




 本文介绍了在Spark SQL中如何利用stack函数将数据列转换为行,以满足在数据不足时补充默认值(如0)的需求。通过一个实际例子展示了如何处理客户近6个月的数据,确保每个月都有记录,缺失月份的金额填充为0。
本文介绍了在Spark SQL中如何利用stack函数将数据列转换为行,以满足在数据不足时补充默认值(如0)的需求。通过一个实际例子展示了如何处理客户近6个月的数据,确保每个月都有记录,缺失月份的金额填充为0。
Spark.sql 列转行方法之stack函数用法
一个小需求:在hive表中取每个客户近6个月月底的三个字段:cust_id(客户id)、par_dt(分区时间)、money(金额),若客户只有近3个月的记录,则需要另外补充数据,金额为0。
因为spark中df只能增加列,而不能增加行记录,故补充默认值需要进行列转行,使用stack内置函数。
好,废话不多说,进行代码Demo演示。
Object TestDev extends LazyLogging{
def main(args: Array[String]):Unit = {
val spark = SparkSession
.builder()
.appName("test_Dev")
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
.enableHiveSupport()
.getOrCreate()
//添加隐式转换
import spark.implicits._
//使用序列创建一个dataFrame
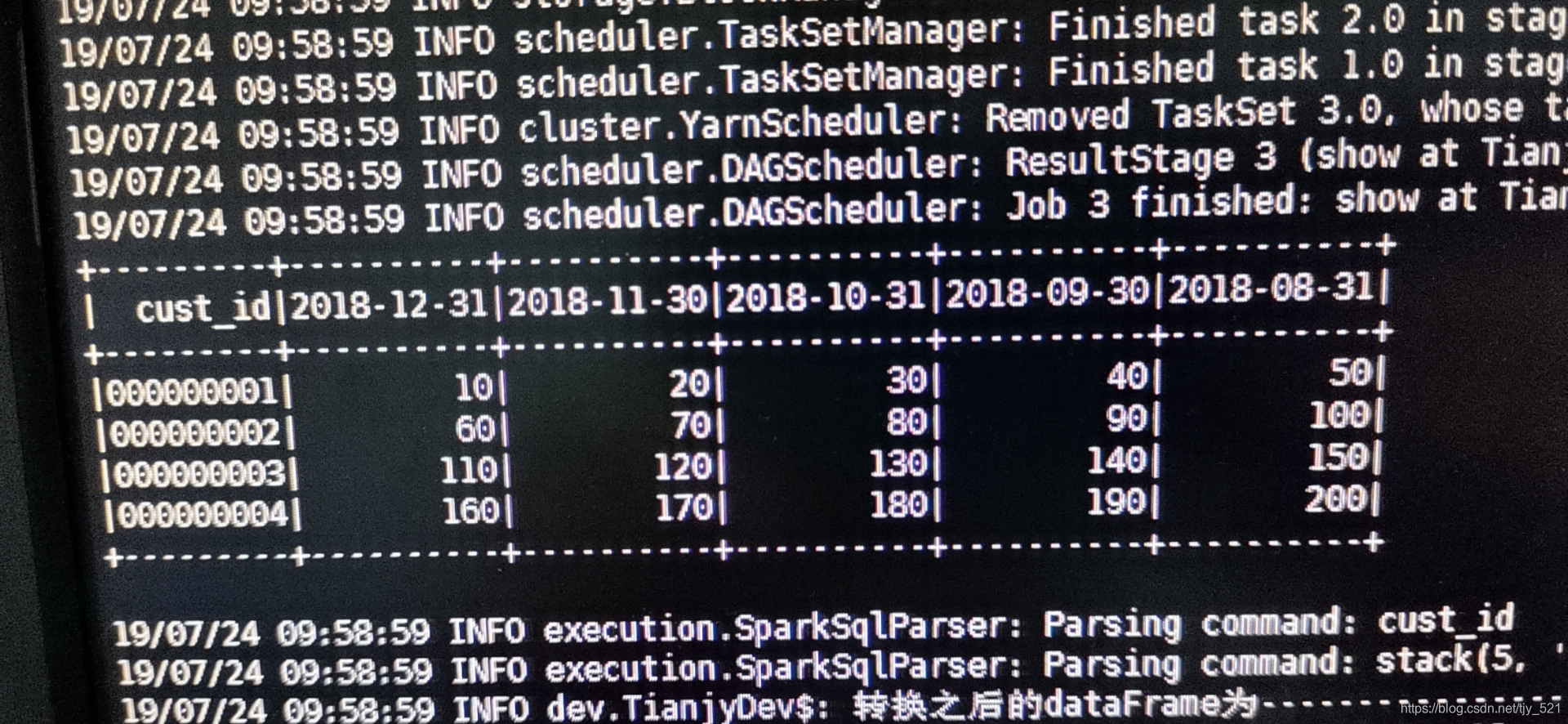
val df = spark.sparkContext.parallelize(Seq(
("000000001", 10, 20, 30, 40, 50),
("000000002", 60, 70, 80, 90, 100),
("000000003", 110, 120, 130, 140, 150),
("000000004", 160, 170, 180, 190, 200)
)).toDF("cust_id", "2018-12-31", "2018-11-30", "2018-10-31", "2018-09-30","2018-08-31")
logger.info("未转换之前的dataFrame为----------------------------------------")
df.show()
//注意stack(n,exp1...expn) n:需要转换几列,``符号不可省略
val df_convert = df.selectExpr("cust_id",
"stack(5, '2018-12-31',`2018-12-31`,'2018-11-30',`2018-11-30`,'2018-10-31', `2018-10-31`,'2018-09-30',`2018-09-30`,'2018-08-31',`2018-08-31`) as (stat_dt, aum)")
.orderBy("stat_dt")
logger.info("转换之后的dataFrame为------------------------------------------")
df_convert.show()
spark.stop()
}
}
结果截图:
转换前的df--------------------
转换后的df--------------------
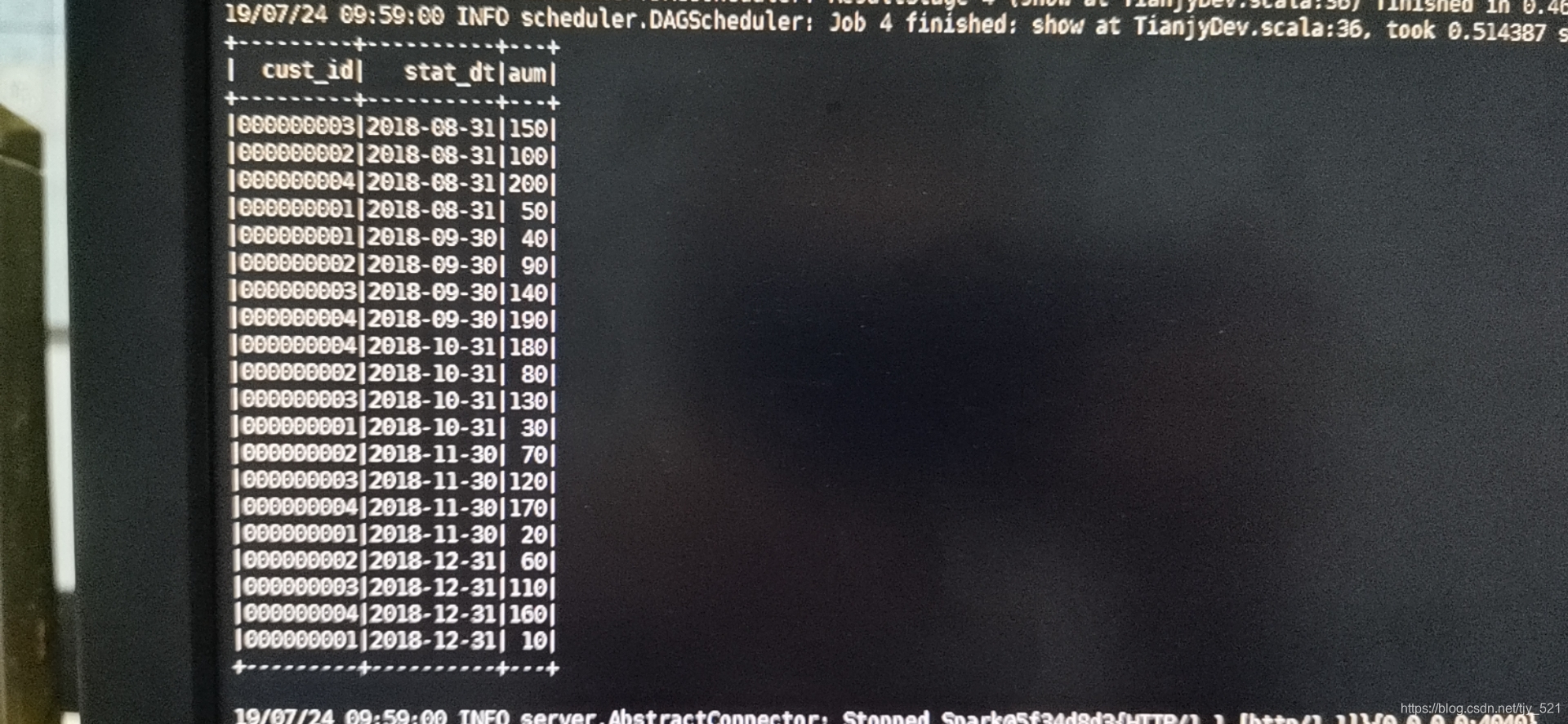
通过这个方式,我们就可以为df增加行数据了。

















 5471
5471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









