








随着企业全球化、多语言电商、国际协同SaaS平台的兴起,多语言支持已成为现代应用不可或缺的能力。一个产品通常需要支持中文、英语、阿拉伯语、法语、印地语等十余种语言,同时保持功能一致性、可用性与本地化体验的统一。
然而,多语言测试所面临的挑战远非传统测试方法所能覆盖:
-
用例样本稀疏:中文环境下构建的测试集无法覆盖阿拉伯语等RTL(从右向左)语言的排版与渲染异常。
-
场景语义差异:同一逻辑在不同语言地区可能有不同行为(如货币格式、本地习惯、敏感词)。
-
测试人员局限:测试人员往往只能掌握1~2门语言,难以构造全面的多语言测试数据。
在此背景下,大语言模型(LLM)以其跨语言理解和生成能力,为测试多样性补全提供了前所未有的智能支撑。本文将从测试场景需求出发,深入探讨大模型如何作为“多语言测试多样性生成器”辅助质量保障,并分享可落地的技术路径与挑战反思。
一、多语言测试的多样性缺口
多语言测试的多样性问题,可归纳为以下四类维度:
| 多样性维度 | 问题表现 |
|---|---|
| 语言结构多样性 | 英语(SVO)与日语(SOV)结构差异导致 UI 排版异常 |
| 跨语种语义模糊 | 英文中的“free”在不同上下文中可指“免费”或“自由”,阿拉伯语翻译难以统一 |
| 特定语言功能变异 | 某些国家法律要求特定条款出现在 UI 中,未出现在原始语言测试集 |
| RTL/LTR布局渲染问题 | 从右向左语言(如希伯来语)UI对齐、滑动、导航条常出现缺陷 |
这些问题的共同点是:单语种测试用例难以发现非本地语言下的潜在缺陷,而传统人工测试难以有效补全这些缺口。
二、大模型具备哪些“补全能力”?
1. 跨语言语义对齐能力(Multilingual Alignment)
现代大模型(如 GPT-4、mT5、XGLM、Qwen)已在跨语言语义表示上取得突破。通过统一的语言嵌入空间,模型能够理解:
-
同一功能在多语言下的语义一致性与差异点;
-
翻译过程中潜在的丢失或歧义内容;
-
用户自然语言意图在不同语言中的表达变化。
这为多语言测试中**“测试意图迁移”与“语言一致性验证”**提供了能力基础。
2. 多语言用例生成能力(Test Case Generation)
大模型可在英文测试用例的基础上,生成其他语言版本,包括:
-
UI文案替换与翻译;
-
输入场景构造(如本地地址、姓名、货币格式);
-
语境对话模拟(如客服聊天测试)。
而且,生成可定制,如:
“请生成一组涵盖边界场景的西班牙语测试输入,涉及用户生日字段。”
3. 多语言数据增强能力(Multilingual Data Augmentation)
通过 paraphrasing 和 perturbation,大模型可以扩展已有测试样本的语言变体,例如:
-
生成语义等价的不同说法(如“Reset Password” vs. “Recover my account”);
-
构造典型拼写错误、字符集混用(如拉丁字母与西里尔混写);
-
生成实体多样化测试数据(如中东国家手机号、假名)。
这类生成是高语义保真但语言形式变化大的数据增强手段,对稳健性测试极为重要。
三、如何让大模型成为“测试多样性助手”
1. 架构概览
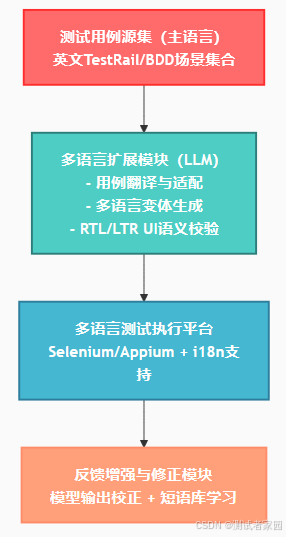
2. 用例生成示例
英文原始用例:
When a user enters an invalid email, an error message should appear.
自动生成阿拉伯语用例(RTL):
عندما يُدخل المستخدم بريدًا إلكترونيًا غير صالح، يجب أن تظهر رسالة خطأ.
附带信息:
-
UI方向建议:text-align: right
-
字符集检查:UTF-8 + Unicode bidi 检测
-
视觉对齐点建议:按钮从右开始布局
四、场景与案例
场景1:电商平台多语言表单测试
-
输入框边界值测试在英语中使用“John Smith”,但在越南语中生成“Nguyễn Văn A”能揭示渲染异常;
-
法语中的“Nom d'utilisateur”字段导致UI错位,中文未触发。
→ 大模型辅助生成不同语种+文化语境的姓名/地址,发现未被覆盖的输入异常。
场景2:客服机器人多语言意图测试
-
英文下“reset my password” → 正常匹配;
-
日语中“パスワードを忘れました” → 模型生成替代表述测试“ログインできません”仍应命中重置意图;
→ 使用大模型生成多语意图 paraphrase 提高NLU鲁棒性。
场景3:RTL语言排版异常发现
-
原UI通过Selenium在阿拉伯语下测试;
-
大模型标注按钮逻辑阅读顺序,发现逻辑操作不一致(如“下一步”出现在错误位置);
→ LLM辅助视觉语义校验提示修复建议。
五、挑战与对策
| 挑战 | 应对策略 |
|---|---|
| 翻译语义偏差或文化误读 | 增强Prompt提示场景上下文,加入语言地域标签 |
| UI字段自动替换时断裂 | 结合i18n配置+测试DOM结构的可适配性检查 |
| 生成内容无法执行或偏离用例意图 | 引入用例校验模型(意图对齐评分)+人工review loop |
| 模型缺乏少数语言能力 | 选用mT5、BLOOMZ等多语训练模型,或蒸馏微调特定语种 |
| 多语测试执行环境复杂 | 利用Docker/i18n测试容器镜像管理语言环境一致性 |
六、大模型如何升级为多语言测试“智能体”
| 智能体角色 | 职责与能力描述 |
|---|---|
| 多语翻译用例生成Agent | 从源语言自动构造多语测试用例及输入 |
| RTL UI对齐检查Agent | 模拟语言阅读顺序,生成语义可视校验任务 |
| 多语言输入扰动生成Agent | 结合文化背景构造边界值、拼写错、口语化表达等输入 |
| 测试反馈对齐Agent | 分析测试报告差异,调整多语用例生成策略 |
这些Agent可基于LangChain等框架实现调用协调,实现真正意义上的“多语种测试知识自动学习与演化”。
结语
大模型使我们得以突破语言界限,将测试从“功能驱动”走向“语义驱动”。未来的测试系统将不再依赖每种语言都手工构造用例,而是通过大模型实现语言间迁移、多样性生成与一致性保障。
在多语言时代,LLM不只是语言处理器,更是软件质量的多语卫士。



















 202
202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











