







随着微服务、云原生与 CI/CD 的普及,团队越来越需要在多个环境并行开展测试:开发环境(dev)、功能/集成环境(int)、预发布/准生产(staging)、性能环境(perf)、用户验收(UAT)以及临时的评审/预览环境(review apps / ephemeral envs)。并行带来速度与覆盖的提升,但也带来资源争用、数据污染、配置漂移与“环境冲突”风险。本文系统梳理多环境并行测试的价值、常见冲突类型、可落地的工程策略、操作级实践,并给出检查表与示例脚本,旨在让测试与工程团队在并行化轨道上既快又稳。
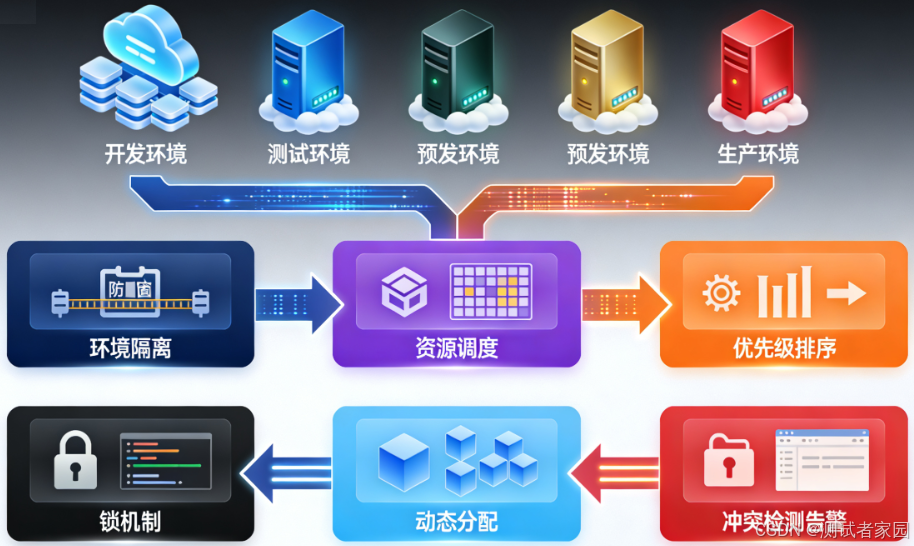
一、为什么要并行多个测试环境
- 并行化缩短交付周期:多个独立环境可以让不同团队同时验证功能、回归与性能,避免排队等待环境,从而缩短发版周期。
- 环境分层保证质量:把不同级别的测试分摊到不同环境(如在 staging 做端到端验收,在 perf 做高并发压测)可以避免互相干扰。
- 实现低风险发布:通过影子流量、金丝雀发布、蓝绿部署在生产附近验证变更,减少回滚成本。
- 支持快速反馈与审查:ephemeral envs(每个 PR 的预览环境)可以给产品、测试、设计快速可视化反馈,提升协作效率。
并行带来的成本和复杂性是可控的——关键在于用工程化手段避免冲突和保证可重复性。
二、常见的“环境冲突”类型
- 共享测试数据污染
- 多个测试并发写入同一个数据库或第三方服务,导致数据互相影响、测试不稳定或无法清理。
- 全局状态与单例服务冲突
- 使用单实例服务(如单一 Redis 实例、共享消息队列、全局锁)会产生并发冲突。
- 配置/凭证漂移
- 不同环境使用相同凭证/域名或未隔离的配置导致误连生产或泄露数据。
- 资源配额争用
- CPU、内存、网络或第三方 API 配额被并行测试消耗殆尽。
- 测试碰撞(name collision)
- 相同的资源名称(bucket、queue、user id)被不同环境或测试用例复用引发冲突。
- 时间/时序相关竞态
- 定时任务、批处理与测试并发触发,导致结果不确定。
- 环境漂移(环境间差异)
- 不同环境脆弱或配置不一致,导致测试结果不可比对。
理解这些冲突类型能帮助我们有针对性地设计规避手段。
三、核心处理原则
- 隔离而非共享:测试应尽量在隔离的计算与数据域内运行,最小化跨测试耦合。
- 可重复与可回滚:每个环境应能快速创建与销毁,测试前置条件要能以脚本方式恢复到干净状态。
- 契约与界面优先:通过契约测试(契约/contract testing)确保服务间交互兼容,减少跨环境联调失败。
- 最小权限与凭证隔离:测试凭证仅能访问测试数据和服务,避免误触生产。
- 端点可重映射:使用环境映射层(抽象 DNS/路由)以保证同一测试脚本可在不同环境下无改动执行。
- 观测与防护并重:完善监控、限流和熔断策略,实时发现并发冲突与资源耗尽。
这些原则将贯穿下文所有策略与示例。
四、实战策略与实现细节
1) 固定环境 + 临时环境的组合
- 固定环境:dev、int、staging、perf、prod(长期存在,配有稳定资源与监控)。
- 临时/预览环境(Ephemeral):每个 PR/分支自动创建命名空间(例如 Kubernetes Namespace / ephemeral VM / docker-compose),测试完成或 PR 关闭自动销毁。
优点:长期环境用于重度测试与性能基线,临时环境用于隔离验证与并行。
实现提示(Kubernetes):对每个 PR 创建独立 namespace,并通过 Ingress + DNS 映射(如 pr-123.project.test.example.com)暴露服务;资源配额(ResourceQuota)限制单个 namespace 资源占用。
2) 多租户数据库、Schema 分离或 DB 克隆
- 策略 A:单库多 schema / tenant id 隔离
每个环境/测试使用独立 schema 或租户 id,测试前后清理。适合数据库支持 schema(如 Postgres)。 - 策略 B:数据库镜像/克隆
对于承受力强的场景,基于快照克隆数据库(如利用云数据库快照/恢复,或 mysqldump + restore)为每个环境提供干净数据。 - 策略 C:合成、合规化的测试数据
遵守隐私合规,用脱敏 / 合成数据代替真实数据;同时保证数据代表性以维持测试可信度。
实战提示:对 CI 中的短时 ephem env,用轻量级数据库镜像(如导入最小子集),并在 teardown 阶段删除数据。对性能测试使用独立 perf DB,避免影响业务环境。
3) 减少跨环境依赖
- 服务虚拟化(Service virtualization):当某些第三方或内部服务不可用或有配额限制时,用 Wiremock、MockServer 或自建 stub 替代真实服务。
- 契约测试(Contract Testing):使用 Pact / Spring Cloud Contract 等工具让消费方与提供方之间的契约由测试自动验证,避免在多环境联调时出现接口兼容性问题。
契约测试把接口期望作为可执行“测试契约”,在 CI 中验证即可减少跨环境联调次数。
4) 避免冲突
- 命名约定:所有临时资源带上环境/PR 前缀(例如
pr-123-orders-bucket、e2e-user-20251203)。 - UUID 和 并发安全 ID:在自动化中尽量使用 UUID 或基于环境前缀的复合 ID(
{env}-{timestamp}-{random})以避免冲突。 - 租户隔离字段:数据库与缓存键中携带环境标识,避免跨环境读写:
env:pr-123:user:42。
5) 配置与凭证管理
- 环境变量与密钥管理:使用 Secret Manager(HashiCorp Vault、K8s Secret、云 KMS)并严格绑定凭证生命周期到环境。
- 最小权限原则:测试凭证仅能访问测试系统 / 数据,绝不使用生产凭证在测试中。
- 配置模板化(IaC + 变量化):用 Terraform/Helm/chart 将配置参数化,部署时注入对应环境变量,避免手工差错。
6) 资源隔离与配额控制
- 在 Kubernetes 使用
ResourceQuota与LimitRange限制 namespace 资源;在云上对每个测试项目分配独立帐单/配额。 - 对第三方 API 设置速率限制模拟(rate-limited mocks),并在自动化脚本中实现退避(exponential backoff)以避免被封锁。
7) 并发冲突的编程模式
- 幂等设计:服务端 API 设计为幂等(PUT/Idempotency-Key)以便并发请求不会造成不一致。
- 乐观锁 / 悲观锁策略:在对共享资源进行修改时使用版本号或租约机制避免覆盖。
- 外部事务边界:避免跨服务长事务,改为事件驱动并提供补偿逻辑(SAGA pattern)以减少并发冲突。
测试工程师应在测试中验证这些机制(例如并发修改同一资源时是否触发乐观锁异常)。
8) 清理与回收
- 自动 teardown:每个 ephemeral environment 在测试完成或 PR 关闭时自动触发销毁脚本(包括 compute、storage、DNS、secrets)。
- 幂等清理脚本:清理脚本应能多次调用且安全(避免误删),例如只删除带有
pr-123-前缀的资源。 - 过期回收策略(GC):对长期遗留的临时资源启用 TTL(例如 K8s 的 CronJob 执行每晚清理超过 48 小时的 namespace)。
五、自动化示例
示例 1:GitHub Actions 并行创建 Kubernetes Namespace(简化)
name: PR Ephemeral Env
on:
pull_request:
types: [opened, reopened, synchronize, closed]
jobs:
deploy:
if: github.event.action != 'closed'
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Setup kubectl
uses: azure/setup-kubectl@v3
- name: Create Namespace
run: |
NAMESPACE=pr-${{ github.event.number }}
kubectl create namespace $NAMESPACE || echo "namespace exists"
# apply helm chart into namespace with env-specific values
helm upgrade --install app-${{ github.event.number }} ./chart \
--namespace $NAMESPACE \
--set image.tag=${{ github.sha }}
对应关闭 PR 时运行删除 namespace 的 job(on: pull_request types: closed)。
示例 2:Kubernetes Namespace ResourceQuota(避免资源争用)
apiVersion: v1
kind: ResourceQuota
metadata:
name: pr-resource-quota
namespace: pr-123
spec:
hard:
requests.cpu: "2"
requests.memory: 4Gi
limits.cpu: "4"
limits.memory: 8Gi
persistentvolumeclaims: "2"
示例 3:幂等性示例(HTTP Idempotency-Key)
测试中向支付/下单接口发出并发请求时,使用 Idempotency-Key 保证重复请求不会重复扣款:
POST /orders
Headers:
Idempotency-Key: pr-123-20251203-uuid
Body: {...}
服务端在收到相同 Idempotency-Key 时应返回首次请求结果而非重复创建。
六、观测、告警与回归
- 环境标签化监控:指标/日志中携带
env与pr标签(Prometheus/Elastic),方便区分并行测试的影响。 - 资源预警:当某环境资源使用高于阈值(CPU、DB 连接数、API 错误率)时触发告警并自动 throttle 或暂停部分并发测试。
- 测试稳定性仪表盘:记录 flaky test、环境失败率、用例平均耗时等,定位是否由环境冲突造成。
- 审计与安全告警:当测试凭证尝试访问生产资源或跨环境访问发生时触发安全告警并自动回滚凭证。
七、常见误区与防范
- 误区:把生产数据直接用于所有测试 → 危险,需脱敏或合成数据。
- 误区:只靠命名规范不足以避免冲突 → 名称只是第一步,必须配合资源隔离与凭证管理。
- 误区:自动化做完就万事大吉 → 自动化需要持续维护(随系统演化调整契约、脚本与清理逻辑)。
八、结语
多环境并行测试不是简单地多开几台机器,而是把隔离、可重复性、契约、资源治理与观测工程化。正确的设计能在不牺牲稳定性的前提下极大提升交付速度与测试覆盖。实践中要坚持“隔离优先、脚本化、最小权限与可回收”这四条原则,并结合契约测试与服务虚拟化把跨服务依赖风险降到最低。实施路径可分步推进,从 PR 级预览环境、数据隔离到契约测试与观测体系,循序渐进便能把并行测试从危险尝试变成可控的工程能力。



















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











