




 本文借助pyspark对零售数据进行分析。先对数据导入与预处理,接着从多维度进行探索性分析,如总体销售情况、商品季节性等,还构造了客单量等KPI。然后使用pyspark自带的FPGrowth算法做关联规则分析,发现常见商品组合。最后得出英国销售数据的时间特征、商品特性等结论。
本文借助pyspark对零售数据进行分析。先对数据导入与预处理,接着从多维度进行探索性分析,如总体销售情况、商品季节性等,还构造了客单量等KPI。然后使用pyspark自带的FPGrowth算法做关联规则分析,发现常见商品组合。最后得出英国销售数据的时间特征、商品特性等结论。
数据集地址:Market Basket Analysis | Kaggle
我的NoteBook地址:pyspark Market Basket Analysis | Kaggle
零售商期望能够利用过去的零售数据在自己的行业中进行探索,并为客户提供有关商品集的建议,这样就能提高客户参与度、改善客户体验并识别客户行为。本文将通过pyspark对数据进行导入与预处理,进行可视化分析并使用spark自带的机器学习库做关联规则学习,挖掘不同商品之间是否存在关联关系。
整体的流程思路借鉴了这个Notebook:Market Basket Analysis with Apriori🛒 | Kaggle
一、导入与数据预处理
这一部分其实没有赘述的必要,贴在这里单纯是为了熟悉pyspark的各个算子。
from pyspark import SparkContext
from pyspark.sql import functions as F, SparkSession, Column,types
import pandas as pd
import numpy as np
spark = SparkSession.builder.appName("MarketBasketAnalysis").getOrCreate()
data = spark.read.csv("/kaggle/input/market-basket-analysis/Assignment-1_Data.csv",header=True,sep=";")
data = data.withColumn("Price",F.regexp_replace("Price",",",""))
data = data.withColumn("Price",F.col("Price").cast("float"))
data = data.withColumn("Quantity",F.col("Quantity").cast("int"))预处理时间类变量
#时间变量
data = data.withColumn("Date_Day",F.split("Date"," ",0)[0])
data = data.withColumn("Date_Time",F.split("Date"," ",0)[1])
data = data.withColumn("Hour",F.split("Date_Time",":")[0])
data = data.withColumn("Minute",F.split("Date_Time",":")[1])
data = data.withColumn("Year",F.split("Date_Day","\.")[2])
data = data.withColumn("Month",F.split("Date_Day","\.")[1])
data = data.withColumn("Day",F.split("Date_Day","\.")[0])
convert_to_Date = F.udf(lambda x:"-".join(x.split(".")[::-1])+" ",types.StringType())
data = data.withColumn("Date",F.concat(convert_to_Date(data["Date_Day"]),data["Date_Time"]))
data = data.withColumn("Date",data["Date"].cast(types.TimestampType()))
data = data.withColumn("DayOfWeek",F.dayofweek(data["Date"])-1) #dayofweek这个函数中,以周日为第一天
data = data.withColumn("DayOfWeek",F.udf(lambda x:x if x!=0 else 7,types.IntegerType())(data["DayOfWeek"]))删除负值的记录、填充缺失值并删除那些非商品的记录
# 删除price/QTY<=0的情况
data = data.filter((F.col("Price")>0) & (F.col("Quantity")>0))
# 增加Total Price
data = data.withColumn("Total Price",F.col("Price")*F.col("Quantity"))
data_null_agg = data.agg(
*[F.count(F.when(F.isnull(c), c)).alias(c) for c in data.columns])
data_null_agg.show()
# CustomerID 空值填充
data = data.fillna("99999","CustomerID")
# 删除非商品的那些Item
data = data.filter((F.col("Itemname")!='POSTAGE') & (F.col("Itemname")!='DOTCOM POSTAGE') & (F.col("Itemname")!='Adjust bad debt') & (F.col("Itemname")!='Manual'))二、探索性分析
1、总体销售情况
本节开始,将会从订单量(No_Of_Trans)、成交量(Quantity)与成交额(Total Price)三个维度,分别从多个角度进行数据可视化与分析。
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from collections import Counter
## 总体分析
data_ttl_trans = data.groupby(["BillNo"]).sum("Quantity","Total Price").withColumnRenamed("sum(Quantity)","Quantity").withColumnRenamed("sum(Total Price)","Total Price").toPandas()
data_ttl_item = data.groupby(["Itemname"]).sum("Quantity","Total Price").withColumnRenamed("sum(Quantity)","Quantity").withColumnRenamed("sum(Total Price)","Total Price").toPandas()
data_ttl_time = data.groupby(["Year","Month"]).sum("Quantity","Total Price").withColumnRenamed("sum(Quantity)","Quantity").withColumnRenamed("sum(Total Price)","Total Price").toPandas()
data_ttl_weekday = data.groupby(["DayOfWeek"]).sum("Quantity","Total Price").withColumnRenamed("sum(Quantity)","Quantity").withColumnRenamed("sum(Total Price)","Total Price").toPandas()
data_ttl_country = data.groupby(["Country"]).sum("Quantity","Total Price").withColumnRenamed("sum(Quantity)","Quantity").withColumnRenamed("sum(Total Price)","Total Price").toPandas()
data_ttl_country_time = data.groupby(["Country","Year","Month"]).sum("Quantity","Total Price").withColumnRenamed("sum(Quantity)","Quantity").withColumnRenamed("sum(Total Price)","Total Price").toPandas()sns.boxplot(data_ttl_trans["Quantity"])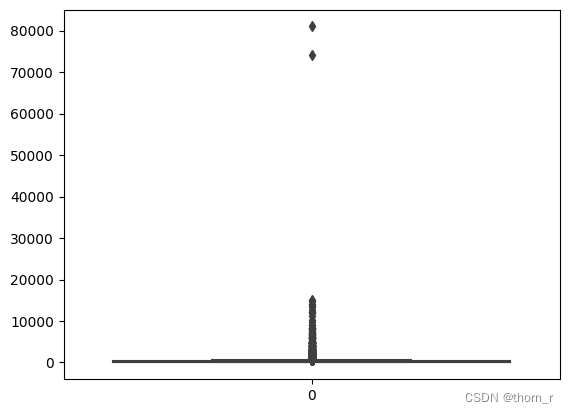
sns.boxplot(data_ttl_trans["Total Price"])
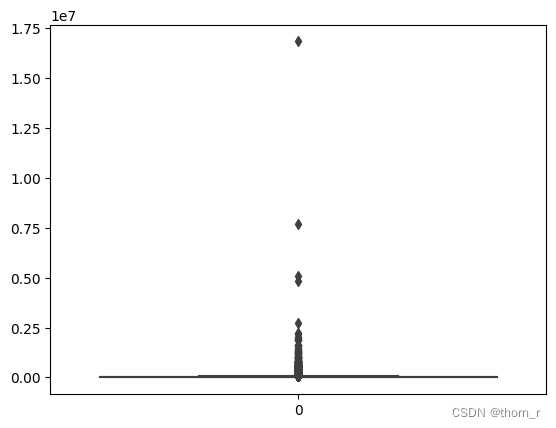
如上两图所示,销售数据极不平衡,有些单子里的销售额或销售量远远超过正常标准,因此在作分布图时,我会将箱线图中的离群点去除。
print("Quantity upper",np.percentile(data_ttl_trans["Quantity"],75)*2.5-np.percentile(data_ttl_trans["Quantity"],25)) #箱线图顶点
print("Total Price upper",np.percentile(data_ttl_trans["Total Price"],75)*2.5-np.percentile(data_ttl_trans["Total Price"],25)) #箱线图顶点
sns.distplot(data_ttl_trans[data_ttl_trans["Quantity"]<=661]["Quantity"])
sns.distplot(data_ttl_trans[data_ttl_trans["Total Price"]<=97779]["Total Price"])
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









