




 本文对比了使用标准C语言与ARMNeonintrinsics进行数组操作的代码实现,展示了如何利用Neon指令集加速数据处理。通过GCC编译器的不同编译选项,观察到ARMv8.2后Neon指令的变化,仅保留Neon寄存器。
本文对比了使用标准C语言与ARMNeonintrinsics进行数组操作的代码实现,展示了如何利用Neon指令集加速数据处理。通过GCC编译器的不同编译选项,观察到ARMv8.2后Neon指令的变化,仅保留Neon寄存器。
#include <stdio.h>
unsigned short int A[] = {1,2,3,4}; // array with 4 elements
int main(void)
{
for(int i=0;i<4;++i)
{
A[i]+=A[i];
}
return 0;
}
对应的neon intrinsics
#include <stdio.h>
#include <arm_neon.h>
unsigned short int A[] = {1,2,3,4}; // array with 4 elements
int main(void)
{
uint16x4_t v; // declare a vector of four 16-bit lanes
v = vld1_u16(A); // load the array from memory into a vector
v = vadd_u16(v,v); // double each element in the vector
vst1_u16(A, v); // store the vector back to memory
return 0;
}
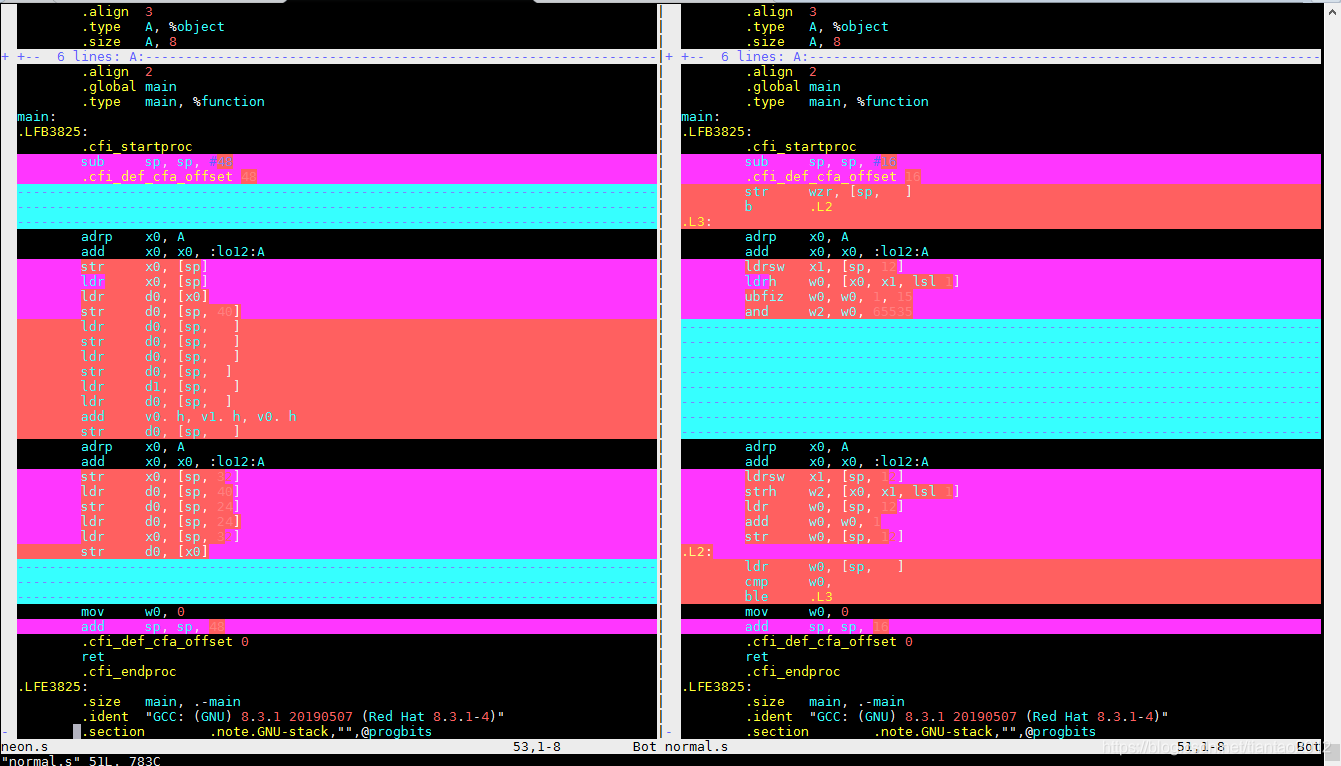
编译命令gcc -S normal.c -o normal.s
normal和neon 汇编的对比,可以明显看到armv8.2 后,没有neon指令了,只有neon 寄存器.其中v 代表neon 寄存器,B 代表8
bit,H 代表16 bit.S 代表32bit,D代表64 bit

















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









