




 在使用Elasticsearch进行分组查询时,遇到错误并尝试修改mapping设置。通过将字段类型设为text并开启fielddata,问题仍未解决。最终发现需使用keyword类型字段进行分组,成功实现产品标签的分组查询。
在使用Elasticsearch进行分组查询时,遇到错误并尝试修改mapping设置。通过将字段类型设为text并开启fielddata,问题仍未解决。最终发现需使用keyword类型字段进行分组,成功实现产品标签的分组查询。
学习es的时候,进行分组查询
GET /ecommerce/product/_search
{
"aggs": {
"group_by_tags": {
"terms": {
"field": "tags"
}
}
}
}
报错:
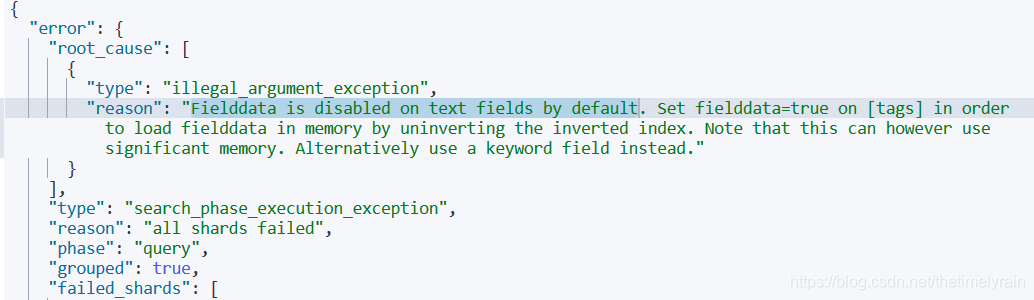 按照教程修改:
按照教程修改:
PUT /ecommerce/_mapping/product
{
"properties": {
"tags": {
"type": "text",
"fielddata": true
}
}
}
还是有问题:
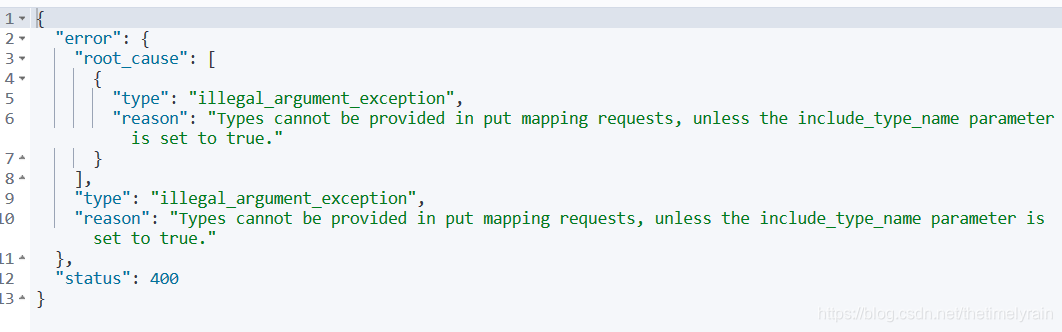 后面找到资料,加入关键字keyword即可搜索:
后面找到资料,加入关键字keyword即可搜索:
GET /ecommerce/product/_search
{
"aggs": {
"group_by_tags": {
"terms": {
"field": "tags.keyword"
}
}
}
}
问题解决

















 1652
1652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









