 GitPuk与Arbess全流程实践
GitPuk与Arbess全流程实践




1、概括
在团队协同开发中,确立一套从代码提交到构建部署的端到端标准化流程,是提升交付效率与软件质量的关键。基于GitPuk代码管理工具,详细阐述我们采用的敏捷开发与交付流程。本文将以Git Flow开发模式为例
1.1 开发阶段
分支开发模式分为两种:1.功能分支模式 - 简单高效
2.Git Flow - 严谨规范
所有新功能均在 develop 开发分支上进行集成与测试。
1.2 发布阶段
通过从 develop 分支创建的 release 发布分支,进行版本封板与最终验证。
1.3 部署阶段
release 分支的代码添加至Arbess构建部署任务,最终发布至生产环境。
2、GitPuk安装与配置
2.1 安装
以Ubuntu操作系统为例
- 下载:Ubuntu安装包下载地址:GitPuk下载,点击Ubuntu下载,下载完成后得到tiklab-gitpuk-1.1.9.deb的文件。
- 安装:上传到服务器上,在文件同级目录执行命令安装。
dpkg -i tiklab-gitpuk-1.1.9.deb
- 启动:系统默认安装路径为/opt目录,进入/opt/tiklab-gitpuk/bin目录下,执行./gitpuk start即可启动成功。
使用 http://ip:9800 进行访问。初始用户名密码admin\123456登录,首次登录根据需要修改管理员密码。成功登录后展示GitPuk首页。
2.2 配置
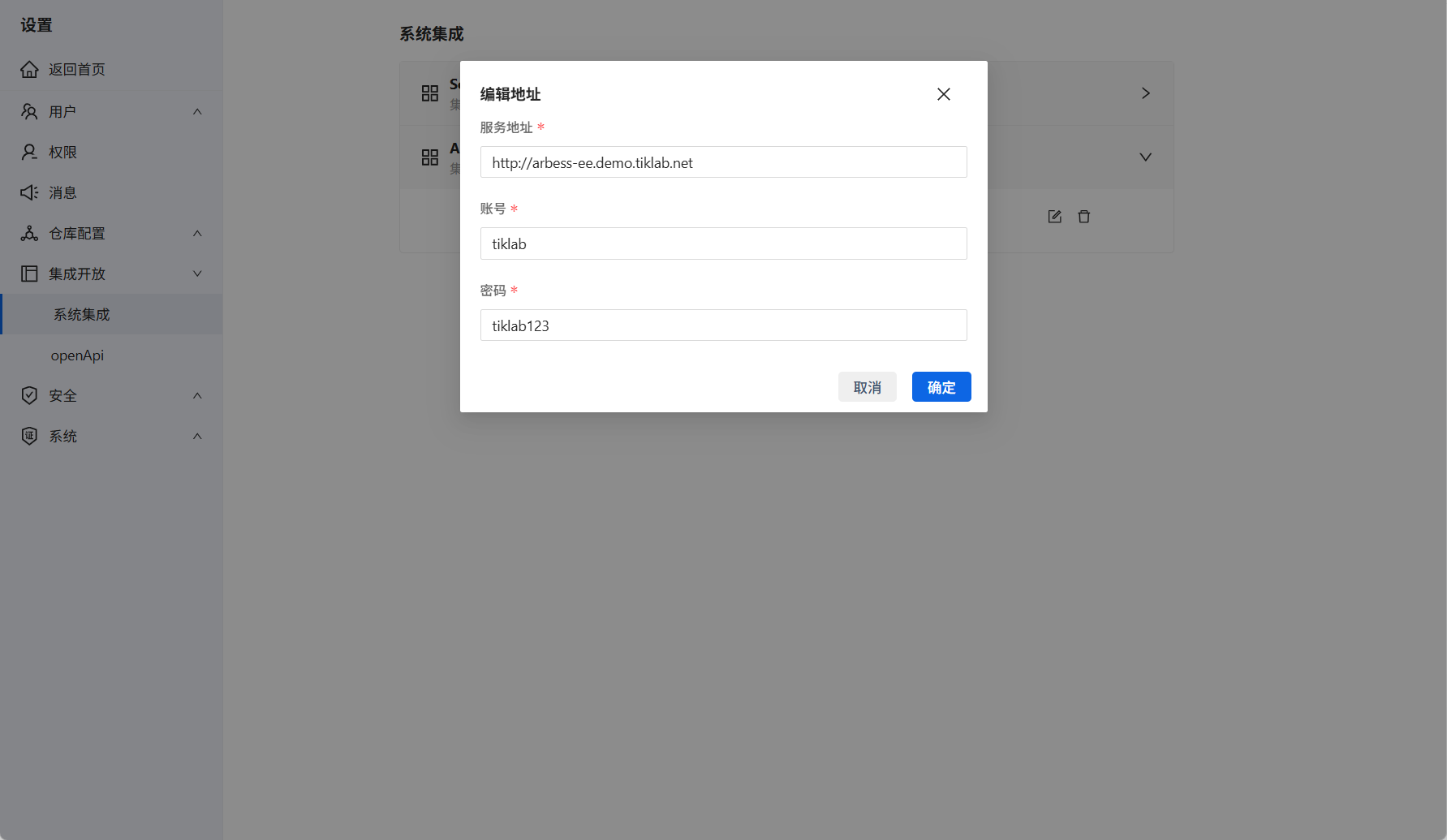
- Arbess服务集成
在系统设置集成开放中添加。选择Arbess填写服务地址、账号密码,部署完成后可回到GitPuk中进行关联查看
2.3 使用
2.3.1 初始化仓库
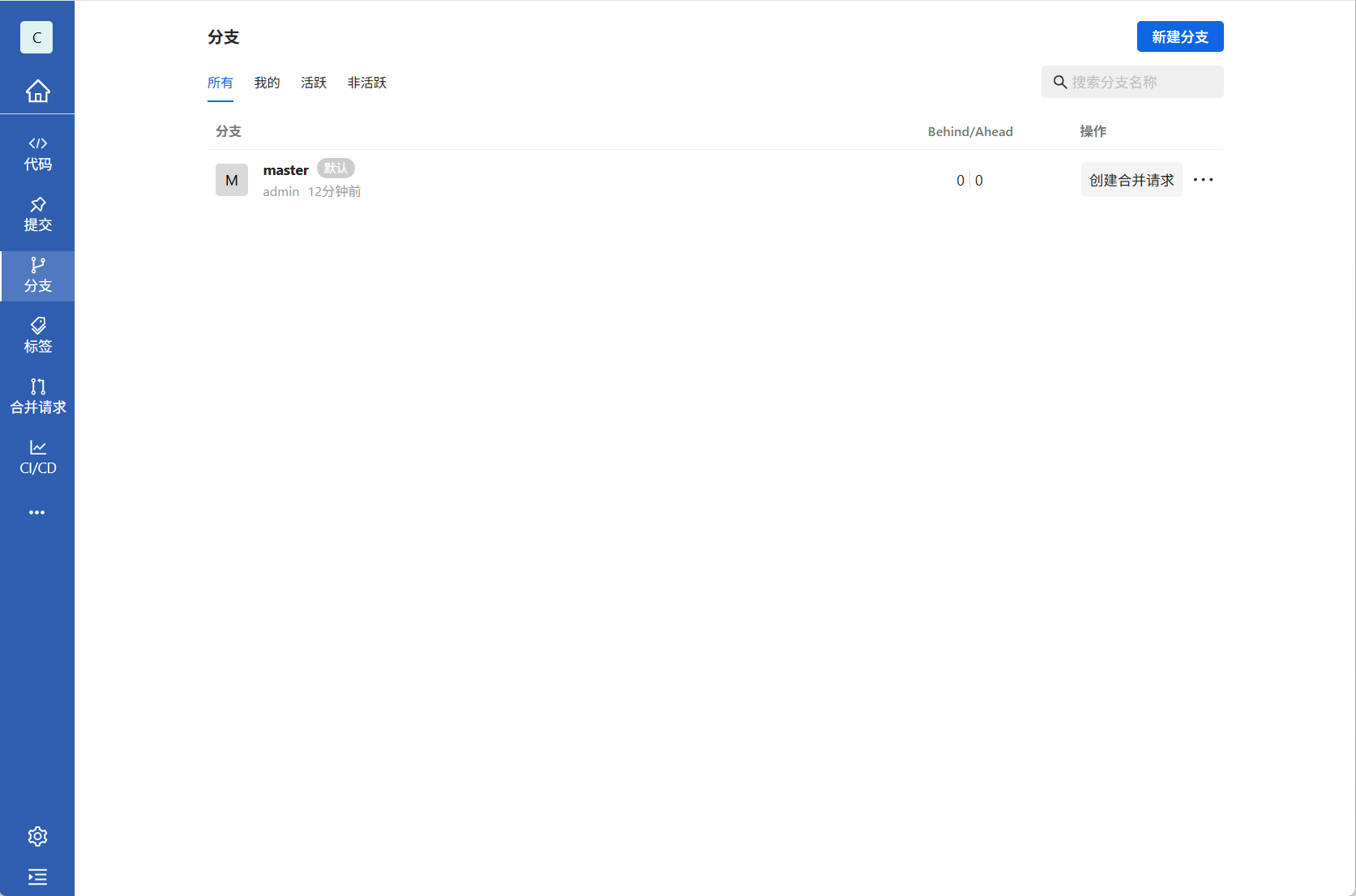
1.在 GitPuk 上创建新仓库时,系统通常会默认生成 main(或 master)分支。此分支代表生产环境的代码状态,每一个提交都应是一个可发布的版本
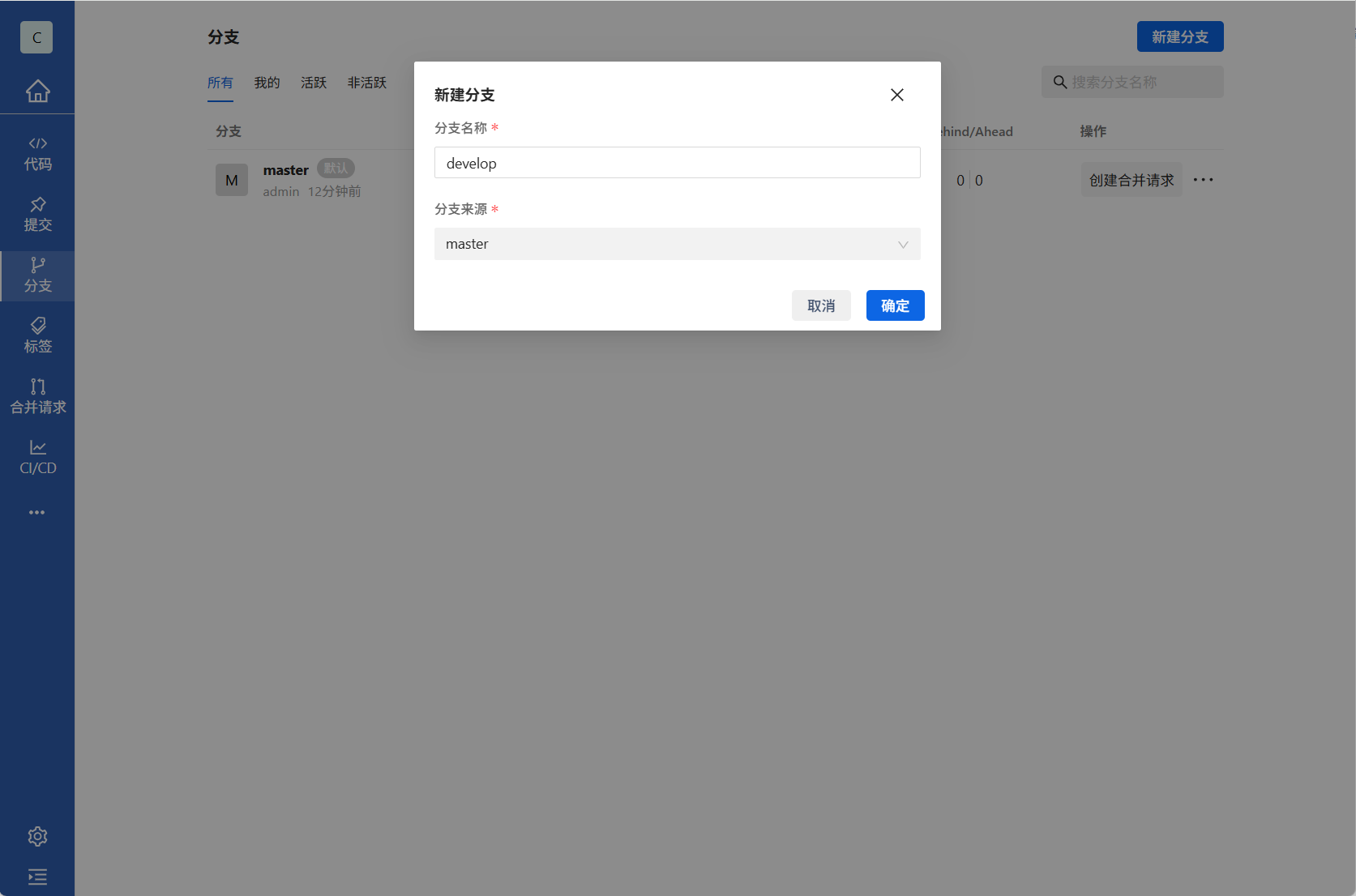
2.在分支管理中点击右上角新建分支,创建我们的开发分支输入develop点击确定即可,develop是我们的开发分支
2.3.2 develop功能开发
所有新功能开发都始于开发分支也就是develop,功能开发完成后需把功能分支合并进开发分支中
1.回到我们的分支页面进行创建我们的功能分支(feature),功能分支名称规范feature/功能简要描述
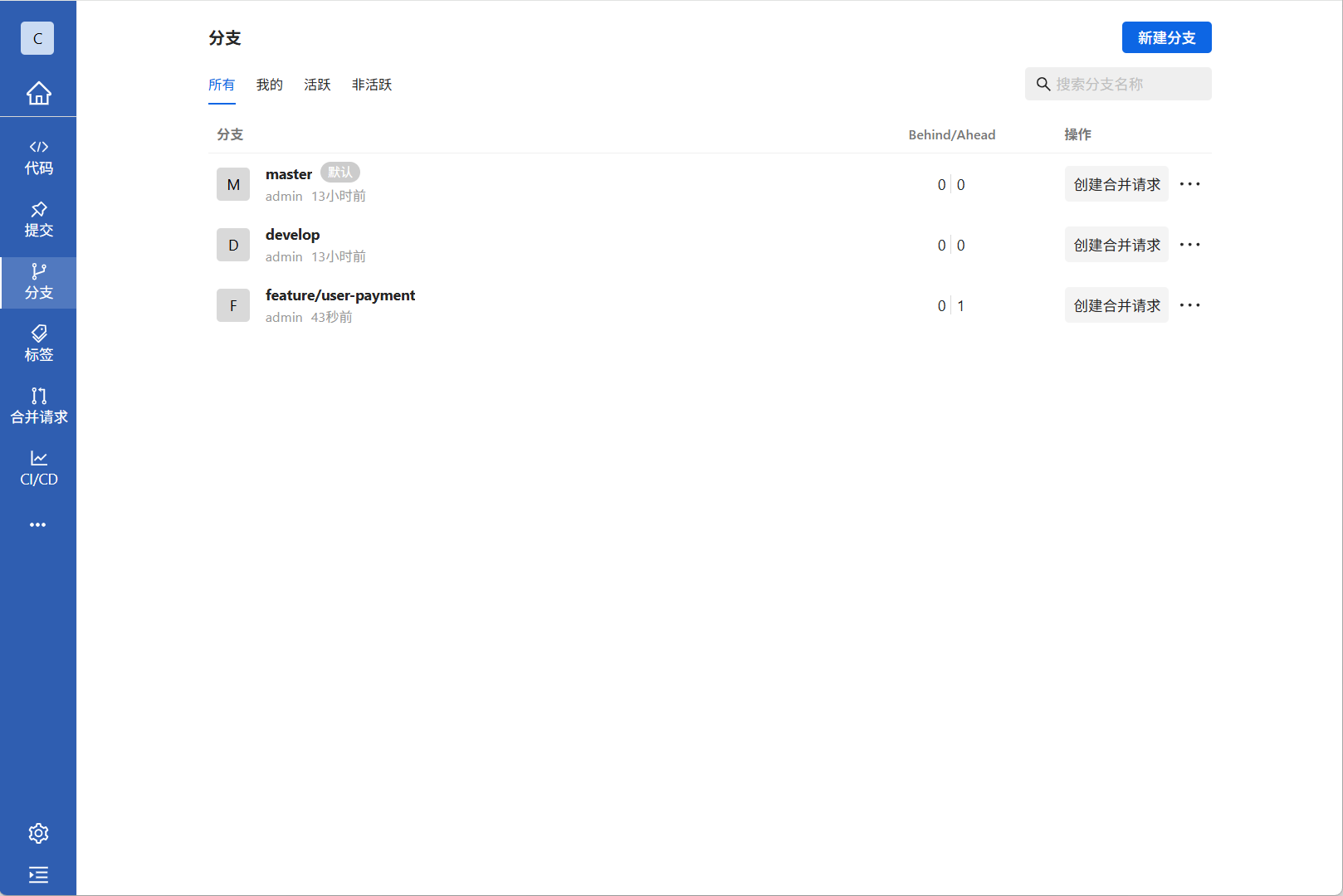
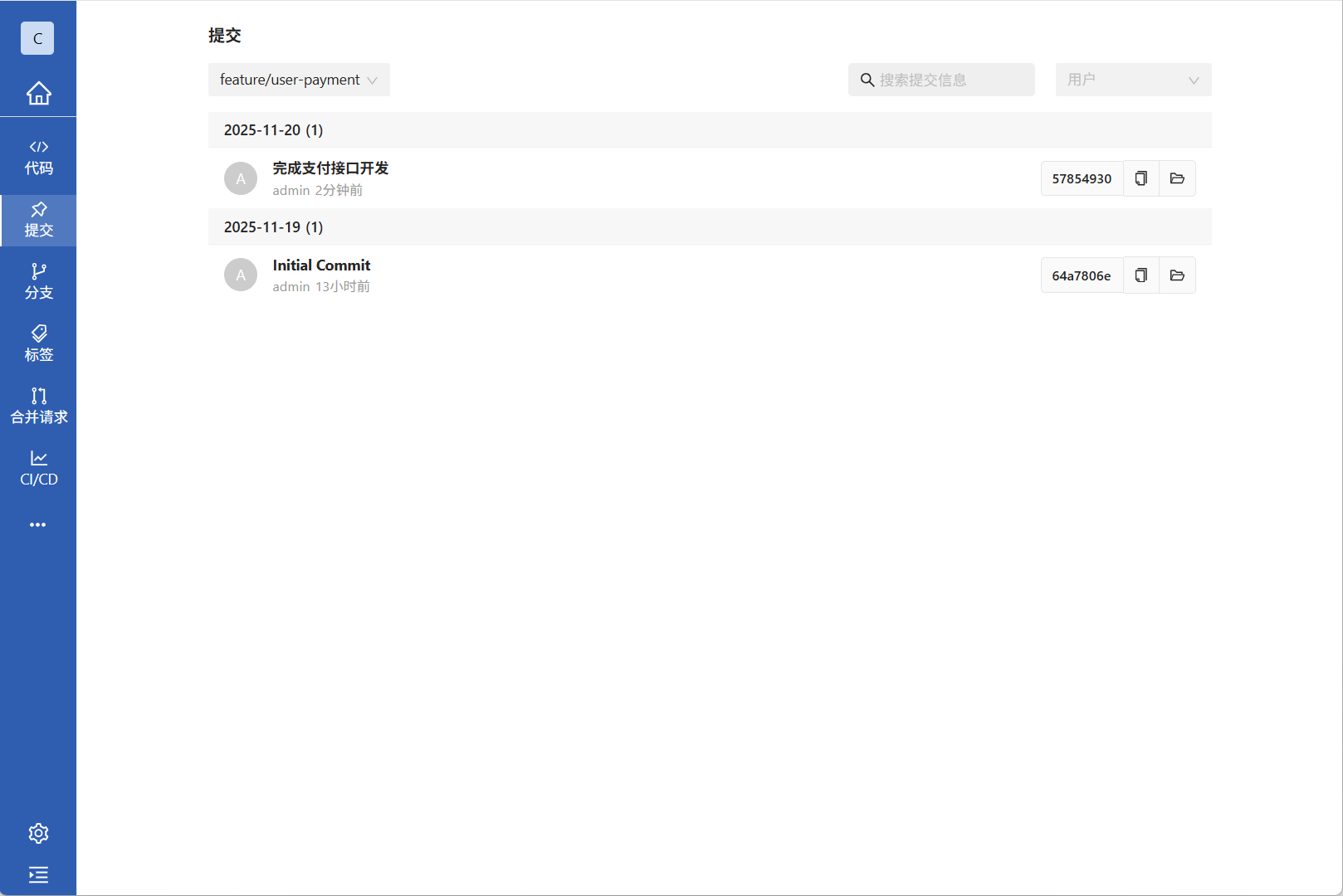
2.创建功能分支后,所有功能类的开发都需要在功能分支中进行开发,提交也是一样
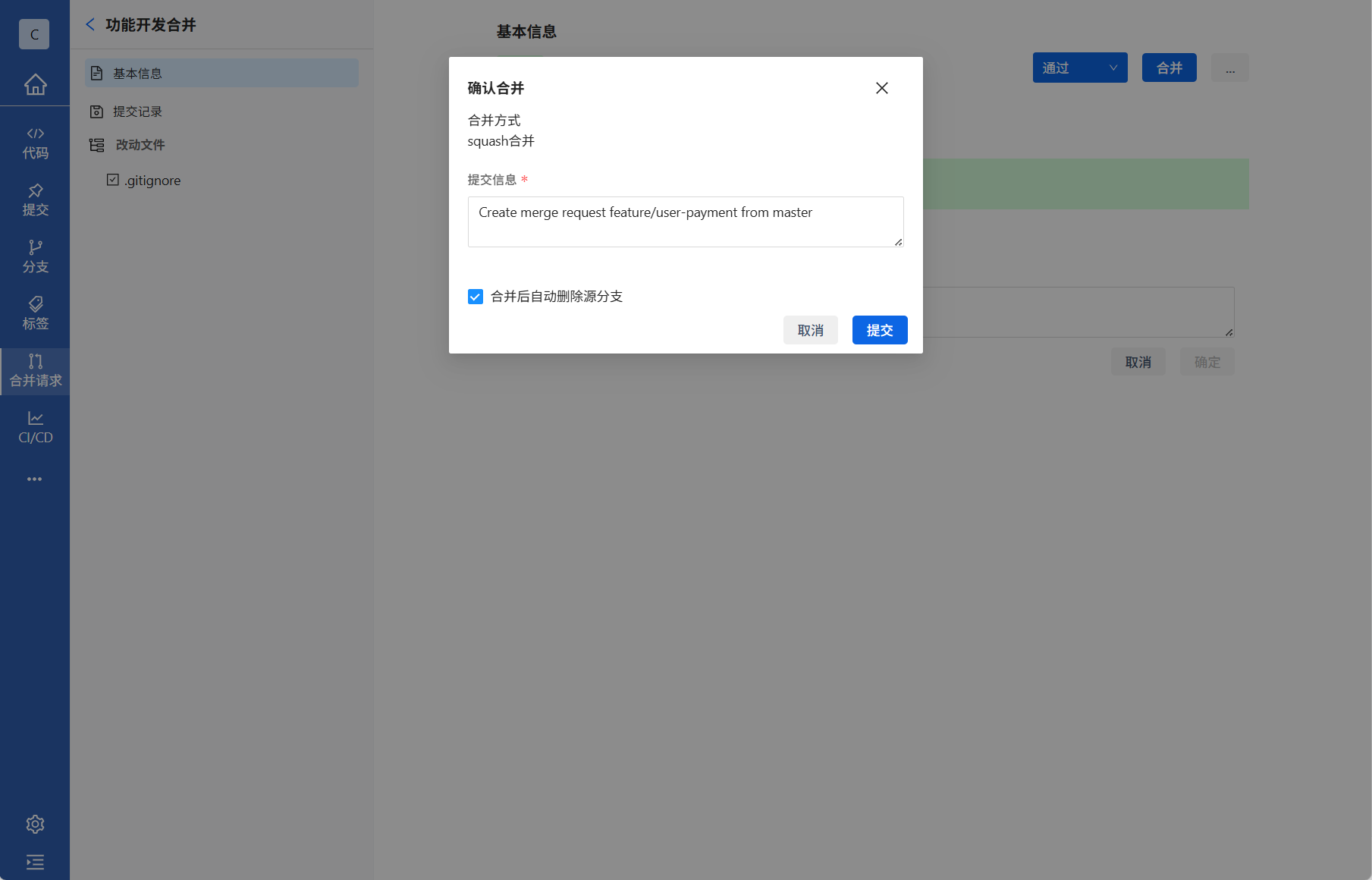
3.开发完成后,可将功能分支合并入开发分支中,合并建议选择squash合并并把合并后自动删除源分支勾选上,保持仓库整洁。
2.3.3 release版本发布
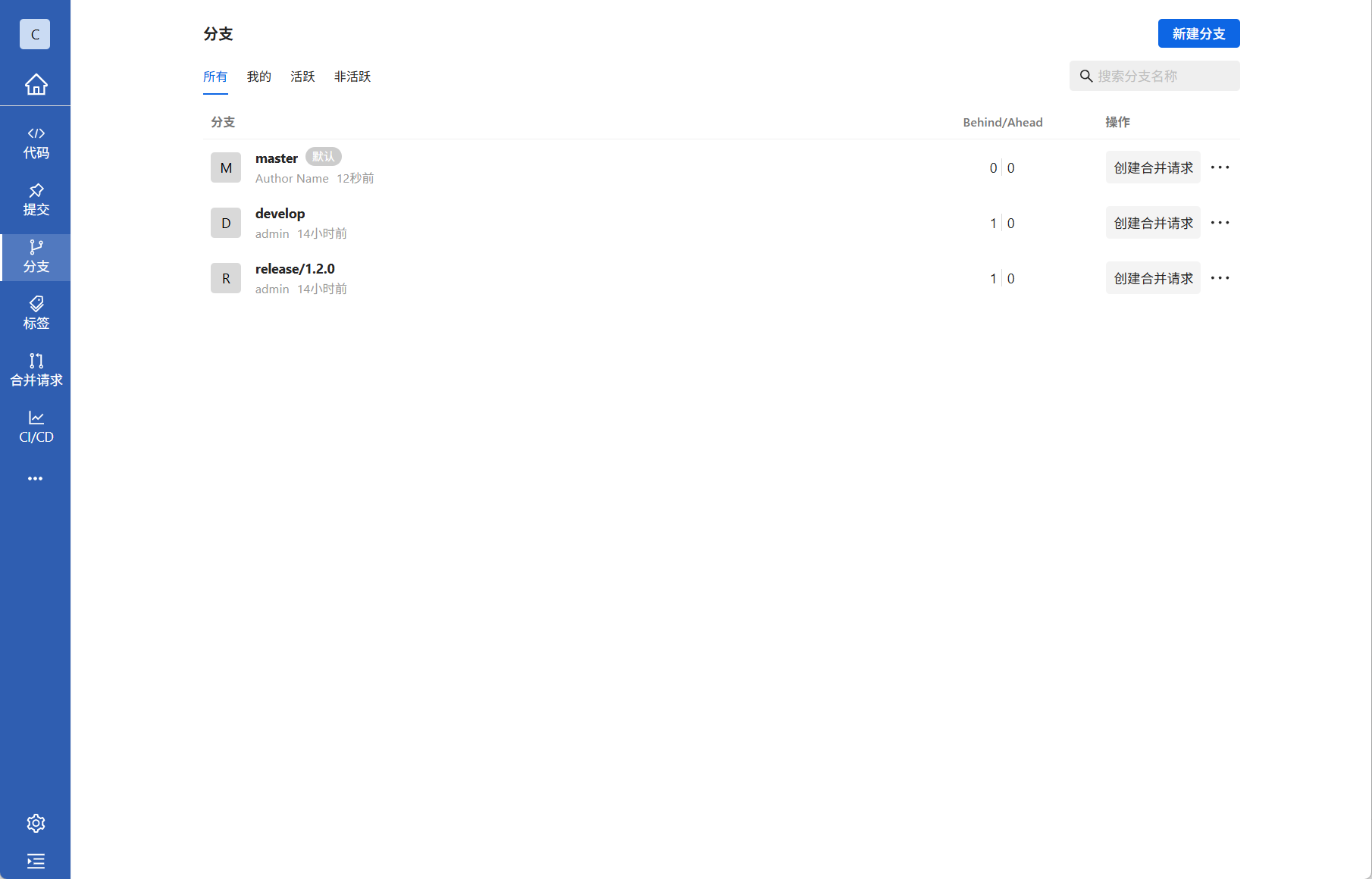
当开发分支(develop)的功能足够进行一次发布时,就可以进行版本发布
从开发分支中创建出发布分支,发布分支命名规范release/版本号
3、Arbess安装与配置
3.1 安装
以Ubuntu操作系统为例
- 下载:Ubuntu安装包下载地址:Arbess下载,点击Ubuntu下载,下载完成后得到tiklab-arbess-2.1.7.deb的文件。
- 安装:上传到服务器上,在文件同级目录执行命令安装。
dpkg -i tiklab-arbess-2.1.7.deb
- 启动,系统默认安装路径为/opt目录,进入/opt/tiklab-arbess/bin目录下,执行./arbess start即可启动成功。
使用 http://ip:9200 进行访问。初始用户名密码admin\123456登录,首次登录根据需要修改管理员密码。成功登录后展示Arbess首页。
3.2 配置
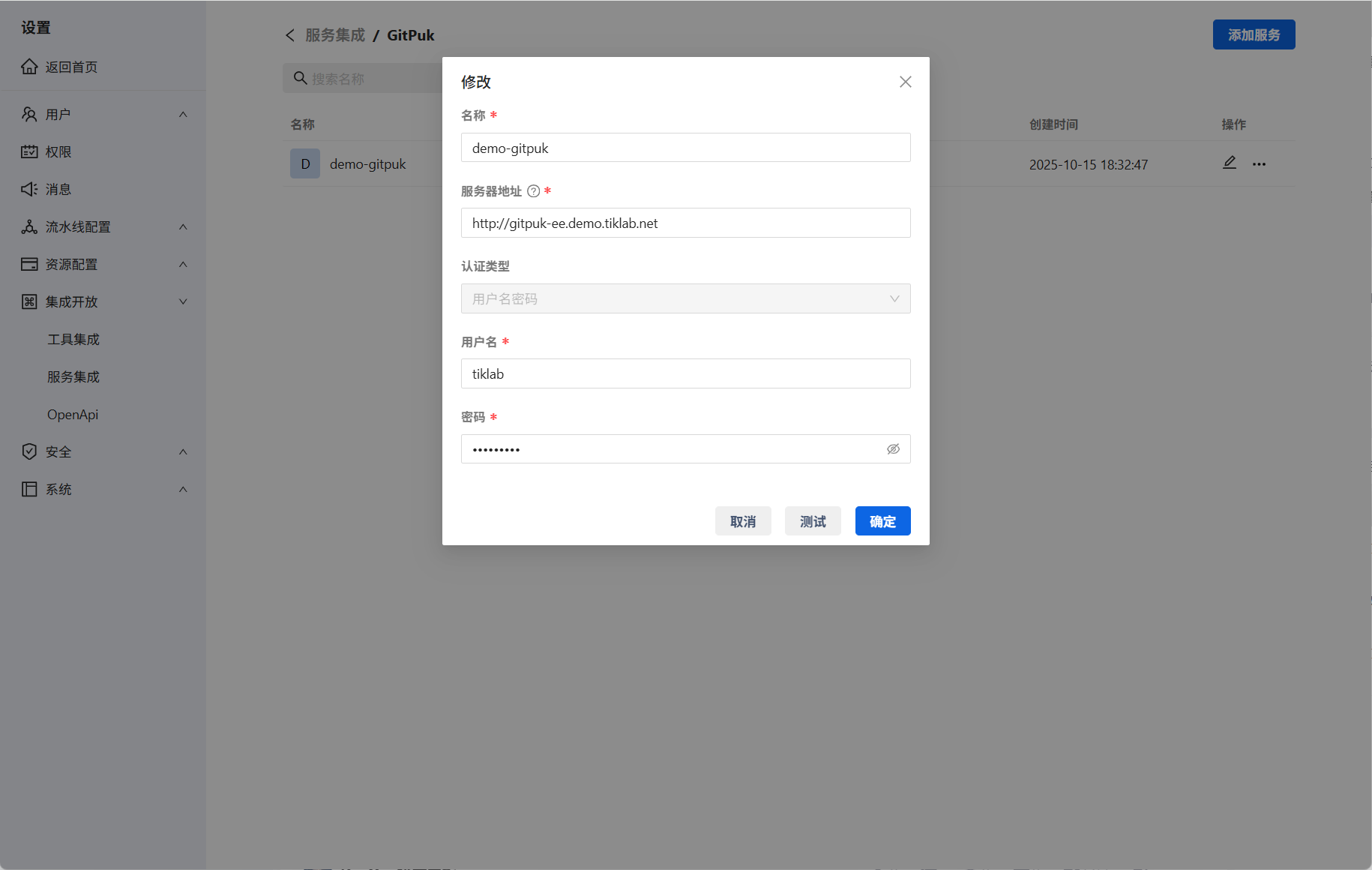
- GitPuk服务集成
在系统设置集成开放中添加服务集成。选择GitPuk、填写名称、服务地址、认证类型(用户名密码或秘钥)、用户名、密码。
3.2.1 构建release分支
进入Arbess添加流水线,点击源码自建GitPuk选择我们需要构建的发布分支填好对应内容点击确定即可
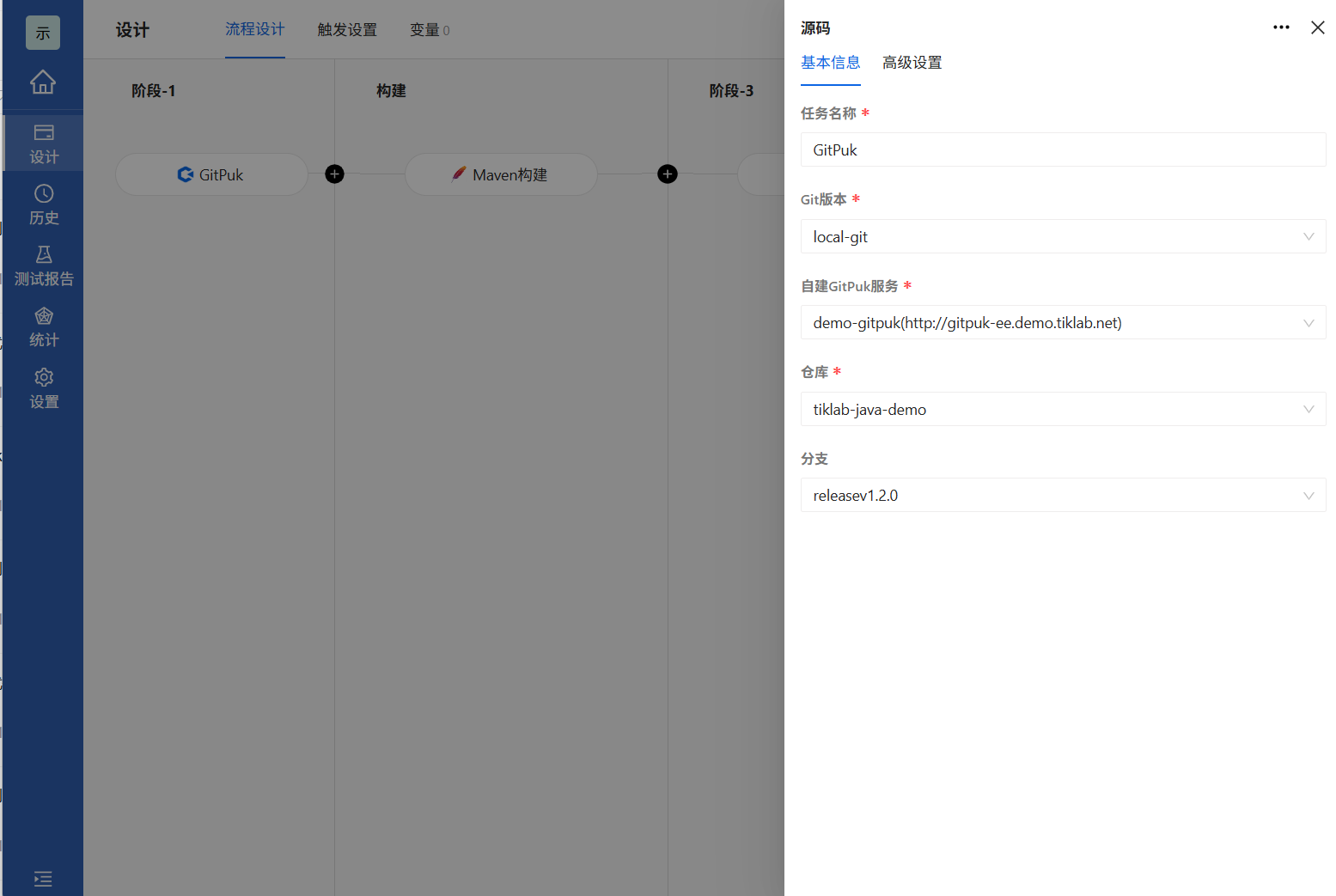
| 字段 | 描述 |
| 任务名称 | 任务名称清晰地标识项目或对象。 |
| Git版本 | Arbess所在服务器Git安装路径。 |
| 自建GitPuk服务 | 自建GitPuk服务地址。 |
| 仓库 | 选择授权信息后点击仓库,程序会自动获取凭证权限下的仓库列表,管理者只需选择需要配置的仓库即可。 |
| 分支 | 选择代码的分支。填写需要拉取远程仓库具体的分支,不填默认为master分支,填写错误会导致任务执行失败。 |
3.2.2 配置Maven构建
源码配置完毕后,配置构建任务,Arbess支持多种构建方式这里以Maven为例,填入对应内容后点击确定即可
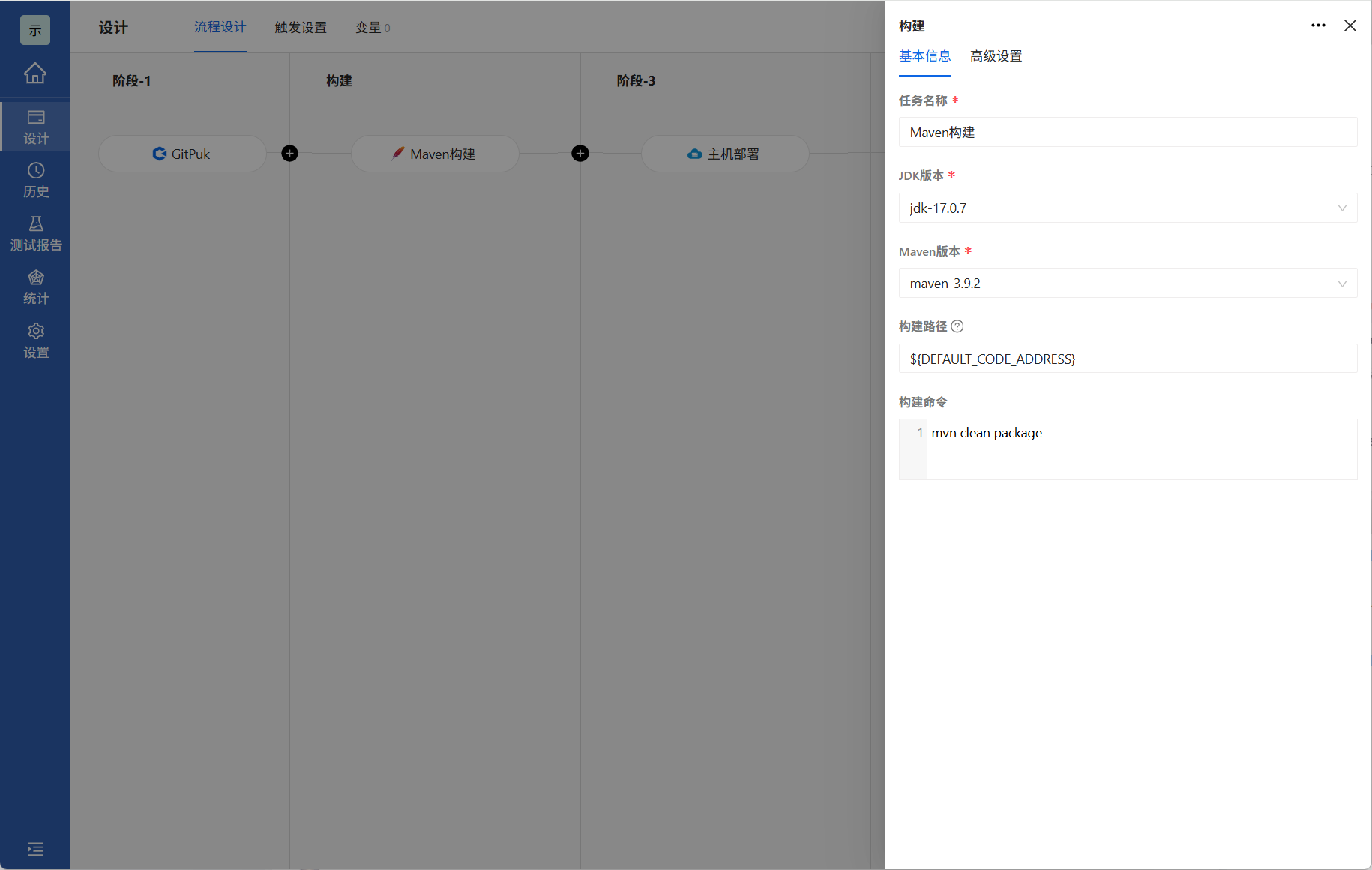
| 字段 | 描述 |
| 任务名称 | 任务名称清晰地标识项目或对象。 |
| JDK版本 | Arbess所在服务器JDK安装路径。 |
| Maven版本 | Arbess所在服务器Maven安装路径 |
| 模块地址 | 构建路径,默认为${DEFAULT_CODE_ADDRESS},也可输入绝对路径。 |
| 执行命令 | 执行Maven构建的命令。 |
3.2.3 配置主机部署
配置主机部署,点击主机部署,输入部署对应信息点击确定即可
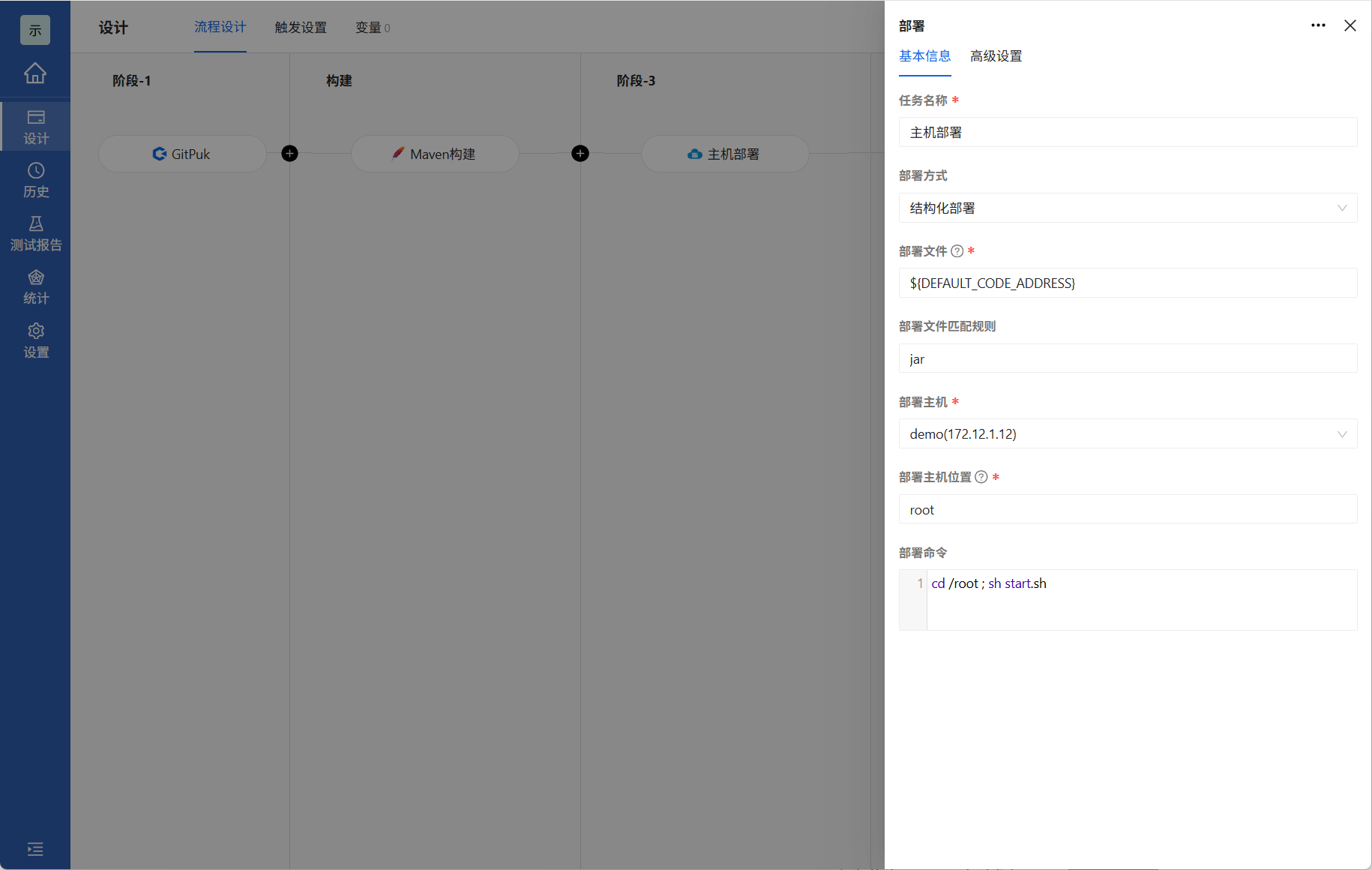
| 字段 | 描述 |
| 任务名称 | 任务名称清晰地标识项目或对象。默认主机部署。 |
| 主机地址 | 部署主机远程SSH认证凭证。 |
| 部署文件 | 需要部署的文件,可以写绝对路径,也可以写泛路径,泛路径需要配合部署文件规则来匹配到部署文件。 |
| 部署文件匹配规则 | 文件匹配规则,支持正则表达式。 |
| 部署位置 | 部署远程主机位置。 |
| 部署命令 | 文件部署命令。 |
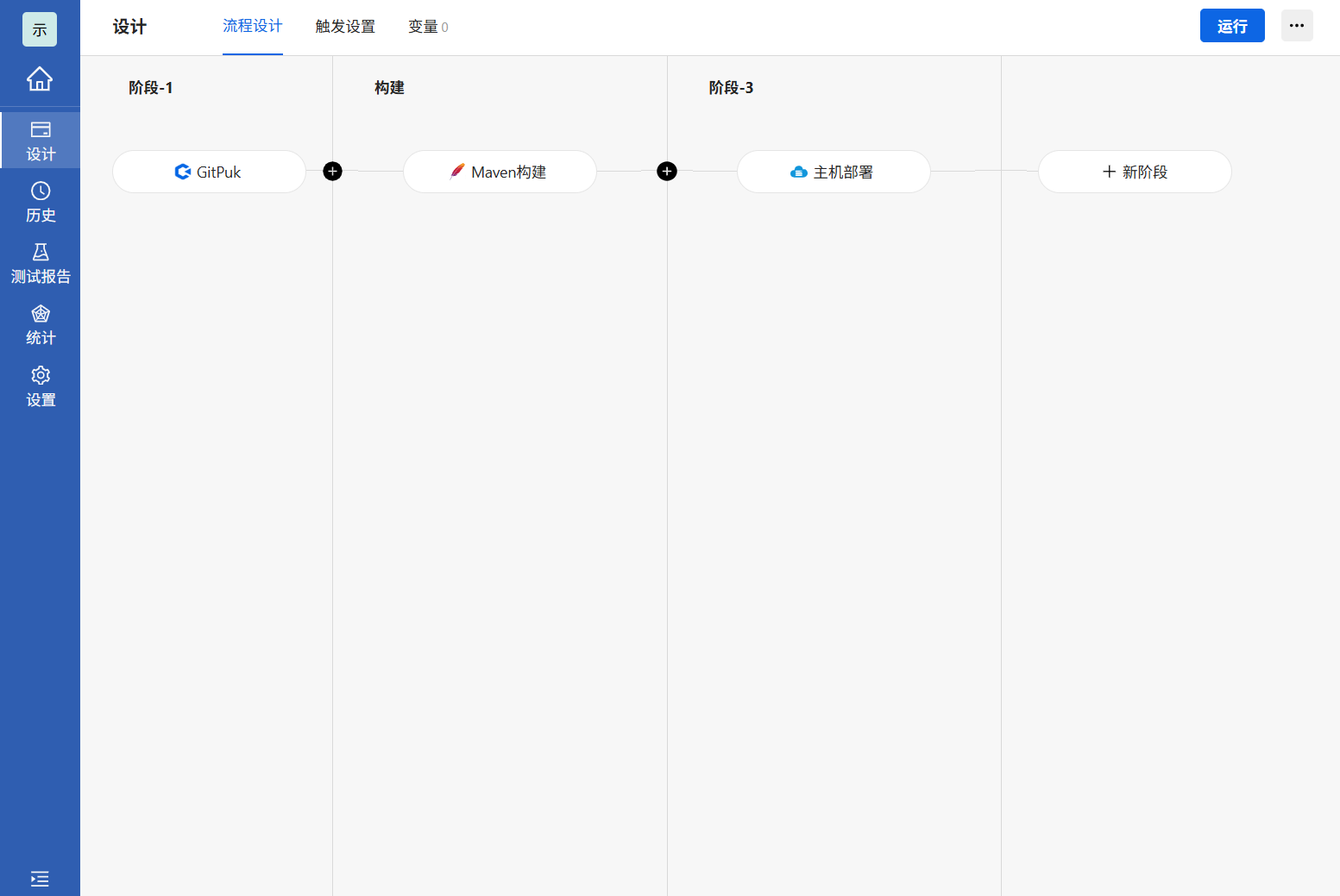
3.3 执行部署
1.全部添加完成后,点击右上角运行按钮进行构建部署等待构建部署完成即可
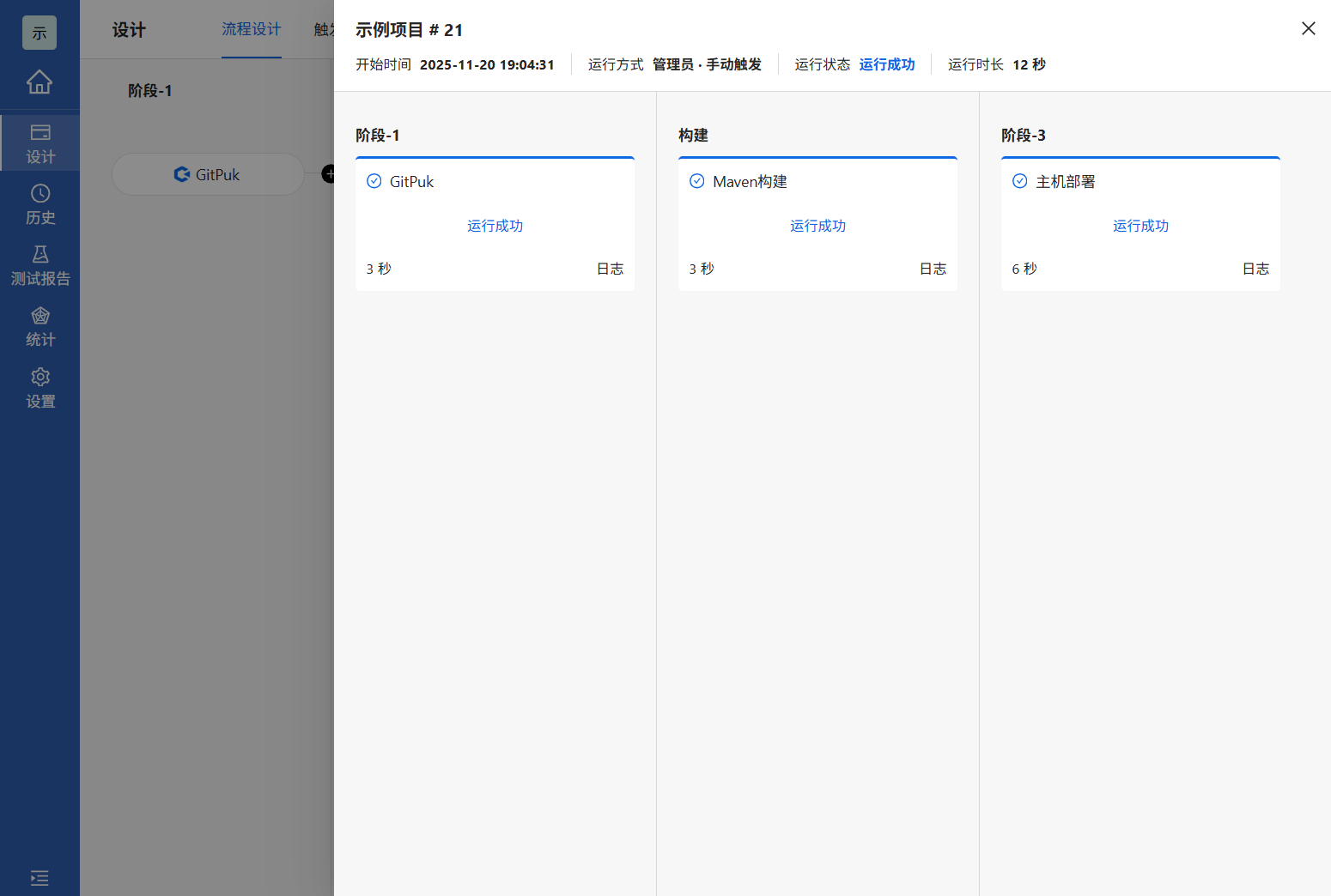
2.构建部署完成后,系统自动跳出完成页面
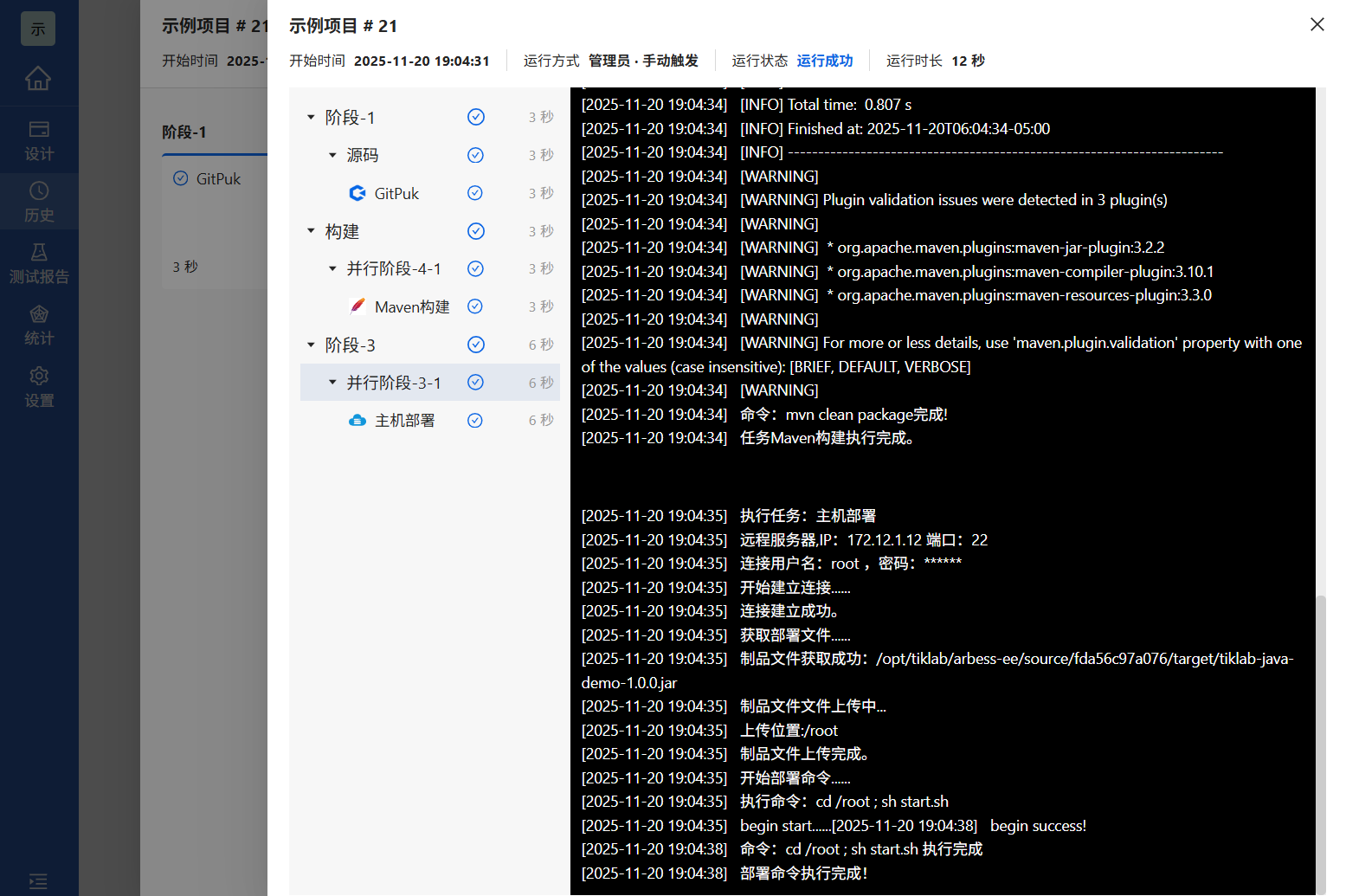
3.点击日志进入日志页面,可以详细查看运行日志

















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









