




目录
一、先搞懂:什么是 Linux Shell?—— 内核与用户的 “沟通桥梁”
2.2.8 文件内容查看:cat/tail/head/more/less 命令
2.3.3 修改所有者 / 所属组:chown/chgrp 命令
2.4.2 查找命令 / 文件路径:which/whereis 命令
2.4.3 查看系统信息:uname/top/free 命令
三、Shell 脚本入门:从 “手动输入” 到 “自动执行”
7.4 坑点 4:循环遍历文件时,目录下无匹配文件导致遍历失败

class 卑微码农:
def __init__(self):
self.技能 = ['能读懂十年前祖传代码', '擅长用Ctrl+C/V搭建世界', '信奉"能跑就别动"的玄学']
self.发量 = 100 # 初始发量
self.咖啡因耐受度 = '极限'
def 修Bug(self, bug):
try:
# 试图用玄学解决问题
if bug.严重程度 == '离谱':
print("这一定是环境问题!")
else:
print("让我看看是谁又没写注释...哦,是我自己。")
except Exception as e:
# 如果try块都救不了,那就...
print("重启一下试试?")
self.发量 -= 1 # 每解决一个bug,头发-1
# 实例化一个我
我 = 卑微码农()引言
在 Linux 世界里,Shell 就像一位 “全能翻译官”,帮我们把人类的指令传递给 Linux 内核,完成文件操作、进程管理、自动化部署等一系列工作。无论是开发调试代码,还是运维监控服务器,Shell 都是不可或缺的工具。很多新手觉得 Shell 晦涩难懂,其实只要掌握核心逻辑,从命令行逐步过渡到脚本实战,就能轻松上手。
本文从 Shell 基础概念切入,循序渐进讲解命令行操作、脚本编写、文本处理、流程控制等核心内容,搭配大量可直接复用的实战示例,帮你彻底吃透 Linux Shell,解决日常工作中的 80% 问题。
一、先搞懂:什么是 Linux Shell?—— 内核与用户的 “沟通桥梁”
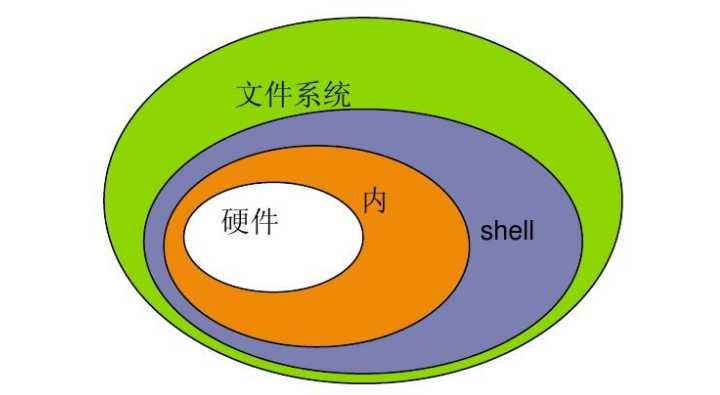
1.1 Shell 的本质:不是内核,却是 “指挥官”
Linux 内核(Kernel)是操作系统的核心,负责管理硬件资源(CPU、内存、硬盘),但它 “高冷” 且 “难懂”,只接受二进制指令。而 Shell 是一个命令解释器,介于用户和内核之间,把用户输入的字符串命令翻译成内核能理解的指令,执行后再把结果反馈给用户。
简单类比:内核是餐厅的后厨(负责做菜),Shell 是服务员(接收顾客订单,传达给后厨,再把菜端给顾客),用户就是顾客。
1.2 常见 Shell 类型:我们用的是哪一种?
Linux 系统中有多种 Shell,不同 Shell 功能略有差异,常见的有:
- sh(Bourne Shell):最早期的 Shell,功能简单,兼容性强,是很多 Shell 的基础;
- bash(Bourne Again Shell):目前绝大多数 Linux 发行版(CentOS、Ubuntu、Debian)的默认 Shell,兼容 sh,新增了别名、历史命令、脚本编程等强大功能;
- csh/tcsh:语法类似 C 语言,适合习惯 C 语言的用户;
- zsh:功能更丰富,支持自动补全、语法高亮,很多开发者的个性化选择。
查看当前系统默认 Shell:
echo $SHELL
# 输出示例:/bin/bash(表示默认是bash)
查看系统支持的 Shell:
cat /etc/shells
# 输出示例:
# /bin/sh
# /bin/bash
# /usr/bin/sh
# /usr/bin/bash
后续内容均以bash为准,这是日常工作中最常用的 Shell。
二、Shell 命令行基础:玩转终端的 “必备技能”
2.1 终端与命令行:打开 Shell 的 “窗口”
- 终端(Terminal):是用户与 Shell 交互的界面,比如 Ubuntu 的 GNOME 终端、CentOS 的 Konsole;
- 命令行(Command Line):终端中输入命令的区域,提示符通常为
$(普通用户)或#(root 用户)。
切换 root 用户(获取最高权限):
su - root # 输入root密码后切换
# 或使用sudo临时获取权限(Ubuntu常用)
sudo ls /root
2.2 核心命令:文件与目录操作(高频使用)
文件和目录操作是 Shell 最基础的功能,以下命令必须熟练掌握,每个命令搭配实战示例。
2.2.1 目录切换:cd 命令
# 1. 切换到指定绝对路径(从根目录/开始)
cd /home/user/Documents # 切换到用户的文档目录
# 2. 切换到相对路径(相对于当前目录)
cd ../Desktop # 切换到上一级目录的Desktop文件夹(../表示上一级)
cd ./test # 切换到当前目录的test文件夹(./可省略,直接cd test)
# 3. 切换到用户主目录(~表示主目录)
cd ~ # 等价于cd /home/user
# 4. 切换到上一次所在目录
cd - # 输出示例:/home/user,同时切换到该目录
2.2.2 目录查看:ls 命令
# 1. 查看当前目录下的文件和目录(默认仅显示名称)
ls
# 2. 详细查看(权限、所有者、大小、修改时间等)
ls -l # 简写为ll(很多系统已设置别名)
# 输出示例:
# drwxr-xr-x 2 user user 4096 10月 1 10:00 test
# -rw-r--r-- 1 user user 120 10月 1 09:30 test.txt
# 解释:d表示目录,-表示文件;rwx表示读写执行权限;2表示链接数;user是所有者;4096是大小(字节)
# 3. 查看隐藏文件(以.开头的文件)
ls -a # 结合-l:ls -la
# 4. 按大小排序查看(从大到小)
ls -lhS # h表示人性化显示大小(KB/MB/GB),S表示按大小排序
2.2.3 目录创建:mkdir 命令
# 1. 创建单个目录
mkdir test
# 2. 递归创建多级目录(父目录不存在时自动创建)
mkdir -p /home/user/project/code # 同时创建project和code目录
2.2.4 文件创建:touch 命令
# 1. 创建空文件
touch test.txt
# 2. 同时创建多个文件
touch a.txt b.log c.csv
# 3. 修改文件的访问/修改时间(不改变文件内容)
touch -d "2024-10-01 12:00" test.txt # 将文件时间改为指定时间
2.2.5 文件 / 目录复制:cp 命令
# 1. 复制文件到指定目录
cp test.txt /home/user/Desktop # 把test.txt复制到桌面
# 2. 复制目录(必须加-r,递归复制)
cp -r test /home/user/Desktop # 把test目录及内容复制到桌面
# 3. 复制时保留文件属性(权限、时间等)
cp -a test.txt /home/user/Desktop # -a等价于-pdr
# 4. 覆盖文件时提示确认
cp -i test.txt /home/user/Desktop # 若目标目录有同名文件,提示是否覆盖
2.2.6 文件 / 目录移动 / 重命名:mv 命令
# 1. 移动文件到指定目录
mv test.txt /home/user/Desktop # 把test.txt移动到桌面
# 2. 移动目录(无需加-r,直接移动)
mv test /home/user/Desktop
# 3. 文件重命名(同一目录下移动即重命名)
mv test.txt new_test.txt # 把test.txt改名为new_test.txt
# 4. 移动时覆盖提示
mv -i test.txt /home/user/Desktop
2.2.7 文件 / 目录删除:rm 命令
⚠️ 注意:rm 命令删除的文件 / 目录无法恢复,慎用!
# 1. 删除文件
rm test.txt
# 2. 强制删除文件(无提示)
rm -f test.txt # 即使文件只读,也能删除
# 3. 删除目录(必须加-r,递归删除)
rm -r test
# 4. 强制删除目录(无提示)
rm -rf test # 高危命令!避免误删系统文件(如rm -rf /)
2.2.8 文件内容查看:cat/tail/head/more/less 命令
# 1. 查看文件全部内容(适合小文件)
cat test.txt
# 2. 查看文件前n行(默认前10行)
head test.txt # 前10行
head -n 5 test.txt # 前5行
# 3. 查看文件后n行(默认后10行,实时监控日志常用)
tail test.txt # 后10行
tail -n 5 test.txt # 后5行
tail -f test.log # 实时跟踪文件内容变化(日志输出时自动刷新)
# 4. 分页查看大文件(按空格键翻页,q退出)
more test.txt # 只能向下翻页
less test.txt # 可上下翻页,支持搜索(输入/关键词查找)
2.3 权限管理:看懂并修改文件权限
Linux 是多用户系统,每个文件 / 目录都有严格的权限控制,避免未授权访问。
2.3.1 权限的表示:rwx 与数字权限
用ls -l查看文件时,最前面的 10 个字符就是权限信息,例如:drwxr-xr-x
- 第 1 位:文件类型(d = 目录,-= 普通文件,l = 链接文件);
- 第 2-4 位:所有者(user)权限(r = 读,w = 写,x = 执行);
- 第 5-7 位:所属组(group)权限;
- 第 8-10 位:其他用户(others)权限。
权限的数字表示(r=4,w=2,x=1,相加得到权限值):
- rw- = 4+2=6;
- r-x = 4+1=5;
- rwx = 4+2+1=7;
- --- = 0。
例如rwxr-xr-x对应的数字权限是 755,rw-r--r--是 644。
2.3.2 修改权限:chmod 命令
# 1. 数字方式修改(推荐,简洁)
chmod 755 test.sh # 所有者rwx,所属组r-x,其他r-x
chmod 644 test.txt # 所有者rw-,所属组r--,其他r--
# 2. 符号方式修改(更灵活)
chmod u+x test.sh # u=所有者,+x=添加执行权限
chmod g-w test.txt # g=所属组,-w=移除写权限
chmod o=r test.txt # o=其他用户,=r=设置为只读权限
chmod a+r test.txt # a=所有用户,+r=添加读权限
2.3.3 修改所有者 / 所属组:chown/chgrp 命令
# 1. 修改所有者(需root权限)
chown root test.txt # 把test.txt的所有者改为root
# 2. 同时修改所有者和所属组
chown root:root test.txt # 所有者和所属组都改为root
# 3. 修改所属组
chgrp user test.txt # 把所属组改为user
2.4 其他常用命令:提升效率必备
2.4.1 查找文件 / 目录:find 命令
# 1. 在当前目录下查找名为test.txt的文件
find . -name "test.txt"
# 2. 在/home目录下查找所有.log后缀的文件
find /home -name "*.log"
# 3. 查找大小大于100MB的文件
find / -size +100M
# 4. 查找24小时内修改过的文件
find /home/user -mtime 0
# 5. 查找所有者为user的文件
find /home -user user
2.4.2 查找命令 / 文件路径:which/whereis 命令
# 1. 查找命令的执行路径
which ls # 输出:/bin/ls
which python3 # 输出:/usr/bin/python3
# 2. 查找命令的二进制文件、源码和帮助文档路径
whereis ls # 输出:ls: /bin/ls /usr/share/man/man1/ls.1.gz
2.4.3 查看系统信息:uname/top/free 命令
# 1. 查看系统内核版本
uname -r # 输出示例:5.15.0-78-generic
# 2. 查看系统负载和进程信息(实时刷新)
top # 按q退出,PID=进程ID,%CPU=CPU占用率,%MEM=内存占用率
# 3. 查看内存使用情况
free -h # h表示人性化显示(总内存、已用、空闲)
# 输出示例:
# total used free shared buff/cache available
# Mem: 15Gi 2.3Gi 10Gi 224Mi 3.1Gi 13Gi
2.4.4 压缩与解压:tar 命令
tar 是 Linux 最常用的压缩解压工具,支持.tar、.tar.gz、.tar.bz2 等格式。
# 1. 压缩文件/目录为.tar.gz格式(最常用)
tar -zcvf test.tar.gz test.txt test/ # z=gzip压缩,c=创建,v=显示过程,f=指定文件名
# 2. 解压.tar.gz文件
tar -zxvf test.tar.gz # x=解压,解压到当前目录
tar -zxvf test.tar.gz -C /home/user/Desktop # -C指定解压目录
# 3. 压缩为.tar.bz2格式(压缩率更高,速度较慢)
tar -jcvf test.tar.bz2 test.txt test/
# 4. 解压.tar.bz2文件
tar -jxvf test.tar.bz2
三、Shell 脚本入门:从 “手动输入” 到 “自动执行”
手动输入命令适合单次操作,若需要重复执行一系列命令(如批量处理文件、自动化部署),就需要编写 Shell 脚本(.sh 文件),把命令按逻辑组织起来,一键执行。

3.1 脚本的基本结构:Hello World 示例
新建一个脚本文件hello.sh,内容如下:
#!/bin/bash
# 这是注释:第一个Shell脚本,输出Hello World
# 输出字符串
echo "Hello World!"
脚本执行的 3 种方式:
# 方式1:赋予执行权限后直接运行(推荐)
chmod +x hello.sh # 赋予执行权限
./hello.sh # 运行脚本(./表示当前目录)
# 方式2:用bash命令解释执行(无需执行权限)
bash hello.sh
# 方式3:用source命令执行(会在当前Shell环境中运行,影响环境变量)
source hello.sh
输出结果:Hello World!
关键说明:
#!/bin/bash:指定脚本的解释器为 bash,必须放在脚本第一行;#:注释符号,后面的内容不会执行;echo:输出字符串到终端。
3.2 变量:脚本中的 “容器”
变量用于存储数据(字符串、数字等),在脚本中重复使用,提升灵活性。
3.2.1 变量定义与使用
#!/bin/bash
# 变量定义:变量名=值(等号两边不能有空格!)
name="Linux"
version=5.15
message="Hello, $name!" # 变量引用:$变量名
# 输出变量
echo "系统名称:$name"
echo "内核版本:$version"
echo $message
# 变量重新赋值
version=6.0
echo "更新后的内核版本:$version"
执行结果:
系统名称:Linux
内核版本:5.15
Hello, Linux!
更新后的内核版本:6.0
3.2.2 特殊变量:脚本参数与系统变量
(1)脚本参数变量(运行脚本时传入的参数)
| 变量 | 含义 |
|---|---|
| $0 | 脚本文件名 |
| 1−n | 第 1 个到第 n 个参数 |
| $# | 参数总数 |
| $* | 所有参数(作为一个整体) |
| $@ | 所有参数(每个参数独立) |
| $? | 上一条命令的执行结果(0 = 成功,非 0 = 失败) |
示例:参数处理脚本param.sh
#!/bin/bash
echo "脚本文件名:$0"
echo "第1个参数:$1"
echo "第2个参数:$2"
echo "参数总数:$#"
echo "所有参数(整体):$*"
echo "所有参数(独立):$@"
# 验证上一条命令执行结果
echo "执行echo命令后的状态:$?" # 输出0,因为echo执行成功
运行脚本并传入参数:
./param.sh "Shell" "Script"
输出结果:
脚本文件名:./param.sh
第1个参数:Shell
第2个参数:Script
参数总数:2
所有参数(整体):Shell Script
所有参数(独立):Shell Script
执行echo命令后的状态:0
(2)常用系统变量
#!/bin/bash
echo "当前用户:$USER"
echo "用户主目录:$HOME"
echo "当前工作目录:$PWD"
echo "系统PATH:$PATH" # 命令搜索路径,可执行文件所在目录
echo "主机名:$HOSTNAME"
3.3 字符串处理:拼接、截取与替换
字符串是 Shell 脚本中最常用的数据类型,掌握以下操作能应对大部分场景。
3.3.1 字符串拼接
#!/bin/bash
str1="Hello"
str2="World"
# 拼接方式1:直接连接
str3=$str1$str2
echo $str3 # 输出:HelloWorld
# 拼接方式2:加双引号(推荐,可读性强)
str4="$str1 $str2"
echo $str4 # 输出:Hello World
# 拼接方式3:单引号(单引号内变量不解析,原样输出)
str5='$str1 $str2'
echo $str5 # 输出:$str1 $str2
3.3.2 字符串长度
#!/bin/bash
str="Linux Shell"
echo "字符串长度:${#str}" # 输出:11(空格算1个字符)
3.3.3 字符串截取
语法:${变量名:起始位置:长度}(起始位置从 0 开始,长度可选)
#!/bin/bash
str="Linux Shell Script"
# 从第0位开始,截取5个字符
echo ${str:0:5} # 输出:Linux
# 从第6位开始,截取到末尾(省略长度)
echo ${str:6} # 输出:Shell Script
# 从倒数第7位开始,截取7个字符
echo ${str: -7:7} # 输出:Script(注意-7前有空格)
3.3.4 字符串替换
#!/bin/bash
str="Linux Shell Shell"
# 替换第一个匹配的子串
echo ${str/Shell/Bash} # 输出:Linux Bash Shell
# 替换所有匹配的子串
echo ${str//Shell/Bash} # 输出:Linux Bash Bash
# 从开头匹配并替换
echo ${str/#Linux/Unix} # 输出:Unix Shell Shell
# 从结尾匹配并替换
echo ${str/%Script/Code} # 输出:Linux Shell Code(原字符串末尾是Shell,无Script,所以不替换)
3.4 数组:存储多个数据
Shell 数组支持存储多个值,常用于批量处理数据(如文件列表、IP 地址等)。
3.4.1 数组定义与访问
#!/bin/bash
# 数组定义方式1:空格分隔值
fruits=("apple" "banana" "orange" "grape")
# 数组定义方式2:单独赋值
fruits[4]="mango"
# 访问数组元素:${数组名[索引]}(索引从0开始)
echo "第1个元素:${fruits[0]}"
echo "第3个元素:${fruits[2]}"
echo "第5个元素:${fruits[4]}"
# 访问所有元素:${数组名[@]} 或 ${数组名[*]}
echo "所有元素:${fruits[@]}"
# 数组长度:${#数组名[@]}
echo "数组长度:${#fruits[@]}"
输出结果:
第1个元素:apple
第3个元素:orange
第5个元素:mango
所有元素:apple banana orange grape mango
数组长度:5
3.4.2 数组遍历
#!/bin/bash
fruits=("apple" "banana" "orange" "grape")
# 方式1:for循环遍历
for fruit in ${fruits[@]}; do
echo "水果:$fruit"
done
# 方式2:按索引遍历
for ((i=0; i<${#fruits[@]}; i++)); do
echo "索引$i:${fruits[$i]}"
done
输出结果:
水果:apple
水果:banana
水果:orange
水果:grape
索引0:apple
索引1:banana
索引2:orange
索引3:grape
四、流程控制:让脚本 “聪明” 起来
默认情况下,Shell 脚本按顺序执行命令,流程控制能让脚本根据条件判断执行不同命令,或重复执行某段命令,实现更复杂的逻辑。

4.1 条件判断:if 语句
if 语句根据条件是否成立,执行不同的代码块,支持单分支、双分支、多分支。
4.1.1 基本语法
# 单分支
if [ 条件表达式 ]; then
命令1
命令2
fi
# 双分支
if [ 条件表达式 ]; then
命令1(条件成立时执行)
else
命令2(条件不成立时执行)
fi
# 多分支
if [ 条件表达式1 ]; then
命令1
elif [ 条件表达式2 ]; then
命令2
else
命令3
fi
⚠️ 注意:[ ] 前后必须加空格,否则会报错!
4.1.2 条件表达式:比较与判断
条件表达式主要用于比较数值、字符串,或判断文件状态。
(1)数值比较(适用于整数)
| 运算符 | 含义 |
|---|---|
| -eq | 等于(equal) |
| -ne | 不等于(not equal) |
| -gt | 大于(greater than) |
| -lt | 小于(less than) |
| -ge | 大于等于(greater or equal) |
| -le | 小于等于(less or equal) |
示例:数值比较脚本
#!/bin/bash
a=10
b=20
if [ $a -eq $b ]; then
echo "$a 等于 $b"
elif [ $a -lt $b ]; then
echo "$a 小于 $b"
else
echo "$a 大于 $b"
fi
输出结果:10 小于 20
(2)字符串比较
| 运算符 | 含义 |
|---|---|
| = 或 == | 等于(== 在 [ ] 中需加引号) |
| != | 不等于 |
| -z | 字符串长度为 0(空字符串) |
| -n | 字符串长度不为 0(非空字符串) |
示例:字符串比较脚本
#!/bin/bash
str1="Shell"
str2="Script"
if [ "$str1" = "$str2" ]; then
echo "两个字符串相等"
else
echo "两个字符串不相等"
fi
# 判断字符串是否为空
str3=""
if [ -z "$str3" ]; then
echo "str3是空字符串"
else
echo "str3是非空字符串"
fi
输出结果:
两个字符串不相等
str3是空字符串
(3)文件状态判断
| 运算符 | 含义 |
|---|---|
| -f | 是否为普通文件 |
| -d | 是否为目录 |
| -e | 文件 / 目录是否存在 |
| -r | 是否有读权限 |
| -w | 是否有写权限 |
| -x | 是否有执行权限 |
| -s | 文件是否非空(大小大于 0) |
示例:文件状态判断脚本
#!/bin/bash
file="test.txt"
dir="test"
# 判断文件是否存在
if [ -e "$file" ]; then
echo "$file 存在"
# 判断是否为普通文件
if [ -f "$file" ]; then
echo "$file 是普通文件"
fi
else
echo "$file 不存在"
touch "$file" # 创建文件
echo "已创建 $file"
fi
# 判断目录是否存在
if [ -d "$dir" ]; then
echo "$dir 是目录"
else
echo "$dir 不是目录"
fi
运行脚本(假设 test.txt 和 test 目录初始不存在):
test.txt 不存在
已创建 test.txt
test 不是目录
4.2 循环结构:for 与 while 循环
循环用于重复执行某段命令,比如遍历文件列表、批量处理数据等。
4.2.1 for 循环:遍历列表或范围
(1)遍历列表
#!/bin/bash
# 遍历数组
fruits=("apple" "banana" "orange")
for fruit in ${fruits[@]}; do
echo "水果:$fruit"
done
# 遍历文件列表
echo "当前目录下的.log文件:"
for file in *.log; do
echo $file
done
(2)遍历数字范围
语法:for 变量 in {起始..结束..步长}(步长可选,默认 1)
#!/bin/bash
# 遍历1-5(步长1)
echo "1-5的数字:"
for i in {1..5}; do
echo $i
done
# 遍历1-10,步长2(只取奇数)
echo "1-10的奇数:"
for i in {1..10..2}; do
echo $i
done
# 遍历10-1(倒序)
echo "10-1的数字:"
for i in {10..1}; do
echo $i
done
(3)C 语言风格 for 循环
语法:for ((初始值; 条件; 增量))
#!/bin/bash
# 计算1-10的和
sum=0
for ((i=1; i<=10; i++)); do
sum=$((sum + i)) # 数值计算:$((表达式))
done
echo "1-10的和:$sum" # 输出:55
4.2.2 while 循环:条件满足时执行
while 循环只要条件成立,就会一直执行循环体。
(1)基本用法
#!/bin/bash
# 计算1-10的和
sum=0
i=1
while [ $i -le 10 ]; do
sum=$((sum + i))
i=$((i + 1)) # 变量自增
done
echo "1-10的和:$sum" # 输出:55
(2)无限循环(配合 break 退出)
#!/bin/bash
i=1
while true; do # true表示条件永远成立
echo "当前数字:$i"
if [ $i -eq 5 ]; then
break # 当i=5时退出循环
fi
i=$((i + 1))
done
输出结果:
当前数字:1
当前数字:2
当前数字:3
当前数字:4
当前数字:5
(3)读取文件内容(逐行读取)
#!/bin/bash
# 逐行读取test.txt的内容
while read line; do
echo "文件内容:$line"
done < test.txt # < 表示从文件读取输入
4.3 循环控制:break 与 continue
break:退出当前循环(多层循环时只退出最内层);continue:跳过当前循环的剩余命令,直接进入下一次循环。
示例:循环控制脚本
#!/bin/bash
# break示例:遍历1-10,遇到5退出
echo "break示例:"
for i in {1..10}; do
if [ $i -eq 5 ]; then
break
fi
echo $i
done
# continue示例:遍历1-10,跳过偶数
echo "continue示例:"
for i in {1..10}; do
if [ $((i % 2)) -eq 0 ]; then # 判断偶数
continue
fi
echo $i
done
输出结果:
break示例:
1
2
3
4
continue示例:
1
3
5
7
9
五、文本处理三剑客:grep、sed、awk(核心应用)
Linux 中处理文本文件(日志、配置文件)时,grep、sed、awk 是最强大的工具组合,被誉为 “文本处理三剑客”。

5.1 grep:文本搜索神器
grep 用于在文件或输入中搜索匹配的字符串,支持正则表达式,是日志分析的必备工具。
5.1.1 基本用法
语法:grep [选项] 搜索模式 文件名
常用选项:
-i:忽略大小写;-n:显示匹配行的行号;-v:反向匹配(显示不包含匹配模式的行);-c:统计匹配的行数;-r:递归搜索目录下的所有文件;-E:支持扩展正则表达式。
5.1.2 实战示例
假设有一个日志文件app.log,内容如下:
2024-10-01 08:00:00 [INFO] 系统启动成功
2024-10-01 08:05:00 [ERROR] 数据库连接失败
2024-10-01 08:10:00 [INFO] 用户登录:admin
2024-10-01 08:15:00 [WARNING] 内存使用率过高:85%
2024-10-01 08:20:00 [INFO] 用户退出:admin
2024-10-01 08:25:00 [ERROR] 接口调用失败:/api/user
(1)搜索包含 “ERROR” 的行
grep "ERROR" app.log
# 输出:
# 2024-10-01 08:05:00 [ERROR] 数据库连接失败
# 2024-10-01 08:25:00 [ERROR] 接口调用失败:/api/user
(2)搜索包含 “INFO” 的行,并显示行号
grep -n "INFO" app.log
# 输出:
# 1:2024-10-01 08:00:00 [INFO] 系统启动成功
# 3:2024-10-01 08:10:00 [INFO] 用户登录:admin
# 5:2024-10-01 08:20:00 [INFO] 用户退出:admin
(3)忽略大小写搜索 “warning”
grep -i "warning" app.log
# 输出:
# 2024-10-01 08:15:00 [WARNING] 内存使用率过高:85%
(4)统计匹配 “INFO” 的行数
grep -c "INFO" app.log
# 输出:3
(5)反向匹配:显示不包含 “INFO” 的行
grep -v "INFO" app.log
# 输出所有非INFO级别的日志
(6)递归搜索目录下所有文件中的 “ERROR”
grep -r "ERROR" /var/log/ # 搜索/var/log目录下所有文件中的ERROR
5.2 sed:文本编辑工具
sed 是流编辑器,用于对文本进行替换、删除、插入等操作,不修改原文件(除非使用-i选项)。
5.2.1 基本用法
语法:sed [选项] '操作' 文件名
常用选项:
-i:直接修改原文件(慎用!建议先备份);-n:只显示匹配的行;-e:执行多个操作。
常用操作:
s/原字符串/新字符串/:替换匹配的字符串(默认替换每行第一个匹配);s/原字符串/新字符串/g:全局替换(每行所有匹配);d:删除匹配的行;i:在匹配行前插入内容;a:在匹配行后追加内容;p:打印匹配的行。
5.2.2 实战示例(基于 app.log 文件)
(1)替换字符串:将 “ERROR” 改为 “严重错误”
# 不修改原文件,输出修改后的结果
sed 's/ERROR/严重错误/' app.log
# 全局替换(若一行有多个ERROR)
sed 's/ERROR/严重错误/g' app.log
# 直接修改原文件(建议先备份:cp app.log app.log.bak)
sed -i 's/ERROR/严重错误/' app.log
(2)删除包含 “WARNING” 的行
# 输出删除后的结果(不修改原文件)
sed '/WARNING/d' app.log
# 直接删除原文件中的行
sed -i '/WARNING/d' app.log
(3)在包含 “INFO” 的行前插入内容
sed '/INFO/i\【日志信息】' app.log
# 输出示例:
# 【日志信息】
# 2024-10-01 08:00:00 [INFO] 系统启动成功
(4)打印包含 “admin” 的行
sed -n '/admin/p' app.log
# 输出:
# 2024-10-01 08:10:00 [INFO] 用户登录:admin
# 2024-10-01 08:20:00 [INFO] 用户退出:admin
5.3 awk:文本分析工具
awk 是功能最强大的文本处理工具,支持模式匹配、字段提取、数值计算等,适合复杂的文本分析场景。
5.3.1 基本用法
语法:awk '模式{动作}' 文件名
- 模式:用于匹配行(如条件判断);
- 动作:对匹配的行执行操作(如打印字段、计算);
- 字段分隔符:默认是空格或制表符,可用
-F指定(如-F,表示逗号分隔); - 字段引用:
$1表示第 1 个字段,$2表示第 2 个字段,$0表示整行内容; - 内置变量:
NR(行号)、NF(当前行的字段数)。
5.3.2 实战示例
(1)提取字段:获取日志中的时间和日志级别
app.log 文件的字段用空格分隔,时间是第 1-2 个字段,日志级别是第 3 个字段(带 []):
# 打印时间($1 $2)和日志级别($3)
awk '{print "时间:"$1" "$2", 级别:"$3}' app.log
# 输出示例:
# 时间:2024-10-01 08:00:00, 级别:[INFO]
# 时间:2024-10-01 08:05:00, 级别:[ERROR]
(2)指定字段分隔符:处理 CSV 文件
假设有user.csv文件,内容如下(逗号分隔):
1,admin,123456,admin@example.com
2,user1,654321,user1@example.com
3,user2,112233,user2@example.com
提取用户名和邮箱:
(3)条件过滤:只显示 ERROR 级别的日志
bash
awk '$3 == "[ERROR]"{print $0}' app.log
# 输出所有ERROR级别的日志行
(4)数值计算:统计日志中 ERROR 的出现次数
awk '$3 == "[ERROR]"{count++} END{print "ERROR出现次数:"count}' app.log
# 输出:ERROR出现次数:2
(5)按行号处理:显示第 2-4 行的内容
awk 'NR>=2 && NR<=4{print $0}' app.log
# 输出第2到第4行的日志
六、Shell 脚本实战案例:解决实际问题
掌握了基础语法和工具后,我们通过几个实战案例,将知识应用到实际工作中。

6.1 案例 1:批量备份文件
需求:编写脚本,批量备份指定目录下的.log 文件到备份目录,并按日期命名备份文件。
#!/bin/bash
# 批量备份.log文件脚本
# 配置参数
source_dir="/var/log" # 源目录(日志文件所在目录)
backup_dir="/home/user/backup/log" # 备份目录
date=$(date +%Y%m%d) # 当前日期(格式:年月日)
# 检查备份目录是否存在,不存在则创建
if [ ! -d "$backup_dir" ]; then
mkdir -p "$backup_dir"
echo "创建备份目录:$backup_dir"
fi
# 批量备份.log文件(复制到备份目录,并添加日期后缀)
echo "开始备份$source_dir下的.log文件..."
for file in "$source_dir"/*.log; do
# 判断文件是否存在(避免目录下无.log文件时出错)
if [ -f "$file" ]; then
filename=$(basename "$file") # 获取文件名(不含路径)
backup_file="$backup_dir/${filename%.log}_$date.log" # 备份文件名:原文件名_日期.log
cp "$file" "$backup_file"
echo "备份成功:$file -> $backup_file"
fi
done
echo "所有.log文件备份完成!"
运行脚本:
chmod +x backup_log.sh
./backup_log.sh
输出示例:
创建备份目录:/home/user/backup/log
开始备份/var/log下的.log文件...
备份成功:/var/log/syslog.log -> /home/user/backup/log/syslog_20241001.log
备份成功:/var/log/auth.log -> /home/user/backup/log/auth_20241001.log
所有.log文件备份完成!
6.2 案例 2:日志分析与统计
需求:分析 app.log 日志,统计不同级别日志的数量,并输出 ERROR 级别的详细信息。
#!/bin/bash
# 日志分析脚本
log_file="app.log"
# 检查日志文件是否存在
if [ ! -f "$log_file" ]; then
echo "错误:日志文件$log_file不存在!"
exit 1 # 退出脚本,状态码1表示错误
fi
echo "=== 日志分析结果 ==="
# 统计INFO级别日志数量
info_count=$(grep -c "INFO" "$log_file")
echo "INFO级别日志:$info_count 条"
# 统计ERROR级别日志数量
error_count=$(grep -c "ERROR" "$log_file")
echo "ERROR级别日志:$error_count 条"
# 统计WARNING级别日志数量
warning_count=$(grep -c "WARNING" "$log_file")
echo "WARNING级别日志:$warning_count 条"
# 输出ERROR级别日志的详细信息(带行号)
echo -e "\n=== ERROR级别日志详情 ==="
grep -n "ERROR" "$log_file"
echo -e "\n日志分析完成!"
运行脚本输出:
=== 日志分析结果 ===
INFO级别日志:3 条
ERROR级别日志:2 条
WARNING级别日志:1 条
=== ERROR级别日志详情 ===
2:2024-10-01 08:05:00 [ERROR] 数据库连接失败
6:2024-10-01 08:25:00 [ERROR] 接口调用失败:/api/user
日志分析完成!
6.3 案例 3:自动化部署 Python 项目
需求:编写脚本,实现 Python 项目的自动化部署(拉取代码、安装依赖、启动服务)。
#!/bin/bash
# Python项目自动化部署脚本
# 配置参数
project_dir="/home/user/project/myapp" # 项目目录
git_repo="https://github.com/user/myapp.git" # Git仓库地址
python_env="/home/user/venv/bin/python" # Python虚拟环境路径
echo "=== 开始部署Python项目 ==="
# 1. 拉取最新代码
echo "1. 拉取最新代码..."
if [ -d "$project_dir" ]; then
cd "$project_dir" || exit 1 # 进入项目目录,失败则退出
git pull # 拉取代码
else
git clone "$git_repo" "$project_dir" # 克隆代码
cd "$project_dir" || exit 1
fi
# 2. 安装依赖
echo "2. 安装项目依赖..."
"$python_env" -m pip install -r requirements.txt
# 3. 停止旧服务(假设用killall停止进程,根据实际情况调整)
echo "3. 停止旧服务..."
killall -9 python3 2>/dev/null # 忽略无进程的错误信息
# 4. 启动新服务(后台运行)
echo "4. 启动新服务..."
nohup "$python_env" app.py > app.log 2>&1 & # nohup表示后台运行,输出重定向到app.log
echo "=== 项目部署完成! ==="
echo "服务日志:$project_dir/app.log"
运行脚本:
chmod +x deploy_app.sh
./deploy_app.sh
输出示例:
=== 开始部署Python项目 ===
1. 拉取最新代码...
Already up to date.
2. 安装项目依赖...
Requirement already satisfied: flask in /home/user/venv/lib/python3.8/site-packages (from -r requirements.txt (line 1))
3. 停止旧服务...
4. 启动新服务...
=== 项目部署完成! ===
服务日志:/home/user/project/myapp/app.log
七、避坑指南:Shell 脚本常见错误与解决方案
新手写 Shell 脚本时容易踩坑,以下是高频错误及应对方法。

7.1 坑点 1:变量赋值时等号两边有空格
错误代码:
name = "Linux" # 等号两边有空格,报错:name: 未找到命令
解决方案:等号两边不能有空格。
name="Linux"
7.2 坑点 2:字符串包含空格时未加引号
错误代码:
str=Hello World # 空格导致被解析为两个参数,报错:World: 未找到命令
解决方案:加双引号或单引号。
str="Hello World"
7.3 坑点 3:条件判断中变量未加引号(含空格时出错)
错误代码:
file="my file.txt"
if [ -f $file ]; then # 变量含空格,被解析为两个参数,报错
echo "文件存在"
fi
解决方案:变量加双引号。
if [ -f "$file" ]; then
echo "文件存在"
fi
7.4 坑点 4:循环遍历文件时,目录下无匹配文件导致遍历失败
错误代码:
for file in *.log; do
echo $file # 若目录下无.log文件,会输出"*.log"
done
解决方案:先判断文件是否存在。
for file in *.log; do
if [ -f "$file" ]; then
echo $file
fi
done
7.5 坑点 5:使用rm -rf时路径错误,误删重要文件
错误代码:
rm -rf $dir/* # 若dir为空,会变成rm -rf /*,删除根目录文件!
解决方案:先判断目录是否存在,或使用更安全的写法。
if [ -d "$dir" ]; then
rm -rf "$dir"/*
fi
7.6 坑点 6:脚本权限不足,无法执行
错误现象:
./test.sh: 权限不够
解决方案:赋予执行权限。
chmod +x test.sh
八、总结:Shell 学习路径与进阶建议
8.1 核心要点回顾
- Shell 的定位:用户与 Linux 内核的命令解释器,是日常操作和自动化的核心工具;
- 基础命令:重点掌握文件 / 目录操作、权限管理、压缩解压、系统信息查看;
- 脚本编程:掌握变量、字符串、数组、流程控制(if/for/while),能编写简单脚本;
- 文本处理:熟练使用 grep(搜索)、sed(编辑)、awk(分析),应对日志和配置文件处理;
- 实战优先:通过实际案例巩固知识,解决工作中的具体问题。
8.2 进阶学习建议
- 正则表达式:深入学习正则表达式,提升 grep、sed、awk 的使用效率;
- Shell 高级特性:学习函数、数组高级操作、进程管理、信号处理;
- 自动化工具整合:结合 crontab(定时任务)、ansible(批量运维),实现更复杂的自动化场景;
- 阅读优秀脚本:查看系统自带脚本(如 /etc/init.d/ 下的服务脚本),学习规范的编写风格。
Shell 的学习没有捷径,多动手写脚本、多解决实际问题,才能从 “会用” 到 “精通”。记住:Shell 的核心价值是 “自动化”,把重复的工作交给脚本,让自己专注于更重要的事情!


















 4075
4075



 到【灌水乐园】发言
到【灌水乐园】发言







