 数据库索引详解
数据库索引详解





 本文介绍了数据库索引的不同类型,如B-Tree索引、哈希索引等,并探讨了索引的优点及其对查询性能的影响。此外,文章还提出了提高索引性能的策略,包括独立列索引、前缀索引、多列索引等。
本文介绍了数据库索引的不同类型,如B-Tree索引、哈希索引等,并探讨了索引的优点及其对查询性能的影响。此外,文章还提出了提高索引性能的策略,包括独立列索引、前缀索引、多列索引等。
1,索引的类型
- B-Tree索引(树说:我本来是个高瘦的富二代,结果为了mysql查找效率,我变成了矮胖的屌丝树)
当我们讨论索引时,不特殊说明某一类,我们一般说的是B-tree索引(多路平衡查找树),使用B-tree的目的是将过多的磁盘IO查找转换成内存查找。磁盘读取依靠的是机械运动,分为寻道时间、旋转延迟、传输时间三个部分,这三个部分耗时相加就是一次磁盘IO的时间,大概9ms左右。这个成本是访问内存的十万倍左右;正是由于磁盘IO是非常昂贵的操作,所以计算机操作系统对此做了优化:预读;每一次IO时,不仅仅把当前磁盘地址的数据加载到内存,同时也把相邻数据也加载到内存缓冲区中。因为局部预读原理说明:当访问一个地址数据的时候,与其相邻的数据很快也会被访问到。每次磁盘IO读取的数据我们称之为一页(page)。一页的大小与操作系统有关,一般为4k或者8k。这也就意味着读取一页内数据的时候,实际上发生了一次磁盘IO。查找情况最差的时候就是遍历二叉树出从根节点到最高度的叶子节点,假如一个树度为10,那么最差的情况就是二叉树查找10次。所以,我们发现二叉树查找最大的问题就是度,于是我们可以构造一个度很低的树,也就是把高瘦的二叉树变为矮胖树。
实现过程就是把多个索引放在一个节点内部,这样当我们从磁盘加载一个节点,那么我们可以直接可以比较该节点内部的多个索引值,这样就避免了传统的二叉树比较2个节点,需要从磁盘机械运动2次加载数据,而把一个节点加载到内存,通过内存间直接比较的效率高于机械运动的查找。所以矮胖的树,就是因为一个节点内部可以装多个值。
B-Tree是有序的进行存储的,它是可以加快表查找速度的,因为使用该索引,就不用进行全表扫描,而是从树的根节点开始查找,根节点存放了下个值的指针,只需要顺着指针获取到真实值,然后进行比较,如果没找到,则一个根据下一个节点进行依次比较。
可以用B-Tree进行的查找的类型:全键值,键值范围,键前缀查找,而且要遵循键的最左查找。
- 哈希索引
哈希索引支持的数据库存储引擎是Memory,哈希索引实现过程是,对于每一行数据,Memory引擎都会计算出一个特殊的hash code,哈希码是一个较小的值,且不同的行计算出的哈希码不一样,哈希索引将所有哈希码存储在索引中,同时哈希表中存放每个哈希行的指针,通过计算特定一行的哈希码,再将哈希码放到索引中查找就能找到了。
- 空间数据索引
MyIsan支持空间数据索引,可以用作地理数据存储。
- 全文索引
全文索引是一种特殊的索引,它可以 查找一篇文章中的关键字,而不都是像普通的索引对比索引的值。
- 其它类型索引
还有其他第三方数据库存储引擎使用的索引类型,这里就没有一一讲述完。
2,索引的优点
索引可以让服务器快速定位到表特定的位置,这个并不是索引唯一的功能,索引还具备其他功能,传统的B-Tree索引,是通过顺序存储的,所以除了用来快速查找还能用来orderby,groupby等功能,综上索引的功能总结如下:
- 避免服务器对表进行全表扫描,而是进行索引顺序查找
- 可以避免服务器创建临时表
- 将随机I/O变为顺序I/O
3,高性能的索引策略
- 独立的列
通常我们可以看到一张表添加了索引,但是这个索引在where查找时,并不是一个单独的列,类似这样的
select * from students where student_id+1=5我们可以看到,若是student_id为主键索引,但是使用该索引并没有单独地使用该列,而是加了一个表达式什么的,那么数据库不用使用索引的方式进行查找的。
- 前缀索引和索引选择性
什么是前缀索引,前缀索引就是,当我们查找一个比较长的列,比如是varchar,text等字段时,mysql不允许我们进行全值匹配索引查找,这个我们就需要进行前缀索引查找,通过查找列的前半部分,可以提高索引的查找效率,节约索引空间。怎么创建一个前缀索引?有2个点决定一个好的前缀索引
选择性越高:选择性=不重复的索引值/表总记录数,选择性越高,效率越快。因为高效率选择性可以让mysql过滤掉更多的行,比如,唯一索引的选择性是1,是最好的索引选择性,也是性能最好的。
越接近全值:越接近全值,并不是说直接等于全值就可以了,而是需要同时选择性越高和越接近全值2个方面一起才是最优的前缀索引。
通过如下例子进行展示如何创建一个前缀索引:
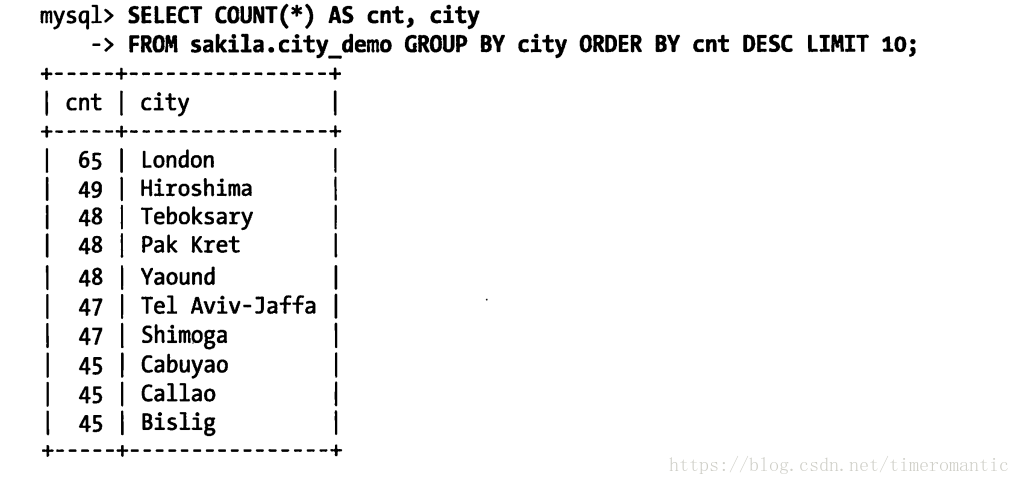


- 多列索引
很多人对多列索引的认识不够,最常见的就是为每个列创建一个索引,当我们的sql语句使用多个单列索引,性能不见得是做优化的。比如我们的sql语句如下:
select * from student where student_id=5 or class_id=4;假设student_id 和class_id都是索引,则mysql并不是执行最优查找。这个时候可以把这2个索引合并为一个多列索引。
- 选择合适的索引列顺序
创建一个多列索引,则在使用多列索引需要遵循最左查找原则,意思是如果左边第一个没有在where的索引查找中,那么多列索引第二个,第三个等等都不会有使用到索引,我们应该把选择性最高的列放最前面,选择性最高的意思就是100行数据student里面,80行中的class_id都是一个值为5班,60行中subject_id都是一个值2科,那么通过subject_id我们可以过滤更多多余数据。所以应该把subject_id放第一位置。
- 聚簇索引
聚簇索引并不是一个索引类型,而是索引的一种数据存放方式,
聚簇索引就是把索引和数据放在一块,而不是像MyIsan的数据存放方式,聚簇索引的索引文件和数据文件是一个文件,而MyIsan的则是2个分开的文件。
Innodb的聚簇索引最好给一个自增的主键ID,这样在存储上才是顺序I/O而不是随机I/O,随机I/O需要进行磁盘查找。
- 覆盖索引
- 使用索引扫描来做排序
- 压缩前缀索引
- 冗余和重复索引
- 未使用的索引
- 索引和锁
4,索引学习案例
- 当有多个条件过滤
- 避免多个范围选择
- 减少索引和数据碎片

















 1429
1429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









