



openstack p版本
弹性伸缩使用服务 heat ceilometers aodh gnocchi
采样周期为300S
告警不上报的可能原因:
(1)堆栈刚创建,不足采集周期。
解决:堆栈创建成功后,需至少等待(采集周期*连续触发次数)才能进行虚机弹性伸缩的操作
(2) 堆栈创建或者更新失败。
(3) 服务状态有问题
heat ceilometers aodh gnocchi,查看服务状态及日志
4) server_group中没有记录
排查步骤:
1. 查看堆栈状态
命令:openstack stack list
结果中ID为 stack的uuid,记为STACK_ID
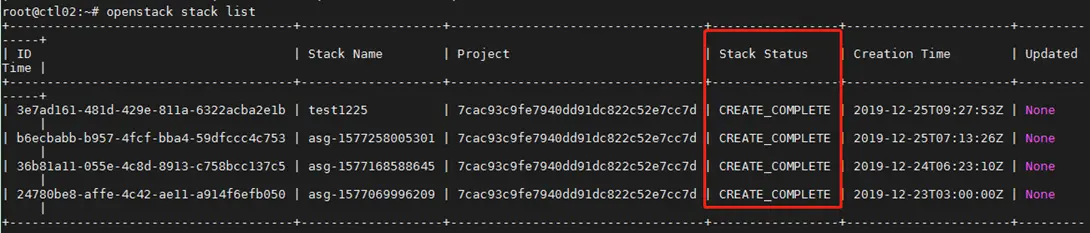
如果堆栈状态为FAIL
查看log,位置:控制节点/var/log/heat/heat-engine.log
2. 查看告警状态
命令:openstack alarm list 或者 aodh alarm list
其中state字段为ok 或者alarm表示告警正常。
Ok表示目前数据采集正常,且处于正常范围内。
Alarm表示目前数据已经触发告警。那么此时应该进行增加虚机或者移除虚机的操作,具体操作根据告警内容进行。
Insufficient data表示数据不足,此时可能:
1)采集时间不足采集周期。一般刚创建堆栈的时候是这个状态,这种情况需要等待。
2)数据采集过程有问题,需继续排查。

3. 查看是否有监控数据
1) 查询虚机id
命令: openstack server list
ID为虚机的uuid,取这个字段备用, 记为VM_ID

2) 查询虚拟机对应的测量项ID
命令:openstack metric resource show $VM_ID
取结果中的metrics中的cpu_util对应ID(堆栈模板中使用cpu_util作为弹性伸缩条件,如果选择其他项做伸缩条件,取对应的ID即可),取cpu_util id记为CPU_UTIL_ID.
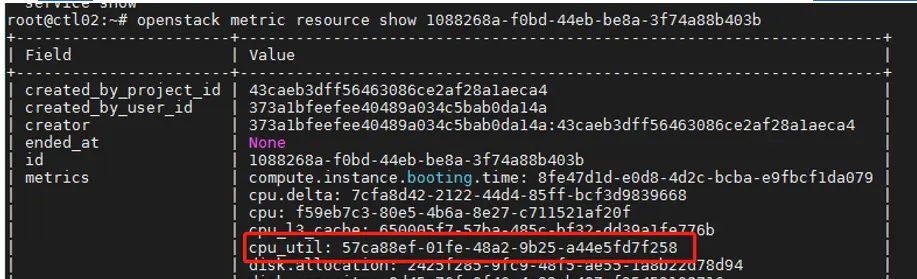
如果找不到resource,检查下计算节点的/etc/ceilometer/polling.yaml中internal的取值是不是300,如果不是,修改为300
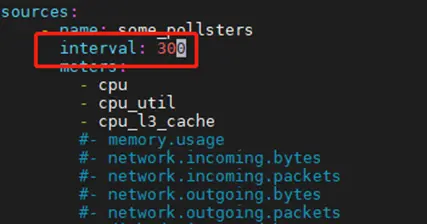
3) 查询测量项对应的测量值
命令:openstack metric measures show $CPU_UTIL_ID
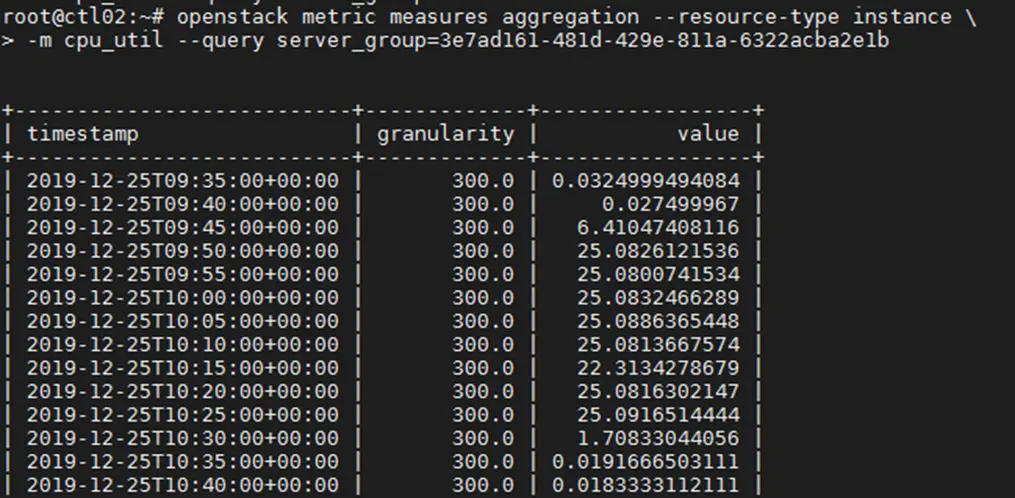
或:openstack metric measures aggregation –resource-type instance –mcpu_util –query server_group=$STACK_ID
结果中展示三列数据,分别表示采集时间,采集周期和采集到的数值。
如下图所示,表示采集到了数据。
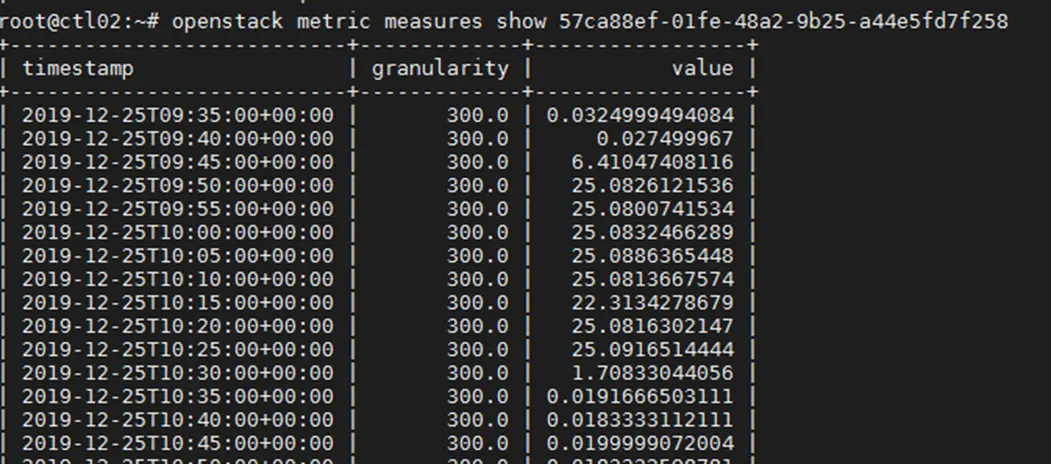
如果没有数据,可能原因:
(a)采集时间不足一个周期
(b)其他原因,继续排查
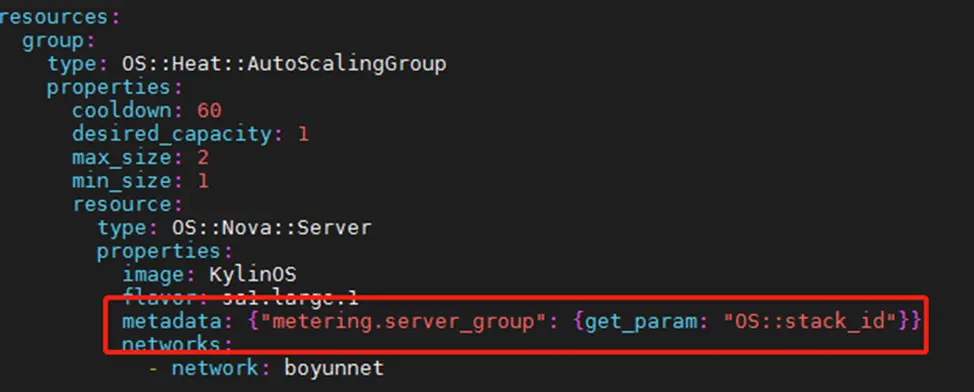
4. 堆栈模板中是否有stack id
如图所示,metadata 字段不能少
5. 查看gnocchi数据库
1)登录gnocchi数据库
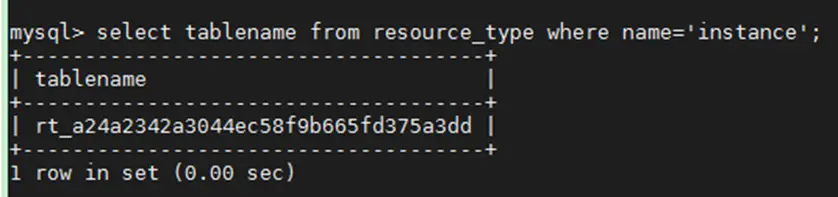
2) 根据instance 查询表名,取结果记为TABLE_NAME;
命令:select tablename from resource_type where name='instance';
3) 根据查询表名,取结果记为TABLE_NAME;
命令:select display_name,server_group from $TABLE_NAME;


















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









