




前言
现阶段,尽管大模型在生成式问答上取得了很大的成功,但由于大部分的数据都是私有数据,大模型的训练及微调成本非常高,RAG的方式逐渐成为落地应用的一种重要的选择方式。然而,如何准确的对文档进行划分chunks,成为一种挑战,在现实中,大部分的专业文档都是以 PDF 格式存储,低精度的 PDF 解析会显著影响专业知识问答的效果。因此,本文将介绍针对pdf,介绍一些pdf结构化技术链路供参考。
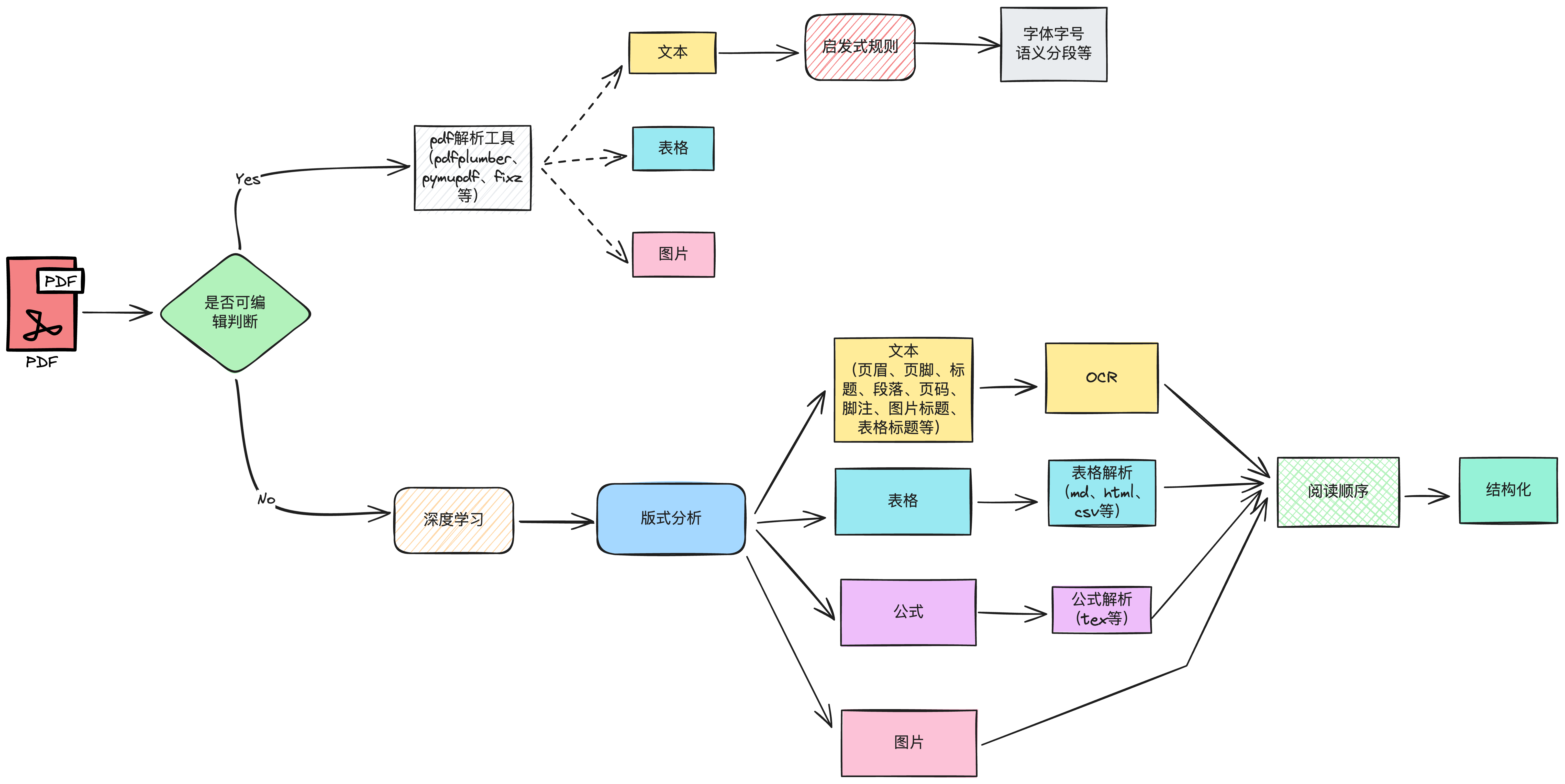
一、可编辑文档
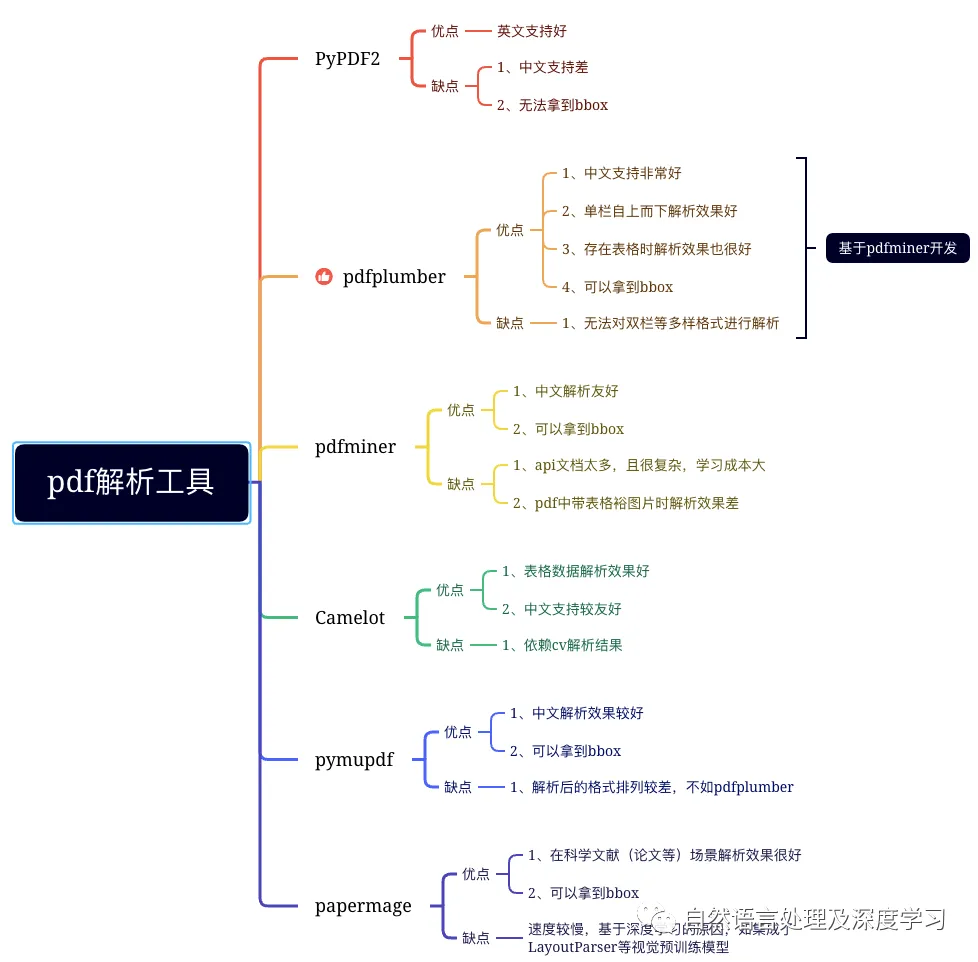
1.1 语义分段
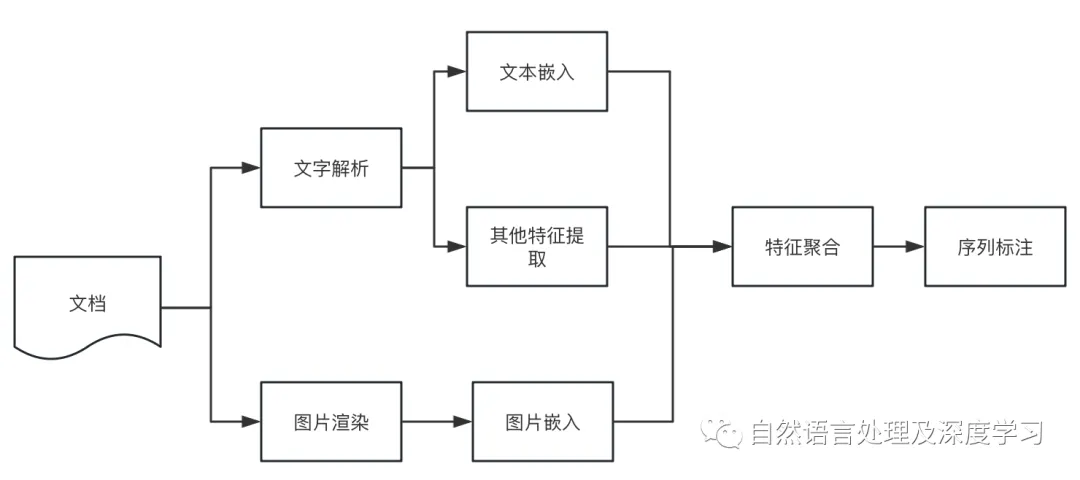
经pdf解析工具后,原始文档的段落信息全部丢失,需要进行段落的划分和重组。下面介绍一种语义分段模型的训练思路和一种开源的分段模型。
- 语义分段训练思路

-
开源的模型
from modelscope.outputs import OutputKeys
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasksp = pipeline(
task=Tasks.document_segmentation,
model=‘damo/nlp_bert_document-segmentation_chinese-base’)result = p(documents=‘移动端语音唤醒模型,检测关键词为“小云小云”。模型主体为4层FSMN结构,使用CTC训练准则,参数量750K,适用于移动端设备运行。模型输入为Fbank特征,输出为基于char建模的中文全集token预测,测试工具根据每一帧的预测数据进行后处理得到输入音频的实时检测结果。模型训练采用“basetrain + finetune”的模式,basetrain过程使用大量内部移动端数据,在此基础上,使用1万条设备端录制安静场景“小云小云”数据进行微调,得到最终面向业务的模型。后续用户可在basetrain模型基础上,使用其他关键词数据进行微调,得到新的语音唤醒模型,但暂时未开放模型finetune功能。’)
print(result[OutputKeys.TEXT])
输出
‘’’
移动端语音唤醒模型,检测关键词为“小云小云”。模型主体为4层FSMN结构,使用CTC训练准则,参数量750K,适用于移动端设备运行。模型输入为Fbank特征,输出为基于char建模的中文全集token预测,测试工具根据每一帧的预测数据进行后处理得到输入音频的实时检测结果。
模型训练采用“basetrain + finetune”的模式,basetrain过程使用大量内部移动端数据,在此基础上,使用1万条设备端录制安静场景“小云小云”数据进行微调,得到最终面向业务的模型。后续用户可在basetrain模型基础上,使用其他关键词数据进行微调,得到新的语音唤醒模型,但暂时未开放模型finetune功能。
‘’’
二、可编辑文档(扫描件)
2.1 版面分析

版面分析指的是对图片形式的文档(扫描件)进行区域划分 ,通过bounding box定位其中的关键区域,如:文字、标题、表格、图片 等,通常采用一些CV目标检测模型进行版式分析,如:参数量大的有:DINO等基于transformer的目标检测模型;参数量小的有MaskRCNN、YOLO系列等。
版式分析的优势,通过大量标注的数据,准确的划分出文档关键区域,如下:
- 文本区域:页眉、页脚、标题、段落、页码、脚注、图片标题、表格标题等
- 表格
- 公式
- 图片
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









