






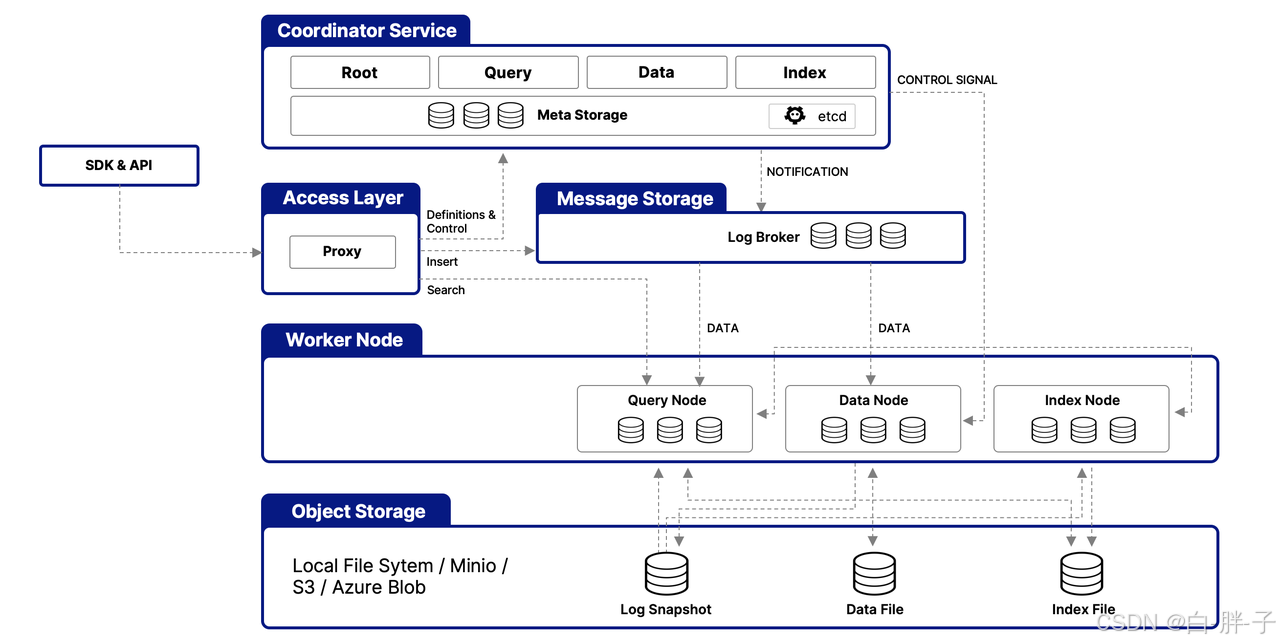
一、引言:从 Oracle 老兵到全球向量数据库标杆的逆袭之路
2025 年 AI 产业正迎来三大关键转变:大模型从云端走向端侧、RAG 成为企业级应用标配、多模态数据处理需求爆发。而这波浪潮背后,一款名为 Milvus 的向量数据库正悄然成为基础设施 —— 它的诞生,源于一位 Oracle 老兵的 “不服输”,更藏着两段 “赌上全部” 的技术传奇。
1. 灵魂人物:Oracle 营收支柱的 “破局者”
Milvus 的缔造者是 Zilliz 公司创始人谢超(花名 “星爵”),这位曾在 Oracle 美国总部深耕多年的核心工程师,一手参与打造了 Oracle 12c 的多租户数据库技术 —— 这项技术为 Oracle 创造了数十亿美金营收,成为企业级数据库的标杆特性。
2017 年,AI 应用爆发催生海量非结构化数据,但谢超团队发现一个尴尬现状:“传统数据库处理不了高维向量,FAISS 这类研究库没有生产级稳定性,Elasticsearch 做向量检索性能拉胯”。试过所有现有方案后,这位数据库老兵下了个 “任性” 的决定:“既然没有能用的,我们就自己造一个”——Milvus 项目就此启动,而当时 “向量数据库” 的概念尚未被行业认知。
2. 关键趣闻:两次改写命运的 “冒险决策”
Milvus 的成长史,藏着两个足以改变行业格局的关键选择:
-
2019 年开源豪赌:产品初具雏形时,团队内部爆发激烈争论 —— 开源意味着暴露所有技术缺陷,还要面临商业变现的不确定性。但谢超力排众议:“AI 技术的进步需要开放生态”。结果出乎意料:开源 4 个月吸引 50 + 企业客户,GitHub 星标从零飙升至数千,更让 Milvus 成为全球首个开源向量数据库。
-
2021 年推倒重来:Milvus 1.0 已获市场认可时,客户反馈 “分布式扩展性不足”“云原生支持薄弱”。团队再次抉择:是修修补补,还是彻底重构?谢超带领核心团队耗时两年重写全部核心代码,打造存算分离的 Milvus 2.0。这次 “冒险” 让 Milvus 性能提升 10 倍,直接奠定其企业级市场领先地位。
如今,Milvus 已成为 GitHub 星标超 35.5K 的顶级开源项目(LF AI & Data 基金会托管),被 Roblox、Salesforce、博世等 1000 + 企业采用。其核心优势 ——十亿级向量毫秒级检索、云原生弹性架构、多模态与混合查询支持,正完美适配 RAG、智能推荐、多模态检索等主流 AI 场景,而这一切的起点,只是一位工程师 “解决实际问题” 的初心。
二、核心特性:适配 2025 AI 趋势的三大核心能力
1. 性能突破:支撑大规模 AI 应用落地
-
极致检索效率:支持 HNSW/CAGRA 等 10 + 索引算法,CAGRA GPU 索引使查询性能提升 8 倍,十亿级向量检索延迟低至 10ms 内;
-
分层存储优化:热数据存 SSD / 内存、冷数据存对象存储,存储成本降低 40%,适配 AI 应用的 PB 级数据存储需求;
-
弹性扩展架构:存算分离设计支持独立扩缩容,K8s 部署保障 99.9% 高可用,满足 AI 原生应用的动态算力需求。
2. 功能升级:紧跟多模态与 RAG 趋势
-
多模态统一处理:v2.6 版本新增 Array of Vector 功能,支持单实体存储多向量,完美适配文本 + 图像的跨模态检索场景;
-
混合查询增强:向量 + 标量 + 全文检索深度融合,支持 JSON Shredding 优化查询效率,适配 RAG 的 “语义检索 + 关键词过滤” 需求;
-
大模型生态联动:原生支持 Qwen GTE-Rerank-v2 等主流重排模型,与 LangChain/LLaMA Index 无缝集成,简化 RAG 架构搭建。
3. 易用性提升:降低 AI 落地门槛
-
轻量化部署:Milvus Lite 零依赖本地运行,支持 Python 一键启动,适合开发测试与边缘设备场景;
-
多语言生态:Python/Java/Go/C++ SDK 全覆盖,Python SDK 功能最完善,支持 RESTful API 与 SQL-like 查询;
-
可视化工具链:Attu 管理工具提供一站式集群监控、数据操作界面,新手快速上手。
三、版本迭代:从开源到企业级的进化之路
| 阶段 | 版本区间 | 核心突破 | 时代意义 |
|---|---|---|---|
| 开源奠基期 | v0.10-v1.0(2019-2020) | 全球首个开源向量数据库,支持分布式部署 | 确立向量数据库技术方向 |
| 架构重构期 | v2.0(2022) | 存算分离 + 云原生架构,支持 K8s 部署 | 从 “可用” 升级为 “企业级” |
| 性能爆发期 | v2.1-v2.4(2022-2024) | GPU 加速 + 分层存储 + 混合查询 | 适配 RAG 热潮,用户量激增 |
| 智能进化期 | v2.6+(2025) | 多向量支持 + JSON 优化 + 大模型联动 | 引领多模态与 AI 原生应用趋势 |
2025 路线图:Milvus 3.0 将推出向量数据湖系统,强化离线海量数据处理能力,打造非结构化数据统一处理平台。
四、实战指南:3 分钟上手 Milvus(AI 应用核心场景示例)
1. 快速部署(优先推荐 Milvus Lite)
\# 安装依赖(Python 3.8+)
pip install pymilvus==2.6.2 milvus-lite
\# 启动服务(零依赖,数据存储本地文件)
from pymilvus import connections
connections.connect(alias="default", uri="./ai\_milvus.db")
2. 核心 AI 场景实战:RAG 知识库搭建
\# 1. 定义集合Schema(适配文本向量+元数据)
from pymilvus import CollectionSchema, FieldSchema, DataType, Collection
schema = CollectionSchema(\[
FieldSchema("id", DataType.INT64, is\_primary=True, auto\_id=True),
FieldSchema("text\_vector", DataType.FLOAT\_VECTOR, dim=768), # 适配BERT/LLaMA向量维度
FieldSchema("doc\_id", DataType.VARCHAR, max\_length=100),
FieldSchema("content", DataType.VARCHAR, max\_length=2000),
FieldSchema("create\_time", DataType.DATETIME) # 标量字段:支持时间过滤
])
collection = Collection("rag\_knowledge\_base", schema)
\# 2. 插入文档向量(实际场景从大模型生成,此处模拟1000条数据)
import random
from datetime import datetime
data = \[
\[random.uniform(-1, 1) for \_ in range(768)] \* 1000, # 向量数据
\[f"doc\_{i}" for i in range(1000)], # 文档ID
\[f"企业知识库内容\_{i}:AI原生应用架构设计..." for i in range(1000)], # 文档内容
\[datetime.now() for \_ in range(1000)] # 创建时间
]
collection.insert(data)
collection.flush()
\# 3. 创建索引(HNSW适配RAG实时检索需求)
collection.create\_index(
field\_name="text\_vector",
index\_params={"index\_type": "HNSW", "metric\_type": "IP", "params": {"M": 8, "efConstruction": 64}}
)
collection.load()
\# 4. 执行RAG检索(语义查询+标量过滤)
query\_text = "AI原生应用如何设计存储架构?"
\# 实际场景:通过大模型生成查询向量(如BERT.encode(query\_text))
query\_vector = \[random.uniform(-1, 1) for \_ in range(768)]
results = collection.search(
data=\[query\_vector],
anns\_field="text\_vector",
param={"ef": 64},
limit=5, # 返回Top5相似结果
output\_fields=\["doc\_id", "content"],
expr="create\_time > '2025-01-01'" # 过滤2025年后的文档
)
\# 解析结果(后续可接入重排模型优化精度)
print("RAG检索结果:")
for idx, hit in enumerate(results\[0], 1):
print(f"\n{idx}. 文档ID:{hit.entity.get('doc\_id')}")
print(f"相似度:{hit.distance:.4f}")
print(f"内容:{hit.entity.get('content')\[:100]}...")
\# 5. 资源释放(可选)
collection.release()
connections.disconnect("default")
3. 生产级部署(Docker Compose)
\# 下载v2.6.4稳定版配置文件
wget https://github.com/milvus-io/milvus/releases/download/v2.6.4/milvus-standalone-docker-compose.yml -O docker-compose.yml
\# 启动服务(后台运行)
docker-compose up -d
\# 安装Attu可视化工具(管理集群/数据)
docker run -d -p 8000:3000 -e MILVUS\_URL=localhost:19530 zilliz/attu:v2.6.0
- 访问 Attu:浏览器打开
http://localhost:8000,默认无密码登录即可管理数据。
五、AI 应用落地:2025 最新行业案例解析
1. RAG 企业知识库(最热门场景)
-
Shell 能源:构建全球能源行业知识库,30 亿文档向量检索响应时间 < 200ms,员工文档查询效率提升 60%,技术文档复用率从 35% 升至 78%;
-
某银行信用卡中心:12 万份合规 / 产品文档向量化,客服问题匹配准确率从 68% 升至 92%,复杂问题解决时间缩短 58%,客户满意度提升 23%。
2. 多模态检索与智能推荐
-
Roblox:基于 Milvus 实现虚拟形象检索,支持数十亿级 3D 模型特征匹配,用户定制化形象生成效率提升 40%,平台活跃度增长 18%;
-
Tokopedia(印尼电商):替换 Elasticsearch 构建商品推荐系统,结合用户行为向量与商品多模态特征,点击率提升 27%,广告服务稳定性达 99.99%。
3. 工业与自动驾驶
-
某新能源车企:处理 PB 级传感器数据,实现 “暴雨 + 夜间” 等长尾驾驶场景检索,自动驾驶模型迭代周期缩短 40%,测试成本降低 30%;
-
博世:分析数十亿驾驶场景向量,数据收集成本降低 80%,年节省 140 万美元,辅助驾驶系统误判率下降 25%。
4. 医疗健康
-
某药企:处理 1.2 亿条蛋白质结构数据,靶点筛选时间从 “周级” 缩短至 “分钟级”,新药研发周期缩短 18 个月;
-
三甲医院影像科:构建 CT/MRI 图像向量库,相似病例检索时间 < 3 秒,医生诊断效率提升 35%,误诊率降低 12%。
六、优劣势客观分析(2025 最新评估)
核心优势
-
大规模场景适配:十亿级向量处理能力行业领先,支持 GPU 加速与分层存储,远超 FAISS 等轻量级库;
-
AI 生态兼容性:深度集成大模型与 RAG 框架,开箱即用,开发成本低;
-
开源商业双保障:Apache 2.0 协议自由二次开发,Zilliz 提供企业级支持与云服务(Milvus Cloud);
-
多模态前瞻性:Array of Vector 等功能提前布局跨模态趋势,适配元宇宙、具身智能等新兴场景。
待改进点
-
轻量化场景适配不足:分布式架构导致小规模部署(百万级向量以下)资源开销高于 Annoy/Qdrant;
-
高频更新效率:大规模数据集的向量更新 / 删除性能仍有优化空间,需通过批量操作规避;
-
跨语言支持不均:C++/Rust SDK 部分高级功能(如自定义索引)滞后于 Python 版本;
-
商业版成本较高:Milvus Cloud 大规模使用成本高于部分闭源竞品(如 Pinecone),中小团队可选择开源版自建。
七、未来展望:向量数据库的下一代进化方向
结合 Zilliz 2025 路线图与 AI 行业趋势,Milvus 将向三大方向演进:
-
AI 原生深度融合:内置索引自动调优、数据生命周期智能管理,支持大模型自动生成查询策略,降低 AI 应用运维成本;
-
多模态统一引擎:支持文本、图像、音频、3D 点云的跨模态关联检索,适配元宇宙与具身智能场景;
-
向量数据湖架构:Milvus 3.0 将实现离线批处理与实时检索一体化,支持与 Hadoop、Spark 生态联动,成为非结构化数据的统一处理平台。
八、总结:AI 原生时代,向量数据库的选型建议
在 AI 原生应用爆发的 2025 年,Milvus 已从 “向量检索工具” 进化为 “非结构化数据处理基础设施”。其核心价值在于:用高效的向量计算连接 AI 模型与业务数据,让语义理解、多模态交互等复杂场景的落地门槛大幅降低。
选型建议
-
优先选 Milvus:十亿级向量、企业级高可用、RAG / 多模态场景、需要开源二次开发;
-
备选方案:小规模测试用 FAISS/Annoy,轻量化生产用 Qdrant,闭源商业场景用 Pinecone。
学习资源
-
官方文档:milvus.io/docs
-
实战示例:pymilvus-demo
-
可视化工具:Attu(Docker 一键部署)
-
社区交流:GitHub Discussions、Zilliz 开发者社区
如果你正在搭建 RAG 应用、多模态检索系统,或面临大规模非结构化数据处理难题,不妨试试 Milvus—— 这款源于 “解决实际问题” 初心的数据库,或许能成为你 AI 落地的关键助力。欢迎在评论区分享你的使用场景与优化经验,一起探讨向量数据库在 AI 时代的更多可能!

















 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









