x ** 2
]
# 对数字5应用所有函数
num = 5
results = [func(num) for func in funcs]
print(results) # 输出:[15, 50, 25]
# 示例2:生成一个字典,key为运算符,value为对应的Lambda计算函数
calc_funcs = {
"add": lambda x, y: x + y,
"subtract": lambda x, y: x - y,
"multiply": lambda x, y: x * y,
"divide": lambda x, y: x / y if y != 0 else 0
}
# 使用字典中的函数进行计算
print(calc_funcs["add"](2, 3)) # 输出:5
print(calc_funcs["multiply"](4, 5)) # 输出:20
print(calc_funcs["divide"](10, 2)) # 输出:5.0
# 示例3:用Lambda+列表推导式批量处理嵌套列表
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 计算每个子列表的和
sum_list = [sum(map(lambda x: x, sublist)) for sublist in nested_list]
print(sum_list) # 输出:[6, 15, 24]
# 示例4:用Lambda+字典推导式筛选并转换字典
original_dict = {"a": 1, "b": 2, "c": 3, "d": 4}
# 筛选值为偶数的键值对,并将值翻倍
new_dict = {k: v * 2 for k, v in original_dict.items() if (lambda x: x % 2 == 0)(v)}
print(new_dict) # 输出:{'b': 4, 'd': 8}
3.3 Lambda 在闭包中的应用
闭包是指嵌套函数引用了外层函数的变量,且外层函数返回内层函数。Lambda 作为匿名函数,可以作为闭包的内层函数,简化代码。
示例:Lambda 实现闭包
# 示例1:计数器闭包
def create_counter():
count = 0 # 外层函数变量
# Lambda作为内层函数,引用count变量
return lambda: nonlocal count; count += 1; count
# 创建计数器
counter = create_counter()
print(counter()) # 输出:1
print(counter()) # 输出:2
print(counter()) # 输出:3
# 示例2:带初始值的计数器
def create_counter_with_init(init_val):
count = init_val
return lambda: nonlocal count; count += 1; count
counter2 = create_counter_with_init(10)
print(counter2()) # 输出:11
print(counter2()) # 输出:12
# 示例3:温度转换器闭包(摄氏度↔华氏度)
def create_temp_converter(from_unit, to_unit):
if from_unit == "c" and to_unit == "f":
# 摄氏度转华氏度:F = C * 9/5 + 32
return lambda c: c * 9/5 + 32
elif from_unit == "f" and to_unit == "c":
# 华氏度转摄氏度:C = (F - 32) * 5/9
return lambda f: (f - 32) * 5/9
else:
return lambda x: x # 不转换
# 创建摄氏度转华氏度的转换器
c_to_f = create_temp_converter("c", "f")
print(c_to_f(0)) # 输出:32.0
print(c_to_f(100)) # 输出:212.0
# 创建华氏度转摄氏度的转换器
f_to_c = create_temp_converter("f", "c")
print(f_to_c(32)) # 输出:0.0
print(f_to_c(212)) # 输出:100.0
3.4 Lambda 在回调函数中的应用
回调函数是指作为参数传递给另一个函数,在特定事件发生时被调用的函数。Lambda 作为简洁的匿名函数,非常适合作为回调函数。
示例:Lambda 作为回调函数
# 示例1:模拟异步任务回调
def async_task(task_name, callback):
print(f"执行任务:{task_name}")
# 模拟任务执行耗时
import time
time.sleep(1)
# 任务完成后调用回调函数
callback(f"{task_name}执行完成")
# 使用Lambda作为回调函数
async_task("下载文件", lambda msg: print(f"回调通知:{msg}"))
async_task("处理数据", lambda msg: print(f"回调通知:{msg}"))
# 示例2:GUI编程中的按钮点击回调(模拟)
class MockButton:
def __init__(self, text):
self.text = text
self.on_click = None # 回调函数
def click(self):
# 模拟按钮被点击,调用回调函数
if self.on_click:
self.on_click(self.text)
# 创建按钮,用Lambda作为点击回调
btn1 = MockButton("确定")
btn1.on_click = lambda text: print(f"点击了【{text}】按钮")
btn2 = MockButton("取消")
btn2.on_click = lambda text: print(f"点击了【{text}】按钮")
# 模拟点击按钮
btn1.click() # 输出:点击了【确定】按钮
btn2.click() # 输出:点击了【取消】按钮
# 示例3:排序回调(自定义复杂排序规则)
data = [
{"name": "张三", "score": 85, "age": 20},
{"name": "李四", "score": 90, "age": 18},
{"name": "王五", "score": 85, "age": 22}
]
# 先按分数降序排序,分数相同按年龄升序排序
sorted_data = sorted(
data,
key=lambda x: (-x["score"], x["age"]) # 元组作为key,先按第一个元素排序,再按第二个
)
print(sorted_data)
# 输出:
# [{'name': '李四', 'score': 90, 'age': 18}, {'name': '张三', 'score': 85, 'age': 20}, {'name': '王五', 'score': 85, 'age': 22}]
3.5 Lambda 与functools.reduce结合:归约计算
functools.reduce(function, iterable[, initializer]):对可迭代对象中的元素进行归约计算,将前两个元素的计算结果与第三个元素继续计算,直到得到最终结果。
示例:Lambda+reduce 实现归约计算
from functools import reduce
# 示例1:计算列表中所有元素的和
nums = [1, 2, 3, 4, 5]
sum_result = reduce(lambda x, y: x + y, nums)
print(sum_result) # 输出:15
# 示例2:计算列表中所有元素的乘积
product_result = reduce(lambda x, y: x * y, nums)
print(product_result) # 输出:120
# 示例3:找出列表中的最大值
max_result = reduce(lambda x, y: x if x > y else y, nums)
print(max_result) # 输出:5
# 示例4:拼接列表中的字符串
str_list = ["Hello", " ", "Python", " ", "World"]
join_result = reduce(lambda x, y: x + y, str_list)
print(join_result) # 输出:Hello Python World
# 示例5:带初始值的归约计算
# 计算10 + 1+2+3+4+5
sum_with_init = reduce(lambda x, y: x + y, nums, 10)
print(sum_with_init) # 输出:25
# 示例6:统计列表中元素出现的次数(归约字典)
from collections import defaultdict
data = ["a", "b", "a", "c", "b", "a"]
count_dict = reduce(
lambda d, x: (d[x] += 1) or d, # 先更新字典,再返回字典(利用or短路特性)
data,
defaultdict(int)
)
print(dict(count_dict)) # 输出:{'a': 3, 'b': 2, 'c': 1}
四、实战场景:Lambda 的 10 个经典应用案例

Lambda 的价值在于解决实际问题。本节将结合企业开发中的高频场景,提供 10 个可直接复用的 Lambda 实战案例。
4.1 场景 1:数据清洗与转换
在数据处理中,经常需要对原始数据进行清洗和转换,Lambda 结合map、filter可以快速实现。
示例:数据清洗与转换
# 原始数据(包含脏数据)
raw_data = [
{"name": "张三", "age": 20, "score": 85},
{"name": "李四", "age": None, "score": 90}, # age为空
{"name": "王五", "age": 25, "score": -10}, # score异常
{"name": "赵六", "age": 30, "score": 95},
{"name": "", "age": 22, "score": 70} # name为空
]
# 步骤1:清洗数据(过滤无效数据)
cleaned_data = list(filter(
lambda x: x["name"] != "" and x["age"] is not None and x["score"] >= 0,
raw_data
))
print("清洗后的数据:")
print(cleaned_data)
# 输出:
# [{'name': '张三', 'age': 20, 'score': 85}, {'name': '赵六', 'age': 30, 'score': 95}, {'name': '钱七', 'age': 22, 'score': 70}]
# 步骤2:转换数据(标准化score为百分制,添加等级字段)
transformed_data = list(map(
lambda x: {
"name": x["name"],
"age": x["age"],
"score": x["score"],
"grade": "优秀" if x["score"] >= 90 else ("良好" if x["score"] >= 80 else "及格")
},
cleaned_data
))
print("转换后的数据:")
print(transformed_data)
# 输出:
# [{'name': '张三', 'age': 20, 'score': 85, 'grade': '良好'}, {'name': '赵六', 'age': 30, 'score': 95, 'grade': '优秀'}, {'name': '钱七', 'age': 22, 'score': 70, 'grade': '及格'}]
4.2 场景 2:列表数据的复杂排序
实际开发中,经常需要对列表(尤其是字典列表)进行复杂排序,Lambda 可以灵活定义排序规则。
示例:复杂列表排序
# 员工数据
employees = [
{"name": "张三", "department": "技术部", "salary": 8000, "hire_date": "2020-01-15"},
{"name": "李四", "department": "市场部", "salary": 6000, "hire_date": "2021-03-20"},
{"name": "王五", "department": "技术部", "salary": 10000, "hire_date": "2019-05-10"},
{"name": "赵六", "department": "财务部", "salary": 7000, "hire_date": "2022-07-01"},
{"name": "钱七", "department": "技术部", "salary": 9000, "hire_date": "2020-09-30"}
]
# 需求1:按部门升序排序,同部门按薪资降序排序
sorted_by_dept_salary = sorted(
employees,
key=lambda x: (x["department"], -x["salary"])
)
print("按部门和薪资排序:")
for emp in sorted_by_dept_salary:
print(f"{emp['department']} - {emp['name']} - {emp['salary']}")
# 需求2:按入职日期降序排序(字符串日期转换为可排序格式)
from datetime import datetime
sorted_by_hire_date = sorted(
employees,
key=lambda x: datetime.strptime(x["hire_date"], "%Y-%m-%d"),
reverse=True
)
print("\n按入职日期降序排序:")
for emp in sorted_by_hire_date:
print(f"{emp['name']} - {emp['hire_date']}")
4.3 场景 3:快速实现简单的函数逻辑
在编写代码时,经常需要临时使用简单的函数逻辑,Lambda 可以避免定义冗余的普通函数。
示例:临时函数逻辑实现
# 场景:处理用户输入的查询参数,对不同类型的参数进行转换
def process_query_params(params):
# 定义参数转换规则:key为参数名,value为转换函数(Lambda)
convert_rules = {
"page": lambda x: int(x) if x.isdigit() else 1, # 页码转换为整数,默认1
"size": lambda x: int(x) if x.isdigit() and int(x) <= 100 else 10, # 每页数量,最大100,默认10
"keyword": lambda x: x.strip() if isinstance(x, str) else "", # 关键字去除空格
"price_min": lambda x: float(x) if x.replace(".", "").isdigit() else 0.0, # 最低价格转换为浮点数
"price_max": lambda x: float(x) if x.replace(".", "").isdigit() else float("inf") # 最高价格,默认无穷大
}
# 应用转换规则
processed = {}
for key, value in params.items():
if key in convert_rules:
processed[key] = convert_rules[key](value)
else:
processed[key] = value
return processed
# 测试:模拟用户输入的参数
raw_params = {
"page": "3",
"size": "200", # 超过100,转换为10
"keyword": " Python教程 ",
"price_min": "9.9",
"price_max": "99.9",
"sort": "price"
}
processed_params = process_query_params(raw_params)
print("处理后的参数:")
print(processed_params)
# 输出:
# {
# 'page': 3,
# 'size': 10,
# 'keyword': 'Python教程',
# 'price_min': 9.9,
# 'price_max': 99.9,
# 'sort': 'price'
# }
4.4 场景 4:GUI 编程中的简洁回调
在 GUI 编程(如 Tkinter、wxPython)中,按钮点击、菜单选择等事件需要回调函数,Lambda 可以让代码更紧凑。
示例:Tkinter 中使用 Lambda 作为回调
import tkinter as tk
from tkinter import messagebox
# 创建主窗口
root = tk.Tk()
root.title("Lambda回调示例")
root.geometry("300x200")
# 定义变量
num_var = tk.IntVar(value=0)
# 标签显示数值
label = tk.Label(root, textvariable=num_var, font=("Arial", 24))
label.pack(pady=20)
# 按钮框架
btn_frame = tk.Frame(root)
btn_frame.pack()
# 增加按钮(Lambda作为回调,修改num_var的值)
add_btn = tk.Button(btn_frame, text="+1", command=lambda: num_var.set(num_var.get() + 1))
add_btn.grid(row=0, column=0, padx=10)
# 减少按钮
sub_btn = tk.Button(btn_frame, text="-1", command=lambda: num_var.set(num_var.get() - 1))
sub_btn.grid(row=0, column=1, padx=10)
# 重置按钮
reset_btn = tk.Button(btn_frame, text="重置", command=lambda: num_var.set(0))
reset_btn.grid(row=0, column=2, padx=10)
# 提示按钮(Lambda作为回调,传递参数)
tip_btn = tk.Button(root, text="提示", command=lambda: messagebox.showinfo("提示", f"当前数值:{num_var.get()}"))
tip_btn.pack(pady=10)
# 启动主循环
root.mainloop()
4.5 场景 5:多线程 / 多进程中的任务函数
在多线程或多进程编程中,需要将任务逻辑封装为函数传递给线程 / 进程,Lambda 适合实现简单的任务逻辑。
示例:多线程中使用 Lambda 作为任务函数
import threading
import time
# 示例1:简单多线程任务
def run_thread(task_name, task_func):
print(f"线程 {task_name} 启动")
task_func()
print(f"线程 {task_name} 结束")
# 定义两个简单任务(Lambda实现)
task1 = lambda: (print("执行任务1..."), time.sleep(2))
task2 = lambda: (print("执行任务2..."), time.sleep(1))
# 创建线程
thread1 = threading.Thread(target=run_thread, args=("Thread-1", task1))
thread2 = threading.Thread(target=run_thread, args=("Thread-2", task2))
# 启动线程
thread1.start()
thread2.start()
# 等待线程结束
thread1.join()
thread2.join()
print("所有线程执行完成")
# 示例2:带参数的多线程任务
def run_thread_with_args(task_name, task_func, *args, **kwargs):
print(f"线程 {task_name} 启动")
task_func(*args, **kwargs)
print(f"线程 {task_name} 结束")
# 带参数的任务(Lambda实现)
task3 = lambda x, y: print(f"执行任务3:{x} + {y} = {x + y}")
task4 = lambda msg: (print(f"执行任务4:{msg}"), time.sleep(1))
# 创建线程
thread3 = threading.Thread(target=run_thread_with_args, args=("Thread-3", task3, 10, 20))
thread4 = threading.Thread(target=run_thread_with_args, args=("Thread-4", task4, "Hello, Thread!"))
# 启动线程
thread3.start()
thread4.start()
thread3.join()
thread4.join()
print("所有带参数线程执行完成")
4.6 场景 6:函数式编程中的管道模式
函数式编程中的 "管道模式" 是指将多个函数按顺序组合,前一个函数的输出作为后一个函数的输入。Lambda 可以简化管道中函数的定义。
示例:Lambda 实现函数管道
# 定义管道函数:接收多个函数,按顺序执行
def pipe(data, *funcs):
result = data
for func in funcs:
result = func(result)
return result
# 示例1:数据处理管道
# 步骤:1. 生成列表 → 2. 筛选偶数 → 3. 每个元素乘以2 → 4. 求和
data = [1, 2, 3, 4, 5, 6, 7, 8]
result = pipe(
data,
lambda x: filter(lambda y: y % 2 == 0, x), # 筛选偶数
lambda x: map(lambda y: y * 2, x), # 每个元素乘以2
lambda x: sum(x) # 求和
)
print(result) # 输出:(2+4+6+8)*2 = 40
# 示例2:字符串处理管道
# 步骤:1. 原始字符串 → 2. 转换为小写 → 3. 去除空格 → 4. 首字母大写
raw_str = " HELLO PYTHON WORLD "
processed_str = pipe(
raw_str,
lambda s: s.lower(), # 转换为小写
lambda s: s.strip(), # 去除空格
lambda s: s.capitalize() # 首字母大写
)
print(processed_str) # 输出:Hello python world
# 示例3:字典列表处理管道
users = [
{"name": "张三", "age": 20, "score": 85},
{"name": "李四", "age": 30, "score": 90},
{"name": "王五", "age": 25, "score": 80}
]
# 步骤:1. 筛选年龄>20 → 2. 提取姓名和分数 → 3. 按分数降序排序
result = pipe(
users,
lambda x: filter(lambda u: u["age"] > 20, x), # 筛选年龄>20
lambda x: [{"name": u["name"], "score": u["score"]} for u in x], # 提取字段
lambda x: sorted(x, key=lambda u: -u["score"]) # 按分数降序排序
)
print(result)
# 输出:[{'name': '李四', 'score': 90}, {'name': '王五', 'score': 80}]
4.7 场景 7:动态生成函数处理不同场景
在某些场景下,需要根据不同的条件动态生成函数,Lambda 可以快速实现这一需求。
示例:动态生成函数
# 场景:根据用户选择的操作类型,动态生成对应的处理函数
def get_processor(operation):
processors = {
"add": lambda a, b: a + b,
"subtract": lambda a, b: a - b,
"multiply": lambda a, b: a * b,
"divide": lambda a, b: a / b if b != 0 else "除数不能为0",
"power": lambda a, b: a ** b,
"mod": lambda a, b: a % b
}
# 返回对应的处理函数,默认返回加法函数
return processors.get(operation, processors["add"])
# 测试:动态获取处理函数
operations = ["add", "multiply", "power", "divide"]
a, b = 10, 3
for op in operations:
processor = get_processor(op)
result = processor(a, b)
print(f"{a} {op} {b} = {result}")
# 输出:
# 10 add 3 = 13
# 10 multiply 3 = 30
# 10 power 3 = 1000
# 10 divide 3 = 3.3333333333333335
# 场景:动态生成数据验证函数
def get_validator(field_type):
validators = {
"string": lambda x: isinstance(x, str) and len(x) > 0,
"integer": lambda x: isinstance(x, int) and x >= 0,
"float": lambda x: isinstance(x, float) and x >= 0,
"email": lambda x: isinstance(x, str) and "@" in x
}
return validators.get(field_type, lambda x: False)
# 测试:验证不同类型的数据
fields = [
("username", "string", "张三"),
("age", "integer", 25),
("salary", "float", -1000.0), # 无效
("email", "email", "test@example.com")
]
for field_name, field_type, value in fields:
validator = get_validator(field_type)
is_valid = validator(value)
print(f"{field_name}({field_type}):{value} → {'有效' if is_valid else '无效'}")
# 输出:
# username(string):张三 → 有效
# age(integer):25 → 有效
# salary(float):-1000.0 → 无效
# email(email):test@example.com → 有效
4.8 场景 8:简化排序中的 key 函数
在复杂排序场景中,sorted的key参数需要自定义函数,Lambda 可以简化这一过程。
示例:简化排序 key 函数
# 示例1:对文件名按数字部分排序
import re
file_names = ["file1.txt", "file10.txt", "file2.txt", "file20.txt", "file3.txt"]
# 提取文件名中的数字作为排序key
sorted_files = sorted(
file_names,
key=lambda x: int(re.findall(r"\d+", x)[0]) # 提取数字并转换为整数
)
print(sorted_files) # 输出:['file1.txt', 'file2.txt', 'file3.txt', 'file10.txt', 'file20.txt']
# 示例2:对嵌套元组列表排序
nested_tuples = [((1, 3), 2), ((2, 1), 4), ((1, 2), 3)]
# 按元组的第一个元素的第二个值排序
sorted_tuples = sorted(
nested_tuples,
key=lambda x: x[0][1]
)
print(sorted_tuples) # 输出:[((2, 1), 4), ((1, 2), 3), ((1, 3), 2)]
# 示例3:对字符串按元音字母数量排序
vowels = {"a", "e", "i", "o", "u", "A", "E", "I", "O", "U"}
str_list = ["apple", "banana", "cherry", "date", "elephant"]
# 计算每个字符串中的元音字母数量
sorted_strs = sorted(
str_list,
key=lambda s: len([c for c in s if c in vowels])
)
print(sorted_strs) # 输出:['date'(2个), 'cherry'(2个), 'apple'(2个), 'banana'(3个), 'elephant'(3个)]
4.9 场景 9:处理 Pandas 数据框中的行 / 列
在数据分析中,Pandas 是常用工具,Lambda 可以简化 DataFrame 中行 / 列的处理。
示例:Lambda 处理 Pandas DataFrame
import pandas as pd
# 创建DataFrame
df = pd.DataFrame({
"name": ["张三", "李四", "王五", "赵六", "钱七"],
"age": [20, 30, 25, 35, 22],
"score": [85, 90, 80, 95, 75]
})
print("原始DataFrame:")
print(df)
# 示例1:使用apply对列进行处理(添加等级列)
df["grade"] = df["score"].apply(
lambda x: "优秀" if x >= 90 else ("良好" if x >= 80 else ("及格" if x >= 60 else "不及格"))
)
print("\n添加等级列后的DataFrame:")
print(df)
# 示例2:使用apply对行进行处理(计算年龄分组)
df["age_group"] = df["age"].apply(
lambda x: "青年" if x <= 25 else ("中年" if x <= 35 else "老年")
)
print("\n添加年龄分组后的DataFrame:")
print(df)
# 示例3:使用applymap对所有元素进行处理(字符串列转换为大写)
df["name_upper"] = df["name"].apply(lambda x: x.upper())
print("\n添加姓名大写列后的DataFrame:")
print(df)
# 示例4:使用filter筛选行(筛选优秀且青年的用户)
filtered_df = df[df.apply(
lambda row: row["grade"] == "优秀" and row["age_group"] == "青年",
axis=1
)]
print("\n筛选优秀且青年的用户:")
print(filtered_df)
4.10 场景 10:简化闭包中的内层函数
闭包中的内层函数如果逻辑简单,使用 Lambda 可以简化代码,让闭包更简洁。
示例:Lambda 简化闭包
# 示例1:生成带前缀的日志函数
def create_logger(prefix):
# Lambda作为内层函数,引用prefix变量
return lambda msg: print(f"[{prefix}] {msg}")
# 创建不同前缀的日志函数
info_logger = create_logger("INFO")
error_logger = create_logger("ERROR")
warning_logger = create_logger("WARNING")
# 使用日志函数
info_logger("程序启动成功")
error_logger("数据库连接失败")
warning_logger("内存使用过高")
# 输出:
# [INFO] 程序启动成功
# [ERROR] 数据库连接失败
# [WARNING] 内存使用过高
# 示例2:生成带系数的乘法函数
def create_multiplier(factor):
return lambda x: x * factor
# 创建不同系数的乘法函数
double = create_multiplier(2)
triple = create_multiplier(3)
quadruple = create_multiplier(4)
print(double(5)) # 输出:10
print(triple(5)) # 输出:15
print(quadruple(5))# 输出:20
# 示例3:生成条件过滤函数
def create_filter(condition):
return lambda data: list(filter(condition, data))
# 创建筛选偶数的函数
filter_even = create_filter(lambda x: x % 2 == 0)
# 创建筛选大于10的函数
filter_greater_than_10 = create_filter(lambda x: x > 10)
data = [1, 2, 3, 4, 10, 11, 12, 13]
print(filter_even(data)) # 输出:[2, 4, 10, 12]
print(filter_greater_than_10(data)) # 输出:[11, 12, 13]
五、避坑指南:Lambda 使用的 10 个常见错误

Lambda 虽然简洁高效,但如果使用不当,容易出现问题。本节将总结 Lambda 使用中的常见错误及解决方案。
5.1 错误 1:Lambda 表达式中使用复杂语句
问题:Lambda 表达式仅支持单个表达式,无法使用if-else语句、循环、异常处理等复杂结构。示例:
# 错误示例:Lambda中使用if-else语句
wrong_lambda = lambda x: if x > 0: x else -x
解决方案:使用三元运算符替代复杂语句,或改用普通函数。
# 正确示例:使用三元运算符
correct_lambda = lambda x: x if x > 0 else -x
print(correct_lambda(-5)) # 输出:5
# 复杂逻辑改用普通函数
def process_x(x):
if x > 0:
return x * 2
elif x == 0:
return 0
else:
return x * (-2)
5.2 错误 2:忽视 Lambda 的作用域问题
问题:Lambda 中的变量引用遵循 Python 的作用域规则,容易出现变量延迟绑定的问题。示例:
# 错误示例:变量延迟绑定
funcs = []
for i in range(3):
funcs.append(lambda: print(i)) # i是循环变量,延迟绑定
# 执行函数,所有函数都打印2(循环结束后i的值)
for func in funcs:
func() # 输出:2 2 2
解决方案:通过默认参数立即绑定变量,或使用闭包。
# 正确示例1:使用默认参数立即绑定
funcs = []
for i in range(3):
funcs.append(lambda x=i: print(x)) # x默认值为当前i,立即绑定
for func in funcs:
func() # 输出:0 1 2
# 正确示例2:使用闭包
def create_func(i):
return lambda: print(i)
funcs = []
for i in range(3):
funcs.append(create_func(i))
for func in funcs:
func() # 输出:0 1 2
5.3 错误 3:Lambda 表达式过于复杂
问题:Lambda 的优势是简洁,若表达式过于复杂,会导致代码可读性差。示例:
# 错误示例:复杂的Lambda表达式
complex_lambda = lambda x: (x ** 2 + 2 * x + 1) if x > 0 else (x ** 3 - 3 * x + 2) if x < 0 else 0
解决方案:将复杂逻辑拆分为普通函数,或使用辅助函数。
# 正确示例:改用普通函数
def calculate(x):
if x > 0:
return x ** 2 + 2 * x + 1
elif x < 0:
return x ** 3 - 3 * x + 2
else:
return 0
print(calculate(2)) # 输出:9
print(calculate(-1)) # 输出:4
5.4 错误 4:误用 Lambda 作为复杂函数的替代
问题:Lambda 仅适合简单逻辑,若用于实现复杂功能,会导致代码难以维护。示例:
# 错误示例:用Lambda实现复杂的数据处理
data_process = lambda data: [
{
"name": item["name"],
"age": item["age"],
"adult": item["age"] >= 18
}
for item in data
if item["age"] is not None
]
解决方案:复杂功能改用普通函数,提高代码可读性和可维护性。
# 正确示例:改用普通函数
def process_data(data):
processed = []
for item in data:
if item["age"] is not None:
processed.append({
"name": item["name"],
"age": item["age"],
"adult": item["age"] >= 18
})
return processed
# 测试
data = [
{"name": "张三", "age": 20},
{"name": "李四", "age": None},
{"name": "王五", "age": 16}
]
print(process_data(data))
# 输出:[{'name': '张三', 'age': 20, 'adult': True}, {'name': '王五', 'age': 16, 'adult': False}]
5.5 错误 5:Lambda 与普通函数的选择误区
问题:盲目使用 Lambda,忽视普通函数的优势(如支持文档字符串、复杂逻辑、可读性强)。示例:
# 错误示例:简单逻辑但需要文档字符串,却使用Lambda
add = lambda x, y: x + y
# 无法为Lambda添加文档字符串
解决方案:需要文档字符串、复杂逻辑或长期复用的函数,改用普通函数。
# 正确示例:需要文档字符串,使用普通函数
def add(x, y):
"""
计算两个数的和
参数:
x: 第一个数
y: 第二个数
返回:
两个数的和
"""
return x + y
print(add(2, 3)) # 输出:5
print(add.__doc__) # 可以查看文档字符串
5.6 错误 6:Lambda 中修改外部变量
问题:Lambda 表达式应尽量保持纯函数特性,避免修改外部变量,否则会导致代码副作用。示例:
# 错误示例:Lambda修改外部变量
count = 0
increment = lambda: nonlocal count; count += 1 # 虽然可行,但不推荐
increment()
print(count) # 输出:1
解决方案:需要修改状态的逻辑,改用普通函数或类。
# 正确示例:使用普通函数
def create_counter():
count = 0
def increment():
nonlocal count
count += 1
return count
return increment
counter = create_counter()
print(counter()) # 输出:1
print(counter()) # 输出:2
5.7 错误 7:Lambda 作为默认参数时的延迟绑定
问题:Lambda 作为函数默认参数时,若引用外部变量,会出现延迟绑定问题。示例:
# 错误示例:Lambda作为默认参数的延迟绑定
def func(callback=lambda: print(x)):
x = 10
callback()
func() # 报错:NameError: name 'x' is not defined
解决方案:避免在默认参数中使用 Lambda 引用外部变量,或通过嵌套函数绑定变量。
# 正确示例1:不引用外部变量
def func(callback=lambda: print("默认回调")):
callback()
func() # 输出:默认回调
# 正确示例2:通过嵌套函数绑定变量
def func():
x = 10
def callback():
print(x)
callback()
func() # 输出:10
5.8 错误 8:Lambda 与sort函数的 key 参数误用
问题:在sorted函数中,Lambda 作为key参数时,返回值类型错误导致排序异常。示例:
# 错误示例:key函数返回值类型不一致
data = [1, "2", 3, "4", 5]
sorted_data = sorted(data, key=lambda x: int(x) if isinstance(x, str) else x)
print(sorted_data) # 输出:[1, '2', 3, '4', 5](虽然可行,但不推荐混合类型)
解决方案:确保key函数返回值类型一致,或先统一数据类型。
# 正确示例:先统一数据类型
data = [1, "2", 3, "4", 5]
# 转换所有元素为整数后排序
sorted_data = sorted(data, key=lambda x: int(x))
print(sorted_data) # 输出:[1, '2', 3, '4', 5](排序逻辑正确)
# 或先转换数据类型
data = [int(x) for x in data]
sorted_data = sorted(data)
print(sorted_data) # 输出:[1, 2, 3, 4, 5]
5.9 错误 9:Lambda 表达式中使用可变参数
问题:Lambda 表达式不支持可变参数(*args、**kwargs),若强行使用会报错。示例:
# 错误示例:Lambda使用可变参数
wrong_lambda = lambda *args: sum(args)
解决方案:改用普通函数支持可变参数。
# 正确示例:普通函数支持可变参数
def sum_args(*args):
return sum(args)
print(sum_args(1, 2, 3)) # 输出:6
print(sum_args(4, 5, 6, 7)) # 输出:22
5.10 错误 10:过度使用 Lambda 导致代码可读性下降
问题:为了追求简洁,过度使用 Lambda,导致代码难以理解和调试。示例:
# 错误示例:过度使用Lambda,代码可读性差
result = list(map(lambda x: lambda y: x * y, [1, 2, 3]))
for func in result:
print(func(2)) # 输出:2 4 6
解决方案:适当使用普通函数替代 Lambda,平衡简洁性和可读性。
# 正确示例:使用普通函数,可读性更强
def multiply_by_x(x):
def multiply_by_y(y):
return x * y
return multiply_by_y
result = list(map(multiply_by_x, [1, 2, 3]))
for func in result:
print(func(2)) # 输出:2 4 6
六、实战项目:用 Lambda 打造简易数据处理工具

结合前面的知识点,我们用 Lambda 表达式开发一个简易的数据处理工具,支持数据清洗、转换、筛选、排序等功能,展示 Lambda 在实际项目中的应用。
6.1 项目需求分析
- 支持加载 CSV 格式的数据文件;
- 提供数据清洗功能(过滤无效数据、处理缺失值);
- 提供数据转换功能(字段类型转换、新增计算字段);
- 提供数据筛选功能(按条件筛选符合要求的数据);
- 提供数据排序功能(按指定字段排序);
- 支持将处理后的数据导出为 CSV 文件。
6.2 项目结构设计
data_processor/
└── main.py # 工具核心代码
6.3 完整代码实现
import csv
import os
from datetime import datetime
class DataProcessor:
def __init__(self):
self.data = [] # 存储原始数据
self.processed_data = [] # 存储处理后的数据
def load_csv(self, file_path):
"""加载CSV文件"""
if not os.path.exists(file_path):
print(f"错误:文件 {file_path} 不存在")
return False
try:
with open(file_path, "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
self.data = [row for row in reader]
self.processed_data = self.data.copy()
print(f"成功加载 {len(self.data)} 条数据")
return True
except Exception as e:
print(f"加载CSV文件失败:{str(e)}")
return False
def clean_data(self, clean_rules):
"""数据清洗:根据规则过滤无效数据"""
if not self.processed_data:
print("错误:未加载数据")
return False
try:
# 应用清洗规则:保留符合所有规则的数据
self.processed_data = list(filter(
lambda row: all(rule(row) for rule in clean_rules),
self.processed_data
))
print(f"数据清洗完成,剩余 {len(self.processed_data)} 条数据")
return True
except Exception as e:
print(f"数据清洗失败:{str(e)}")
return False
def transform_data(self, transform_rules):
"""数据转换:根据规则转换数据字段"""
if not self.processed_data:
print("错误:未加载数据")
return False
try:
# 应用转换规则:对每条数据应用所有转换函数
self.processed_data = list(map(
lambda row: self._apply_transforms(row, transform_rules),
self.processed_data
))
print("数据转换完成")
return True
except Exception as e:
print(f"数据转换失败:{str(e)}")
return False
def _apply_transforms(self, row, transform_rules):
"""对单条数据应用所有转换规则"""
new_row = row.copy()
for key, transform_func in transform_rules.items():
if key in new_row:
new_row[key] = transform_func(new_row[key])
else:
# 新增字段
new_row[key] = transform_func(new_row)
return new_row
def filter_data(self, filter_func):
"""数据筛选:根据条件筛选数据"""
if not self.processed_data:
print("错误:未加载数据")
return False
try:
self.processed_data = list(filter(filter_func, self.processed_data))
print(f"数据筛选完成,剩余 {len(self.processed_data)} 条数据")
return True
except Exception as e:
print(f"数据筛选失败:{str(e)}")
return False
def sort_data(self, sort_key_func, reverse=False):
"""数据排序:根据指定规则排序"""
if not self.processed_data:
print("错误:未加载数据")
return False
try:
self.processed_data = sorted(self.processed_data, key=sort_key_func, reverse=reverse)
print("数据排序完成")
return True
except Exception as e:
print(f"数据排序失败:{str(e)}")
return False
def export_csv(self, file_path):
"""导出处理后的数据为CSV文件"""
if not self.processed_data:
print("错误:无处理后的数据")
return False
try:
# 获取字段名(第一条数据的键)
fieldnames = self.processed_data[0].keys() if self.processed_data else []
with open(file_path, "w", encoding="utf-8", newline="") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(self.processed_data)
print(f"成功导出 {len(self.processed_data)} 条数据到 {file_path}")
return True
except Exception as e:
print(f"导出CSV文件失败:{str(e)}")
return False
# ------------------------------
# 测试工具
# ------------------------------
if __name__ == "__main__":
# 创建数据处理器实例
processor = DataProcessor()
# 1. 加载CSV文件(假设数据格式:name,age,score,hire_date,salary)
# 先创建测试CSV文件
test_csv = "test_data.csv"
with open(test_csv, "w", encoding="utf-8", newline="") as f:
writer = csv.DictWriter(f, fieldnames=["name", "age", "score", "hire_date", "salary"])
writer.writeheader()
writer.writerows([
{"name": "张三", "age": "20", "score": "85", "hire_date": "2020-01-15", "salary": "8000"},
{"name": "", "age": "30", "score": "90", "hire_date": "2021-03-20", "salary": "10000"}, # 姓名为空
{"name": "王五", "age": "", "score": "80", "hire_date": "2019-05-10", "salary": "9000"}, # 年龄为空
{"name": "赵六", "age": "35", "score": "-10", "hire_date": "2022-07-01", "salary": "12000"}, # 分数异常
{"name": "钱七", "age": "25", "score": "95", "hire_date": "2020-09-30", "salary": "11000"}
])
# 加载CSV文件
processor.load_csv(test_csv)
# 2. 数据清洗:过滤无效数据
clean_rules = [
lambda row: row["name"] != "", # 姓名不为空
lambda row: row["age"] != "", # 年龄不为空
lambda row: int(row["score"]) >= 0 # 分数大于等于0
]
processor.clean_data(clean_rules)
# 3. 数据转换:转换字段类型,新增字段
transform_rules = {
"age": lambda x: int(x), # 年龄转换为整数
"score": lambda x: int(x), # 分数转换为整数
"salary": lambda x: float(x), # 薪资转换为浮点数
"hire_date": lambda x: datetime.strptime(x, "%Y-%m-%d").strftime("%Y年%m月%d日"), # 日期格式转换
"grade": lambda row: "优秀" if row["score"] >= 90 else ("良好" if row["score"] >= 80 else "及格"), # 新增等级字段
"annual_salary": lambda row: float(row["salary"]) * 12 # 新增年薪字段
}
processor.transform_data(transform_rules)
# 4. 数据筛选:筛选年龄>25且等级为优秀的员工
processor.filter_data(
lambda row: row["age"] > 25 and row["grade"] == "优秀"
)
# 5. 数据排序:按年薪降序排序
processor.sort_data(
key=lambda row: row["annual_salary"],
reverse=True
)
# 6. 导出处理后的数据
processor.export_csv("processed_data.csv")
# 7. 打印处理后的数据
print("\n处理后的数据:")
for row in processor.processed_data:
print(row)
6.4 运行结果
成功加载 5 条数据
数据清洗完成,剩余 3 条数据
数据转换完成
数据筛选完成,剩余 1 条数据
数据排序完成
成功导出 1 条数据到 processed_data.csv
处理后的数据:
{'name': '钱七', 'age': 25, 'score': 95, 'hire_date': '2020年09月30日', 'salary': 11000.0, 'grade': '优秀', 'annual_salary': 132000.0}
6.5 项目亮点
- Lambda 深度应用:数据清洗、转换、筛选、排序等核心功能均使用 Lambda 实现,代码简洁高效;
- 高度灵活:通过传入不同的 Lambda 函数,支持自定义数据处理规则,适配多种场景;
- 功能完整:涵盖数据处理的全流程,从加载、清洗、转换、筛选、排序到导出,可直接用于实际项目;
- 易于扩展:新增数据处理功能时,只需添加对应的方法和 Lambda 规则,扩展性强。
七、总结与进阶学习
7.1 Lambda 核心要点总结
- 本质:Lambda 是 Python 中的匿名函数,仅支持单个表达式,用于实现简单逻辑;
- 核心优势:简洁高效、代码紧凑,适合临时使用的小函数,尤其适合作为高阶函数的参数;
- 核心应用场景:数据处理(
map、filter、sorted)、回调函数、闭包、函数式编程; - 使用原则:逻辑简单、即用即弃,避免复杂逻辑和过度使用,平衡简洁性和可读性。
7.2 进阶学习方向
- 函数式编程深入学习:掌握
functools模块中的reduce、partial、singledispatch等工具,结合 Lambda 实现更复杂的函数式编程; - 框架中的 Lambda 应用:阅读 Django、Flask、Pandas 等框架的源码,学习 Lambda 在实际框架中的应用场景;
- 性能优化:了解 Lambda 与普通函数的性能差异,在高并发场景下合理选择使用;
- Python 高级特性结合:将 Lambda 与装饰器、生成器、上下文管理器等高级特性结合,实现更强大的功能;
- 其他语言中的匿名函数



















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









