







在行业周期性调整的浪潮中,谁能提前洞察风险,谁就能更好地行稳致远。
作者Toby,来源公众号:Python风控模型,基于机器学习的房地产企业债务风险预测模型
一、引言:当“高杠杆”遇上“黑天鹅”
近年来,部分头部房地产企业的债务危机如同多米诺骨牌般接连爆发,不仅震撼了整个行业,也让投资者、金融机构乃至产业链上下游都措手不及。传统的信用评级和财务分析模型,往往依赖于静态的财务比率和历史数据,在风险加速暴露时显得“慢半拍”。
我们能否更早、更精准地预见风险?答案是肯定的。随着大数据与人工智能技术的发展,基于机器学习的债务风险预测模型,正成为穿透财报迷雾、预警潜在“雷暴”的利器。

二、为什么传统方法“失灵”了?
在深入探讨新模型之前,我们先看看传统分析的局限:
-
滞后性:财务报告按季度或年度发布,信息滞后,无法捕捉实时风险。
-
片面性:依赖少数几个财务比率(如资产负债率、流动比率),难以综合反映企业复杂的真实状况。
-
线性局限:传统统计模型假设变量间为线性关系,但企业风险的形成往往是多因素非线性交织的结果。
-
难以识别“伪装”:企业可能通过财技在短期内美化报表,欺骗传统指标。
-
困难性:Toby老师也尝试过期刊论文热度高的kmv模型,实际预测效果和真实情况有很大差距,预测能力不佳。
三、机器学习模型:一位“不知疲倦的超级分析师”
机器学习模型能够从海量数据中自动学习规律,并做出预测。将其应用于房地产企业的债务风险预测,优势显著:
-
多维度数据融合:它不仅看财报,还能整合股权市场数据(如股价波动率、市值)、宏观数据(如利率、房价指数)甚至文本数据(如年报中的管理层讨论、新闻舆情),构建一个全息风险视图。
-
捕捉复杂非线性关系:模型能够发现那些人类分析师难以直观发现的复杂特征交互,比如“现金比率下降同时伴随融资性现金流急剧收缩”可能比单一指标更能预示风险。
-
动态与实时预测:一旦模型训练完成,它可以对新流入的数据进行即时分析,实现月度甚至周度的动态风险评估。
-
强大的模式识别能力:通过分析成百上千家企业的历史数据,模型能精准学习到从“健康”到“违约”的演变模式,从而对高风险企业进行“精准画像”。
四、模型是如何构建的?
第一步:收集数据
我方数据来源国内核心商业数据库,均为真实上市房地产企业财务数据。如下图包括万科A,深振业A,ST全新,深物业A,沙河股份,深深房A,大悦城,华联控股,中洲控股,华侨城A,金融街,渝开发,荣安地产,中绿电,莱茵体育,我爱我家,粤宏远A,阳光股份,ST美谷,*ST新联,顺发恒业,金科股份,荣丰控股,苏宁环球,新能泰山,中交地产,中国武夷,财信发展,三湘印象,海南高速,津滨发展,ST数源,福星股份,中南建设,天保基建,招商积余,招商蛇口,世荣兆业,广宇集团,荣盛发展,合肥城建,滨江集团,世联行,南国置业,南山控股,国创高新,新大正,万科B,深物业B,深深房B,特发服务,中国国贸,保利发展,南京高科,冠城大通,大名城,大龙地产,香江控股,卧龙地产,格力地产,新湖中宝,派斯林,福瑞达,卓朗科技,云南城投,万通发展,城建发展,津投城开,华发股份,华夏幸福,首开股份,金地集团,华丽家族,黑牡丹,海南机场,栖霞建设,迪马股份,市北高新,光大嘉宝,新黄浦,浦东金桥,万业企业,城投控股,信达地产,电子城,陆家嘴,天地源,中华企业,京投发展,珠江股份,亚通股份,光明地产,凤凰股份,苏州高新,华远地产,上实发展,西藏城投,京能置业,济南高新,ST世茂,上海临港,张江高科,新城控股,中新集团,北辰实业,南都物业,市北B股,金桥B股,临港B股,陆家B股,大名城B,凌云B股,它们共同构成了行业发展的中坚力量。

数据集包含30多个企业财务变量,变量分类汇总如下
1. 基础标识信息
这类变量用于唯一标识数据的主体、时间和来源。
-
股票代码 -
股票简称 -
统计截止日期:该条财务数据对应的具体日期。 -
报表类型编码:如年报、季报等。 -
行业代码 -
行业名称 -
公告来源:数据出自何处。
2. 流动性风险指标(短期偿债能力)
这类指标衡量企业偿还短期债务的能力,关注资产的变现速度和流动性。
-
流动比率:最通用的短期偿债能力指标。 -
速动比率:更严格的流动性测试,剔除存货。 -
保守速动比率:最保守的流动性指标,通常只包含现金、短期投资和应收账款。 -
现金比率:直接衡量企业用现金及等价物覆盖短期负债的能力。 -
营运资金:营运资本绝对值,反映短期财务安全性。 -
营运资金与借款比:反映营运资本对借款的保障程度。 -
经营活动产生的现金流量净额/流动负债:核心指标,反映企业用主营业务产生的现金偿还短期债务的能力。
3. 杠杆风险指标(资本结构与长期偿债能力)
这类指标衡量企业的负债水平、财务杠杆以及对长期债务的保障能力。
-
资产负债率:总资产中通过负债融资的比例。 -
有形资产负债率:更稳健的资产负债率,剔除无形资产等不易变现的资产。 -
权益乘数&权益乘数2:反映由股东权益放大获取总资产的倍数,是杠杆的另一种表达。 -
产权比率(通常为负债/权益):直接反映债权资本与股权资本的关系。 -
权益对负债比率:股东权益对总负债的覆盖程度。 -
负债与权益市价比率:引入市场价值,反映市场对企业杠杆的评估。 -
有形净值债务率:负债与有形净值的比率,更保守。 -
长期借款与总资产比:资产结构中长期借款的占比。 -
有形资产带息债务比:核心指标,反映有形资产对带息债务的抵押保障能力。
4. 现金流保障指标
这类指标聚焦于企业的现金流对其债务和固定支出的覆盖能力,是评估信用风险的核心。
-
利息保障倍数A&利息保障倍数B:通常基于息税前利润,反映利润对利息的覆盖。 -
现金流利息保障倍数:更可靠的指标,用实际现金流入覆盖利息支出。 -
现金流到期债务保障倍数:现金流对即将到期债务的保障。 -
固定支出偿付倍数:覆盖范围更广,包括利息、租金、本金等所有固定支出。 -
经营活动产生的现金流量净额/负债合计:反映用年经营现金流偿还全部债务所需的大致年数。 -
经营活动产生的现金流量净额/带息债务:核心指标,直接反映主营业务现金流对有偿债务的保障。 -
息税折旧摊销前利润/负债合计:反映用 EBITDA 偿还全部债务的能力。
5. 长期结构与资产配置指标
这类指标分析企业的长期资本结构、债务期限配置以及长期投资效率。
-
长期资本负债率:长期资本中,长期负债所占的比例。 -
长期负债权益比率:长期负债与股东权益的对比。 -
长期债务与营运资金比率:衡量长期负债用于支撑营运资本的程度,过高可能意味着“短债长投”的错配风险。
6. 冗余或高度相关指标
这类指标与上述类别中的其他指标在含义上高度重叠或可由其他指标推导得出,在建模时需注意防止多重共线性。
-
保守速动比率:与速动比率高度相关,但计算口径更严。 -
产权比率:与权益乘数和资产负债率可相互推导。 -
权益对负债比率:是产权比率的倒数。 -
权益乘数2:可能与权益乘数是同一指标的不同版本或计算口径略有差异。 -
有形净值债务率:与有形资产负债率在概念上非常接近。
构建一个有效的机器学习预测模型,通常遵循以下核心步骤:
第二步:定义“风险”标签
我们需要明确告诉模型什么是“风险”。通常,我们将企业未来12个月内是否发生债券实质性违约、重大债务重组或申请破产作为二分类标签(1=高风险,0=低风险)。
第三步:选择与训练算法
我们将历史数据(包含特征和标签)输入算法进行训练。常用的算法包括:
-
逻辑回归:基础且可解释性强,作为基准模型。
-
随机森林:能有效处理非线性关系,抗过拟合能力强。
-
梯度提升树:如XGBoost、LightGBM,在各类数据科学竞赛中表现优异,预测精度高。
-
支持向量机:在高维空间中寻找最优分类边界。
第四步:模型验证与部署
使用未参与训练的“测试集”来评估模型性能。关键评估指标包括:准确率、精确率、召回率,尤其是AUC值(模型区分高风险与低风险企业的能力)。性能达标后,即可部署,对新的企业数据进行滚动预测。
五、案例:预警某爆雷房企
以某知名爆雷房企H为例。在公开违约事件发生前的一年半,我们的机器学习模型就已将其风险评分持续调升至“高危”区间。
模型驱动这一判断的关键因素并非仅仅是高企的资产负债率,更关键的信号包括:
-
经营性现金流持续为负,但投资性现金流依然巨额流出,表明“造血”能力枯竭而扩张仍未停止。
-
现金比率急剧恶化,同时短期有息债务占比过高,显示流动性危机一触即发。
-
股价波动率显著高于行业平均,市场用脚投票,反映了强烈的悲观预期。
这些信号交织在一起,构成了一个清晰的“高风险”模式,被机器学习模型成功捕捉。
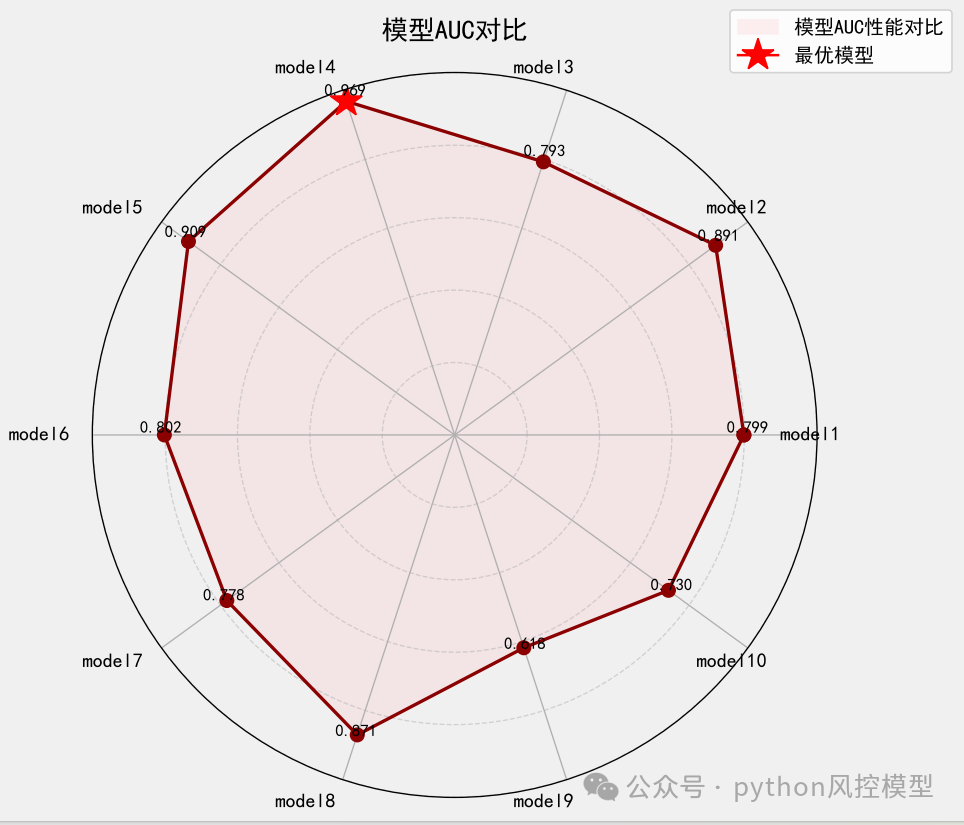
模型性能
多头借贷模型AUC高于0.8,这只是初步实验结果,通过多算法比较,调参,变量筛选,模型性能还有提升空间。
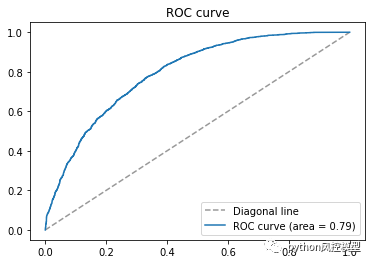
ks大于0.4,模型区分好坏客户能力良好。

数据案例可用于建立华丽模型,发布论文专利,政府企业科研立项
数据案例可用于建立华丽模型,发布论文专利。
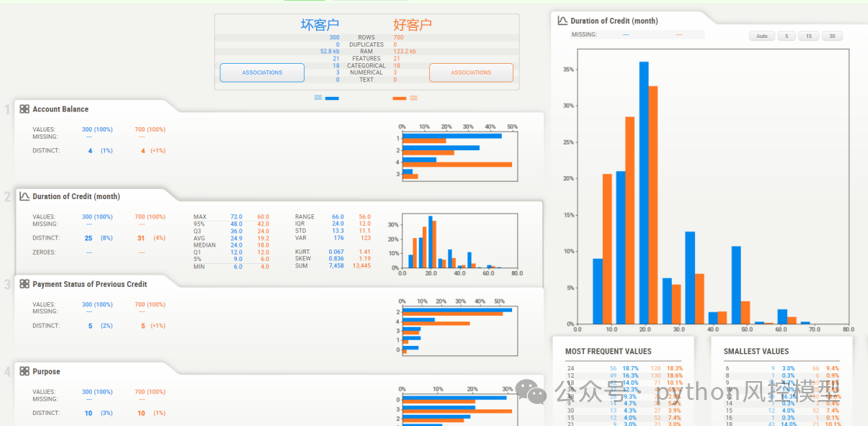
(模型自动化EDA统计图)
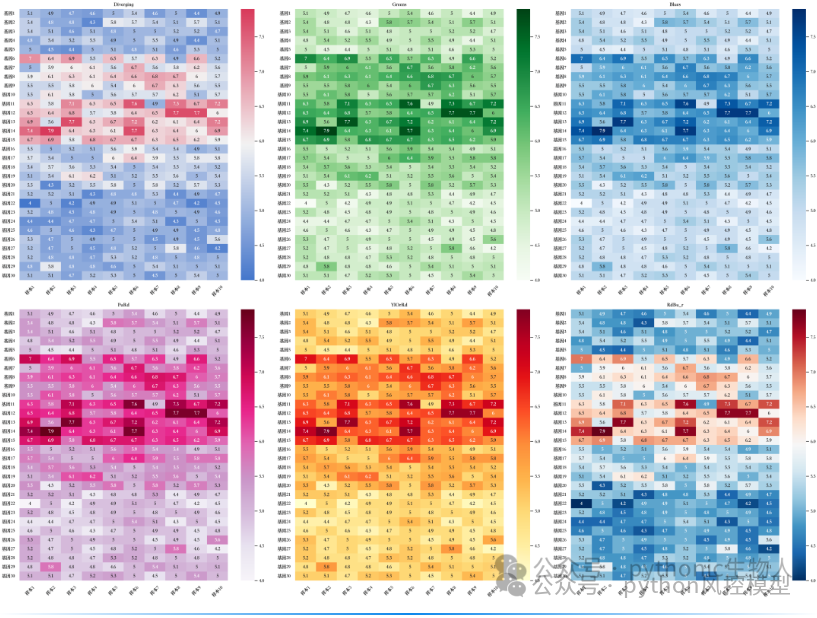
(热力图可视化)
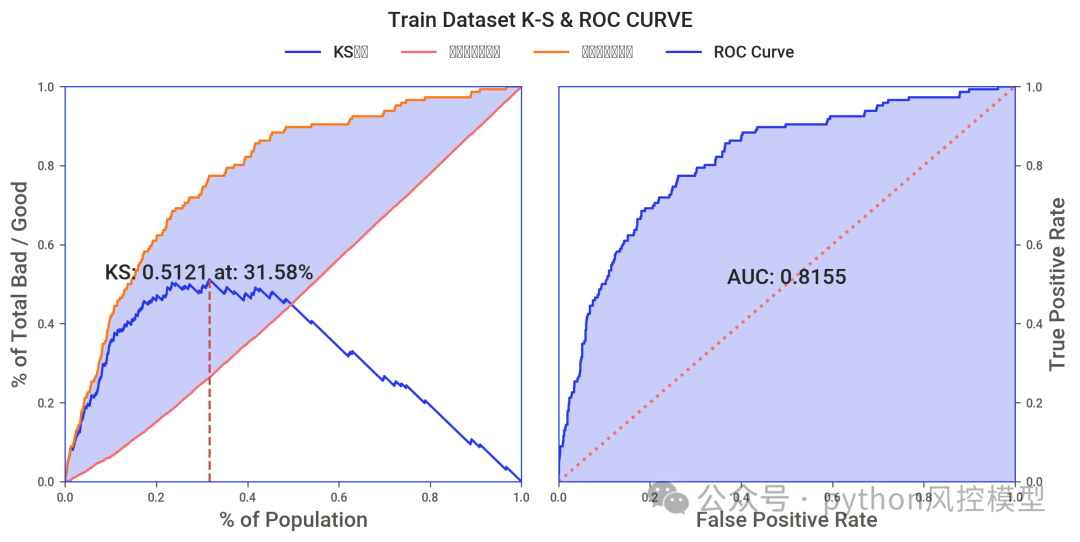
(KS和AUC,模型区分能力指标)
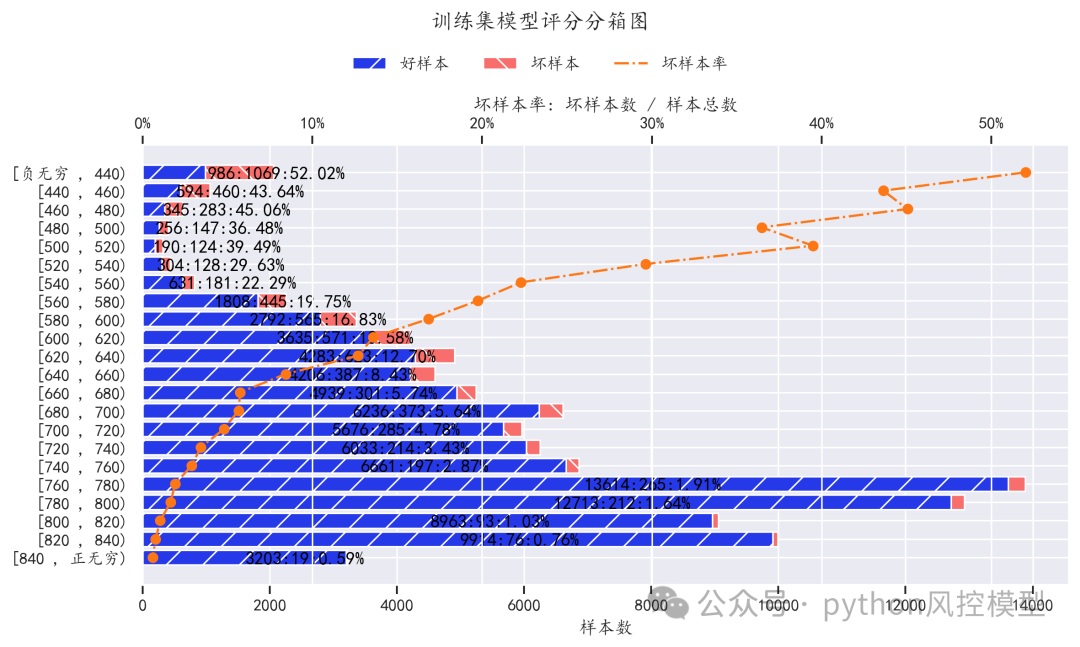
(评分分箱图)
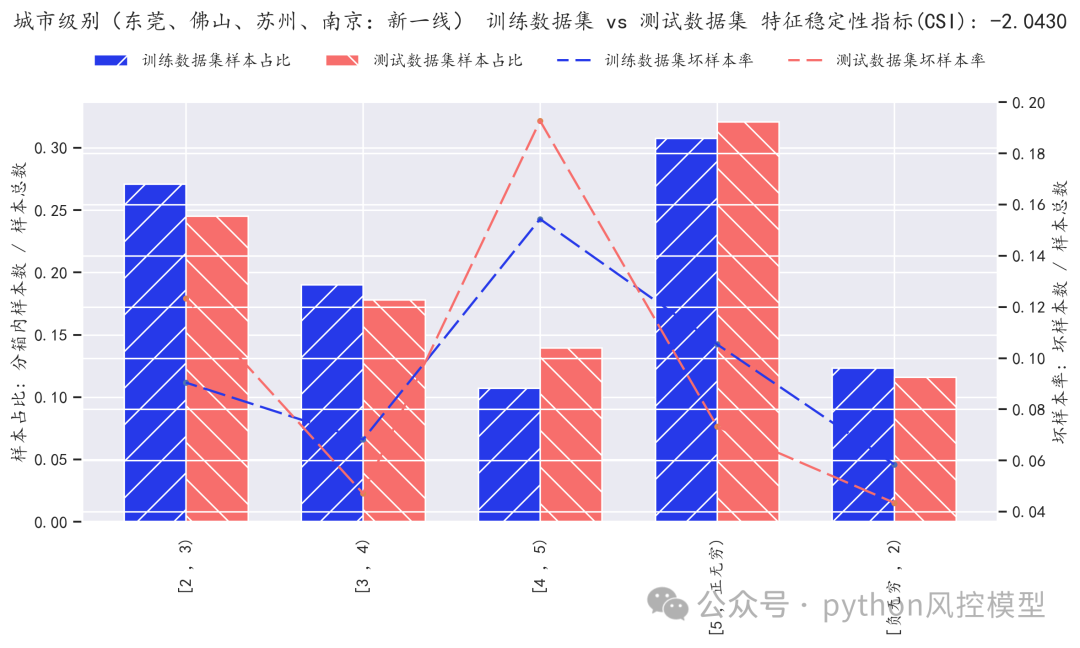
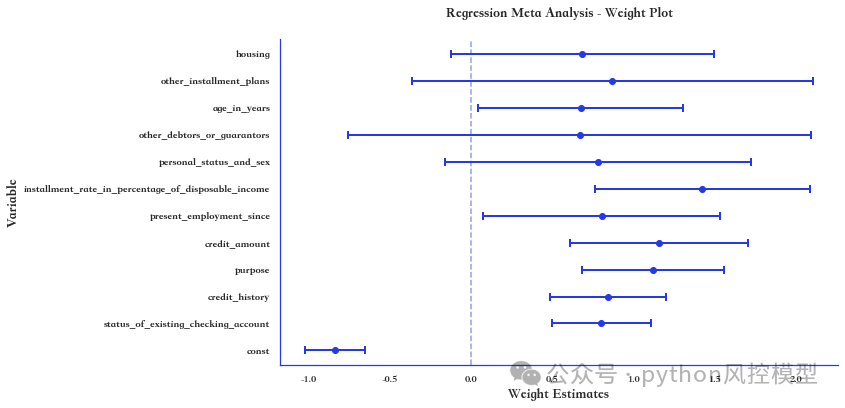
(变量系数稳定性)
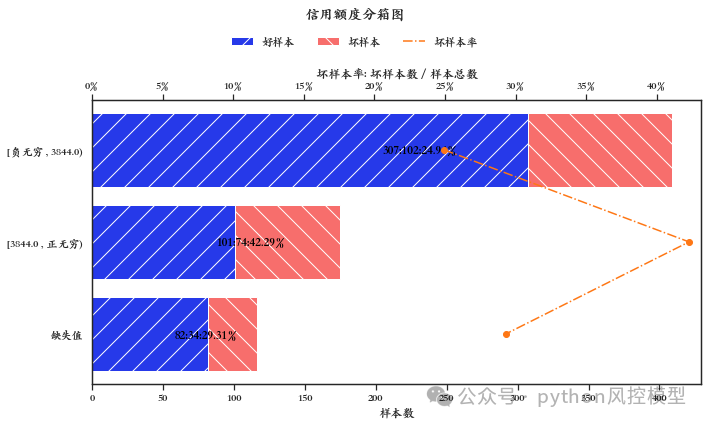
(信用额度分箱)
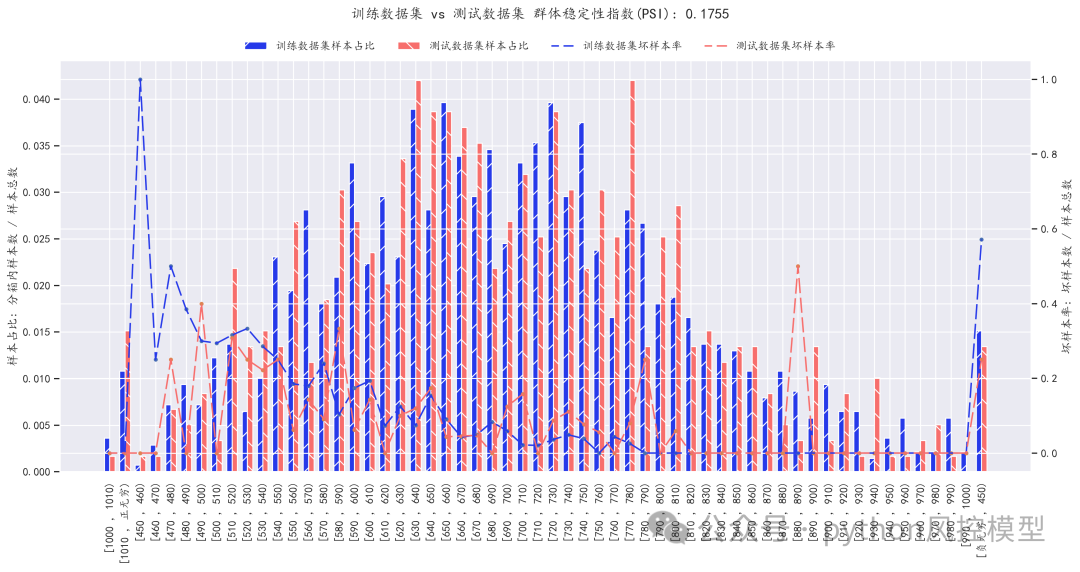
(PSI模型稳定性测评)

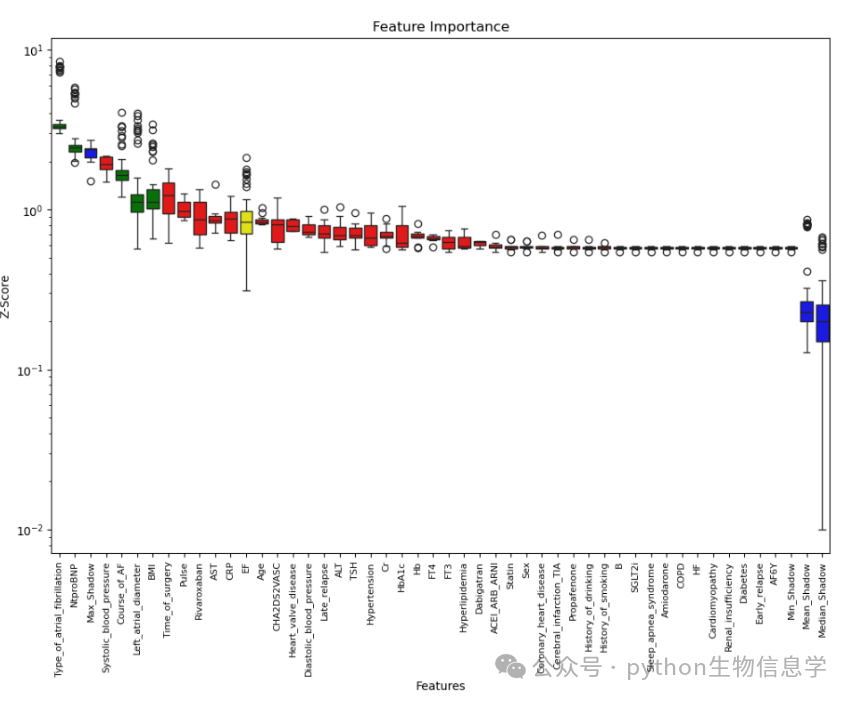
(变量重要性可视化)
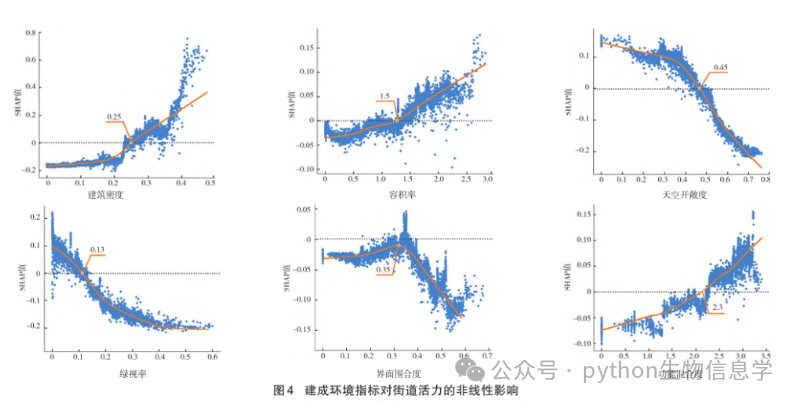

对各省多头借贷数量可视化统计

六、结语:人机协同,决策未来
机器学习模型并非要取代人类分析师,而是成为一个强大的决策支持工具。它能从繁杂的数据中提炼出核心风险信号,让分析师能够聚焦于更深层次的定性研究(如公司治理、战略方向)。
在不确定性成为新常态的今天,拥抱数据智能,构建更敏锐的风险预警系统,对于投资者规避损失、金融机构加强风控、企业自身防范经营风险,都具有至关重要的意义。


















 2396
2396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









