



在接口管理工具的选择中,Swagger UI是比较常见的工具,PostIn是一款国产开源免费的 API 管理工具,两款工具各有特点。本文将从安装配置、功能、用户体验几个方面对两款软件进行详细对比。
1、安装配置
|
项目 |
Swagger UI | PostIn |
| 安装难度 | 支持一键安装。 | 一键安装,私有部署不同环境均支持傻瓜式一键安装。 |
| 配置难度 | 安装结束需要访问文件获取临时密码。 | 零配置,安装后即刻可用,无需额外配置。 |
| 支持操作系统 | 支持Windows、MacOS、Linux、Docker等系统。 | 支持Windows、MacOS、Linux、Docker等系统。 |
2、功能对比
PostIn是API全生命周期管理平台,Swagger UI主要作用为接口文档管理。下面进行功能对比,主要针对两个平台功能进行详细的对比。
|
模块 |
功能 |
Swagger UI |
PostIn |
|
项目管理 |
项目管理 |
✖ |
✔ |
|
用户管理 | ✖ | ✔ | |
|
权限管理 | ✖ | ✔ | |
| 项目变量 | ✖ | ✔ | |
| 项目参数 | ✖ | ✔ | |
| 环境管理 | ✖ | ✔ | |
|
接口调试 |
HTTP协议 | ✔ | ✔ |
|
WebSocket协议 | ✖ | ✔ | |
|
保存为接口 | ✔ | ✔ | |
| 前置、后置脚本 | ✖ | ✔ | |
| 断言 | ✖ | ✔ | |
| 数据库操作 | ✖ |
✔ | |
|
接口管理 |
API导入 | ✖ | ✔ |
|
API文档 | ✔ | ✔ | |
|
API设计 | ✔ | ✔ | |
|
API测试 | ✔ | ✔ | |
|
API认证 | ✔ | ✔ | |
| 接口分享 | ✔ | ✔ | |
|
IDEA插件 | ✔ | ✔ | |
|
MOCK数据 | ✖ | ✔ | |
| 接口测试 | 接口用例 | ✖ | ✔ |
| 场景用例 | ✖ | ✔ | |
| 性能用例 | ✖ |
✔ | |
| 性能用例分布式运行 | ✖ | ✔ | |
| 测试计划 | ✖ | ✔ | |
| 测试报告 | ✖ | ✔ | |
| 系统设置 | 用户管理 | ✖ | ✔ |
| 权限管理 | ✖ | ✔ | |
| 消息通知方案 | ✖ | ✔ | |
| 消息配置 | ✖ | ✔ | |
|
数据备份还原 | ✔ | ✔ | |
|
IP黑白名单 | ✔ | ✔ | |
|
日志管理 | ✔ | ✔ |
- 接口调试
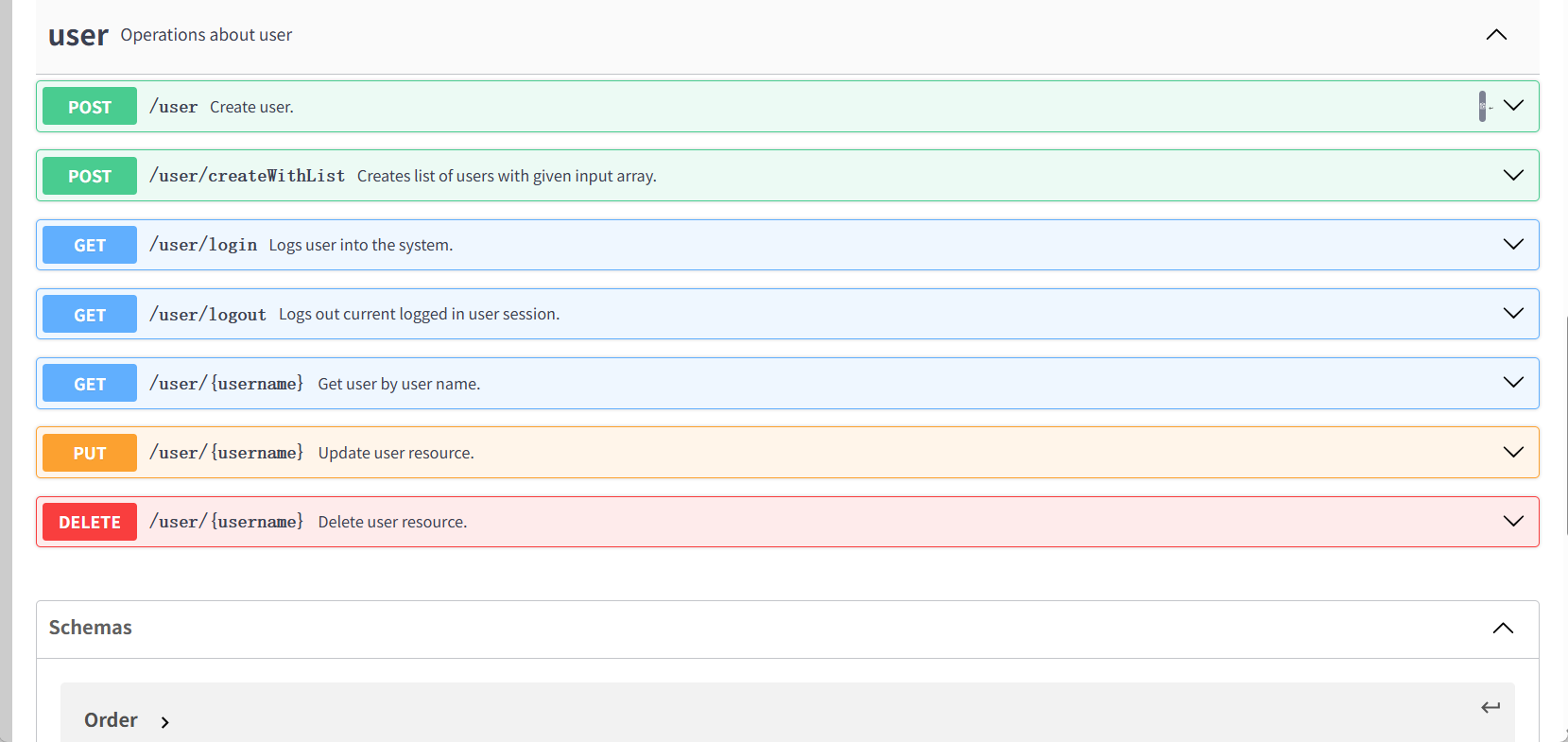 Swagger UI接口调试
Swagger UI接口调试
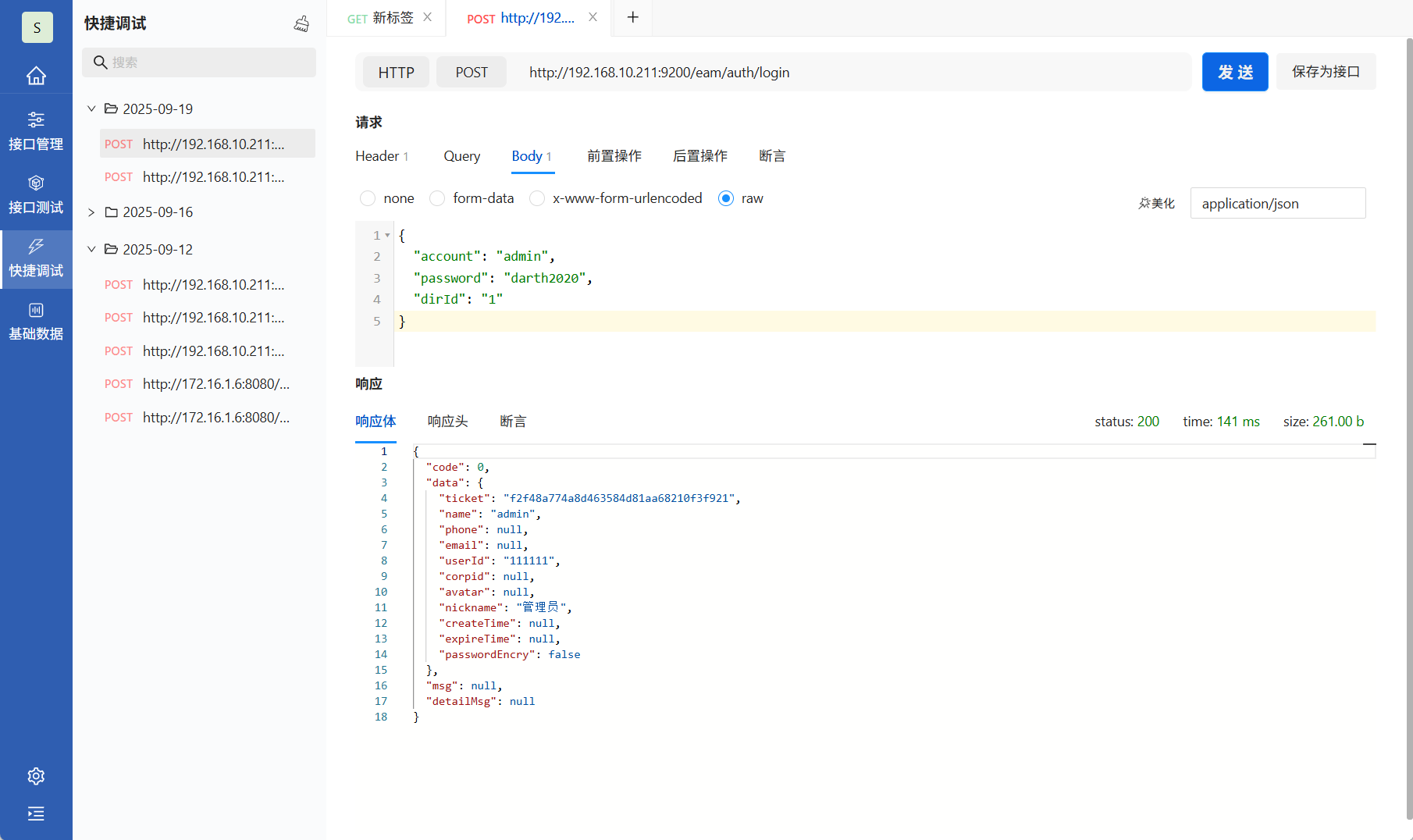 PostIn接口调试
PostIn接口调试
- 接口管理
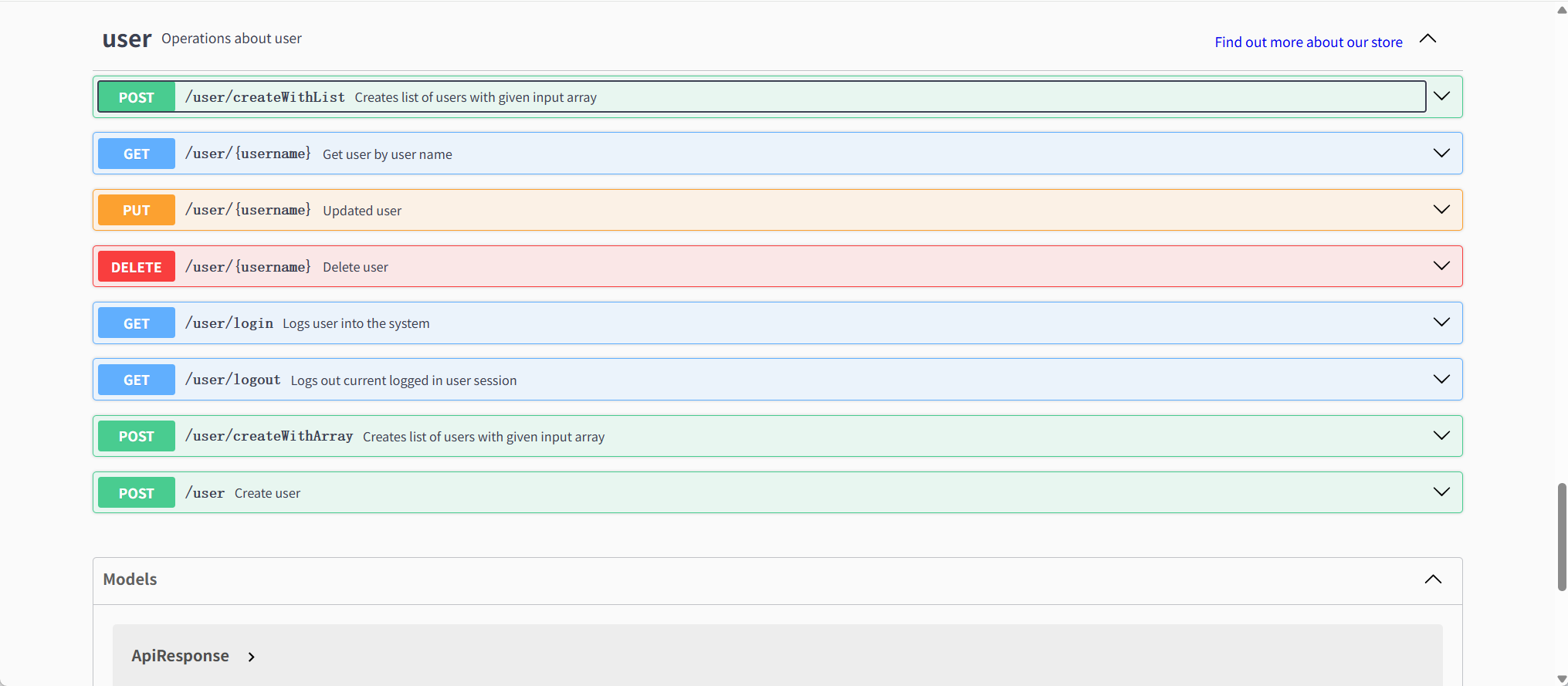 Swagger UI接口列表
Swagger UI接口列表
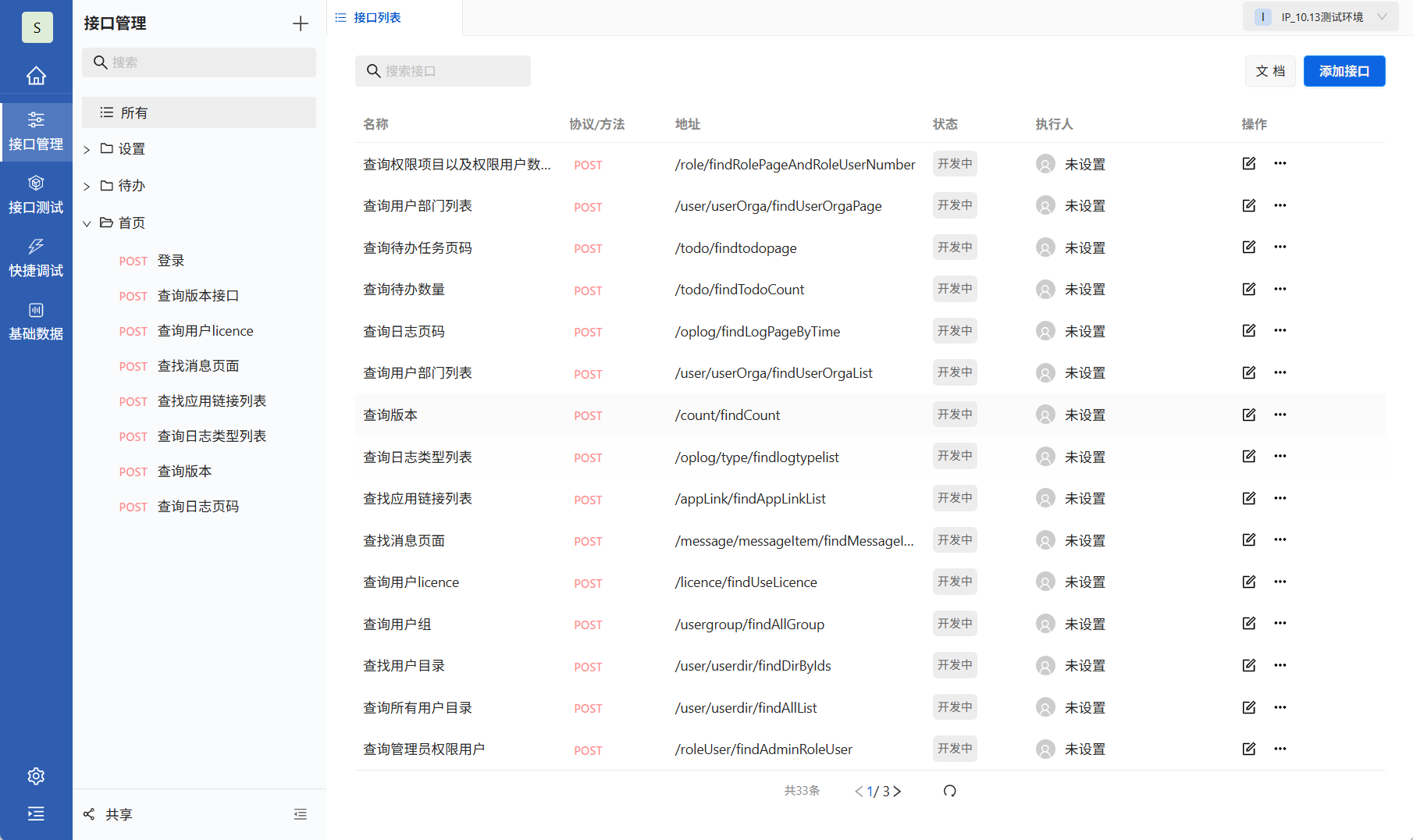 PostIn接口列表
PostIn接口列表
- 接口测试
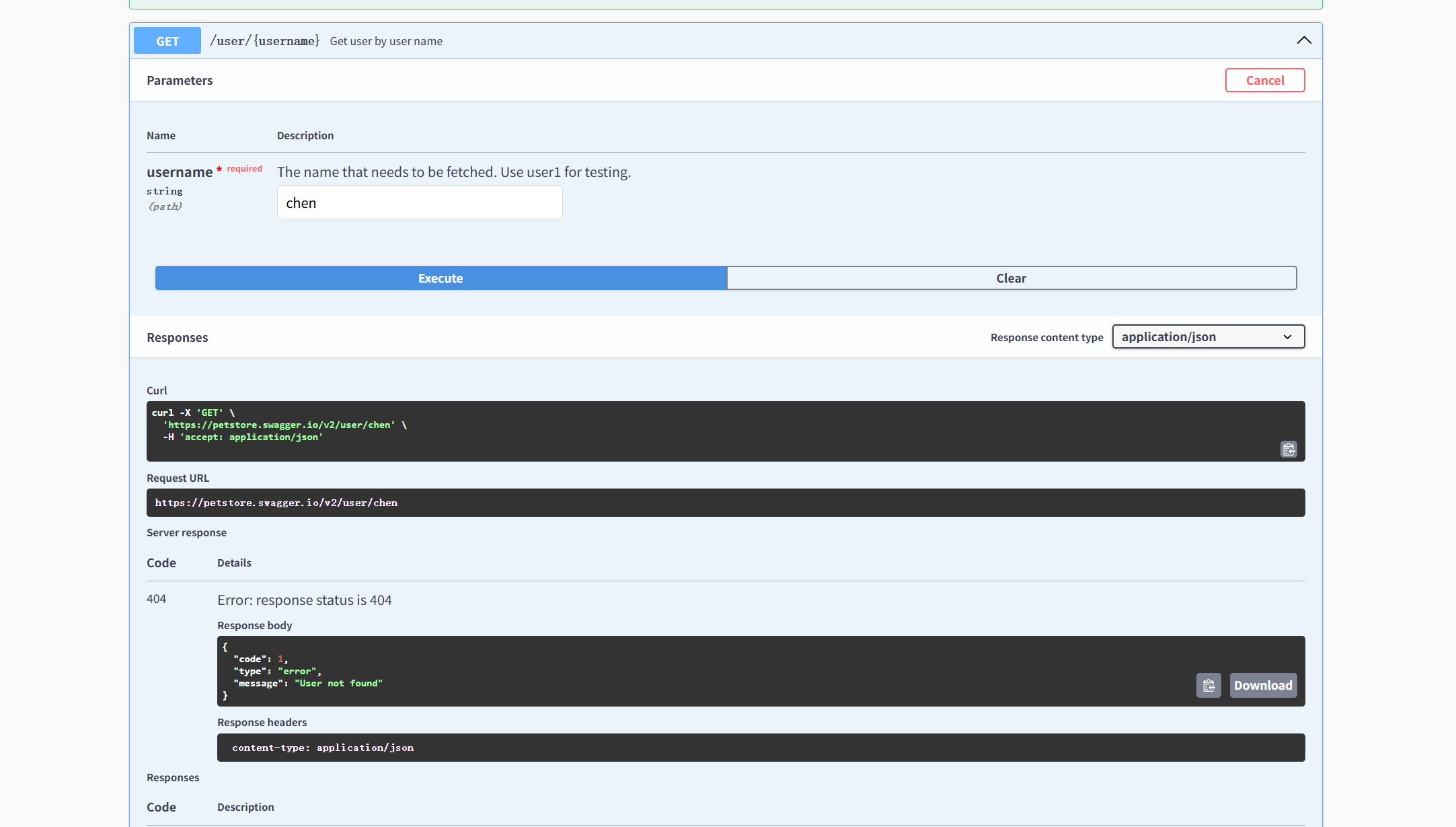 Swagger UI接口测试
Swagger UI接口测试
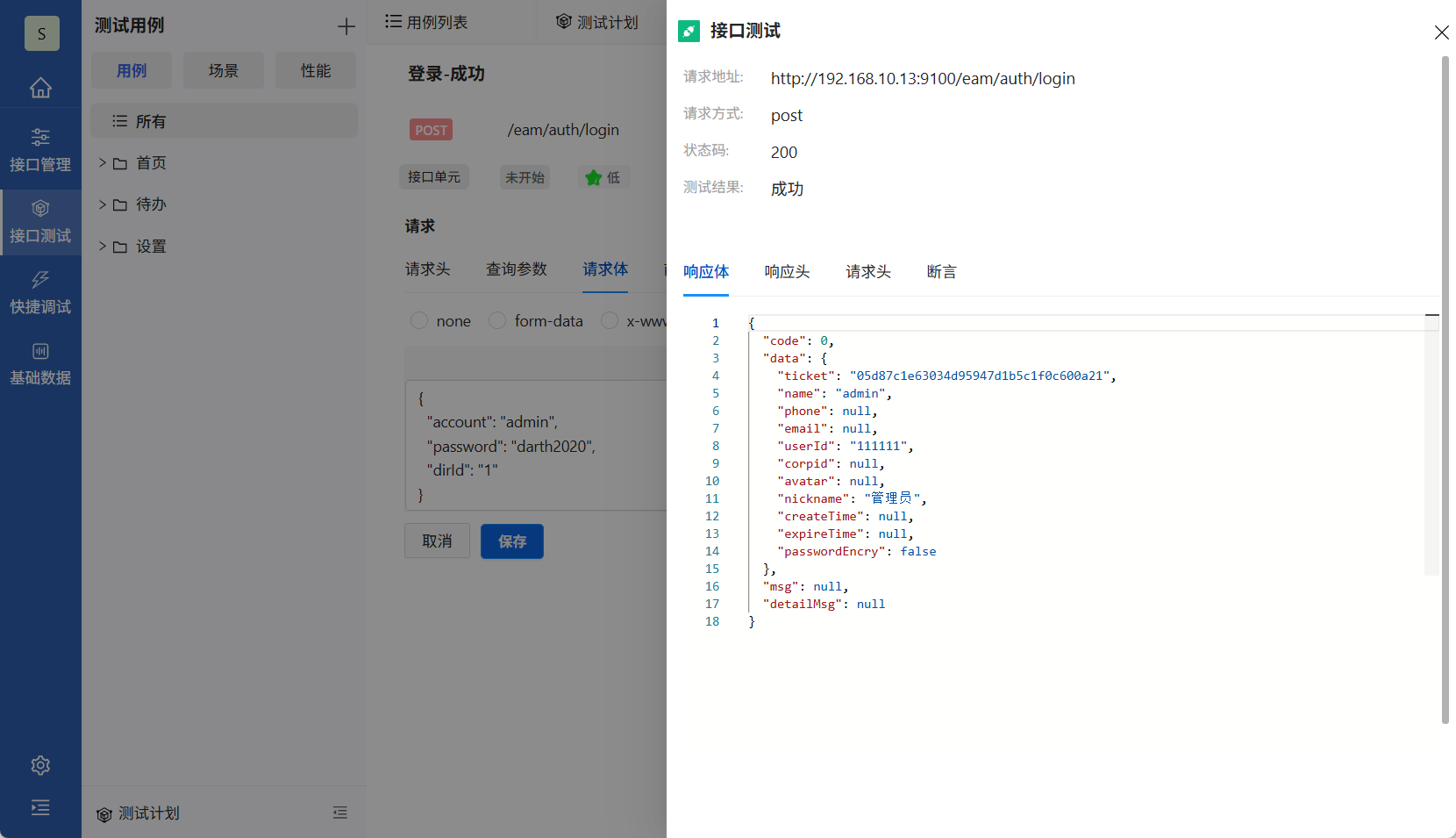 PostIn接口测试
PostIn接口测试
3、系统集成
|
项目 |
Swagger UI |
PostIn |
| IDEA插件 | 不支持 | 支持通过IDEA插件扫描代码一键上传接口 |
| CICD工具 | 与主流 CI/CD 工具 Jenkins集成,实现 API 文档的自动化生成。 | 与Arbess集成,实现运行流水线自动触发测试计划。 |
| 账号体系 | 仅限于软件注册用户 | 与LDAP、企业微信、钉钉集成,同步用户并登录 |
| IM消息集成 | 不支持 | 支持站内信、邮箱、企业微信通知 |
| 接口导入导出 | 支持导入OpenAPI格式文件。 | 支持Postman Collection v2.0/2.1、Swagger 2.0、OpenAPI 3.0/3.1导入,接口导出。 |
| OpenApi | 不提供 | 提供完整的OpenAPI接口 |
4、用户体验
|
项目 |
Swagger UI |
PostIn |
| 安装配置 | Docker支持一键安装,其余环境需要依赖才可以安装安装较为复杂 | 一键式安装,安装便捷,零配置 |
| UI交互体验 | 默认布局不够直观。 | 界面干净简洁,用户体验较好,支持切换个性化主题。 |
| 上手难度 | 上手难度低 | 所见即所得,配置简单,上手难度低 |
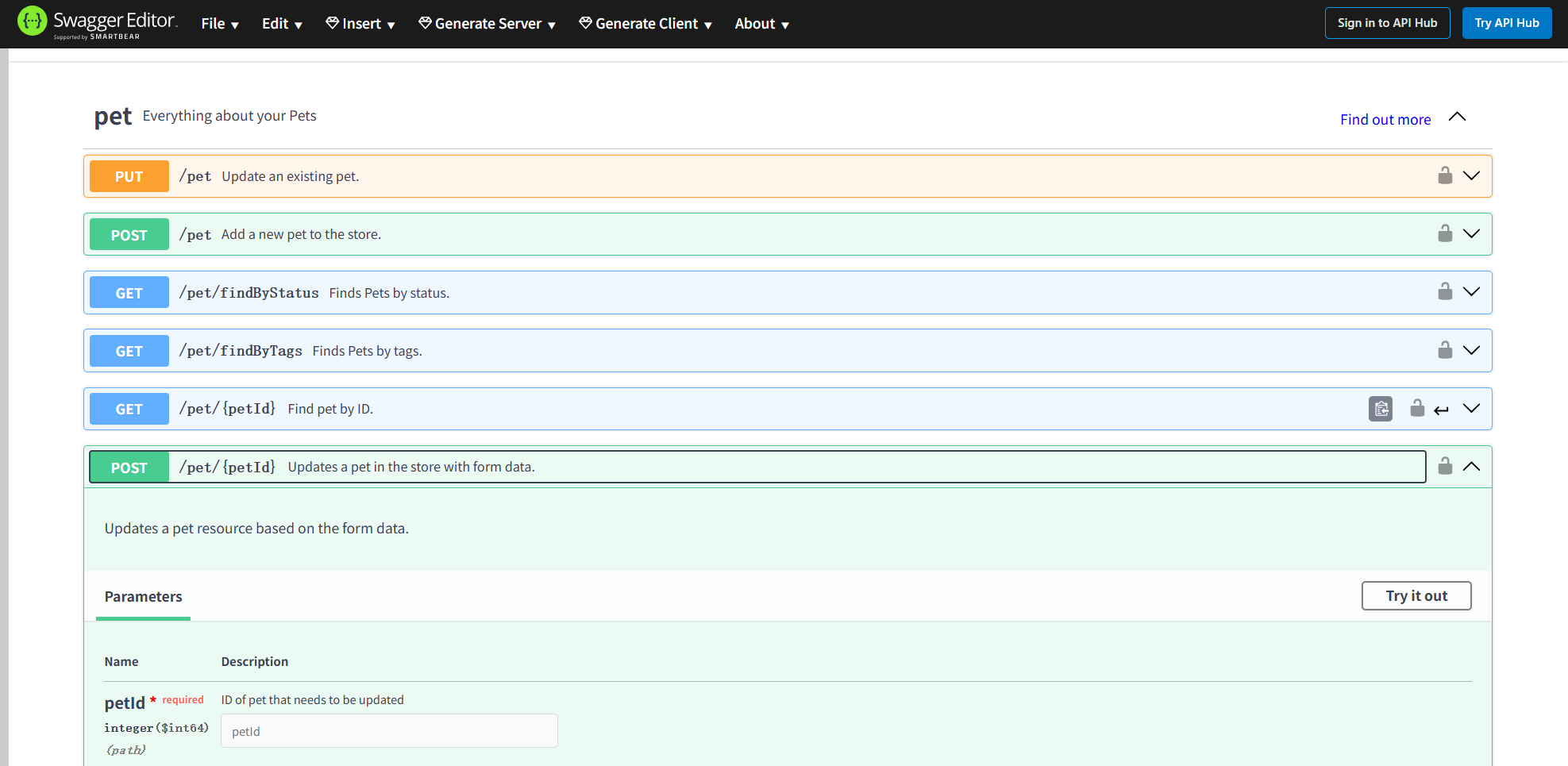 Swagger界面
Swagger界面
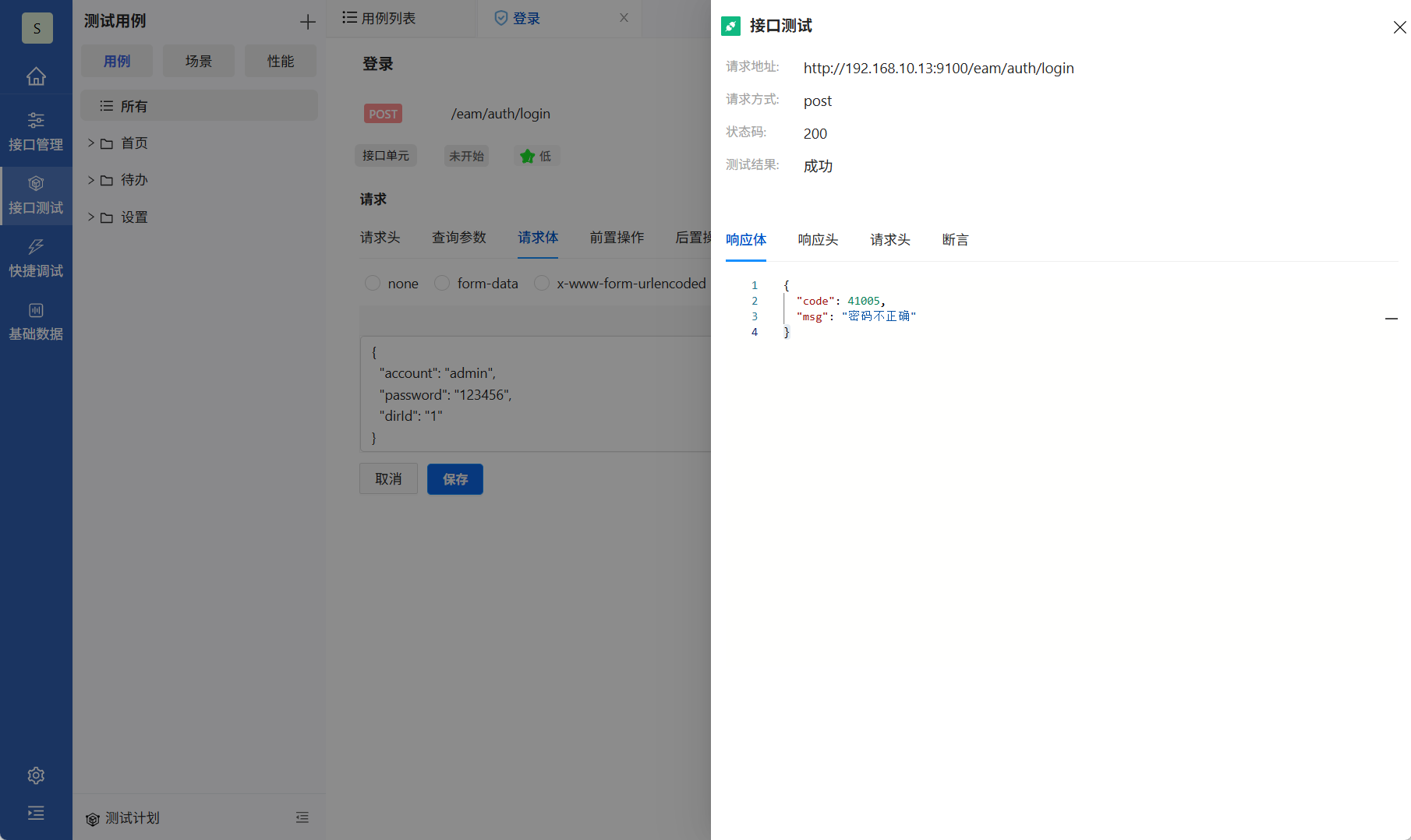 PostIn测试界面
PostIn测试界面
5、开源免费
|
项目 |
Swagger UI |
PostIn |
|
是否开源免费 | 开源免费 | 开源免费 |
6、服务支持
|
项目 |
Swagger UI |
PostIn |
|
服务支持 | 国际化技术支持,出现问题处理难度高。 | 本土化技术支持,7*24小时服务热线;提供工单系统快速反馈和响应问题;企业专属IM群,一对一服务支持。 |

















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









