




现在我们来详细说明一下正则表达式中的特殊元字符到底能完成哪些复杂的匹配功能。
1.单个字符匹配
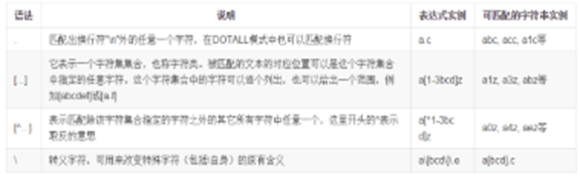
说明: 所有的特殊字符在[ ]内都将失去其原有的特殊含义:
有些特殊字符在[ ]中被赋予新的特殊含义,如 ‘^‘出现在[ ]中的开始位置表示取反,它出现在[]中的其他位置表示其本身(变成了一个普通字符);
有些特殊字符则变为普通字符,如 ‘.’, ‘*’, ‘+’, ‘?’, ‘$’
有的普通字符变为特殊字符,如 ‘-’ 在[ ]中的位置不是第一个字符则表示一个数字或字母区间,如果在[ ]中的位置是第一个字符则表示其本身(一个普通字符)
在[ ]中,如果要使用’-’, ‘^’ 或’]’,可在在它们前面加上反斜杠,或把’-’, ']‘放在第一个字符的 位置,把’^'放在非第一个字符的位置。
2. 预定义字符集
我们可以在反斜杠后面跟上一个指定的字母来表示预定义的字符集合
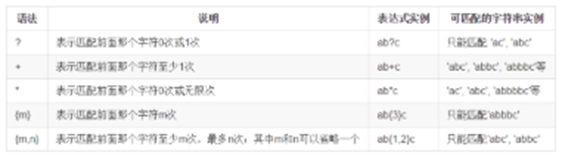
3. 字符次数匹配–量词
在正则表达式中,我们还可以指定匹配某个字符出现次数
说明: {m,n}中的m和n可以省略其中一个,{,n}相当于{0,n},{m,}相当于{m,整数最大值}。
我们可以得出以下结论:
{0,1}或{,1} 等价于 ?
{1,} 等价于 +
{0,} 等价于 *
我们优先选择使用 ?, + 和 *,因为他们书写简单,也可以使整个正则表达式变得简洁。
说明: ? 这个字符在正则表达中与 ?, +, *, {m,n}连用时还有一个额外的功能,就是将匹配模式由贪婪模式(尽可能的增加匹配次数) 变成 非贪婪模式(尽可能减少匹配次数), 这个会在下面的内容中进行详细说明。
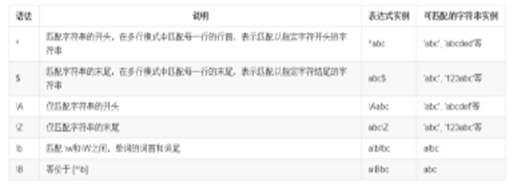
4. 边界匹配
正则表达式中还可以对边界位置进行匹配,如一个字符串的开头或结尾,一个单词的开头或结尾。

5. 逻辑与分组
语法 | 说明 | 表达式实例 | 可匹配到的字符串实例

6. 特殊构造

说明: 上面所说的“不消耗字符串内容”是指只是进行匹配,但是不移动原始字符串的匹配位置,这样就可以完成多次匹配。下面有个匹配密码的正则表达式实例,就是用这个特性巧妙完成的。

















 1133
1133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









