






总览
Rowkey 表是一种优化的数据存储表,通过指定唯一主键来避免数据重复,专为提高数据写入和读取性能而设计。通过设置 rowkey,ArgoDB 实现了高性能的 UPSERT 能力,即在写入时能够直接定位数据行,避免全表扫描,实现快速的整行或部分列更新,确保数据的唯一性。
背景信息
在传统的数据存储方案中,读时合并(MOR)被广泛应用于实现快速数据写入的场景,其原理是通过将新数据追加到 Delta 文件中,而不是直接修改基础数据文件(Base 文件),从而大幅提高了写入速度,有效避免写入过程中对现有数据的直接修改,减少写入锁定和资源争用。
然而,在读取数据时,MOR 机制需要将 Base 文件和 Delta 文件进行合并。这种读时合并操作会显著增加读取时的计算开销,导致查询性能下降,尤其是在数据频繁变更和大量查询请求的场景下。这种高开销的合并操作会拖慢系统响应时间,不利于实时数据访问需求。
为克服传统 MOR 机制的不足,在 ArgoDB 6.0 版本中,我们引入了 Rowkey 表(性能增强版),通过优化数据组织和管理方式,实现了快速写入和高效读取:
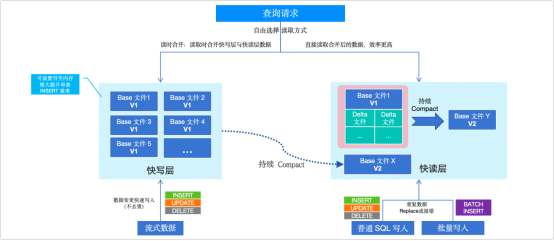
快速写入:通过 Slipstream 或 ArgoDB API 等方式将实时数据写入至 Rowkey 表,写入时仅将基础数据文件写入快写层,无需立即进行去重和合并操作,从而实现实时数据的极速写入。
高效读取:系统后台自动执行合并操作,将写入的基础数据文件合并去重后转移至快读层。这种分层机制确保读取时无需额外的合并处理,同时结合向量化引擎加速查询,大幅提升查询效率。
一致性选择:根据业务需求选择不同的读取层来平衡数据一致性和读取性能。例如需要获取最新数据,可以选择从快写层读取(采用 MOR 策略,可能会有一些合并开销);如果需要读取速度优先,则可以选择从快读层读取,这样可以提供稳定的高性能查询,但数据的最新状态可能存在轻微的延迟,取决于后台合并操作的策略配置。
功能对比
| 对比项 | Rowkey 表(性能增强版) | Rowkey 表(普通版) |
|---|---|---|
| Linac 计算引擎加速(快读模式下) | ||
| 数据分层管理 | ||
| 快读层加速查询 | ||
| 极速单行插入 | ||
| 接入实时数据流 | ||
| 读时合并(MOR) |
建表语法介绍
创建 Rowkey 表
CREATE TABLE [IF NOT EXISTS] [<database_name>.]<table_name>(
<column_name1> <DATATYPE1> [NOT NULL] [COMMENT "<text>"],
<column_name2> <DATATYPE2> [NOT NULL] [COMMENT "<text>"],
<column_name3> <DATATYPE3> [NOT NULL] [COMMENT "<text>"],
...
)
[PARTITIONED BY ...]
CLUSTERED BY (<bucket_column1>, <bucket_column2>, ...) [INTO <num_buckets> BUCKETS]
STORED AS HOLODESK
TBLPROPERTIES("holodesk.rowkey" ="<rowkey_column1>, <rowkey_column2>, ...", "<property_name>"="<property_value>", ...)参数说明
- <database_name>(可选): 指定创建表的数据库名称。
- <table_name>: 表名称。
- <column_name>: 列名称,后跟数据类型 <DATATYPE>,支持非空约束 [NOT NULL] 和列描述 [COMMENT "<text>"]。
- <DATATYPE>: 列的数据类型。
- <text>: 列的描述文本。
- <num_buckets>(可选): 分桶数,默认由 ArgoDB 自动计算,可覆盖大部分业务场景,计算方式为 数据磁盘总数 * 2,然后取比其大的相邻质数,例如磁盘数为 12,先将其乘以 2,再向上取相邻质数,则默认分桶数为 29。
| 此外,分桶默认系数的值可通过参数控制,例如 SET argodb.default.bucket.ratio=5,则在自动计算时,采用 数据磁盘总数 * 5 来计算。 |
- <bucket_column>: 用于分桶的列名。
- <rowkey_column>: 设置为 Rowkey 的字段必须是唯一且非空的列或列组合,且必须在一个 SQL 语句中完整定义。Rowkey 可以与分桶键完全一致,或者由分桶列和普通列组合而成,但在这种情况下,分桶键必须为单列,且应是 Rowkey 中的第一个字段。
| 不支持修改表 Rowkey,如需修改请重新建表。Rowkey 字段不支持以下数据类型:BLOB、CLOB、NUMBER、DECIMAL、FLOAT、DOUBLE、VARCHAR 和 VARCHAR2。 |
附加可选项
- IF NOT EXISTS: 如果指定表已存在,不会报错。
- COMMENT: 为表添加注释,注释需放在引号内。
- PARTITIONED BY:支持创建分区 Rowkey 表,此时的 Rowkey 键为分区级唯一。
- INTO <num_buckets> BUCKETS: 指定表的分桶数。
- <property_name>, <property_value>: 表的其他属性名称及其值,多个属性设置间使用英文逗号(,)分隔。属性名称和对应的属性值,均大小写敏感。
| 在 ArgoDB 5.2 及早期版本中,Rowkey 表的 rowkey 键必须与分桶列完全一致,且为传统 MOR 模式。如需在 6.0 版本中创建此类表,需要执行 set holodesk.rowkey.version=v0; 后,再执行建表操作。 |
建表示例
在下述命令示例中,Rowkey 键是由分桶列和普通列组合而成,其中分桶键 id 是 Rowkey 键的第一个字段。
CREATE TABLE IF NOT EXISTS v1_mrk_bucket_product (
id INT,
prod_NO INT,
prod_name STRING,
prod_time DATE,
price DOUBLE
)
CLUSTERED BY (id)
STORED AS HOLODESK
TBLPROPERTIES ("holodesk.rowkey" = "id,prod_NO");数据写入
Rowkey 表支持高性能的 UPSERT 能力,通过 INSERT 写入数据时直接定位分区唯一的 Rowkey 键数据行,并根据 Rowkey 键值选择更新(UPDATE)或插入(INSERT)。
| ArgoDB 通过 Rowkey 实现了 UPSERT 功能,无需使用 UPSERT 语法,执行数据插入(如 INSERT)时可自动判断数据是否存在并进行更新或插入。 |
Rowkey 表支持以下数据写入方式:
- 实时数据写入:支持通过 Slipstream 或 Sink API 等方式将实时流数据写入至 Rowkey 表,写入时仅将基础数据文件写入快写层,无需立即进行去重和合并操作,从而实现实时数据的极速写入。
- 批量数据写入:支持使用 BATCHINSERT 或 INSERT INTO SELECT 批量插入数据至 Rowkey 表中,写入的同时立刻触发去重合并至快读层,实现批量数据的实时读取。
读取快读层数据
ArgoDB 通过引入写入与查询数据分层的创新方式,进一步增强了 Rowkey 表的查询性能,支持同时实现快速写入和快速查询。为了更好地平衡数据实时性与读取性能,我们提供了 Quark 参数 argodb.rowkey.table.fast.read.mode,让用户灵活控制读取行为,取值说明如下:
- true(默认):仅读取已合并(Compact)的快读层数据,从而显著提升读取性能。虽然这可能会导致数据新鲜度有所降低,但您可以通过调整 Compact Service 服务参数 来提升数据新鲜度至毫秒级,为用户提供更加实时的查询体验。
- false:采用读时合并策略,读取快写层和快读层的数据,以确保数据的完整性和实时性。
提升数据新鲜度
通过调整 Compact Service 的资源配置和触发频率,可以有效降低数据延迟,提高快读层的数据新鲜度。
| 建议适当调低以下 Quark 服务参数的默认值,以增加 Compact 触发频率,不仅能防止小文件数量过多影响读取性能,还能确保文件生成速率不超过 Compact 处理能力,从而避免小文件数超过 50,000 可能引发的实时写入任务失败。 |
| 参数 | 默认值 | 说明 |
|---|---|---|
| holodesk.compact.init.interval | 1 | 设置 Init 线程的休眠时间,单位为秒 |
| holodesk.compact.table.interval | 5 | 设置同一表同一分区之间执行 Compact 的最小间隔时间,单位为秒 |
| holodesk.compact.thread.max | 6 | 限制 Compact 操作的最大并发线程数 |
| holodesk.compact.worker.interval | 1 | 设置 worker 线程在运行周期中的休眠时间,单位为秒 |
| holodesk.fullcompaction.single.task.filenum.threshold | 30 | 控制每个 fullcompact 任务处理的小文件数量上限 |
以下是一个配置示例,可供参考:
set holodesk.compact.init.interval=1
set holodesk.compact.table.interval=5
set holodesk.compact.thread.max=5
set holodesk.compact.worker.interval=1
set holodesk.fullcompaction.single.task.filenum.threshold=20除配置自动合并外,您还可以通过执行 EXECUTE SYNCTABLE <rowkey_table>; 格式的命令手动触发。
启用极速单行插入
面对小规模的低频数据写入,例如风险监测、用户交互数据等,传统的分布式数据库由于架构开销较大,常常难以应对单条数据的实时写入需求。
为了解决这一问题,ArgoDB 6.1 版本推出了基于 SQL 的轻负载实时入库方案,其原理是通过对单条数据插入性能和处理路径的优化(免去事务开销),系统无需依赖额外组件,即可实现高效、低延迟的数据写入,确保在轻负载场景下依然保持快速响应能力。
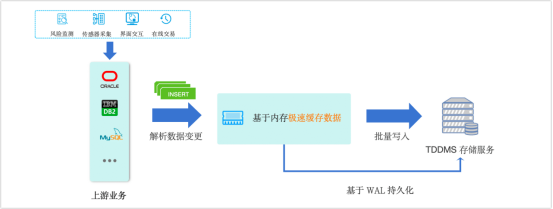
如上图所示,ArgoDB 将上游解析到 INSERT 操作写入至内存中进行缓存,并通过 WAL 日志实现数据持久化,后续以微批的形式写入到 TDDMS 存储服务中,实现数据的极速插入,优势如下:
- 快速响应:大幅提升数据插入效率,确保在持续低频次的写入场景下依然保持高响应性。
- 无需额外组件:无需依赖工具或中间件,简化了系统架构,降低了运维成本。
- 稳定性提升:不仅能够处理持续的数据流入,还有效减少了传统框架中频繁的小文件写入带来的存储开销和性能瓶颈。
注意事项
快速插入功能仅针对 INSERT VALUES 操作,不支持 UPDATE、DELETE 操作。
系统在建表时会自动为 rowkey 列创建索引,加速所有基于 rowkey 的查询,并确保查询实时数据。
对于非 rowkey 列的查询,您需要等待数据刷写至磁盘后才能获取最新数据,刷写操作会在以下情况触发:
内存缓存数据达到 500 条。
到达自动刷写周期(1 分钟)。
手动触发刷写。
使用示例
1、执行下述命令开启快速插入功能及其关联性配置。
-- 设置为性能增强版 rowkey 表
set holodesk.rowkey.version=v1;
-- 启用 Linac 向量化计算引擎与编译器
set use.linac=true;set use.linac.compiler=true;
-- 启用快速插入模式
set linac.compiler.insert.enable=true;set argodb.fast.insert.values.enabled=true;
-- 启用读取快读层数据模式
set argodb.rowkey.table.fast.read.mode=true;2、创建 rowkey 表,并通过表属性设置('holodesk.real.time.enabled'='true')启用实时单行快速插入能力。
CREATE TABLE IF NOT EXISTS fast_insert_demo (
id INT,
prod_name STRING,
price DOUBLE
)
CLUSTERED BY (id)
STORED AS HOLODESK
TBLPROPERTIES ("holodesk.rowkey"='id','holodesk.real.time.enabled'='true');| 此模式下系统会在建表时自动基于 rowkey 列创建索引,后续所有基于 rowkey 的查询操作将获得加速,并可获得其最新数据以保障实 |
3、执行数据插入操作,观察其响应时间,低至 10 毫秒级。
0: jdbc:transwarp2://argodb-01:10000/default> INSERT INTO fast_insert_demo VALUES (1, 'ProductA', 10.5);1 row affected (0.014 seconds)
0: jdbc:transwarp2://argodb-01:10000/default> INSERT INTO fast_insert_demo VALUES (2, 'ProductB', 20.0);1 row affected (0.011 seconds)
0: jdbc:transwarp2://argodb-01:10000/default> INSERT INTO fast_insert_demo VALUES (3, 'ProductC', 15.75);1 row affected (0.012 seconds)4、(可选)查询表中的索引信息,系统已自动为 rowkey 列创建了索引。
SELECT HOLO_INDEX ("demodata", "fast_insert_demo");
+--------------+-------------------+----------------+-------------+
| column_name | table_name | database_name | index_type |
+--------------+-------------------+----------------+-------------+
| ID | fast_insert_demo | demodata | global |
+--------------+-------------------+----------------+-------------+5、执行下述命令,将数据从内存刷写至存储层,随后即可从快读层查询到所有写入的数据。
-- 刷写数据
EXECUTE SYNC TABLE fast_insert_demo;
-- 执行 Compact 操作,合并快写层数据至快读层
ALTER TABLE fast_insert_demo COMPACT "full";更多关于ArgoDB及其性能增强版Rowkey表的详细信息,欢迎访问 ArgoDB官方网站详情页 以获取进一步资料。

















 266
266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









