




 本文介绍SQL语句性能优化的重要性和Oracle执行计划的概念,包括如何查看执行计划及其各字段含义,以及不同类型的表访问方式和索引扫描方式。
本文介绍SQL语句性能优化的重要性和Oracle执行计划的概念,包括如何查看执行计划及其各字段含义,以及不同类型的表访问方式和索引扫描方式。
|
一.编写初衷描述 |
在应有系统开发初期,由于数据库数据较少,对于sql语句各种写法的编写体现不出sql的性能优劣,随着数据的不断增加,出现海量数据,劣质sql与优质sql在执行效率甚至存在百倍差距,可见sql优化的重要性
|
二.Sql语句性能优化 |
1.什么是Oracle执行计划
执行计划是一条查询语句在Oracle中执行过程或者访问路径的描述.
2. 查看Oracle执行计划
1.执行计划常用的列字段解释
基数:返回的结果集行数
字节:执行该步骤后返回的字节数
耗费(cust),CPU耗费:Oracle估计的该步骤的执行成本,用于说明SQL执行的代价,理论上越小越好.
3 看懂Oracle执行计划
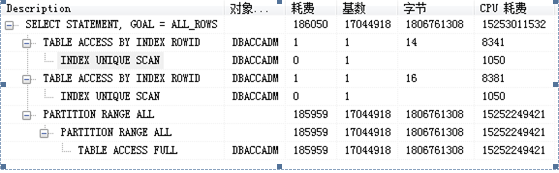
4执行顺序
根据缩进来判断,缩进最多的最先执行(缩进相同时,最上面的最先执行)
5 表的访问方式
- TABLE ACCESS FULL(全表扫描)
- TABLE ACCESS BY ROWID(通过rowid的表存取)
- TABLE ACCESS BY INDEX SCAN(索引扫描)
6 ABLE ACCESS FULL(全表扫描)
Oracle会读取表中的所有行,并检查是否满足where语句中条件;
使用建议:数据量太大的表不建议全表扫描
7 TABLE ACCESS BY ROWID(通过ROWID的表存取)
ROWID的解释:oracle会自动加在表的每一行的最后一列伪列,表中并不会物理存储ROWID的值,一旦一行数据插入后,则其对应的ROWID在该行的生命周期内是唯一的,即使发生行迁移,该行的ROWID值也不变。
8 TABLE ACCESS BY INDEX SCAN(索引扫描)
在索引块中即存储每个索引的键值,也存储具有该键值所对的ROWID.
索引的扫描分两步:首先是找到索引所对的ROWID,其次通过ROWID读取改行数据
索引扫描又分五种:
- INDEX UNIQUE SCAN(索引唯一扫描)
- INDEX RANGE SCAN(索引范围扫描)
- INDEX FULL SCAN(索引全扫描)
- INDEX FAST FULL SCAN(索引快速扫描)
- INDEX SKIP SCAN(索引跳跃扫描)
(a).INDEX UNIQUE SCAN(索引唯一扫描):
针对唯一性索引(UNIQUE INDEX)的扫描,每次至多只返回一条记录,主要针对该字段为主键或者唯一;
(b). INDEX RANGE SCAN(索引范围扫描)
使用一个索引存取多行数据;
发生索引范围扫描的三种情况:
- 在唯一索引列上使用了范围操作符(如:> < <> >= <= between)
- 在组合索引上,只使用部分列进行查询(查询时必须包含前导列,否则会走全表扫描)
- 对非唯一索引列上进行的任何查询
(c). INDEX FULL SCAN(索引全扫描)
- 进行全索引扫描时,查询出的数据都必须从索引中可以直接得到
(d). INDEX FAST FULL SCAN(索引快速扫描)
- 扫描索引中的所有的数据块,与 INDEX FULL SCAN 类似,但是一个显著的区别是它不对查询出的数据进行排序(即数据不是以排序顺序被返回)
(e). INDEX SKIP SCAN(索引跳跃扫描):
Oracle 9i后提供,有时候复合索引的前导列(索引包含的第一列)没有在查询语句中出现,oralce也会使用该复合索引,这时候就使用的INDEX SKIP SCAN;
当Oracle发现前导列的唯一值个数很少时,会将每个唯一值都作为常规扫描的入口,在此基础上做一次查找,最后合并这些查询;
例如:
假设表emp有ename(雇员名称)、job(职位名)、sex(性别)三个字段,并且建立了如 create index idx_emp on emp (sex, ename, job) 的复合索引;
因为性别只有 '男' 和 '女' 两个值,所以为了提高索引的利用率,Oracle可将这个复合索引拆成 ('男', ename, job),('女', ename, job) 这两个复合索引;
当查询 select * from emp where job = 'Programmer' 时,该查询发出后:
Oracle先进入sex为'男'的入口,这时候使用到了 ('男', ename, job) 这条复合索引,查找 job = 'Programmer' 的条目;
再进入sex为'女'的入口,这时候使用到了 ('女', ename, job) 这条复合索引,查找 job = 'Programmer' 的条目;
最后合并查询到的来自两个入口的结果集。

















 1286
1286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









