



前言
时隔两年再次更新了,本文主要给大家带来一些我面试的经历和经验,希望对正在求职大厂前端岗位的同学有所帮助。我先大致说下面试之前的个人情况:2021年毕业去了一家500人左右的小公司,react和vue项目经验都有,两年半后拿礼包去了一家中厂,后来在这家公司待了一年左右最近面试京东拿到了P6的offer,差不多四年的工作经验终于拿到了大厂的入场券。
我写的篇幅可能比较长,这里讲一下为什么会有七轮面试,刚开始社区找人内推的北京团队,后来三面老板面因为工作地点的原因挂掉了(本人毕业后一直在上海工作),由于前面技术轮评价比较好,又找了上海的团队内推重新面了四轮才成功拿下。
好了,接下来就大概讲讲我的多轮京东面试
北京1轮
React 代码实现:在页面上实时显示窗口宽度的变化
import { useState, useEffect, useCallback } from 'react';
// 防抖函数
function debounce(func, wait) {
let timeout;
return function executedFunction(...args) {
const later = () => {
clearTimeout(timeout);
func(...args);
};
clearTimeout(timeout);
timeout = setTimeout(later, wait);
};
}
// 自定义 Hook
function useWindowWidth(delay = 300) {
const [width, setWidth] = useState(window.innerWidth);
const handleResize = useCallback(() => {
setWidth(window.innerWidth);
}, []);
useEffect(() => {
// 创建防抖版本的 resize 处理函数
const debouncedHandleResize = debounce(handleResize, delay);
// 添加事件监听
window.addEventListener('resize', debouncedHandleResize);
// 立即执行一次以获取初始宽度
handleResize();
// 清理函数
return () => {
window.removeEventListener('resize', debouncedHandleResize);
};
}, [handleResize, delay]);
return width;
}
// 使用示例
function WindowWidthDisplay() {
const windowWidth = useWindowWidth();
return (
<div>
<h2>窗口宽度实时显示</h2>
<p>当前窗口宽度: {windowWidth}px</p>
</div>
);
}
export default WindowWidthDisplay;
react为什么不能在if里写useEffect
React hooks的调用顺序必须稳定,React 在内部通过调用顺序来区分和管理不同的 Hooks。例如:
function Component() {
const [count, setCount] = useState(0); // Hook 1
useEffect(() => {}); // Hook 2
const [name, setName] = useState(""); // Hook 3
}
React 会按顺序将这些 Hook 存储在一个链表中(类似 [Hook1, Hook2, Hook3] )。如果组件的多次渲染中 Hook 的调用顺序不一致(比如因为条件语句跳过某个 Hook),React 就无法正确匹配状态,导致 bug
useEffect的各种机制
useEffect 的工作流程依赖于 React 的渲染周期:
-
依赖项比对:
React 会对比当前渲染和上一次渲染的依赖项数组(
deps),如果不同,会重新执行useEffect的回调。 -
清理与执行:
- 组件挂载时执行
useEffect。 - 依赖项变化时,先执行上一次的清理函数(如果存在),再执行新的
useEffect。 - 组件卸载时执行清理函数。
- 组件挂载时执行
如果 Hook 的调用顺序不稳定,React 无法正确追踪哪些 useEffect 需要清理或更新
useRef和useState底层区别
useRef 和 useState 都是 React Hooks,但它们的用途和底层实现有显著不同:
| 特性 | useState | useRef |
|---|---|---|
| 存储的值 | 存储状态,触发重新渲染 | 存储可变值,不触发重新渲染 |
| 返回值 | [state, setState](状态 + 更新函数) | {current: value }(可变 ref 对象) |
| 是否触发渲染 | ✅ 调用 setState 会触发重新渲染 | ❌ 修改 ref.current 不会触发渲染 |
| 底层存储位置 | 在 Fiber 节点的memoizedState 链表里 | 在 Fiber 节点的ref 属性上 |
| 试用场景 | 需要 UI 响应的数据(如表单、计数) | 存储 DOM 引用、缓存变量、避免重复计算 |
底层实现对比
-
useState:- React 在组件 Fiber 节点上维护一个 Hooks 链表,每个
useState对应链表中的一个节点。 - 调用
setState会标记组件需要更新,触发 re-render。 - 状态变化后,React 会重新执行组件函数,并返回最新的
state。
- React 在组件 Fiber 节点上维护一个 Hooks 链表,每个
-
useRef:useRef返回一个普通 JavaScript 对象{ current: initialValue }。- 这个对象在组件的整个生命周期中保持不变(即使组件重新渲染)。
- 修改
ref.current不会触发 React 的更新机制,因为 React 不追踪 ref 的变化。
useEffect能监听useRef的值发生改变吗?
默认情况下,useEffect 无法监听 useRef 的变化
原因分析
-
useRef的修改不会触发重新渲染useEffect的依赖项机制依赖于 组件渲染,而ref.current的变化不会导致重新渲染,因此useEffect不会自动检测到变化。 -
useRef返回的对象始终是同一个引用const ref = useRef(0); // 即使修改 ref.current,ref 本身仍然是同一个对象 ref.current = 1;// React 不会感知到这个变化由于
ref对象在组件的整个生命周期中引用不变,useEffect的依赖项比对(Object.is)会认为它没有变化。
如何让 useEffect 监听 useRef 的变化?
虽然 useRef 本身不会触发 useEffect,但可以通过 额外状态 或 自定义 Hook 间接监听
function useWatchableRef(initialValue) {
const ref = useRef(initialValue);
const [version, setVersion] = useState(0);
const setRef = (value) => {
ref.current = value;
setVersion(v => v + 1); // 更新版本号触发 useEffect
};
return [ref, setRef, version];
}
function Component() {
const [ref, setRef, refVersion] = useWatchableRef(0);
useEffect(() => {
console.log("ref changed:", ref.current);
}, [refVersion]); // 监听 version 变化
}
为什么 React 不直接支持监听 useRef?
-
设计初衷不同
useRef主要用于 存储可变值而不触发渲染(如 DOM 引用、定时器 ID)。useState才是用于 管理状态并触发 UI 更新 的。
-
性能优化
- 如果
useRef的每次修改都触发useEffect,可能会导致不必要的副作用执行(比如频繁的 DOM 操作)。
- 如果
-
避免滥用
- 如果业务逻辑需要响应式更新,应该优先使用
useState或useReducer,而不是强行监听useRef。
- 如果业务逻辑需要响应式更新,应该优先使用
手写算法 标签树的深度
const htmlStr = `
<div>
<div>
<span>123</span>
<a>222</a>
<div>
<button>333</button>
<br/>
</div>
</div>
</div>
`;
答案
function getHtmlTreeDepth(htmlStr) {
let depth = 0;
let maxDepth = 0;
const stack = [];
const tagRegex = /<\/?([a-z][a-z0-9]*)[^>]*>/gi;
htmlStr.replace(tagRegex, (tag) => {
if (tag.startsWith('</')) {
// 闭合标签
depth--;
stack.pop();
} else if (!tag.endsWith('/>')) {
// 非自闭合的开放标签
depth++;
maxDepth = Math.max(maxDepth, depth);
stack.push(tag.match(/<([a-z]+)/i)[1]);
}
// 自闭合标签(如 <br/>)不改变深度
return tag;
});
return maxDepth;
}
const depth = getHtmlTreeDepth(htmlStr);
console.log(depth); // 输出: 4
北京2轮
ssr、ssg、rsc原理及优缺点
1. SSR(Server-Side Rendering,服务端渲染)
原理:
- 用户请求页面时,服务器实时执行 JavaScript,生成完整 HTML 并返回给浏览器。
- 浏览器接收到 HTML 后直接显示,然后再进行 hydration(注水) 使其可交互。
优点:
✅ 首屏加载快:用户直接看到渲染好的内容,无需等待 JS 执行。
✅ SEO 友好:搜索引擎爬虫能直接获取完整 HTML。
✅ 低端设备兼容:不依赖客户端 JS 能力,适合性能较差的设备。
缺点:
❌ 服务器压力大:每次请求都需要实时渲染,高并发时可能拖慢服务器。
❌ TTFB(首字节时间)延迟:用户需等待服务器生成 HTML。
❌ 交互延迟:必须等 hydration 完成后才能交互。
适用场景:
- 需要 SEO 的内容型网站(如新闻、博客)。
- 对首屏速度要求高的应用。
2. SSG(Static Site Generation,静态站点生成)
原理:
- 在 构建阶段 提前生成所有页面的静态 HTML,直接托管到 CDN。
- 用户访问时,CDN 直接返回预渲染的 HTML,无需服务器计算。
优点:
✅ 极致性能:CDN 直接返回 HTML,速度极快。
✅ 零服务器压力:无需运行时渲染,节省计算资源。
✅ 高安全性:没有动态服务器逻辑,减少攻击面。
缺点:
❌ 不适合动态内容:数据更新必须重新构建。
❌ 规模化成本高:页面数量多时,构建时间会很长。
❌ 无法个性化:所有用户看到相同的内容(除非结合客户端 JS)。
适用场景:
- 内容不经常变的网站(如文档、营销页)。
- 需要极致性能的场景。
3. RSC(React Server Components,React 服务端组件)
原理:
- 按组件粒度 区分哪些在服务端渲染,哪些在客户端渲染。
- 服务端组件直接访问数据库/API,返回 JSON 数据,客户端组合渲染。
优点:
✅ 减少客户端 JS 体积:部分逻辑留在服务端,前端代码更小。
✅ 自动代码拆分:按需加载组件,优化性能。
✅ 直接访问后端:服务端组件可直接调用 DB/API,无需额外接口。
缺点:
❌ 复杂度高:需要处理服务端/客户端组件的通信问题。
❌ 兼容性要求:必须使用 React 18+ 和特定框架(如 Next.js)。
❌ 调试困难:跨环境调试较麻烦。
适用场景:
- 复杂应用,需要优化包大小和加载速度。
- 需要服务端直接获取数据的场景(如仪表盘、管理后台)。
node ssr什么原因引起的堵塞,怎么解决
- CPU 密集型任务阻塞事件循环
- 复杂组件渲染(如大型列表、深度递归组件)
- 繁重的模板计算(如Pug/EJS模板处理大数据)
- 加密/解密操作(如JWT验证)
- 同步I/O操作阻塞
- 同步文件读写(
fs.readFileSync) - 同步数据库查询(某些ORM的同步方法)
- 阻塞式网络请求(未正确使用Promise)
- 内存泄漏
- 全局变量累积(如缓存未清理)
- 闭包引用未释放
- 事件监听器未移除
- 资源竞争
- 数据库连接池耗尽
- 文件描述符耗尽
- 子进程管理不当
解决方案
1.架构层优化
// 使用React的renderToNodeStream
import { renderToNodeStream } from 'react-dom/server';
app.get('/', (req, res) => {
res.write('<!DOCTYPE html>');
const stream = renderToNodeStream(<App />);
stream.pipe(res, { end: false });
stream.on('end', () => res.end());
});
2.渲染性能优化
// 使用React的renderToNodeStream
2import { renderToNodeStream } from 'react-dom/server';
3
4app.get('/', (req, res) => {
5 res.write('<!DOCTYPE html>');
6 const stream = renderToNodeStream(<App />);
7 stream.pipe(res, { end: false });
8 stream.on('end', () => res.end());
9});
3.异步I/O和非阻塞操作
// 使用Promise.all优化并行请求
async function fetchData() {
const [user, posts] = await Promise.all([
UserModel.findById(userId),
PostModel.findByUser(userId)
]);
return { user, posts };
}
数据库/API 调用优化:
- 使用 Data Cache(如 Redis)减少重复查询。
- 对慢接口设置 超时 或 降级处理
站点seo怎么做的
1.语义化 HTML
- 使用
<h1>~<h6>合理嵌套标题 - 使用
<section>、<article>、<nav>等语义化标签 - 图片必须加
alt属性
2.Meta 标签优化
<head>
<title>网站标题 - 重要关键词</title>
<meta name="description" content="网站描述,包含核心关键词" />
<meta name="keywords" content="关键词1, 关键词2" />
<!-- 避免被转码 -->
<meta http-equiv="Content-Type" content="text/html;charset=UTF-8" />
<!-- 移动端适配 -->
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<!-- 禁止搜索引擎转码(如百度) -->
<meta http-equiv="Cache-Control" content="no-transform" />
<meta http-equiv="Cache-Control" content="no-siteapp" />
</head>
3.前端框架(React/Vue)SEO优化
- Next.js(React) / Nuxt.js(Vue) 默认支持 SSR
- 静态生成(SSG)
- React Helmet(Next.js 内置
Head组件)
4.Sitemap(站点地图)
作用
- 告诉搜索引擎网站有哪些页面可被抓取
- 标注页面的更新频率(
lastmod)和优先级(priority) - 尤其适合 大型网站 或 动态内容网站(如电商、新闻站)
手动编写 Sitemap
<!-- public/sitemap.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="<http://www.sitemaps.org/schemas/sitemap/0.9>">
<url>
<loc><https://example.com/></loc>
<lastmod>2023-10-01</lastmod>
<changefreq>daily</changefreq>
<priority>1.0</priority>
</url>
</urlset>
5.Robots.txt(爬虫协议)
作用
- 控制搜索引擎哪些页面可以抓取
- 禁止抓取敏感页面(如后台、临时页)
标准配置
txt
# public/robots.txt
User-agent: * # 对所有爬虫生效
Disallow: /admin/ # 禁止抓取后台
Disallow: /tmp/ # 禁止抓取临时文件
Allow: /public/ # 允许抓取 public 目录
Crawl-delay: 2 # 抓取延迟(秒),防止服务器压力
# 声明 Sitemap
Sitemap: <https://example.com/sitemap.xml>
北京3轮
平时怎么学习?遇到比较难的问题怎么解决?讲一下工作中遇到的问题
上海1轮
手写算法 版本号列表排序
给定一个版本号列表从小到大排序 如[1.0.1, 0.1, 1.3.26, 1.0.3.29, 2.1.3, 1.0.9.7.25]
function sortVersions(versions) {
return versions.sort((a, b) => {
const partsA = a.split('.').map(Number);
const partsB = b.split('.').map(Number);
const maxLength = Math.max(partsA.length, partsB.length);
for (let i = 0; i < maxLength; i++) {
const numA = partsA[i] || 0;
const numB = partsB[i] || 0;
if (numA !== numB) {
return numA - numB;
}
}
return 0;
});
}
// 测试
const versions = ["1.0.1", "0.1", "1.3.26", "1.0.3.29", "2.1.3", "1.0.9.7.25"];
console.log(sortVersions(versions));
// 输出: ["0.1", "1.0.1", "1.0.3.29", "1.0.9.7.25", "1.3.26", "2.1.3"]
聊聊ssr和segment ssr架构以及rsi相关的
1.传统 SSR(服务端渲染)
运行时渲染:用户请求时,服务器动态生成完整 HTML,工作流程:
用户请求
->NodeJs服务器
->执行React/vue组件渲染
->返回完整HTML+客户端js
->浏览器Hydration交互
✅ 优点: 首屏速度快、SEO友好、低端设备兼容
❌缺点:高服务器负载、 TTFB(首字节时间)较长、 TTFB(首字节时间)较长
2.Segment SSR(分段服务端渲染)
- 流式分块渲染:将页面拆分为多个可独立渲染的模块(Segments)
- 渐进式传输:边渲染边传输,而非等待整个页面完成
// 1. 定义可分段组件
import { Suspense } from 'react';
function Page() {
return (
<div>
<Header />
<Suspense fallback={<Spinner />}>
<ProductList /> // 异步加载的模块
</Suspense>
<Footer />
</div>
);
}
// 2. 服务端流式响应
import { renderToPipeableStream } from 'react-dom/server';
app.get('/', (req, res) => {
const stream = renderToPipeableStream(<Page />);
stream.pipe(res);
});
✅ 优势
- 关键内容优先渲染(Critical CSS/JS),非关键模块延迟加载
- 服务器CPU时间分段使用,减少内存峰值压力
3.RSI(Remote Server Includes)
边缘包含技术:将页面拆分为多个独立服务渲染的片段,在CDN边缘组合
与传统SSR对比:
- 传统SSR: [DB → 完整渲染 → HTML]
+ RSI: [DB → 片段A渲染]
[API → 片段B渲染] → CDN组合// CDN边缘逻辑示例(伪代码)
async function handleRequest(request) {
const [header, body] = await Promise.all([
fetch('<https://service-a/render-header>'),
fetch('<https://service-b/render-body>')
]);
return new Response(`
${await header.text()}
${await body.text()}
`);
}
✅ 优势
- 减少回源延迟,单个片段失败不影响整体
- 静态部分预生成,动态部分按需渲染
微前端底层怎么实现的,css隔离、通信怎么做
1. 应用隔离机制
proxy沙箱:
- 每个子应用运行在独立的proxy上下文
- 卸载时清除所有副作用
// 基于Proxy的沙箱实现
class Sandbox {
constructor() {
const fakeWindow = {};
this.proxy = new Proxy(fakeWindow, {
get(target, key) {
return target[key] || window[key];
},
set(target, key, value) {
target[key] = value;
return true;
}
});
}
}
CSS隔离:
Shadow DOM天然隔离样式
const shadow = element.attachShadow({ mode: 'open' });
2shadow.innerHTML = `<style>h1 { color: red; }</style>`;
Scoped CSS通过前缀隔离(如**qiankun的scoped-css**)
通信机制:
Custom Events
// 子应用发送事件
window.dispatchEvent(new CustomEvent('micro-event', {
detail: { type: 'login' }
}));
// 主应用监听
window.addEventListener('micro-event', handler);
聊下ai相关的llm、mcp的 对日常工作作用
这里具体自己翻文档了解使用和简单原理,具体可以看看mcp文档
上海2轮
编辑器的多人协作冲突原理
OT (Operational Transformation) 算法
将编辑操作转换为原子操作(如**insert(pos, text) 、 delete(pos, length)**),通过转换函数解决操作冲突
// 操作转换函数示例
function transform(op1, op2) {
// 如果op2在op1之前发生,调整op1的位置
if (op1.type === 'insert' && op2.type === 'insert') {
if (op1.pos <= op2.pos) {
return { ...op1 }; // op1不需要修改
} else {
return { ...op1, pos: op1.pos + op2.text.length };
}
}
// 其他情况处理...
}
CRDT (Conflict-Free Replicated Data Type)
将数据结构设计保证最终一致性,每个编辑操作天生可合并
// 使用唯一ID标识每个字符
const doc = {
"id1": { char: 'H', id: 'id1', pos: 0.1 },
"id2": { char: 'i', id: 'id2', pos: 0.2 }
};
// 插入新字符时分配介于两者之间的position
insertAfter('id1', '!') → pos = (0.1 + 0.2)/2 = 0.15
webpack的loader和plugin原理
Loader 的作用
- 转换文件内容:将非 JS 文件(如
.css、.vue)转换成 Webpack 可识别的模块。 - 链式调用:多个 Loader 可以串联执行(如
sass-loader→css-loader→style-loader)
Loader的底层实现
Loader 本质是一个函数,接收源文件内容,返回转换后的内容:
// 一个简单的 Loader 示例
module.exports = function(source) {
// 1. 处理 source(如编译、转换)
const transformed = source.replace('red', 'blue');
// 2. 返回处理后的内容(可以是 JS/CSS/其他)
return transformed;
// 可选:返回多个结果(如 source + sourceMap)
// this.callback(null, transformed, sourceMap);
};
Plugin 的作用
- 扩展构建流程:在 Webpack 编译的不同阶段注入自定义逻辑。
- 访问 Webpack 内部:可以修改模块、优化 chunks、生成 assets 等。
Plugin的底层原理
Plugin 是一个类,必须实现 apply 方法:
class MyPlugin {
apply(compiler) {
// 1. 注册钩子
compiler.hooks.emit.tap('MyPlugin', (compilation) => {
// 2. 操作 compilation(如修改生成的资源)
compilation.assets['new-file.txt'] = {
source: () => 'Hello Webpack!',
size: () => 13,
};
});
}
}
module.exports = MyPlugin;
关键点:
compiler代表整个 Webpack 环境。compilation包含当前构建的所有信息(模块、chunks、assets)。- 可以通过
Tapable的tapAsync/tapPromise处理异步逻辑。
webpack的底层打包原理
1.依赖图构建
从入口文件出发,递归分析所有依赖,形成完整的模块关系图
根据 webpack.config.js 中的 entry 配置(如 ./src/index.js),创建初始模块 遍历 AST 找到所有 import/require 语句,收集依赖路径
递归处理子模块,对每个依赖路径解析为绝对路径
最终生成一个 Map 结构的依赖图:
const dependencyGraph = {
'./src/index.js': {
id: './src/index.js',
dependencies: ['./src/utils.js'],
source: '...'
},
'./src/utils.js': {
id: './src/utils.js',
dependencies: ['lodash'],
source: '...'
},
'lodash': { ... }
};
2. Chunk 生成
- Entry Chunk: 每个
entry配置生成一个初始 Chunk - Async Chunk: 动态导入(
import())自动生成新 Chunk - SplitChunks 优化: 根据
optimization.splitChunks配置拆分公共模块,如将lodash等第三方库提取到vendorsChunk
3.模块转译
- Loader 链式处理: 按配置顺序调用 Loader 处理模块内容
- 生成运行时兼容代码: 将 ESM 的
import转为 Webpack 的__webpack_require__
4.模板渲染 生成 Runtime 代码包含模块加载、缓存等逻辑
// 运行时伪代码
function __webpack_require__(moduleId) {
if (cache[moduleId]) return cache[moduleId].exports;
const module = { exports: {} };
modules[moduleId](module, module.exports, __webpack_require__);
return module.exports;
}
拼接 Chunk 内容
(function(modules) {
// Runtime 代码...
})({
'./src/index.js': function(module, exports, __webpack_require__) {
// 模块代码
},
'./src/utils.js': function(...) { ... }
});
生成 Asset 文件
根据 output.filename 规则命名文件(如 [name].[contenthash].js),如果配置了 devtool 还会生成SourceMap文件
5.优化阶段
Tree Shaking 基于 ES Module 的静态分析,标记未使用的导出
// 源码:
export function a() {}
export function b() {} // 未被导入
// 打包后:
/* unused harmony export b */
Scope Hoisting合并模块作用域,减少闭包
// 优化前:
(function(module) {
module.exports = 1;
});
// 优化后:
module.exports = 1; // 直接内联
代码压缩 使用 TerserPlugin 混淆和压缩 JS
讲下esm、cmd、umd区别
1. ESM
ES6 引入的模块化方案,现代浏览器和 Node.js 原生支持,依赖关系在编译时确定
运行环境:
- 浏览器:
<script type="module"> - Node.js:
.mjs文件或package.json设置"type": "module"
✅优点:静态分析支持 Tree Shaking、浏览器原生支持,无需打包工具(但生产环境仍需打包优化)、支持循环引用(模块只被加载一次,存在缓存中)
❌缺点:旧浏览器不支持(需通过 Webpack/Babel 转译)、Node.js 中与 CommonJS 混用需注意兼容性
2.CMD
NodeJS默认规范,主要用于服务端,依赖关系在运行时确定,模块同步加载会阻塞执行
运行环境:
- Node.js 原生支持
- 浏览器需通过 Webpack/Browserify 打包
✅优点:Node.js 生态默认支持、简单易用
❌缺点:同步加载不适合浏览器环境(会导致性能问题)、不支持 Tree Shaking
3.UMD
同时兼容 ESM、CMD 和浏览器全局变量,根据环境自动选择导出方式
(function (root, factory) {
if (typeof define === 'function' && define.amd) {
// AMD 规范(如 RequireJS)
define(['jquery'], factory);
} else if (typeof exports === 'object') {
// CommonJS 规范
module.exports = factory(require('jquery'));
} else {
// 浏览器全局变量
root.MyLib = factory(root.jQuery);
}
}(this, function ($) {
// 模块逻辑
return { name: 'UMD' };
}));
运行环境
- 浏览器:直接引入
<script>或通过 AMD 加载器 - Node.js:直接
require
✅优点:跨环境兼容(浏览器/Node.js/AMD)、适合库开发(如 jQuery、Lodash)
❌缺点:代码冗余(包含多种兼容逻辑)、无法利用 ESM 的静态优化
上海3轮
聊项目深度、聊解决问题思路
上海4轮
这一轮面试官是Taro团队的,也是技术深度和面试难度最大的一轮
react18以前批处理是啥样的? react18+的批处理怎么做的,从底层讲讲
1.React 18 之前的批处理
仅合并合成事件:在 React 事件处理函数(如 onClick)中的多个 setState 会被批量处理,React 使用事务机制延迟更新(异步批处理)到事件结束
function App() {
const [count, setCount] = useState(0);
const [flag, setFlag] = useState(false);
const handleClick = () => {
setCount(c => c + 1); // 不会立即触发渲染
setFlag(f => !f); // 不会立即触发渲染
// React 会将这两个更新合并为一次渲染
};
return <button onClick={handleClick}>Click</button>;
}
局限性: setTimeout/Promise/原生事件 中的 setState 会立即触发更新
setTimeout(() => {
setCount(c => c + 1); // 立即渲染
setFlag(f => !f); // 再次渲染
}, 0);
2.React 18+ 的自动批处理
全场景批处理:合并所有上下文中的更新(包括事件、定时器、Promise、原生事件等),使用新的并发调度器(Scheduler)管理更新优先级
// 以下所有场景都会批量处理!
function App() {
const handleClick = () => {
setCount(c => c + 1);
setFlag(f => !f);
// 合并为一次渲染(即使放在 setTimeout 中)
};
const fetchData = async () => {
const res = await fetch('/api');
setData(res);
setLoading(false); // 异步操作后仍会批量处理
};
return <button onClick={handleClick}>Click</button>;
}
底层实现:
1.更新队列:所有更新被放入共享队列,通过 lane(车道)模型标记优先级
function dispatchSetState(fiber, queue, action) {
const update = {
lane: requestUpdateLane(fiber), // 分配优先级
action,
next: null
};
enqueueUpdate(fiber, queue, update); // 入队
scheduleUpdateOnFiber(fiber); // 调度更新
}
2.调度合并
function scheduleUpdateOnFiber(root, fiber, lane) {
markRootUpdated(root, lane); // 标记待处理更新
ensureRootIsScheduled(root); // 统一调度
}
- 车道模型(Lane)
export const SyncLane = 0b0001; // 同步优先级
export const InputContinuousLane = 0b0010; // 连续输入(如滚动)
export const DefaultLane = 0b0100; // 默认优先级
useLayoutEffect和useEffect啥区别,从底层讲讲
1.核心区别总结
| 特性 | useLayoutEffect | useEffect |
|---|---|---|
| 执行时机 | DOM 更新后、浏览器绘制前(同步) | 浏览器绘制后(异步) |
| 堵塞渲染 | ✅ 会阻塞浏览器绘制 | ❌ 不阻塞 |
| 适用场景 | 需要同步计算 DOM 布局的场景 | 数据获取、事件订阅等副作用 |
| 源码阶段 | commitLayoutEffects 阶段执行 | commitBeforeMutationEffects 阶段调度 |
2.底层执行流程
React 的渲染分为 Render 阶段 和 Commit 阶段,两者在 Commit 阶段的不同时机执行 Commit阶段
- BeforeMutation:调度
useEffect的销毁函数(如果依赖项变化) - Mutation:实际更新 DOM(React 17+ 使用
Fiber直接操作)。 - Layout:执行
useLayoutEffect的回调、更新 **ref、**执行componentDidMount/Update(类组件)
useLayoutEffect 执行细节
同步执行 在 commitLayoutEffects 函数中直接调用
// ReactFiberCommitWork.js
function commitLayoutEffects(root) {
while (nextEffect !== null) {
if (effectTag & Layout) {
const effect = nextEffect.updateQueue.lastEffect;
if (effect !== null) {
do {
if (effect.tag === Layout) {
effect.destroy = effect.create(); // 同步执行回调
}
effect = effect.next;
} while (effect !== firstEffect);
}
}
nextEffect = nextEffect.nextEffect;
}
}
阻塞流程 由于在浏览器绘制前执行,长时间运行会导致页面卡顿
useEffect 执行细节
异步调度 在 commitBeforeMutationEffects 阶段标记,由 Scheduler 异步执行
// ReactFiberWorkLoop.js
function scheduleCallback(priorityLevel, callback) {
// 将 effect 放入调度队列
Scheduler_scheduleCallback(priorityLevel, callback);
}
实际执行时机 React 17 使用 requestIdleCallback 的 polyfill,React 18 使用 Scheduler 包的优先级调度
fiber是什么
Fiber 是 React 16+ 的核心调度单元,解决了传统 Stack Reconciler(React 15 及之前)的不可中断问题
React 将组件树转换为 Fiber 链表(深度优先遍历),每个 Fiber 节点对应一个 React 元素(组件/DOM 节点),包含以下关键属性:
ts
//fiber数据结构
interface Fiber {
// 标识信息
tag: WorkTag; // 组件类型(函数组件/类组件/DOM节点等)
key: string | null; // 同级节点唯一标识
type: any; // 组件构造函数或DOM标签名(如 'div')
// 树结构关系
return: Fiber | null; // 父节点
child: Fiber | null; // 第一个子节点
sibling: Fiber | null;// 下一个兄弟节点
alternate: Fiber | null; // 当前节点对应的旧Fiber(用于Diff)
// 状态与副作用
memoizedState: any; // Hook链表(函数组件状态)
stateNode: any; // 实例(DOM节点/类组件实例)
flags: Flags; // 标记需要进行的操作(如Placement/Update)
lanes: Lanes; // 优先级(车道模型)
// 工作进度
pendingProps: any; // 待处理的props
memoizedProps: any; // 上次渲染的props
}
React调度怎么做的
React 18 引入 车道模型(Lane) 管理任务优先级 1.优先级划分
export const SyncLane = 0b0001; // 同步任务(如点击事件)
export const InputContinuousLane = 0b0010; // 连续输入(如滚动)
export const DefaultLane = 0b0100; // 普通更新
2.优先级抢占
高优先级任务可中断低优先级任务:
function ensureRootIsScheduled(root) {
// 获取最高优先级任务
const nextLanes = getNextLanes(root);
if (nextLanes === NoLanes) return;
// 如果存在更高优先级任务,取消当前任务
if (existingCallbackPriority !== newCallbackPriority) {
cancelCallback(existingCallbackNode);
}
}
react可执行中断渲染从底层怎么做到的
1.关键机制:时间切片
React 将渲染任务拆分为多个 Fiber 工作单元,通过浏览器 API(如 requestIdleCallback 或 MessageChannel)在空闲时段执行
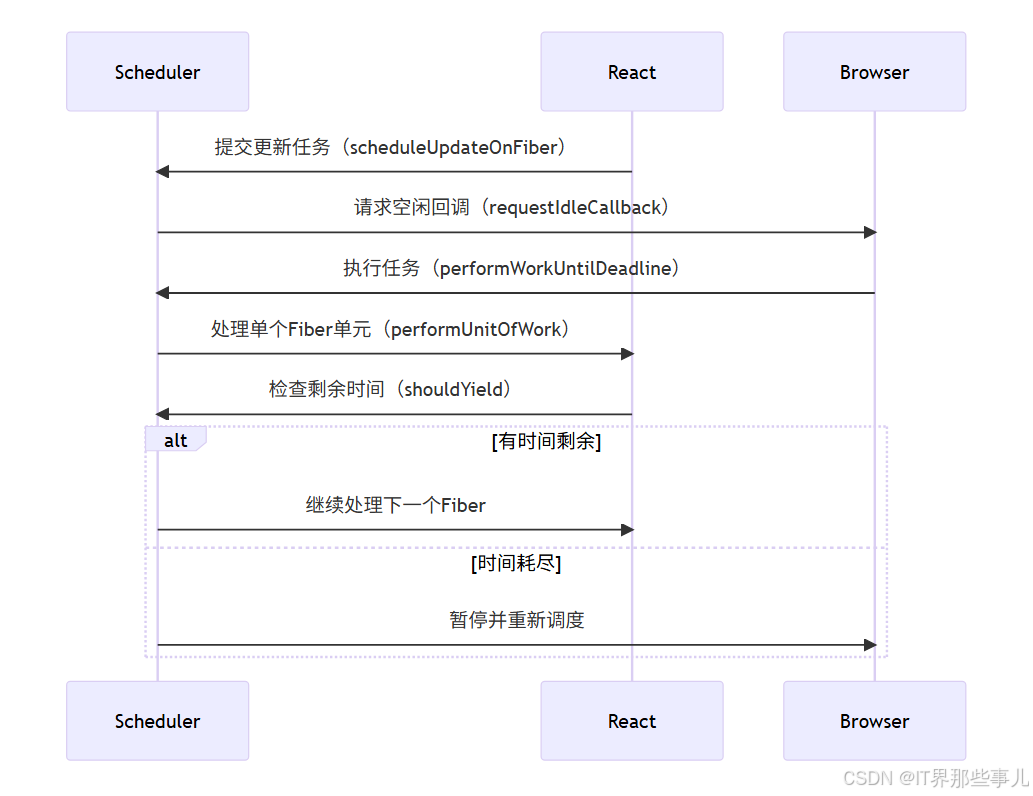
2.双缓存技术
React 维护两棵 Fiber 树:
- Current Tree:当前渲染的树(对应屏幕上显示的内容)。
- WorkInProgress Tree:正在构建的新树(可中断修改)。
中断时:保存当前处理的 Fiber 节点指针(workInProgress) 恢复时:从上次中断的 Fiber 节点继续处理
function workLoopConcurrent() {
while (workInProgress !== null && !shouldYield()) {
performUnitOfWork(workInProgress);
}
// 如果被中断,workInProgress会保留当前节点
}
微信小程序架构具体怎么做的
微信小程序的架构设计采用了独特的双线程模型,将**视图层(View Layer)和逻辑层(App Service Layer)**分离,并通过微信客户端(Native)进行通信,以实现高性能、安全性和跨平台一致性
双线程模型
- 视图层(View Layer) :运行在单独的 WebView 线程,负责 UI 渲染。
- 逻辑层(App Service Layer) :运行在 JavaScriptCore(iOS)/V8(Android) 线程,处理业务逻辑和数据管理。
- Native 层:微信客户端作为中间层,负责通信、权限管理和原生能力调用,wx API底层依赖于Bridge机制
wasm是什么
WebAssembly(WASM)是一种二进制指令格式,设计用于在浏览器中高效执行接近原生速度的代码,WASM 的代码通常由 C/C++/Rust 等语言编译而来,可与 JavaScript 无缝交互使用 以 Rust + WASM 为例
rust代码用wasm-pack编译成wasm
// src/lib.rs
#[no_mangle]
pub fn add(a: i32, b: i32) -> i32 {
a + b
}
js调用wasm
import init, { add } from './pkg/your_module.js';
await init();
console.log(add(2, 3)); // 输出 5
Rust所有权
Rust的所有权用于管理内存和资源的生命周期,确保内存安全而无需垃圾回收。简单来说,所有权规则主要包括三条:
1.每个值有且只有一个所有者(Owner)
String 类型的数据存储在堆上,赋值时发生 所有权转移(Move),s1 不再有效
let s1 = String::from("hello"); // s1 是所有者
let s2 = s1; // 所有权从 s1 转移到 s2
println!("{}", s1); // 编译错误!s1 已失效
2.所有权可以转移(Move),但不能共享(除非借用)
同一作用域内可存在多个不可变引用,不允许同时存在可变引用(防止数据竞争)
let s = String::from("hello");
let len = calculate_length(&s); // 传递不可变引用
fn calculate_length(s: &String) -> usize {
s.len() // 可读但不可修改
}
当所有者变量离开作用域时,该值会被自动清理释放内存(调用 drop)
fn main() {
{
// s 进入作用域
let s = String::from("hello"); // 在堆上分配内存
println!("{}", s); // 输出 "hello"
} // s 离开作用域,自动调用 drop 释放内存
// 此处无法再访问 s
}
用React做跨端小程序框架实现
1.技术选型
- React:作为核心渲染库,利用其虚拟 DOM 能力。
- 自定义渲染器(如 React Reconciler) :实现跨端渲染调度能力。
- 平台适配层:将虚拟 DOM 映射到不同平台(如微信小程序、支付宝小程序、Web等)的原生组件。
- JSX 语法:统一开发体验。
- 打包工具:如 webpack、Vite,结合 Babel 进行代码转换。
2.平台适配
- Web:直接用 ReactDOM 渲染。
- 小程序:将虚拟 DOM 转换为小程序的 JSON 结构和 WXML。
- 原生 App:可用 React Native 或自定义桥接。
3.运行时 提供一套跨端组件(如 View、Text、Image 等),在不同平台下有不同实现,统一事件、生命周期、样式等 API
怎么做node cli的插件化,扩展给外部开发者定制化
1. 插件化的基本思路
- 插件发现:CLI 能自动发现和加载外部插件。
- 插件注册:插件能注册命令、参数、钩子等。
- 插件通信:插件和主程序、插件之间可以通信。
- 插件隔离:插件运行环境与主程序隔离,避免冲突。
2.常见实现方式
插件 API 设计: 主程序暴露 API 给插件,插件通过 API 注册命令、钩子等
主程序
class CLI {
constructor() {
this.commands = {};
}
registerCommand(name, fn) {
this.commands[name] = fn;
}
run(argv) {
const cmd = argv[2];
if (this.commands[cmd]) {
this.commands[cmd]();
}
}
}
const cli = new CLI();
module.exports = cli;
插件
module.exports = function(api) {
api.registerCommand('hello', () => {
console.log('Hello from plugin!');
});
};
最后如有错误,请告知提醒
原文:面试分享:二本靠7轮面试成功拿下大厂P6时隔两年再次更新了,本文主要给大家带来一些我面试的经历和经验,希望对正在求职京东 - 掘金

















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









