



 谷歌和Mila研究所的研究者提出Hypotheses-to-Theories(HtT)框架,让LLM学习推理规则,显著提升多步推理准确率,尤其是在数值和关系推理任务中。GPT-4受益明显,HtT可作为知识蒸馏方式。
谷歌和Mila研究所的研究者提出Hypotheses-to-Theories(HtT)框架,让LLM学习推理规则,显著提升多步推理准确率,尤其是在数值和关系推理任务中。GPT-4受益明显,HtT可作为知识蒸馏方式。
当前,大型语言模型(LLM)在推理任务上表现出令人惊艳的能力,特别是在给出一些样例和中间步骤时。然而,prompt 方法往往依赖于 LLM 中的隐性知识,当隐性知识存在错误或者与任务不一致时,LLM 就会给出错误的回答。
现在,来自谷歌、Mila 研究所等研究机构的研究者联合探索了一种新方法 —— 让 LLM 学习推理规则,并提出一种名为假设到理论(Hypotheses-to-Theories,HtT)的新框架。这种新方法不仅改进了多步推理,还具有可解释、可迁移等优势。

论文地址:https://arxiv.org/abs/2310.07064
对数值推理和关系推理问题的实验表明,HtT 改进了现有的 prompt 方法,准确率提升了 11-27%。学到的规则也可以迁移到不同的模型或同一问题的不同形式。
方法简介
总的来说,HtT 框架包含两个阶段 —— 归纳阶段和演绎阶段,类似于传统机器学习中的训练和测试。
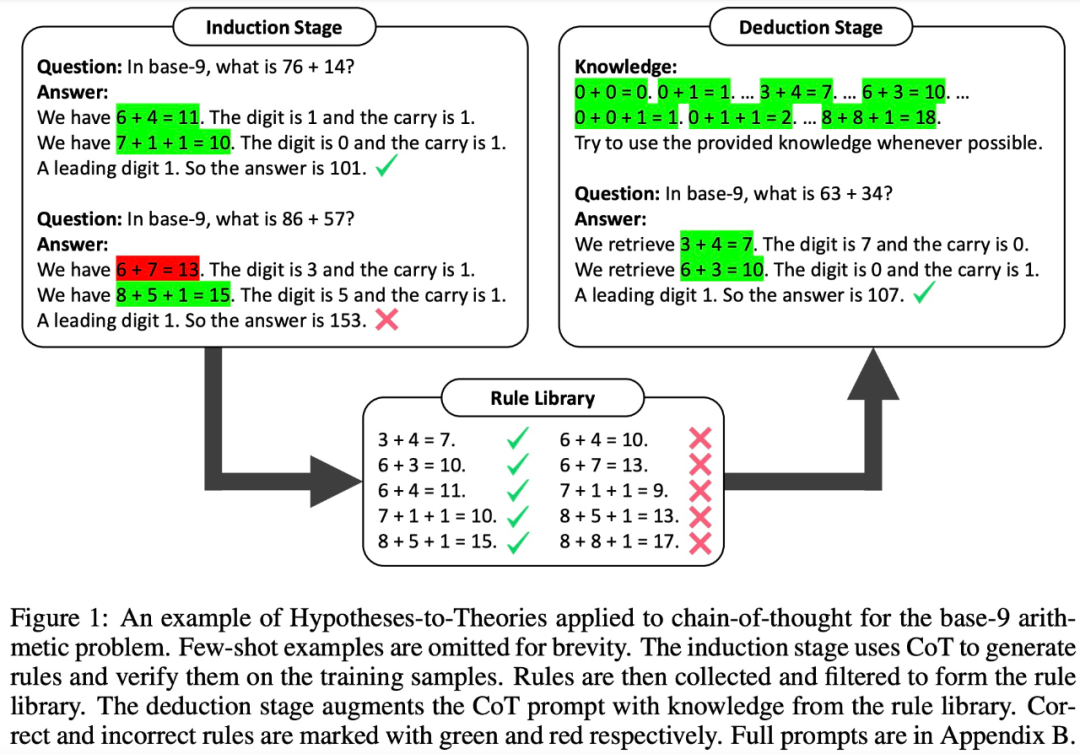
在归纳阶段,LLM 首先被要求生成并验证一组训练样例的规则。该研究使用 CoT 来声明规则并推导答案,判断规则的出现频率和准确性,收集经常出现并导致正确答案的规则来形成规则库。
有了良好的规则库,下一步该研究如何应用这些规则来解决问题。为此,在演绎阶段,该研究在 prompt 中添加规则库,并要求 LLM 从规则库中检索规则来进行演绎,将隐式推理转换为显式推理。
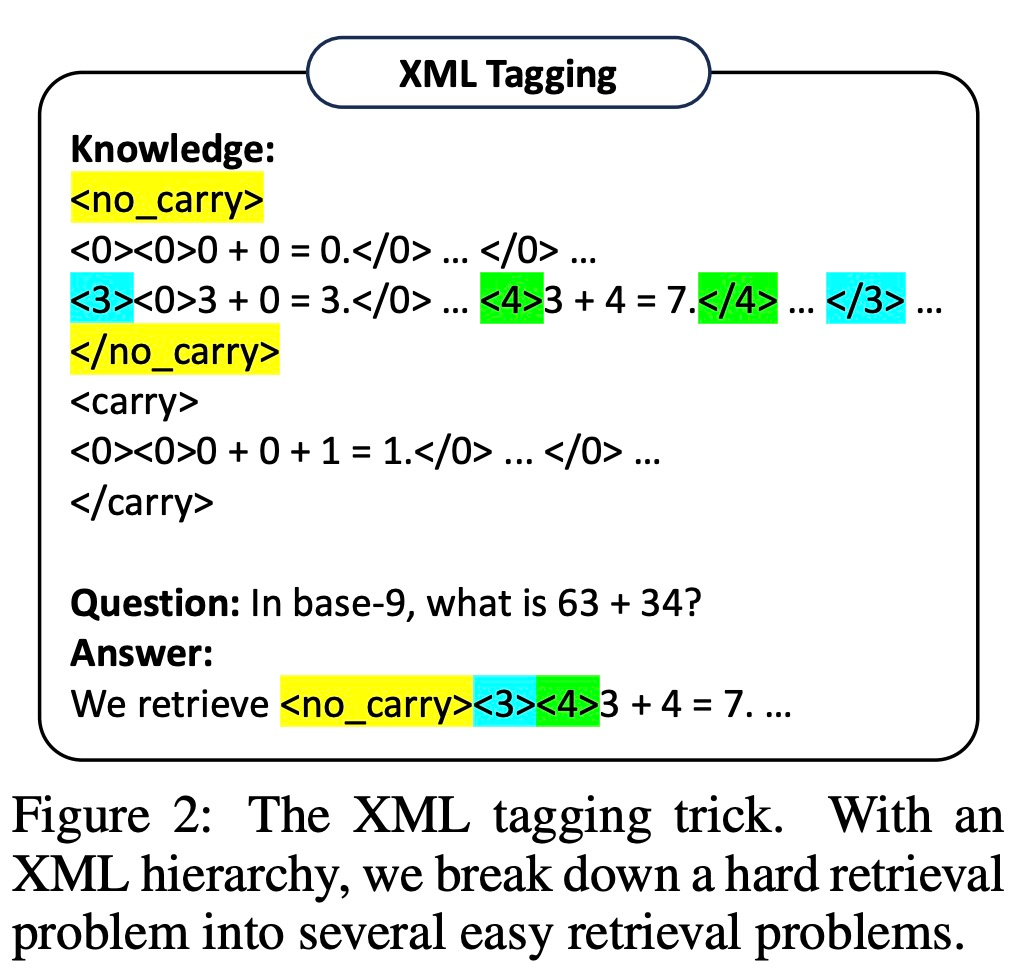
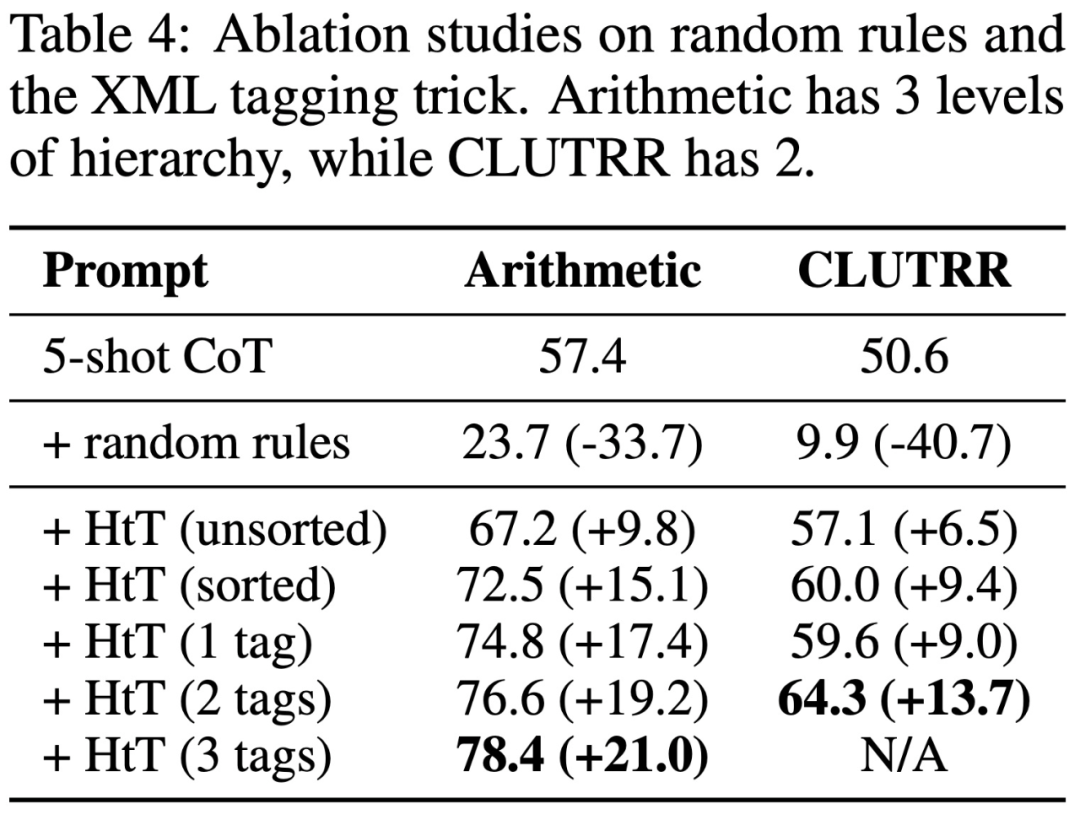
然而,该研究发现,即使是非常强大的 LLM(例如 GPT-4)也很难在每一步都检索到正确的规则。为此,该研究开发了 XML tagging trick,来增强 LLM 的上下文检索能力。
实验结果
为了评估 HtT,该研究针对两个多步骤推理问题进行了基准测试。实验结果表明,HtT 改进了少样本 prompt 方法。作者还进行了广泛的消融研究,以提供对 HtT 更全面的了解。
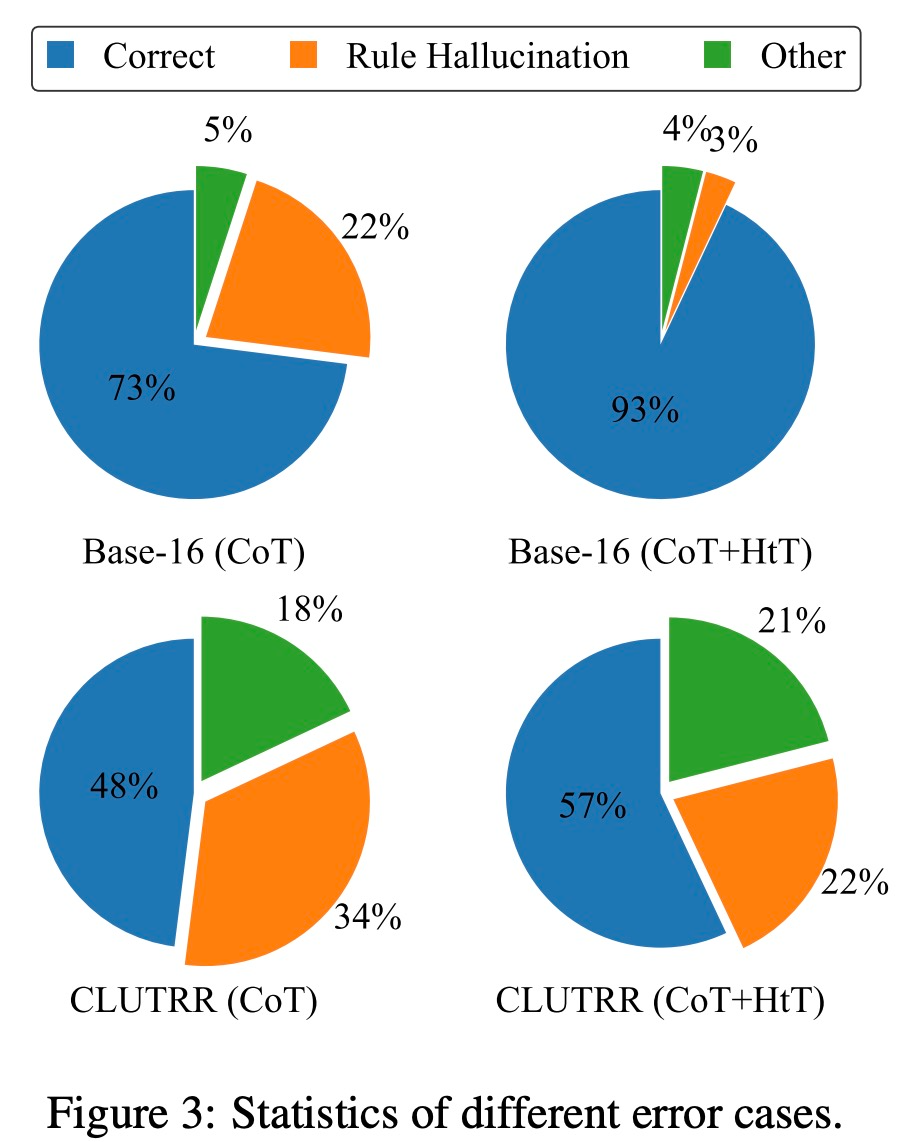
他们在数值推理和关系推理问题上评估新方法。在数值推理中,他们观察到 GPT-4 的准确率提高了 21.0%。在关系推理中,GPT-4 的准确性提高了 13.7%,GPT-3.5 则获益更多,性能提高了一倍。性能增益主要来自于规则幻觉的减少。
具体来说,下表 1 显示了在算术的 base-16、base-11 和 base-9 数据集上的结果。在所有 base 系统中,0-shot CoT 在两个 LLM 中的性能都最差。
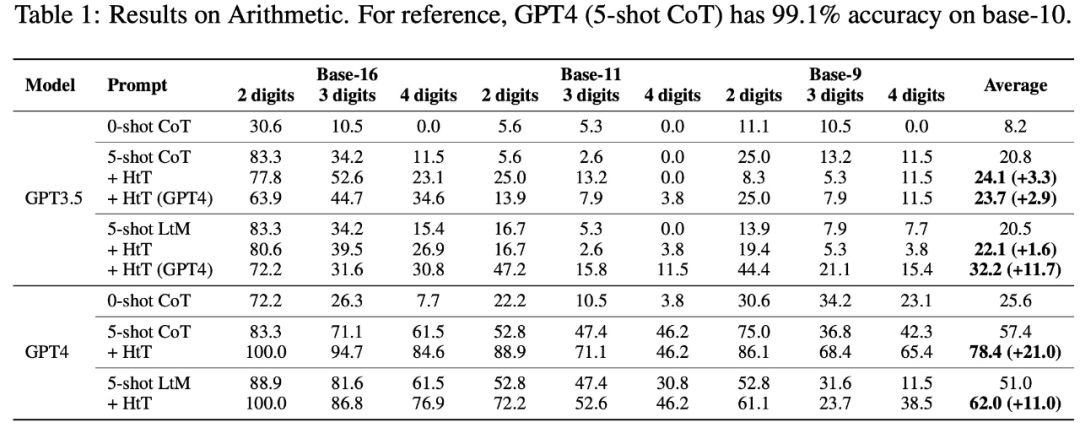
表 2 呈现了在 CLUTRR 上比较不同方法的结果。可以观察到,在 GPT3.5 和 GPT4 中,0-shot CoT 的性能最差。对于 few-shot 提示方法,CoT 和 LtM 的性能相似。在平均准确率方面,HtT 始终比两种模型的提示方法高出 11.1-27.2%。值得注意的是,GPT3.5 在检索 CLUTRR 规则方面并不差,而且比 GPT4 从 HtT 中获益更多,这可能是因为 CLUTRR 中的规则比算术中的规则少。
值得一提的是,使用 GPT4 的规则,GPT3.5 上的 CoT 性能提高了 27.2%,是 CoT 性能的两倍多,接近 GPT4 上的 CoT 性能。因此,作者认为 HtT 可以作为从强 LLM 到弱 LLM 的一种新的知识蒸馏形式。
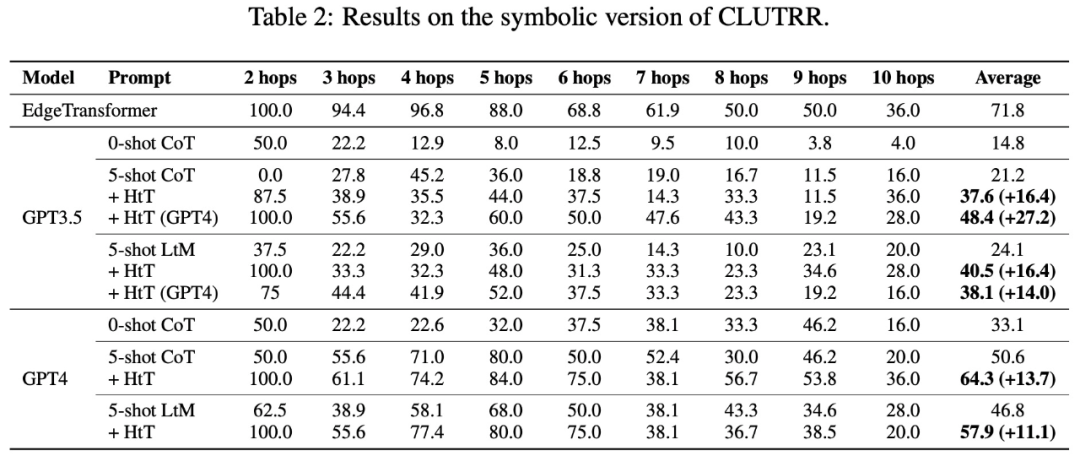
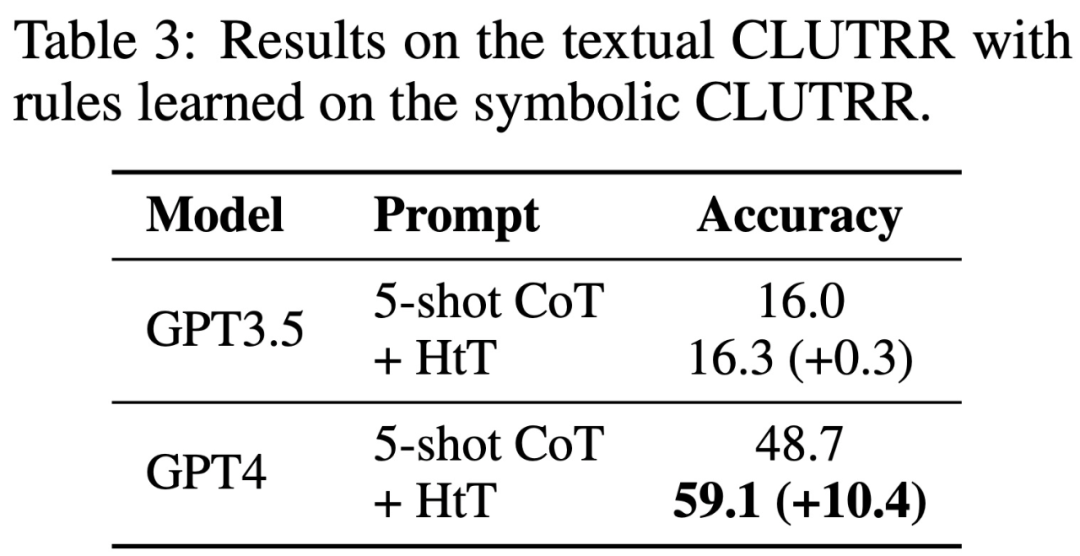
表 3 显示,HtT 显著提高了 GPT-4(文本版)的性能。对于 GPT3.5 来说,这种改进并不显著,因为在处理文本输入时,它经常产生除规则幻觉以外的错误。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









