



1.JAVA主流的AI开发框架
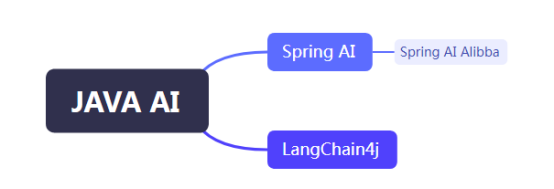 Spring AI并没有国内相关大模型的接入,对国内开发者不友好。基于Spring AI,阿里巴巴于2024年9月推出了Spring AI Alibba开源框架,专为接入阿里云系的百炼大模型、通义系列大模型设计。LangChain4j几乎支撑所有国内外主流的AI大模型,并且提供了统一的API,这意味着开发者无需学习每个API的细节,可以轻松切换不同的模型和存储,而无需重写代码。
Spring AI并没有国内相关大模型的接入,对国内开发者不友好。基于Spring AI,阿里巴巴于2024年9月推出了Spring AI Alibba开源框架,专为接入阿里云系的百炼大模型、通义系列大模型设计。LangChain4j几乎支撑所有国内外主流的AI大模型,并且提供了统一的API,这意味着开发者无需学习每个API的细节,可以轻松切换不同的模型和存储,而无需重写代码。
2.LangChain4j是什么
LangChain4j是一个专为Java开发者设计的开源库,旨在简化大型语言模型(LLM)与Java应用程序的集成过程。 LangChain原本仅支持Python和JavaScript语言,而LangChain4j则是其Java版本。
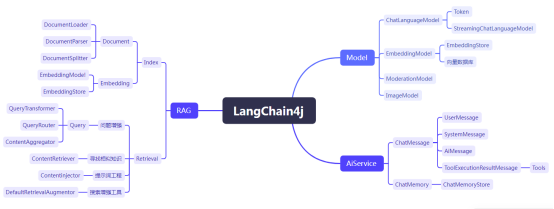
3.LangChain4j知识树
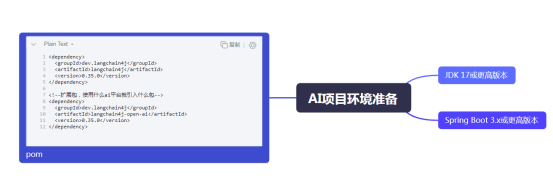
4.AI项目环境要求
5.Ollama安装步骤
第一:拉取 Ollama 镜像
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/ollama/ollama:latest
官方镜像源太慢,使用到华为云的镜像源
第二:运行 Ollama 容器
拉取镜像成功后,你可以使用以下命令来运行 Ollama 容器
docker run -d -p 11434:8080 -v ollama_data:/root/.ollama --name ollama_deepseek ollama/ollama
这里的参数解释如下:
-d:以守护进程模式运行容器。
-p 11434:8080:将容器的 8080 端口映射到主机的 11434 端口。
-v ollama_data:/root/.ollama:创建一个名为 ollama_data 的卷,并将其挂载到容器的 /root/.ollama 目录。这将用于存储 Ollama 的数据和配置。
--name ollama_deepseek:为容器指定一个名称(在这里是 ollama_deepseek)
第三:验证Ollama安装
打开浏览器,访问 http://localhost:11434(或者你在 -p 参数中指定的其他端口)。如果看到 Ollama 的界面,则表示安装成功。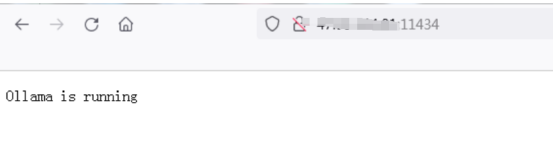
6.DeepSeek安装
第一:登录ollama官网
第二:点击Models菜单,找到deepSeek
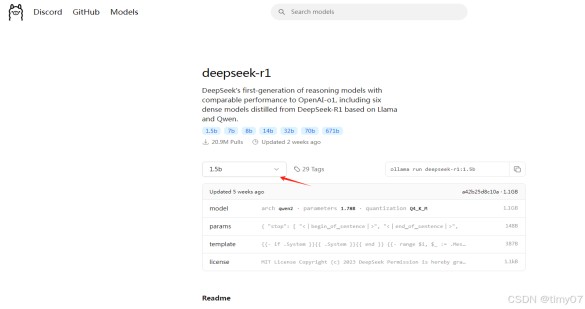
第三:点击deepSeek,选择1.5b版本
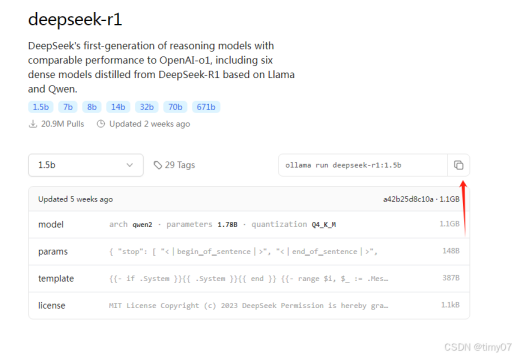
第四:复制deepSeek安装命令
第五:登录安装并运行了Ollama的linux机子,执行上一步复制的安装命令
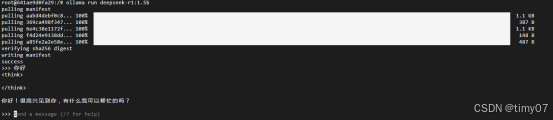
安装成功,看到success后,随便输入一个句话,deepSeek有响应,即表示安装成功
deepSeek 1.5B版本仅做学习使用,企业使用推荐安装7B/8B模型。
deepSeek每个版本推荐的服务器配置如下图
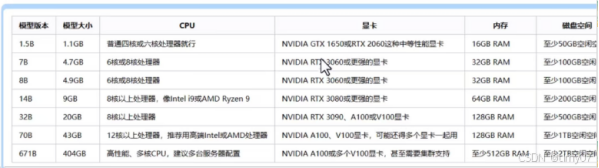
deepSeek版本号,例如 1.5B、7B、8B.....有什么含义
DeepSeek的命名规则中,如1.5B、7B、8B、14B、32B、70B、671B等,这些数字代表模型的参数量(Parameters),单位为十亿(Billion)。具体来说:
1.5B代表模型拥有15亿参数。
7B代表模型拥有70亿参数。
8B代表模型拥有80亿参数。
14B代表模型拥有140亿参数。
32B代表模型拥有320亿参数。
70B代表模型拥有700亿参数。
671B代表模型拥有6710亿参数。
参数规模直接反映模型的复杂度和学习能力。通常,参数越多,模型对复杂模式的捕捉能力越强,但同时对硬件资源的需求也越高。不同参数规模的DeepSeek模型适用于不同的应用场景:
1.5B和7B版本的模型属于轻量级模型,低资源消耗,响应速度快,适合基础任务,如移动端应用(如手机助手)、实时客服、简单文本生成等。
8B版本在处理复杂自然语言理解任务方面表现更优。
14B和32B版本的模型属于平衡型模型,适合高质量内容生成、复杂问答系统、多模态任务等。
70B和671B版本的模型参数规模庞大,适合前沿研究、高精度工业应用等需要顶尖性能的场景。
7.AI之旅的第一个示例
public class TextChat {
public static void main(String[] strings){
ChatLanguageModel model = OllamaChatModel.builder()
.baseUrl("http://localhost:11434/")
.temperature(0.0)
.logRequests(true)
.logResponses(true)
.modelName("deepseek-r1:1.5b")
.build();
String answer = model.generate("你好,我是timy");
System.out.println(answer);
}
}7.1.LangChain4j目前支持的模型类型列表
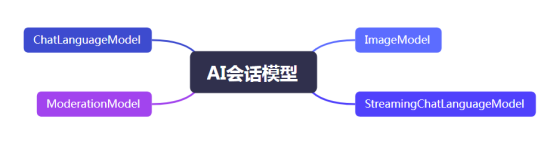
ChatLanguageModel:语言处理模型,能够是计算机能够理解用户输入的信息,并生成响应。
StreamingChatLanguageModel:流式模型,能够清楚的获取输入、输出的token信息,经常被用于成本控制。
ModerationModel:温和模型,被用于用户输入敏感字过滤
ImageModel:文生图模型
ModerationModel模型使用示例
public class ModerationModelDemo {
public static void main(String[] strings){
ModerationModel model = OpenAiModerationModel.builder()
.apiKey("demo")
.modelName("gpt-4o-mini")
.build();
Response<Moderation> answer = model.moderate("杀人偿命,欠债还钱");
System.out.println(answer.content().flaggedText());
}
}7.2. Token概念
Token AI计费单位。具体个分词器相关,他可能是一个字,也可能是一个词。Stream 流式方式可以知道输入、输出的token信息,达到控制成本的目的。
public class TokenStream {
public static void main(String[] strings){
StreamingChatLanguageModel model = ChatLanguageModelFactory.getOllamaStreamingChatModel();
model.generate("你好,我是timy", new StreamingResponseHandler<AiMessage>() {
@Override
public void onNext(String s) {
System.out.println("token "+s);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
System.out.println("InterruptedException "+e.getMessage());
}
}
@Override
public void onError(Throwable throwable) {
System.out.println("InterruptedException "+throwable);
}
});
}
}7.3.ChatMessage 的四种消息类型
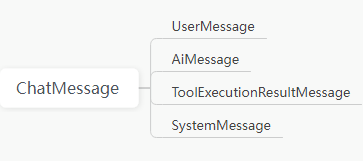
UserMessage:用户发给Ai的消息
AiMessage:Ai生成的返回的消息
SystemMessage:系统消息,就是对用户消息的一些包装。例如我问AI一个问题“实现二叉树前序遍历算法并输出java示例代码”,SystemMessage 可以包装为“你是一位资深的java 程序,请实现二叉树前序遍历算法并输出java示例代码”,明确AI的角色。及提示工程。
Toolexecutuonresultmessage:工具消息,专用来为AI系统提供一些AI无法回答的信息。
8.AI 会话
AI会话是指通过自然语言处理(NLP)技术,使计算机能够与人类进行自然、流畅的对话交流。
public class AIChatContextDemo {
public static void main(String[] strings){
ChatLanguageModel model = ChatLanguageModelFactory.getOllamaChatModle();
UserMessage userMessage1 = UserMessage.from("一加一等于几");
Response<AiMessage> aiMessageResponse1= model.generate(userMessage1);
AiMessage aiMessage1 = aiMessageResponse1.content();
System.out.println(aiMessage1.text());
UserMessage userMessage2 = UserMessage.from("请重复一次");
/*多个mess绑定在一起,达到让ai记住上下文目的*/
Response<AiMessage> aiMessageResponse2= model.generate(userMessage1,aiMessage1,userMessage2);
AiMessage aiMessage2 = aiMessageResponse2.content();
System.out.println(aiMessage2.text());
}
}这将导致,会话次数越多,后面会后的历史信息记录越多,编码越是复杂。Chatmemory就能解决这一问题,能自己把所有交互记录都记住,从而完成多轮会话。
8.1.ChatMemory
ChatMemory是一个内存管理容器,用于存储和管理多轮对话中的ChatMessage。它不仅允许开发者保存消息,还提供了以下几种功能:消息驱逐策略、持久化存储、特殊消息处理(如系统消息和工具执行消息)等。
MessageWindowChatMemory:根据消息记录条数存储,采用FIFO策略驱逐历史消息
TokenWindowChatMemory:根据token数量驱逐历史消息
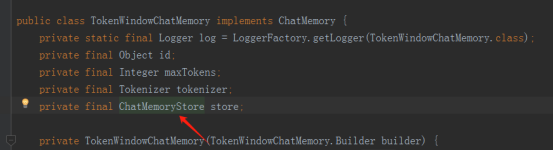
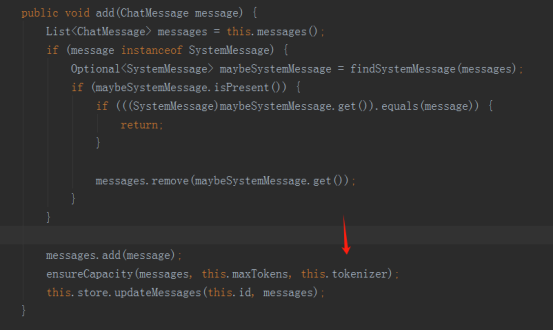 TokenWindowChatMemory 在加入消息是,需要传一个tokenizer( token分析器),每个AI平台的分词器不一样,同一个AI平台不同版本分词器也不一样,正式环境的分词器要与实际使用为准。
TokenWindowChatMemory 在加入消息是,需要传一个tokenizer( token分析器),每个AI平台的分词器不一样,同一个AI平台不同版本分词器也不一样,正式环境的分词器要与实际使用为准。
public class ChatMemoryTest {
public static void main(String[] strings){
ChatLanguageModel model = ChatLanguageModelFactory.getOllamaChatModle();
// TokenWindowChatMemory
ChatMemory chatMemory = MessageWindowChatMemory.builder()
.maxMessages(10)
.build();
chatMemory.add(UserMessage.from("一加一等于几"));
AiMessage aiMessage1= model.generate(chatMemory.messages()).content();
System.out.println(aiMessage1.text());
chatMemory.add(aiMessage1);
chatMemory.add(UserMessage.from("请重复一次"));
AiMessage aiMessage2= model.generate(chatMemory.messages()).content();
System.out.println(aiMessage2.text());
chatMemory.clear();
}
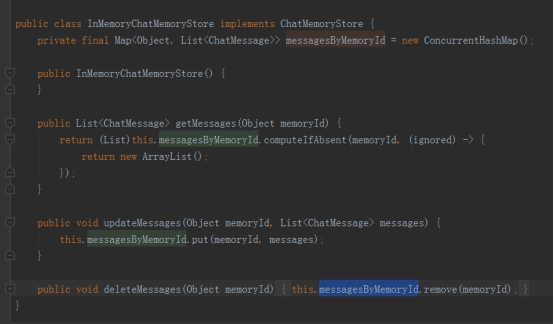
}8.2.ChatMemoryStore
LangChain4j默认实现InMemoryChatMemoryStore,将数据存储在内存,系统重启后消失,因此如果需要重启后不消失,可以考虑使用redis、elasticsearch、mongodb等持久化服务,重新实现ChatMemoryStore接口。
 InMemoryChatMemoryStore
InMemoryChatMemoryStore
9.如何训练自己的大模型
9.1Tools工具
对于大模型来说,他解决的是他解决过的问题积累的经验,但是一些专业领取的知识,他没有学过,他是解决不了的,如何然大模型能解决特定领取的问题呢?使用tools工具,就能训练出自己的大模型。
单击此处输入文字。
public class ToolsTest {
public static void main(String[] strings) throws Exception {
ChatLanguageModel model = ChatLanguageModelFactory.getOllamaChatModle();
ToolSpecification toolSpecification;
toolSpecification = ToolSpecifications.toolSpecificationFrom(ToolsTest.class.getMethod
("getDate"));
UserMessage userMessage1 = UserMessage.from("请问,请问今天是几月几号?");
Response<AiMessage> responseAiMsg = model.generate(Collections.singletonList(userMessage1),Collections.singletonList(toolSpecification));
AiMessage aiMessage1 = responseAiMsg.content();
System.out.println(aiMessage1);
if(aiMessage1.hasToolExecutionRequests()){
aiMessage1.toolExecutionRequests().forEach(req->{
String name = req.name();
Method method = null;
try {
method = ToolsTest.class.getMethod(name);
String value = (String) method.invoke(null);
System.out.println(value);
ToolExecutionResultMessage toolMsg = ToolExecutionResultMessage.from(req.id(),
req.name(),value);
//不管什么message,只要是chatMessage,都打包喂给model
Response<AiMessage> response = model.generate(Arrays.asList(userMessage1,toolMsg,aiMessage1));
System.out.println( response.content().text());
} catch (Exception e) {
e.printStackTrace();
}
});
}
}
/**
* 大模型不知道,我提供工具类,只要大模型调用,就能知道
* @return
*/
@Tool("获取单前日期")
public static String getDate(){
return LocalDateTime.now().toString();
}
}Tools具备扩展能力,可对接业务数据完成与业务数据的融合。
9.2.Tools补充
1.大部分的主流大模型都能够支持Tools工具机制。关于各个模型的支持情况,可以参见LangChain4j官网整理的表格
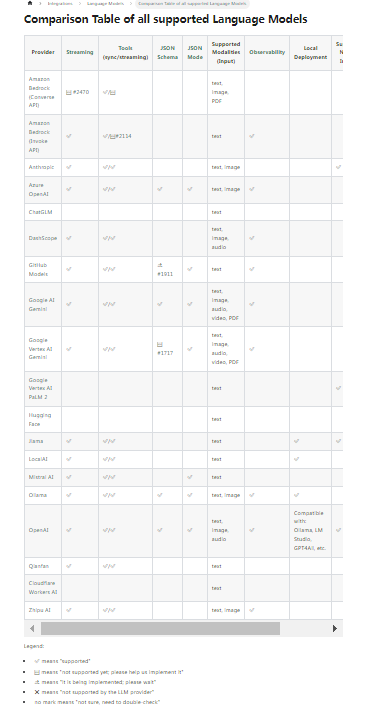
2.在@Tools标识的工具方法中,还可以通过@P注解,给参数提供更明确的说明。
public class ToolsTest {
public static void main(String[] strings) throws Exception {
ChatLanguageModel model = ChatLanguageModelFactory.getOllamaChatModle();
ToolSpecification toolSpecification;
toolSpecification = ToolSpecifications.toolSpecificationFrom(ToolsTest.class.getMethod
("getDate"));
UserMessage userMessage1 = UserMessage.from("请问,请问今天是几月几号?");
Response<AiMessage> responseAiMsg = model.generate(Collections.singletonList(userMessage1),Collections.singletonList(toolSpecification));
AiMessage aiMessage1 = responseAiMsg.content();
System.out.println(aiMessage1);
if(aiMessage1.hasToolExecutionRequests()){
aiMessage1.toolExecutionRequests().forEach(req->{
String name = req.name();
Method method = null;
try {
method = ToolsTest.class.getMethod(name);
String value = (String) method.invoke(null);
System.out.println(value);
ToolExecutionResultMessage toolMsg = ToolExecutionResultMessage.from(req.id(),
req.name(),value);
//不管什么message,只要是chatMessage,都打包喂给model
Response<AiMessage> response = model.generate(Arrays.asList(userMessage1,toolMsg,aiMessage1));
System.out.println( response.content().text());
} catch (Exception e) {
e.printStackTrace();
}
});
}
}
/**
* 大模型不知道,我提供工具类,只要大模型调用,就能知道
* @return
*/
@Tool("获取单前日期")
public static String getDate(){
return LocalDateTime.now().toString();
}
}10.AIService
10.1.AIService初阶玩法
AIService简化了与AI 模型的交互
public class AiServiceDemo {
public static void main(String[] args) {
ChatLanguageModel model = ChatLanguageModelFactory.getOllamaChatModle();
Singer singer = AiServices.create(Singer.class, model);
String result = singer.write("创作程序员之歌,字数50个字以内");
System.out.println(result);
}
interface Singer {
String write(String content);
}
}10.2.AIService高阶玩法
public class AiServiceSeniorDemo {
public static void main(String[] args) {
ChatLanguageModel model = ChatLanguageModelFactory.getOllamaChatModle();
Singer singer = AiServices.create(Singer.class, model);
String result = singer.write("创作程序员之歌", 100);
System.out.println(result);
}
interface Singer {
@SystemMessage("你是一位英文原创歌手,请根据{{title}}为主题,创作一首歌词字数在{{contentNum}}内的歌曲")
String write(@V("title") String title, @V("contentNum") int contentNum);//如果参数没有注解可以一个都没有,如果有注解,所有参数都需要注解
}
}其中SystemMessage对用户的输入消息做了增强
10.3.AIService同其他组件联合使用
public class UserAiServiceDemo {
public static void main(String[] args) throws NoSuchMethodException {
ChatLanguageModel model = ChatLanguageModelFactory.getOllamaChatModle();
ToolSpecification toolSpecification;
toolSpecification = ToolSpecifications.toolSpecificationFrom(UserAiServiceDemo.class
.getMethod("getDate"));
AIUser aiUser = AiServices.builder(AIUser.class) //代理技术
.chatLanguageModel(model)
.chatMemoryProvider(memoruId -> MessageWindowChatMemory.withMaxMessages(10))
//一个会话id返回一个存储上下文的memory,这样不混乱
.tools(toolSpecification)
.build();
System.out.println(aiUser.ask(1, "你好,我是timy", 100));//没有memoryid就默认使用同一个
System.out.println(aiUser.ask(1, "你好,timy生日是什么时候", 100));
System.out.println(aiUser.ask(2, "你好,我是佩奇", 100));
System.out.println(aiUser.ask(2, "你好,佩奇生日是什么时候", 100));
System.out.println("相同的问题,不同的会话,返回不同的内容");
}
@Tool("获取单前日期")
public static String getDate(){
return LocalDateTime.now().toString();
}
interface AIUser {
Result<String> ask(@MemoryId long userId, @V("title") String title, @V("contentNum") int contentNum);
}
}11.什么是Embeding
11.1.文本向量化
Embeding就是文本向量化:就是通过机器学习的方式,将一个自然语言转为一个多维向量存储,然后使用向量的相似度衡量向量之间相似度。
package com.ai.langchain4j.AIDemo.demo;
import com.ai.langchain4j.AIDemo.factory.ChatLanguageModelFactory;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.CosineSimilarity;
/**
* ClassName: VectorDemo
* Description:
*
* @Author TimyLiu
* @Create 2025/2/25 18:27
*/
public class VectorDemo {
public static void main(String[] args) {
EmbeddingModel embeddingModel = ChatLanguageModelFactory.getOllamaEmbeddingModel();
Response<Embedding> response1 = embeddingModel.embed("你好,我是timy");
System.out.println("向量内容"+response1.content().toString());
System.out.println("内容有多少维度 "+response1.content().vector().length);
//两个文本向量的相似度计算
Response<Embedding> response2 = embeddingModel.embed("我的名字叫timy");
double similarity =CosineSimilarity.between(response1.content(),response2.content());
System.out.println("CosineSimilarity 相似度 "+similarity);
}
}11.2.向量数据库
向量数据库支持如下

利用向量数据库计算两个向量之间的相似度
public class VectorSimilarityDemo { public static void main(String[] args) { EmbeddingModel embeddingModel = ChatLanguageModelFactory.getOllamaEmbeddingModel(); Response<Embedding> response1 = embeddingModel.embed("你好,我是timy"); Response<Embedding> response2 = embeddingModel.embed("我的名字叫timy"); InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>(); embeddingStore.add(response1.content()); EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder().queryEmbedding (response2.content()).maxResults(10).build(); EmbeddingSearchResult<TextSegment> result = embeddingStore.search(embeddingSearchRequest); List<EmbeddingMatch<TextSegment>> listTextSegment= result.matches(); listTextSegment.forEach(textSegment ->{ System.out.println("相似度 "+textSegment.score()); System.out.println("向量 "+textSegment.embedding()); System.out.println("数据库id "+textSegment.embeddingId()); System.out.println("向量对应文本 "+textSegment.embedded().text()); }); } }
12.支持检索增强生成技术
LLM(Large Language Model,大语言模型)的知识确实局限于其训练数据。若想让LLM了解特定领域知识或专有数据,需要使用RAG技术。
12.1.什么是 RAG
支持检索增强生成技术 RAG (Retrieval-Augmented-Generation)
RAG 是一种在将提示词发送给 LLM 之前,从你的数据中找到并注入相关信息的方式。这样,LLM 希望能获得相关的信息并利用这些信息作出回应,从而减少幻觉概率。
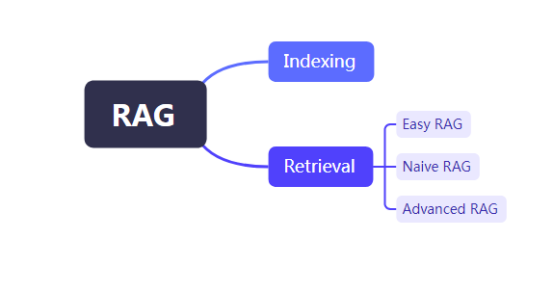
Easy RAG:最简单方式RAG
Native RAG:使用向量搜索的RAG
Advanced RAG:一个模块化的 RAG 框架,允许执行额外的步骤,如查询转换、从多个来源检索和重新排序
12.2.Indexing阶段
文档会进行预处理,以便在检索阶段实现高效搜索。简化的索引流程未:将知识文档预处理,利用附加数据和元数据对其进行增强,将其拆分为较小的片段(即“分块”),对这些片段进行嵌入,最后将它们存储在嵌入存储库(即向量数据库)。通常在离线完成,即用户无需等待该过程的完成。
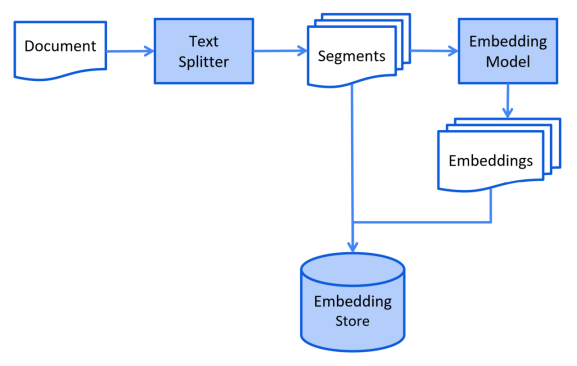
索引阶段简化流程图
public class RagIndexingDemo {
public static void main(String[] args) throws Exception {
Path path;
path = Paths.get(RagIndexingDemo.class.getClassLoader().getResource("question.txt").toURI());
DocumentParser parser = new TextDocumentParser();//不同文件,不同解析器
//第一步 :读取文件
Document document = FileSystemDocumentLoader.loadDocument(path, parser);
//第二步:把知识文件分解为一个个知识条目.文件拆分
DocumentSplitter splitter = new MyDocumentSplitter();//不同的分隔解析器,不合适的就自己实现一个
List<TextSegment> textSegments = splitter.split(document);
textSegments.forEach(text-> {
System.out.println(JSONObject.toJSONString(text.text()));
});
//第三步:把每个条目文本向量化存储到向量数据库
EmbeddingModel embeddingModel = ChatLanguageModelFactory.getEmbeddingModel();
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
List<Embedding> embeddingList = embeddingModel.embedAll(textSegments).content();//文本向量化处理
embeddingStore.addAll(embeddingList,textSegments);//存储向量和对应文本到向量数据库
}
}12.3.Retrieval 阶段
通常在线进行,当用户提交一个问题时,系统会使用已索引的文档来回答问题。对于向量搜索,通常包括嵌入用户的查询(问题),并在嵌入存储库中执行相似度搜索。然后,将相关片段(原始文档的部分内容)注入提示词并发送给 LLM。
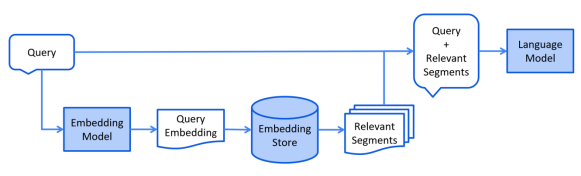
Retrieval 阶段的简化流程图
public class RAGRetrievalDemo {
public static void main(String[] args) {
String msg = "客服电话是多少";
EmbeddingModel embeddingModel = ChatLanguageModelFactory.getEmbeddingModel();;
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
//ContentRetriever统一封装,兼容所有模型和向量数据库
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingModel(embeddingModel).embeddingStore(embeddingStore).maxResults(5)
.minScore(0.8).build();
Query query = Query.from(msg);
List<Content> contentList = contentRetriever.retrieve(query);
contentList.forEach(content -> {
System.out.println(content);
});
//把信息发给ai大模型
ContentInjector contentInjector = DefaultContentInjector.builder().build();//可以自己定制内容注入器,实现自己的模版
ChatMessage userMessage = UserMessage.from(msg);
ChatMessage promoptMessage = contentInjector.inject(contentList,userMessage);//数据增强模版
System.out.println(promoptMessage);
ChatLanguageModel chatLanguageModel = ChatLanguageModelFactory.getOllamaChatModle();
Response<AiMessage> aiMessageResponse = chatLanguageModel.generate(promoptMessage);//提供给ai
System.out.println(aiMessageResponse);
}
}使用AIService整合大模型,实现更简单的检索
public class RAGRetrievaAIServicelDemo {
public static void main(String[] args) {
String msg = "客服电话是多少";
AiCustomer aiCustomer = RAGRetrievaAIServicelDemo.create();
Result<String> result = aiCustomer.answer(msg);
System.out.println(result);
}
public static AiCustomer create() {
EmbeddingModel embeddingModel = ChatLanguageModelFactory.getEmbeddingModel();;
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingModel(embeddingModel).embeddingStore(embeddingStore).maxResults(5)
.minScore(0.8).build();
ContentInjector contentInjector = DefaultContentInjector.builder().build();
ChatLanguageModel chatLanguageModel = ChatLanguageModelFactory.getOllamaChatModle();
DefaultRetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder().contentInjector
(contentInjector).contentRetriever(contentRetriever).build();
AiCustomer aiCustomer = AiServices.builder(AiCustomer.class)
.chatLanguageModel(chatLanguageModel)
.chatMemoryProvider(memoruId -> MessageWindowChatMemory.withMaxMessages(10))
.tools(new KCardSvc())
.retrievalAugmentor(retrievalAugmentor)
.build();
return aiCustomer;
}
interface AiCustomer {
Result<String> answer(String question);
}
static class KCardSvc {
@Tool("客服信息")
public static String tell() {
return "10010-1234";
}
}
}14.附录
14.1.如何利用向量数据库实现一个简单客服系统
public class CustomerDemo {
public static void main(String[] args) {
EmbeddingModel embeddingModel = ChatLanguageModelFactory.getOllamaEmbeddingModel();;
//加入向量数据库
TextSegment textSegment1 = TextSegment.textSegment("客服电话:10010-123");
TextSegment textSegment2 = TextSegment.textSegment("客服工作时间:周一-周五");
TextSegment textSegment3 = TextSegment.textSegment("客服投诉电话:10010-456");
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.add(embeddingModel.embed(textSegment1).content(),textSegment1);//向量模型和对应文本都存下来
embeddingStore.add(embeddingModel.embed(textSegment2).content(),textSegment2);
embeddingStore.add(embeddingModel.embed(textSegment3).content(),textSegment3);
TextSegment quest = TextSegment.textSegment("请问客服电话是多少");
//查询向量数据库
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder().queryEmbedding
(embeddingModel.embed(quest).content()).maxResults(10).build();
EmbeddingSearchResult<TextSegment> result = embeddingStore.search(embeddingSearchRequest);
List<EmbeddingMatch<TextSegment>> listTextSegment= result.matches();
listTextSegment.forEach(textSegment ->{
System.out.println("相似度 "+textSegment.score());
System.out.println("向量对应文本 "+textSegment.embedded().text());
});
}
}14.2.Langchain4j官网
官网地址https://docs.LangChain4j.dev



















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











